kube-proxy operational mechanism
To support horizontal scaling and high availability of clusters, Kubernetes abstracts the concept of a Service, which is an abstraction of a set of Pods that are accessed according to an access policy (e.g., load balancing policy). Kubernetes assigns a virtual IP address to the Service when it is created, and clients access the Service by accessing the virtual Clients access the service by accessing the virtual IP address, and the service is responsible for forwarding requests to the back-end Pods. This acts like a reverse proxy. But there are some differences between it and a normal reverse proxy: first, the IP address of the Service, also known as ClusterIP, is virtual and requires some skills to access it from outside; second, its deployment and startup/stopping is managed automatically by Kubernetes.
kube-proxy operating modes
The specific mode of operation of kube-proxy has actually evolved with the evolution of Kubernetes versions, and is broken down into the following modes of evolution.
- userspace (userspace proxy) mode
- iptables mode
- IPVS mode
userspace mode
The earliest mode of operation of kube-proxy is userspace userspace proxy mode, in which kube-proxy takes on the real TCP/UDP proxy task, and when a Pod accesses the Service via Cluster IP, the traffic is intercepted by iptables and forwarded to the node’s kube-proxy process.
The service’s routing information is obtained through the watch API Server, and then the kube-proxy process establishes a TCP/UDP connection with the specific Pod. The kube-proxy process then establishes a TCP/UDP connection with the specific Pod and sends the request to the Service’s back-end Pod, achieving load balancing in the process.
iptables mode
Starting from kubernetes 1.2, userspace userspace proxy mode is no longer used and is replaced by iptables mode. In iptables mode, kube-proxy no longer acts as a direct proxy, but its core responsibility becomes: on the one hand, it gets the change information of Service and Endpoint in real time through watch API Server, and then dynamically updates the iptables rules, and then the traffic is directly routed to the target Pod according to the NAT mechanism of iptables instead of establishing a separate connection.
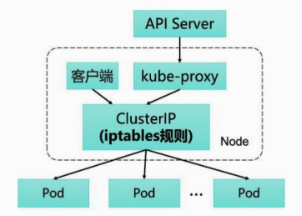
Compared with the previous userspace mode, iptables mode works entirely in the kernel state without switching to the user state kube-proxy, avoiding frequent switching between kernel and user states and improving performance compared to the previous one.
However, iptables also has a limitation, that is, due to the objective factor of iptables, when the size of Kubernetes cluster increases, the number of rules of iptables will increase dramatically, which will lead to the degradation of its forwarding performance, and even the loss of rules (the failure is very difficult to reproduce and troubleshoot), so The iptables model also needs to be improved.
IPVS Mode
IPVS mode is the IP Virtual Server mode, which was upgraded to GA in Kubernetes 1.11. IPVS and iptables are both based on Netfilter implementation, but the positioning is fundamentally different. iptables is designed to be used as a firewall, while IPVS is used for high performance load balancing. IPVS uses a Hash Table structure for rule storage, so it is theoretically more suitable for large-scale scaling without affecting performance. IPVS also supports more complex load balancing algorithms than iptables (minimum load/minimum connections/weighting, etc.), server health checks and connection retries. In addition, it can dynamically modify the ipset set.
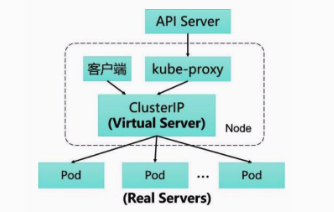
In IPVS mode, you don’t have to abandon iptables. Although IPVS is definitely better than iptables in terms of performance, there are many features that IPVS lacks compared to iptables, such as packet filtering, address masquerading, SNAT, etc. Therefore, there are scenarios where IPVS and iptables need to work together. For example, the NodePort implementation. Also, in IPVS mode, kube-proxy uses ipset, an extension of iptables, instead of generating rule chains directly from iptables. iptables rule chains are linear data structures, while ipset is an indexed data structure, so when there are many rules, they can be matched and found efficiently.