blkio cgroup basic functions
blkio is a subsystem in cgroup v1. The main reason for using cgroup v1 blkio subsystem is to reduce the problem of mutual interference when processes read and write to the same disk together.
The cgroup v1 blkio control subsystem can limit the IOPS and throughput of process reads and writes, but it can only limit the speed of file reads and writes for Direct I/O, but not for Buffered I/O.
Buffered I/O means that it goes through the PageCache and is then written to the storage device. The meaning of Buffered here is different from buffer cache in memory, the meaning of Buffered here is equivalent to buffer cache + page cache in memory.
In the blkio cgroup, there are four main parameters to limit disk I/O as follows.
To limit the write throughput of a control group to no more than 10M/s, we can configure the blkio.throttle.write_bps_device parameter as follows.
|
|
In Linux, the default way to read and write files is Buffered I/O, where the application writes the file to the PageCache and returns it directly, and then the kernel thread synchronizes the data from memory to disk asynchronously. Direct I/O, on the other hand, does not deal with memory, but writes directly to the storage device.
To understand the speed limit logic of the blkio cgroup, you need to first understand the Linux write file flow.
Flow of writing files in Linux
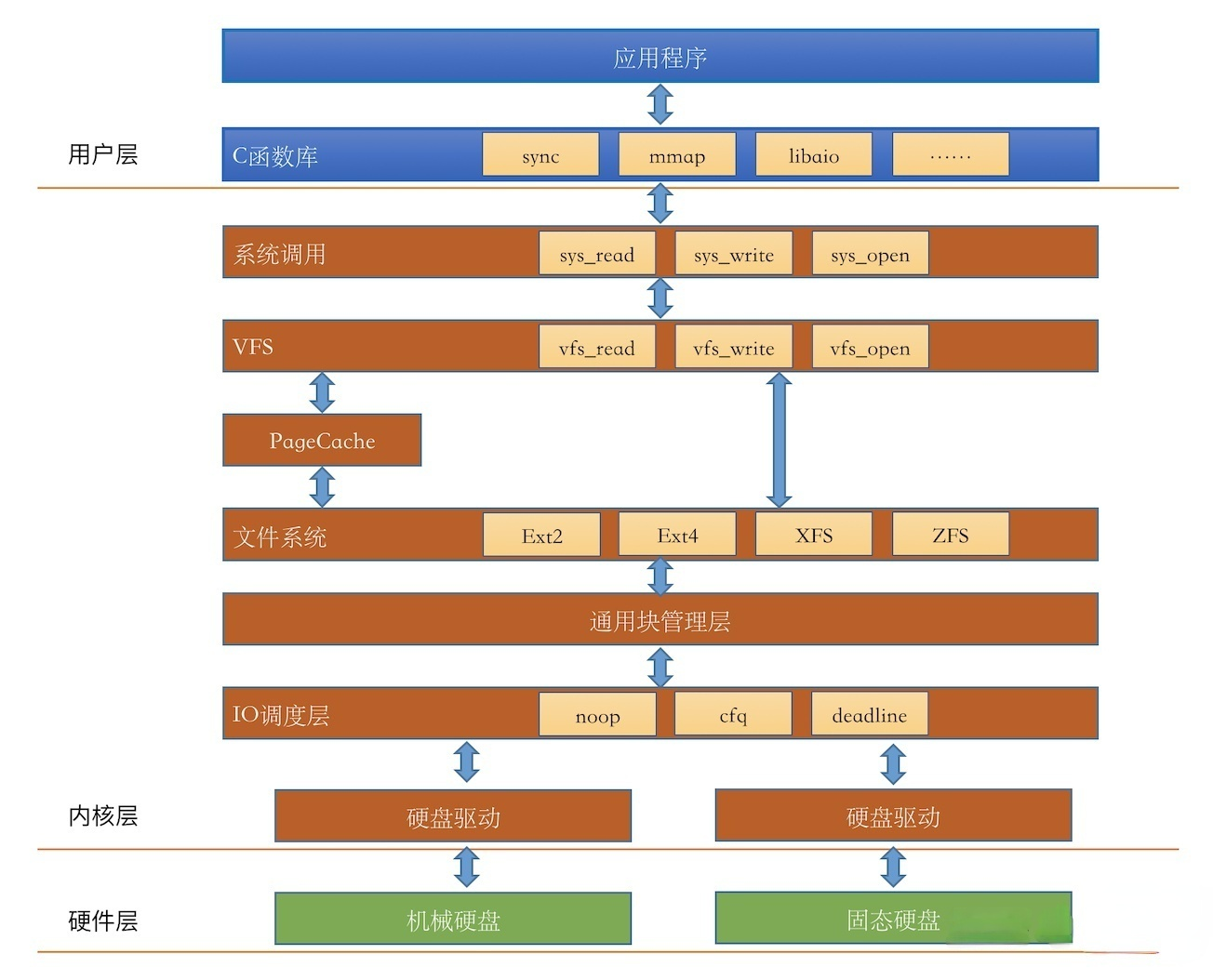
The above diagram is a flowchart of Linux file writing, which contains three main parts, user layer, kernel layer, and hardware layer. Linux writes files to disk after going through several processes such as system calls, VFS, PageCache, file system, general block management layer, and IO scheduling layer. The blkio cgroup works in the general block management layer; Buffered I/O writes to the PageCache first and then goes to the next process to write data to disk, while Direct I/O bypasses the PageCache and goes directly to the next process.
Linux applications write to files as Buffered I/O by default. In this case, it does not need to go through the common block management layer, but only writes to the PageCache, so it cannot be speed limited. However, the data in the PageCache is always written to disk through the common block management, which in principle has an impact, but it may not be the same for the application, which is also related to the mechanism of writing to disk in the PageCache.
Under normal I/O conditions, the application is likely to write the data very quickly (if the amount of data is less than the cache space) and then go off to do other things. At this point, the application does not feel that it is being limited, and as the kernel synchronizes data from the PageCache to disk, all PageCache writes can only be limited in the root group of the cgroup because there is no specific cgroup association information in the PageCache, but not in other cgroups, and the root The root cgroup is generally unrestricted as well. In the case of Direct IO, since the data written by the application does not go through the cache layer, it can directly feel that the speed is limited and must wait until the whole data is written or read at the limited speed before it can be returned. This is the environmental limitation that the current cgroup’s blkio limit can work.
PageCache dirty page write-back mechanism.
-
If there are too many dirty pages, the proportion of dirty pages in the Page Cache reaches a certain threshold and writes back. There are two main parameters to control the dirty page ratio.
- dirty_background_ratio indicates that a background thread starts flushing dirty pages when the percentage of dirty pages to total memory exceeds this value. This value, if set too small, may not make good use of memory to accelerate file operations. If set too large, a periodic spike in write I/O will occur, defaulting to 10.
- dirty_background_bytes: performs the same function as dirty_background_ratio, this parameter is based on the number of dirty page bytes, but only one of the two parameters will take effect, default is 0;
- dirty_ratio When the percentage of memory occupied by dirty pages exceeds this value, the kernel blocks the write operation and starts flushing the dirty pages, default is 20.
- dirty_bytes: same function as dirty_ratio, this parameter is based on the number of dirty pages bytes, but only one of the two parameters will take effect, default is 0.
-
Dirty pages exist for too long and the kernel threads will write back periodically. The dirty page existence time is mainly controlled by the following parameters.
- dirty_writeback_centisecs indicates how often to wake up the background thread for refreshing dirty pages, this parameter will act together with the parameter dirty_background_ratio, one indicates the size ratio and the other indicates the time; i.e., the condition of refreshing the disk is reached if any one of these conditions is met, the default is 500.
- dirty_expire_centisecs indicates how long a dirty page will be considered by the kernel thread to need to be written back to disk, default is 3000.
Why cgroup v1 does not support non-buffer IO limitation
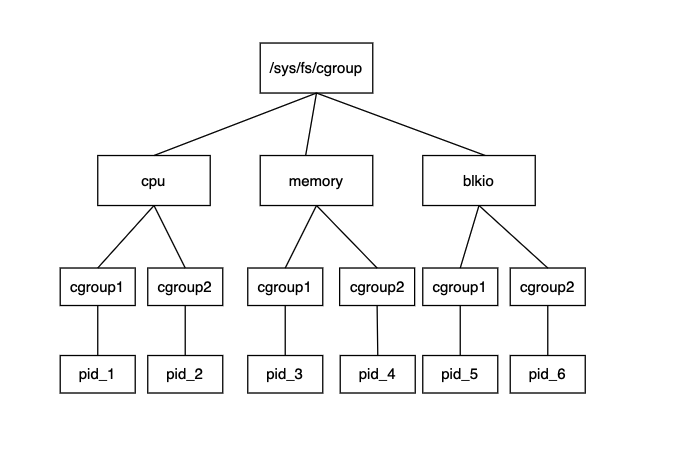
cgroup v1 usually has one subsystem per tier, and the subsystems need to be mounted for use, and each subsystem is independent of each other, so it is hard to work together. For example, memory cgroup and blkio cgroup can control the resource usage of a process separately, but blkio cgroup can’t sense the resource usage of the process in memory cgroup when restricting the process resources, so the restriction of Buffered I/O has not been implemented.
The cgroup v1 structure is shown below.
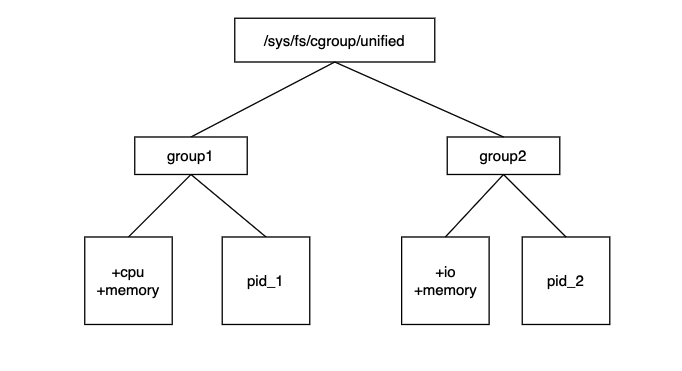
cgroup v1 had a lot of flaws that led linux developers to redesign cgroup, which led to cgroup v2. In cgroup v2, the problem of Buffered I/O limitation can be solved. cgroup v2 uses unified hierarchy, each subsystem can be mounted under unified hierarchy, a process belongs to a control group, and each control group can define as many subsystems as it needs. cgroup v2 io subsystem The io subsystem in cgroup v2 is equivalent to the blkio subsystem in v1.
The structure of cgroup v2 is shown as follows.