Normally when we use a computer, our intuition is that the computer is divided into two kinds of things: folders and files. But in fact, in the operating system’s file system, folders can also be thought of as files that store special content; “everything is a file”. And the file system doesn’t use file names to distinguish files, but rather a string of non-repeating numbers. In this article, we will introduce some concepts and principles of the file system.
The Linux file system divides the disk into two parts. The contents of the file are stored in the block. The meta-information of the file, such as owner, group, atime, etc., is stored in the inode, including the location of the block. The following figure shows this.
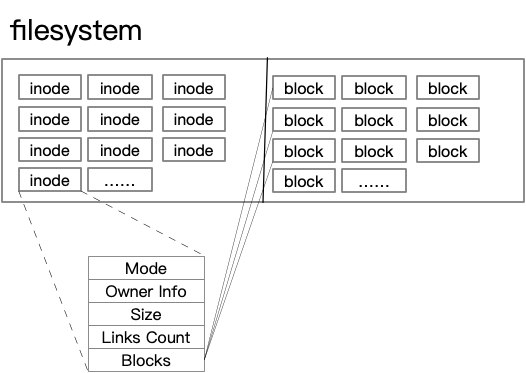
As we can see from the picture, there is no information about the file name in this. And our daily operations on files are through the file name. So where is the file name? As mentioned above, folders are also files, and the names of the files, in fact, are inside the contents of the folders (i.e. blcok). Folders are also in the above form, with inode recording its meta information, and then inode pointing to block, which stores the contents of the folder, i.e. the mapping from file name to inode.
Although a folder is also a file, the operating system does not provide syscall to operate directly on the contents of the folder. For example, you cannot cp /dev/null directory to overwrite the contents of a folder, nor can you view the actual contents of a block. Instead, you can only perform limited operations on the folder through the syscall provided by the system. This is done first because there are only so many operations on the folder, and syscall is enough; second because if the mapping of the folder storage is messed up, not only is the folder unavailable, but the associated inode is not available (because we operate on files by filename, and the inode is blocked out by the file system).
So, when the file system gets a path, how does it find the corresponding content? For example, /home/root/a.txt.
First the file system will start with #2 inode (note the classic file system here, different file systems may start with different inodes, but why is it 2?) Then you find the block pointed to by #2 inode and read the list of files under /. Then you find the inode corresponding to home. Then find the inode corresponding to home, open the list of files under /home through the block pointed to by the inode, find the inode corresponding to root, find the block pointed to by the inode, read the block corresponding to a.txt, and finally read the content stored in the block, which is the content of a.txt.
We can see the inode corresponding to the name under a folder with the -i parameter of ls (not the same as above starting from #2, because my environment is xfs):
Once a file system is created, the number of inodes or blocks is determined and cannot be modified. If the inode is used up, the file system can no longer create new files (unlikely to happen, unless the creation of a very large number of small files). df -i can view the system’s inode usage.
|
|
inode to block addressing
Have you ever used a USB flash drive? Have you ever had a problem with a flash drive not being able to store files larger than 4G (FAT32 file system)? Even if the flash drive is 32G. This is actually a limitation of file system addressing. Next, let’s take the EXT4 file system as an example and see how the file system finds the block with inode, and by the way, let’s calculate what is the maximum possible EXT4 single file.
In the preceding diagram, you can see that the inode contains information about the file owner, the access time, the modification time, and so on. The most important thing is the location of the block, which is, after all, where the actual contents of the file are stored.
If you are given an inode, how do you store the location of the block inside the inode? The size of the file is unknown and can be large or small. Based on this feature, the first thought might be to use a LinkedList to store the location of the block, leaving a location for the next block, but it is important to know that mechanical hard drives read sequentially very quickly, and head movement is very slow if read randomly. So the block must be used continuously as much as possible, and using LinkedList to do the addressing is too slow, so it is more appropriate to use Array as an adjacent form.
So how much space should we leave in the inode for the block address? Too little, and the single file limit is too small. If it is too big, it is too wasteful if the system is full of small files.
Here’s what the Ext4 file system does (and what most file systems do): set aside 15 locations to take care of storing block addresses. Can a file have only 15 blocks? Of course not. These 15 addresses are divided into Direct Block Pointers, Indirect Block Pointers, Double indirect Block Pointers, and Triple Indirect Block (Pointers).
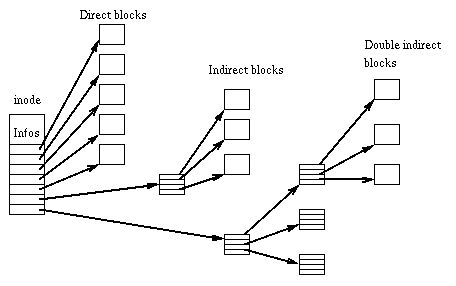
Here we assume that the size of a block is 4K, so if the file is smaller than 4*12=48K, it can be stored by using the direct block pointers in the inode. In summary, there are 12 Direct Block Pointers, each of which represents a 4K block. 48K can be stored in total.
The 13th pointer is an Indirect Block Pointers, which also points to a block, but instead of storing the contents of the file, the block stores some pointers to the block - a whole block of pointers like Direct Block Pointers! Block pointers are 32bit, one block can store 4K/32bit = 1024 Block pointers. In summary, Indirect Block Pointers is one block, which stores 1024 block pointers in one block, and can store 1024 * 4K = 4M data.
The 14th pointer is Double indirect Block Pointers, which is better understood, the address stored in this location still points to a block, but this block is still stored in the block pointer, these block pointers point to the block is still stored in the pointer! These pointers then point to the block that stores the contents of the file. See the last position in the figure above. We know that Indirect Block Pointers can store 4M data, so the double Block Pointers here are actually the pointers that store 4M, how many Block Pointers can be stored in 4M?4M /32bit = 1048576, each block 4K, that can store 4G data.
The 15th pointer, it is very good to understand it, let me go around a circle, here is the storage of pointers to Block, pointers to the Block stored or Block pointer, pointers to the Block stored or Block pointer, here is the storage of Block pointer or Block pointer (count the number of Indirect it). These pointers to the Block is stored in the contents of the file. Double indirect Block Pointers can have 4G, so the 4G data are all pointers then is 4G / 32bit * 4K = 4G * 1024 = 4T.
In summary, the maximum file size is 48K + 4M + 4G + 4T. Isn’t that a clever design?
The last point to emphasize is that the inode data structure differs from one file system to another, for example, the ext4 file system supports storing very small files directly in the inode and does not use blocks.
Hard Link and Symbolic Link
As we said above, the contents of a folder are actually a mapping of file names to inodes.
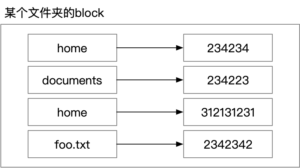
So is it possible to have two names mapped to the same inode?
The answer is yes, this is called a Hark Link.
A Hard Link can be created by ln source-filename target-filename, which creates a target-filename mapped to the same inode number as source-filename.
As an example, we now have the hello file.
We can see that its inode number is 12945694378, and then we create a Hark Link.
We can observe two interesting phenomena.
1) hello and world have the same inode number, which means that the inode corresponding to these two file names is the same, i.e. they have exactly the same owner, atime, and the block they point to, and of course the file contents are exactly the same. If we change the permissions of one file, then if we look at the name of the other file, it will change as well.
2) There is a number that has changed from 1 to 2. This number is called Link Counts, which is a field in the inode that records how many filename -> inode number mappings there are, and when there is no filename pointing to this inode, it means that this inode can be recycled.
From the above, we can see that after creating a Hard Link, there are actually two filenames pointing to the same inode, i.e. there is no difference between the newly created Hard Link and the original one, and there is no way to tell who is the Hard Link and who is the original file. The operation of deleting a file is actually unlink, which means that the mapping of a filename -> inode is deleted, and the inode will be deleted only when the Link Counts of an inode is 0.
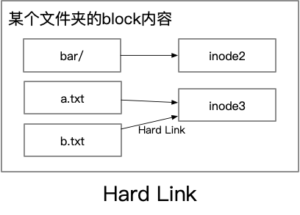
Does it feel like reference counting in GC? Then a new question arises: how to solve the problem of circular references? For example, in the following case, a Hard Link to the parent folder is created in the subfolder.
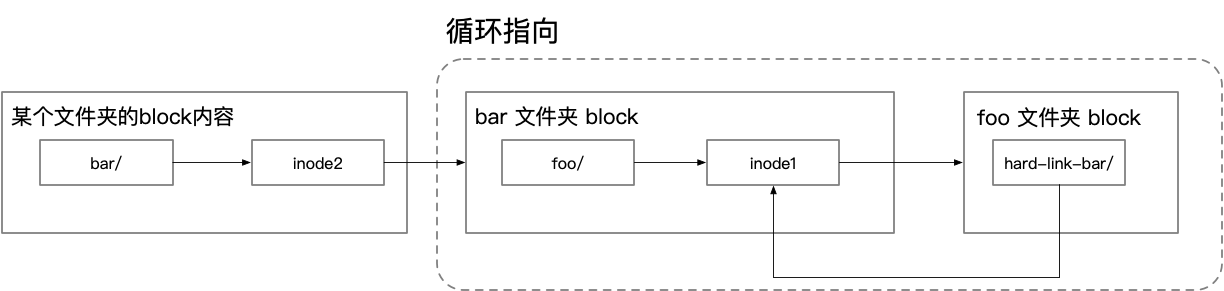
This way, when the entire parent folder is deleted, the Link Counts of the inodes to which these Hard Links point still do not drop, causing problems with the release. How does the file system solve this? Disable Hard Link creation for folders and only allow Hard Link creation for files.
Also, have you ever wondered why we can use cd ... to jump to the parent folder? Actually, when a folder is created, it automatically creates a mapping called .. mapping to the inode of the parent folder, i.e. after a new folder is created, its Link Count will be 2, one is . and . .
Symbolic Link is relatively more commonly used, because the management cost of Hard Link is too high. When you delete a file, you have to delete all the Hard Links in order to do so.
A Symbolic Link can be understood as a special file whose contents point to the real file. In this way, if you delete the source file, the Symblic Link still exists (as a Windows shortcut for those who have used Windows).
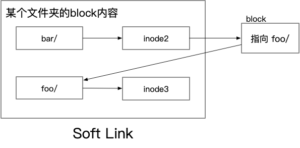
Early implementations of symbolic links used direct allocation of disk space to store information about symbolic links, a mechanism consistent with that of ordinary files. Such symbolic link files contained a reference to the target file in text form, as well as a flag identifying itself as a symbolic link.
Such storage proved to be somewhat slow and wasted disk space on some small systems early on. A new type of storage called fast symbolic links can store links in text form in a standard data structure on disk (inode) used to store file information. The original symbolic link storage method is also called slow symbolic link to indicate the difference.
Fun with inodes
- Moving files, renaming, etc., actually only modifies the filename -> inode mapping stored in the block of the parent directory, so it has nothing to do with how big the file is, it’s all O(1) complexity; and it doesn’t affect the inode number either.
- Theoretically, when a file is created and inode is assigned, it never changes again. Moving, renaming, writing to a file, truncating a file only modifies the inode meta information or modifies the contents of the parent directory, the inode always remains the same. So it is very reliable to use inode to distinguish log files like log collectors. The logs are rotated so that there are no duplicates or omissions.
- If you know an inode, how do you find the file?
$ find . -inum 23423 -print - But direct inode manipulation is not allowed, the syscall provided by Kernel can only manipulate files by filename. For the same reason as above, it is dangerous to corrupt the file system.
- There is a file with a weird name inside the file system, how can I delete it? You can delete it by inode.
$ find . -inum 234234 -delete.
Finally, this article describes the behavior of most filesystems and may vary for a particular filesystem. If there are any omissions in this article, please feel free to point them out.