The word schema originates from the Greek word form or figure, but exactly how schema should be defined depends on the context of the application environment. There are different types of schema and their meanings are closely related to the fields of data science, education, marketing and SEO, and psychology.
But schema in computing is actually very close to this interpretation, and the term schema can be found in many places, such as database, openldap, programming language, etc. Here we can simply interpret _schema_ as a metadata component, which mainly contains declarations of elements and attributes, and other data structures.
Schema in a database
In a database, schema is like a skeleton structure that represents a logical view of the entire database. It designs all the constraints that are applied to the data in a particular database. A schema is created when data is modeled. schema is often used when talking about relational databases] and object-oriented databases. sometimes it also refers to a description of the structure or text.
A schema in a database describes the shape of the data and its relationship to other models, tables, and libraries. In this case, the database entry is an instance of the schema and contains all the attributes described in the schema.
Database schema is usually divided into two categories: physical database schema which defines how data files are actually stored, and logical database schema which describes all the logical constraints applied to stored data, including integrity, tables and views. Common ones include
- star schema
- snowflake schema
- fact constellation schema (fact constellation schema or galaxy schema)
The star schema is similar to a simple data warehouse diagram that includes a one-to-many fact table and dimension table. It uses non-normalized data.
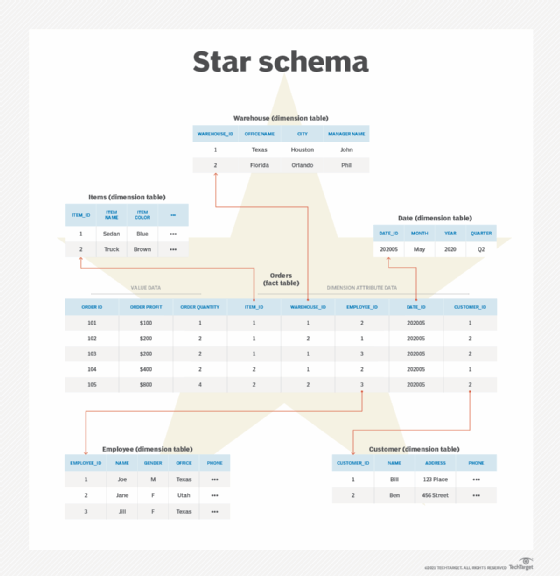
Snowflake schema is a more complex and popular database schema in which dimension tables are normalized to save storage space and minimize data redundancy.
The fact constellation schema is far more complex than the star and snowflake schemas. It has multiple fact tables that share multiple dimension tables.
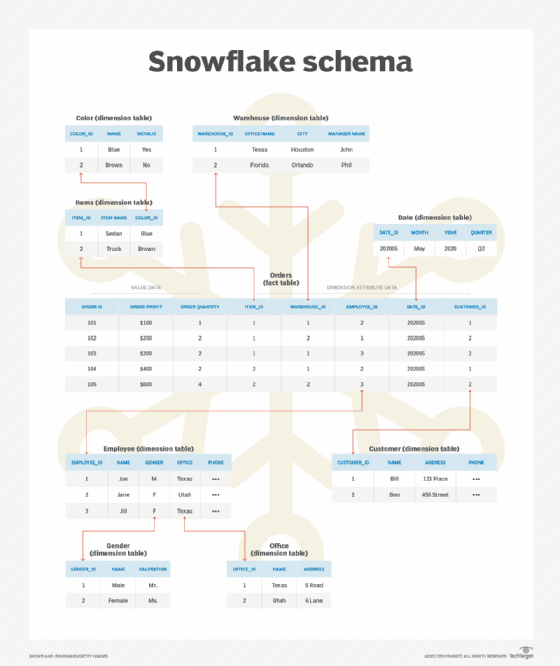
Schema in Kubernetes
The above explanation gives you an idea of what schema is. In Kubernetes, there is also the concept of schema, which is the metadata of k8s resource objects by defining the specification of resources (GVK) in kubernetes and mapping the relationships between them.
The resource objects in kubernetes are Group Version Kind, which are defined in staging/src/k8s.io/api/type.go. This is the yaml file that we normally work with.
For example.
The corresponding ones are TypeMeta, ObjectMeta and DeploymentSpec, TypeMeta for kind and apiserver, ObjectMeta for Name, Namespace, CreationTimestamp and so on. .
The DeploymentSpec corresponds to the spec in yaml.
The whole yaml is a k8s resource object.
|
|
register.go is the class that registers the corresponding resource type into the schema.
|
|
The apimachinery package is an implementation of schema, and by looking at its contents you can see that schema in kubernetes is a mapping between GVK attribute constraints and GVR.
Understanding schema through examples
For example, in the apps/v1/deployment resource, which is represented in the code as k8s.io/api/apps/v1/types.go, what do you need to do if you need to extend the resource? For example, create a StateDeplyment resource.
As shown in the above code, metav1.TypeMeta and metav1.ObjectMeta in Deployment.

Then we copy a Deployment as StateDeployment, note that since the two properties of Deployment, metav1.TypeMeta and metav1.ObjectMeta implement different methods respectively, as shown in the figure.
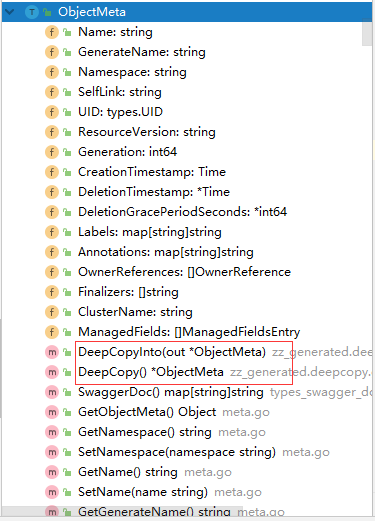
So when implementing the methods, you need to implement DeepCopyinfo, DeepCopy and the DeepCopyObject method of the inherited interface Object.
|
|
Then the entire stream for extending a resource is.
- Resource type in:
k8s.io/api/{Group}/types.go - The implementation interface for the resource type
k8s.io/apimachinery/pkg/runtime/interfaces.go.Object - which is based on the
Deploymenttypes,metav1.TypeMetaandmetav1.ObjectMeta metav1.TypeMetaimplementsGetObjectKind();metav1.ObjectMetaimplementsDeepCopyinfo=(),DeepCopy()and also needs to implementDeepCopyObject()- Finally register the resource in schema
k8s.io/api/apps/v1/register.go