In the previous article, Docker’s network implementation was introduced and discussed. For Docker network, its biggest limitation is the gap in the cross-host container communication scheme, while Kubernetes, as a container orchestration platform suitable for large-scale distributed clusters, mainly solves the following problems at the network implementation level.
- inter-container communication.
- Pod-to-Pod communication.
- Pod-to-Service communication.
- Intra-cluster and inter-cluster communication.
This blog post focuses on Kubernetes inter-container communication and inter-Pod communication, followed by a separate article on Pod-Service communication, which is related to kube-proxy working principle and service mechanism.
Inter-container communication
Pod is the most basic scheduling unit in Kubernetes, not a Docker container. Pod means pod, and containers can be understood as beans in a pod, and a Pod can contain multiple containers with related relationships. The communication between Pod and Service is also from the Pod level. This is a concept that must be understood in advance, but at the bottom, it still involves the communication between containers, after all, Pod is only an abstract concept.
Containers within the same Pod do not communicate across hosts, they share the same Network Namesapce space and the same Linux protocol stack. So for all kinds of network operations, a Pod can be treated as a separate “host” and the containers inside can access each other’s ports with localhost addresses. The result is simplicity, security and efficiency, and it also makes it less difficult to migrate existing programs from physical or virtual machines to run under containers.
As shown in the figure, there is a Pod instance running on the Node, and the containers inside the Pod share the same Network Namespace, so communication between Container 1 and Container 2 is very simple, and can be done through direct local IPC, and for network applications, directly through localhost access to the specified port. Therefore, for some traditional programs want to port to Pod, almost do not need to do too much modification.
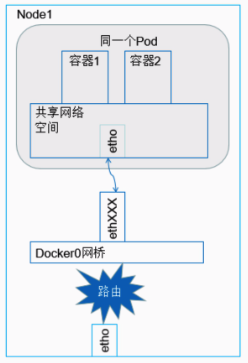
Pod-to-Pod Communication
Just now I said that the containers in the same Pod are all on the same Node, so there is no problem of cross-node communication, but at the Pod level, as the basic scheduling unit of Kubernetes, different Pods are likely to be scheduled to different Nodes, and of course, they may also be scheduled to the same Node. Therefore, the communication between Pods should be discussed in two ways.
- Pod-to-Pod communication under the same Node
- Pod-to-Pod communication under different Nodes
Inter-Pod communication under the same Node
Each Pod has a real global IP address, different Pods within the same Node can communicate directly with each other using the other Pod’s IP address, and no other discovery mechanisms such as DNS, Consul or Etcd are required.
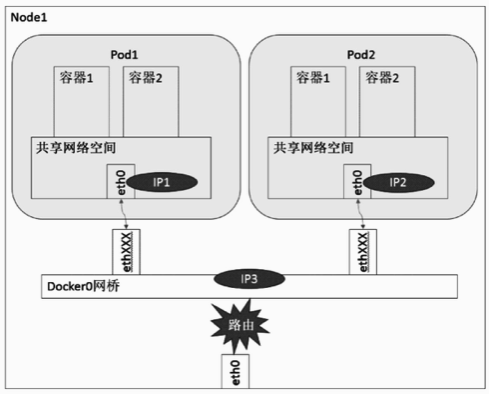
Under the same Node, different Pods are connected to the docker0 bridge through the Veth device pair. The Docker bridge mode has been discussed in the previous Docker network implementation, and the IPs of the Pods are dynamically assigned from the docker0 bridge. Pod1, Pod2 and docker0 bridge belong to the same network segment, that is, they can communicate directly with each other. This is easy to understand.
Don’t you have any questions about the eth0 per Pod point? Why Pod is an abstract virtual concept, but can also have a separate network stack, i.e. Network Namespace, and can also mount a Veth device? In fact, the diagram here is not delineated, each Pod will have a pause container by default (actual name: google_containers/pause), which can be considered as a “housekeeping container” for Pods, the pause container is responsible for some initialization work including Pod networking, the pause container uses the previously mentioned Docker’s default network communication model Bridge, pause through the Veth device pair and docker0 bridge, while other containers within the Pod using a non-default network configuration and mapping container model, specify the mapping of the target container to the Pause container, the purpose of doing so is very simple, in order to achieve a Pod within multiple containers, itself no good way to connect, pause to provide a Pod internal communication “bridge”, why not the latter container associated with the former container way it? If this way, once the previous container does not start or hang, the container behind will be followed by the impact.
Pod-to-Pod communication under different Nodes
Inter-Pod communication under the same Node is easy to understand because it can be achieved directly through the docker0 bridge. But how to implement inter-Pod communication under different Nodes is a problem that needs to be studied.
The first thing we need to know is that the docker0 bridge on each host assigns private IPs to Pods, and Kubernetes requires that the network address to Pods is flat and direct, which means that you can communicate between different Nodes in the cluster via the Pod’s private IP. Therefore, we can see that the planning of Pod IPs is very important. In order to achieve the above-mentioned goal of using private IPs for Pod communication between different Nodes within the cluster, we must at least ensure that these private IPs must be conflict-free at the cluster level. Note that these Pod private IPs are stored in the Etcd cluster.
In addition, we know that the communication between different Nodes must be through the physical NIC of the host, so to achieve the communication between Pods in different Nodes, we also need to address and communicate through the IP of the Node, which is also a point that needs attention.
In summary, we can see that for inter-Pod communication under different Nodes, the core is to satisfy two points:
- Pod IP achieves no conflict at the cluster level Although the IP allocation of Pods is the responsibility of the local docker0, the specific address planning must be at the cluster level to ensure that it does not conflict, which is the basic condition for cross-Node communication through private Pod IP.
- Pod IP addresses access with Node IP The bridge between Nodes is still the actual physical NIC of the Node, so we need to find a way to associate Pod IP with Node IP and achieve access between Pods of different Nodes through this association.
For the first point, to achieve Pod IP at the cluster level without conflict, we need to docker0 address segment planning, to ensure that the docker0 segments on each Node are conflict-free, for this point, you can manually configure, of course, if it is a small cluster is okay, if it is a large-scale cluster, I think this is bullshit. Therefore, there should be a better solution, such as making an assignment rule and letting the program assign the address segments itself, which is easy to think of. Yes, thanks to the CNI (Container Network Interface) provided by Kubernetes, there are some great Kubernetes network enhancements that can be docked in to help us do this. Typical examples are Flannel, Calico.
For the second point, the core goal is to realize the addressing of Pod IP by Node IP, that is to say, there is a mechanism to know which Node the Pod IP is on, forward the data to the target Node through the host, and then the target Node will forward the data to the specific local docker0, and finally to the target Pod, the whole process is roughly The whole process is roughly as shown in the diagram.
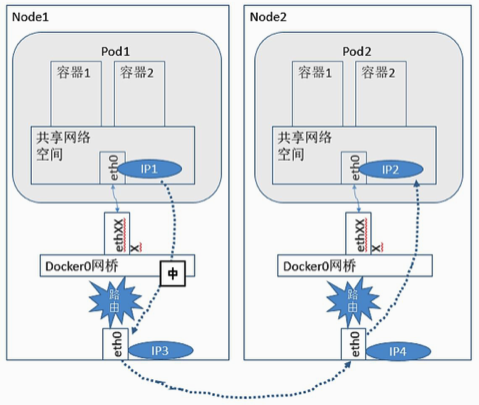
Some well-known cloud platforms are designed to implement IP management of Pods, so Pod communication can be opened with the network design of the platform layer. However, in most cases, especially for Kubernetes clusters maintained by enterprises, you may not be able to enjoy this mechanism, so you need to configure the network to meet the requirements of Kuberntes before you can achieve normal communication between Pods, and then achieve the normal operation of the cluster. As mentioned in the first point above, Kubernetes is highly scalable, and some network enhancement components (Flannel, Calico, etc.) achieve these network requirements through the CNI mechanism. However, the basic principle and requirements are described above, which must be understood, but for the actual implementation, each enhancement component has its own implementation plan. It is impossible to introduce them one by one in detail here.