
GitOps was first introduced by Weaveworks, a Kubernetes management company, in 2017. Now that five years have passed, I’m sure you’ve heard of the concept, but you may not know what it is or what it has to do with DevOps. In this article, we’ll help you figure it out one by one.
Infrastructure as Code
Before we can understand GitOps, we need to understand what Infrastructure as Code is.
Infrastructure as Code (IaC), as the name implies, indicates that infrastructure is defined using code (rather than manual processes) and that developers can treat infrastructure like application software, for example.
- Declarative configuration files can be created that contain infrastructure specifications, thereby facilitating editing and distribution of configurations.
- It is possible to ensure that the environment is identical every time it is configured.
- Version control is possible, and all changes are logged for easy traceability.
- The infrastructure can be divided into several modular components and combined in different ways through automation.
Of course, IaC in the broader sense is not just about infrastructure, but also includes Networking, Security, Configuration, and so on, so IaC in the broader sense is also called X as Code.
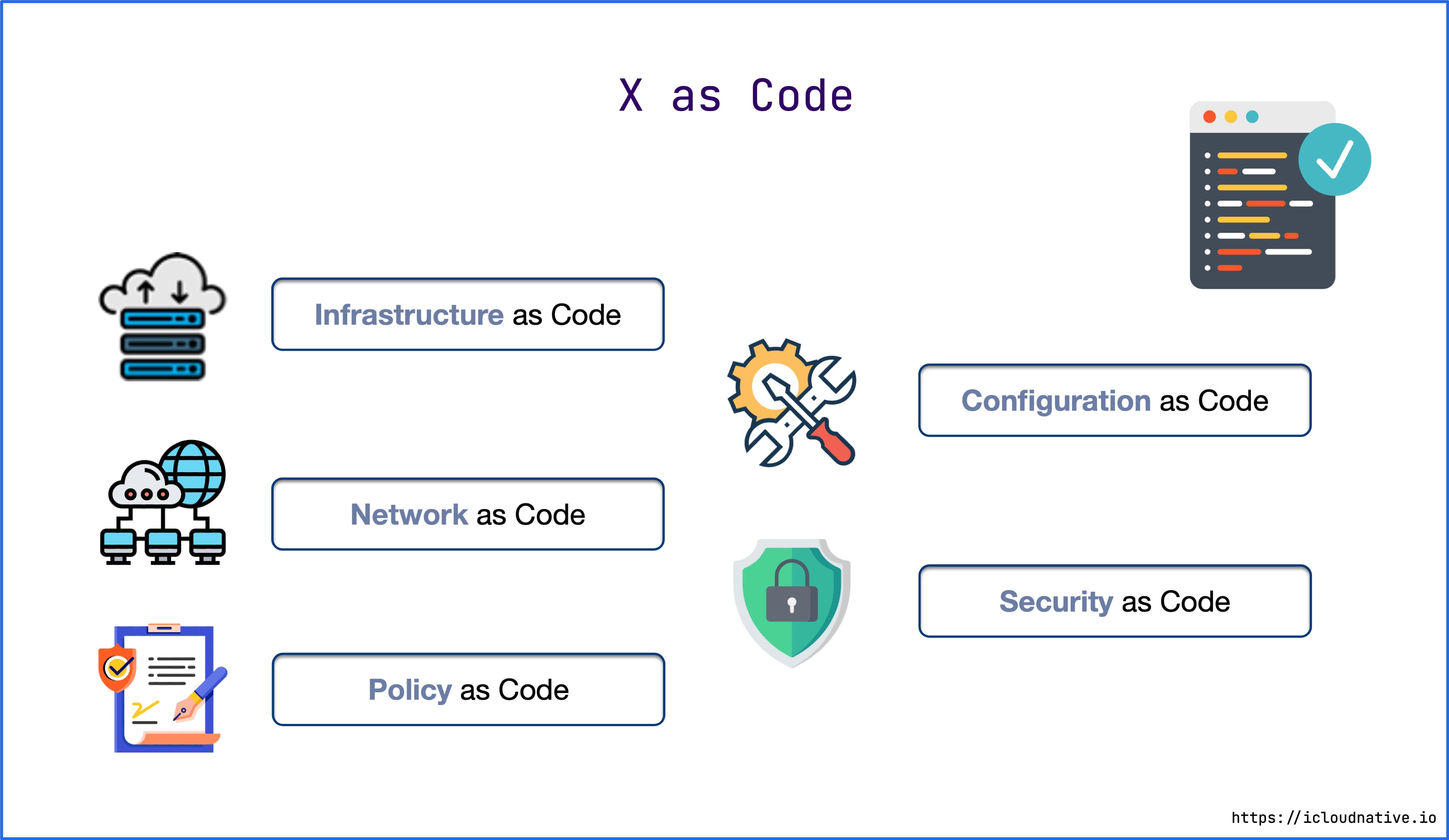
For example, if you want to create servers, configure networks, deploy Kubernetes clusters and various workloads in AWS, all you need to do is define a declarative configuration for Terraform or Ansible and a configuration checklist for Kubernetes, eliminating all the tedious manual work.
What is GitOps
GitOps = IaC + Git + CI/CD, a versioned CI/CD based on IaC. at its core, it uses a Git repository to manage the configuration of your infrastructure and applications, and with the Git repository as the single source of truth for your infrastructure and applications, you can’t change your configuration from anywhere else (like manually changing your online configuration) without going through.
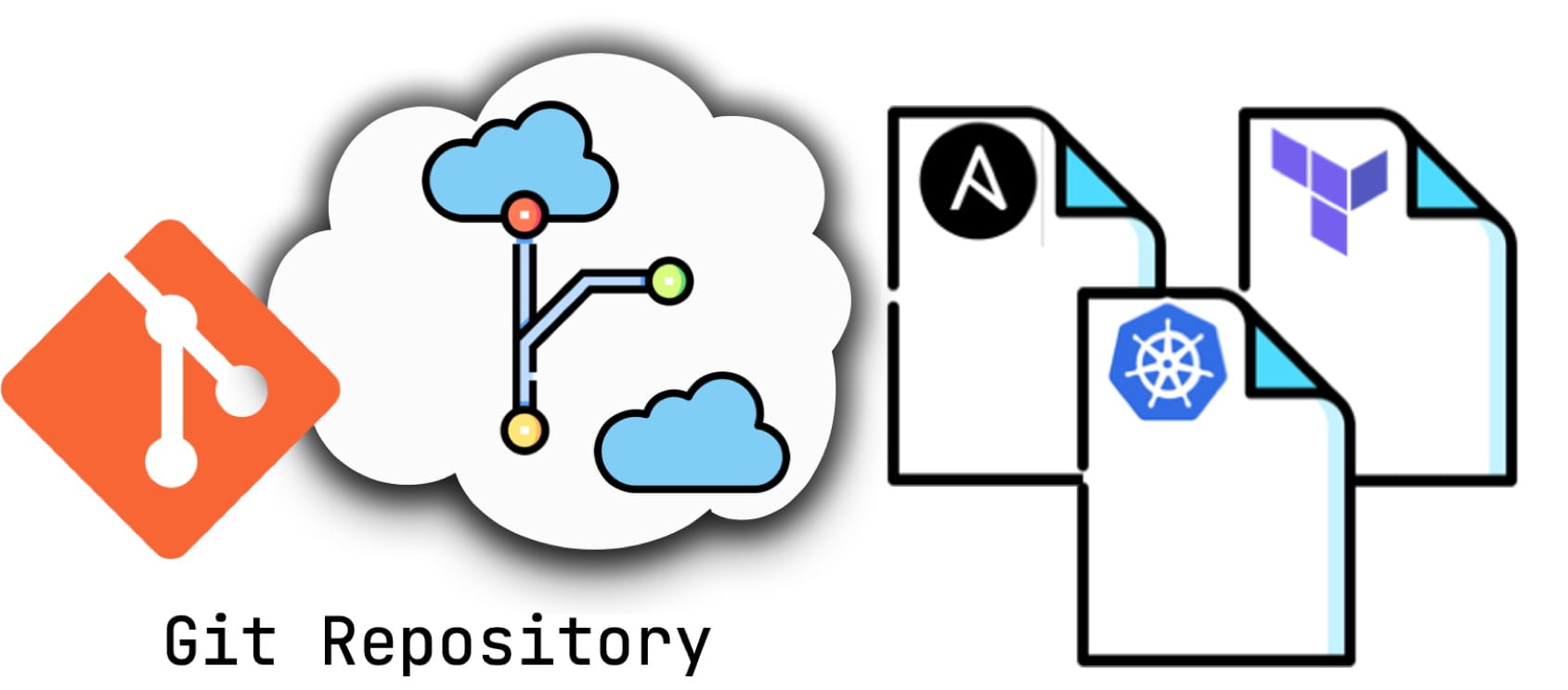
The declarative configuration in the Git repository describes the desired state of the target environment’s current required infrastructure. With GitOps, if the actual state of the cluster does not match the desired state defined in the Git repository, Kubernetes reconcilers adjust the current state based on the desired state, ultimately making the actual state match the desired state.
On the other hand, modern application development is more concerned with iteration speed and scale, and organizations with a mature DevOps culture can deploy code to a generative environment hundreds of times a day, and DevOps teams can do this with best practices like version control, code review, and CI/CD streams for automated testing and deployment, which is what GitOps does.
GitOps vs DevOps
In a broad sense, GitOps and DevOps are not in conflict. GitOps is a technical tool, while DevOps is a culture GitOps is a tool and framework that enables Continuous Delivery, Continuous Deployment, and Infrastructure as Code (IaC), which supports a DevOps culture.
In a narrow sense, GitOps differs from DevOps in several ways.
First, GitOps is goal-oriented. It uses Git to maintain the desired state and continuously adjust the actual state to eventually match the desired state. Whereas DevOps focuses more on best practices that can be universally applied to every process in the enterprise.
Second, GitOps takes a declarative approach to operations, while DevOps accepts both declarative and imperative approaches, so DevOps is applicable to both virtual and bare-metal environments in addition to container environments.
Finally, GitOps redefines CI/CD in cloud-native scenarios with Git as the central immutable state declaration to speed up continuous deployment.
GitOps Design Philosophy
To use GitOps to manage your infrastructure and applications, you need to practice the following principles.
1. declarative
The desired state of the system must be described declaratively. For example, Kubernetes, one of the many modern cloud-native tools that are declarative, is just one of them.
2. Version Control / Immutability
Because all state declarations are stored in the Git repository and use the Git repository as a single source of truth, then all operations are driven from the Git repository and retain a full version history for easy rollback. With Git’s excellent security, you can also use SSH keys to sign commits, enforcing strong security over the authorship and provenance of your code.
3. Automatically Apply Changes
Any changes to the expected state declared in the Git repository can be applied to the system immediately, and there is no need to install and configure additional tools (like kubectl) or configure Kubernetes authentication authorization.
4. Continuous Reconciliation
Reconciliation is a concept that was first introduced in Kubernetes to represent the process of ensuring that the actual state of the system matches the desired state. This is achieved by installing an agent in the target environment, which will automatically repair any mismatch between the actual state and the desired state. The repair here is more advanced than Kubernetes’ fault self-healing, where the cluster is restored to the state described by the manifest in the Git repository, even if the cluster’s orchestration manifest is manually modified.
With these design philosophies in mind, let’s look at the GitOps workflow.
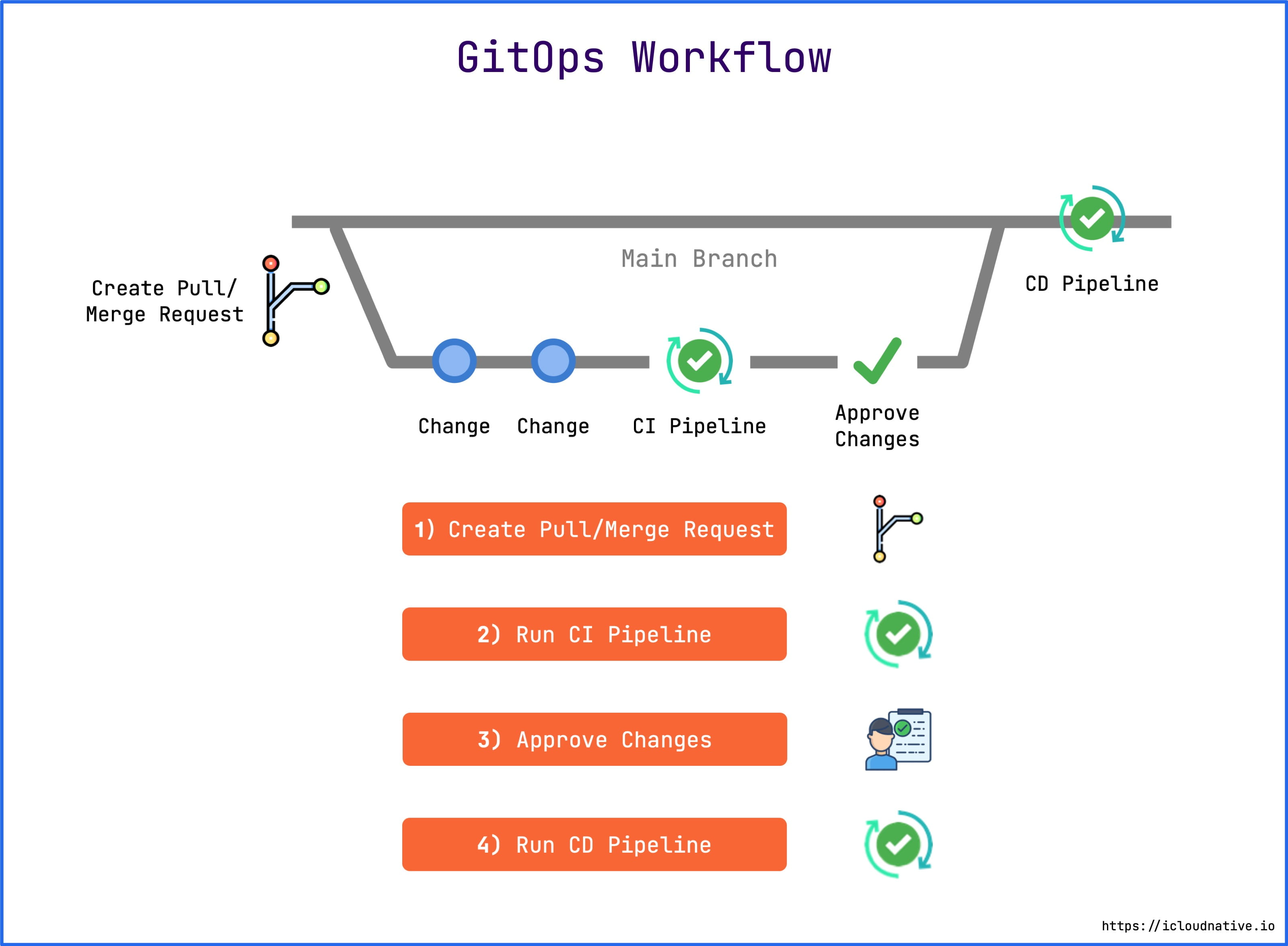
- First, any member of the team can Fork the repository to make changes to the configuration and then submit a Pull Request.
- Next, the CI pipeline will run, typically doing several things: validating the configuration file, executing automated tests, testing the code for complexity, building the OCI image, pushing the image to the mirror repository, and so on.
- Once the CI pipeline is running, the person on the team with the merge code permission will merge the pull request into the master branch. Usually the person with this permission is an R&D person, security expert, or senior operations engineer.
- Finally, a CD pipeline is run to apply the changes to the target system (e.g., Kubernetes cluster or AWS).
The entire process is fully automated and transparent, with multi-person collaboration and automated testing to ensure robustness of the infrastructure statement configuration. The traditional model is that one of the engineers does it all on his or her own computer, and no one else knows what’s going on or can review his or her actions.
Push vs Pull
There are two modes in the CD flowline: Push and Pull.
Push mode
Most CI/CD tools today use a Push-based deployment model, such as Jenkins, CircleCI, and so on. This mode typically executes a command (such as kubectl) to deploy the application to the target environment after the CI pipeline has finished running.
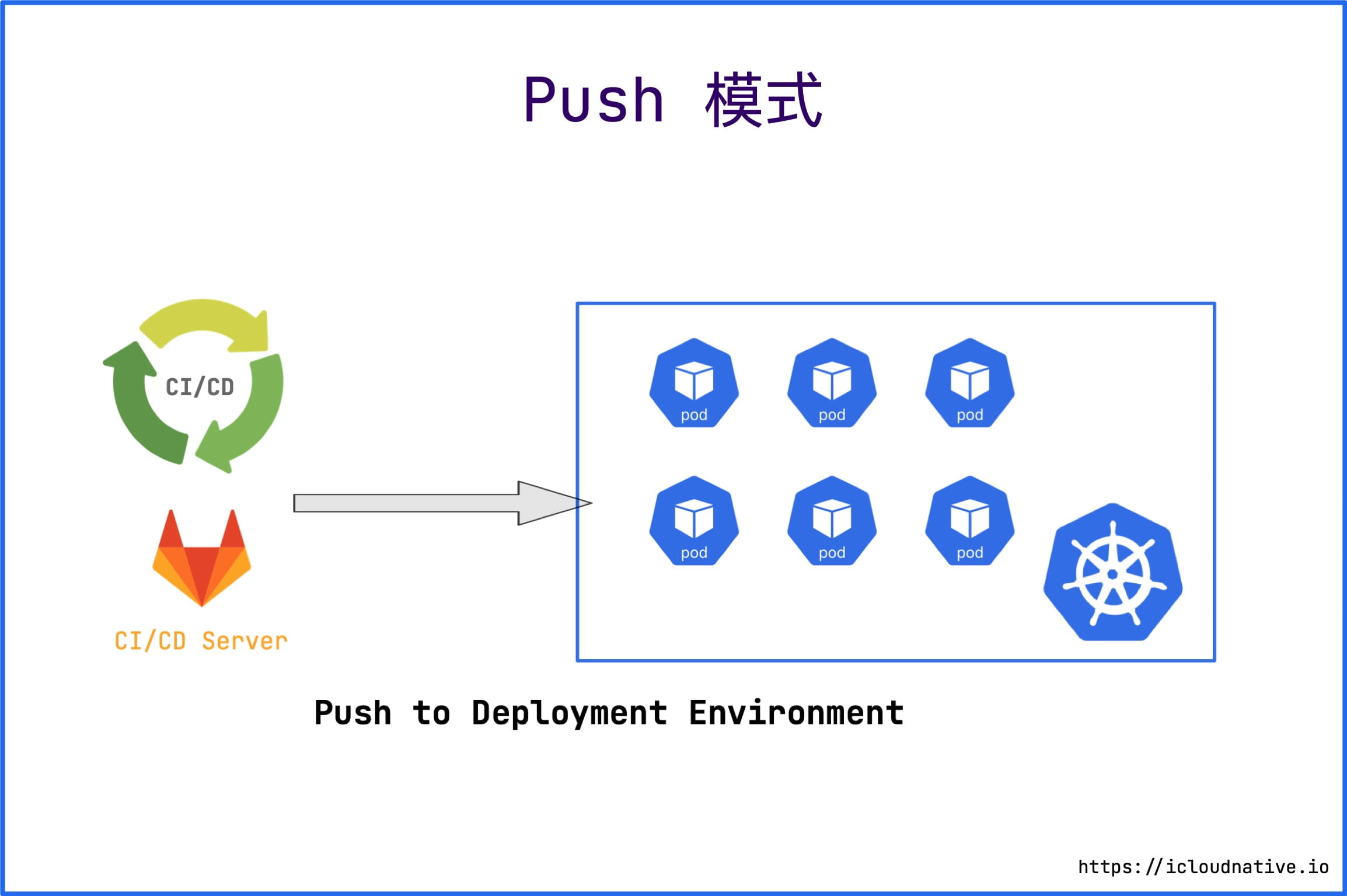
The drawbacks of the CD model are obvious.
- the need to install and configure additional tools (such as kubectl).
- the need for Kubernetes to license it.
- the need for cloud platform authorization.
- Inability to perceive the deployment state. It is also impossible to perceive the deviation of the desired state from the actual state, and requires additional solutions to guarantee consistency.
The authorization credentials of the CI system by the Kubernetes cluster or cloud platform are outside the trust domain of the cluster or cloud platform and are not protected by the security policy of the cluster or cloud platform, so the CI system can be easily used as a vector for illegal attacks.
Pull Mode
Pull mode installs an Agent in the target environment, such as an Operator in a Kubernetes cluster, and periodically monitors the actual state of the target environment and compares it to the desired state in the Git repository. If the actual state does not match the desired state, Operator updates the actual state of the infrastructure to match the desired state.
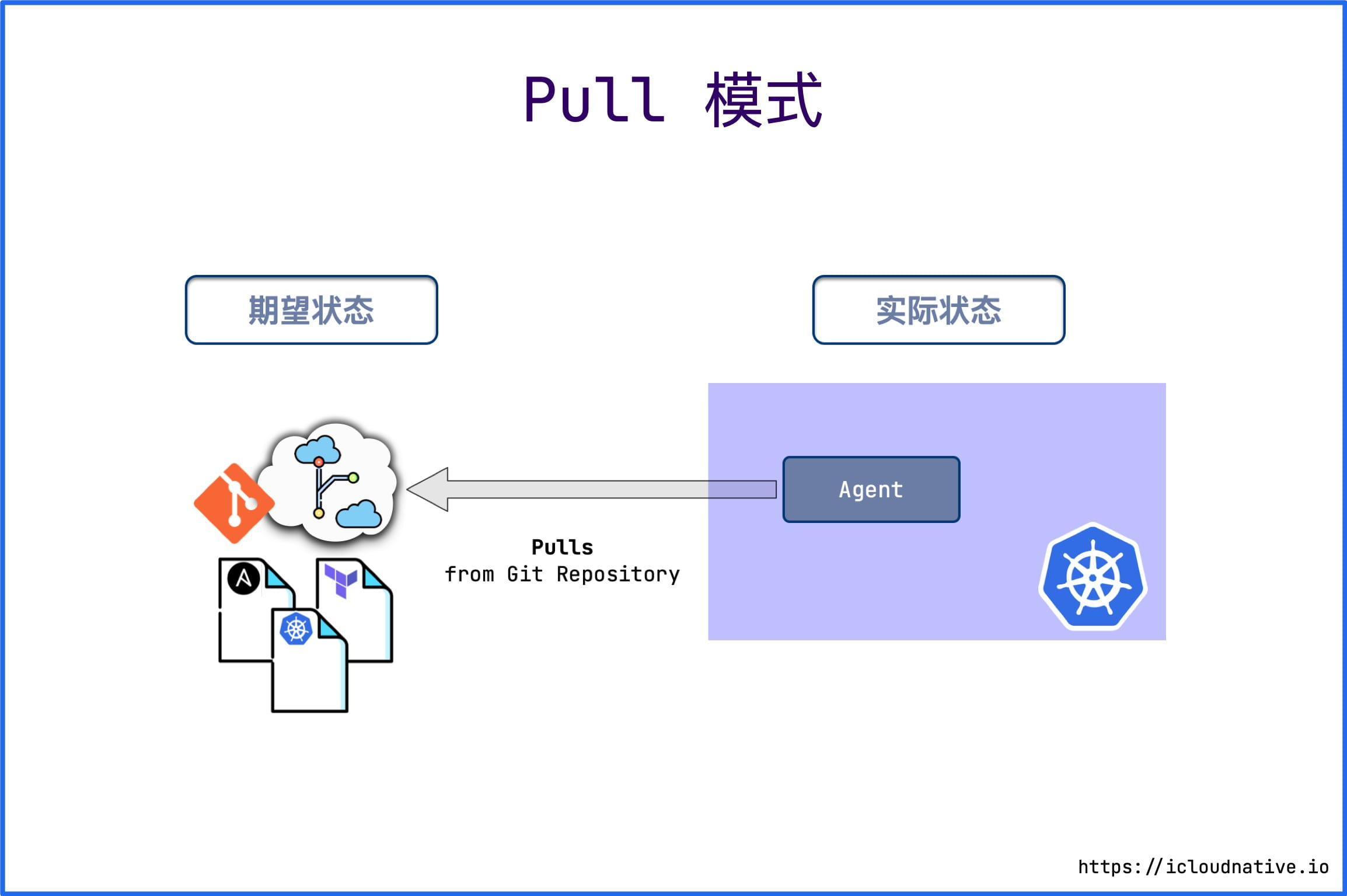
Only Git changes can be used as the only source of desired state; otherwise, no one can make any changes to the cluster, and even if you do, they will be restored to the desired state by the Operator, which is also known as immutable infrastructure.
The current CD tools based on the Pull model are Argo CD, Flux CD, and ks-devops.
Advantages of GitOps
GitOps generally prefers a Pull-based deployment model because it has a number of irreplaceable advantages.
Stronger Security
As mentioned above, using GitOps does not require any Kubernetes or cloud platform credentials to perform a deployment. An Argo CD or Flux CD within a Kubernetes cluster simply accesses the Git repository and updates it via Pull mode.
Git, on the other hand, is backed by strong cryptography for tracking and managing code changes, with the ability to sign changes to prove authorship and provenance, which is key to securing your cluster.
Git as the Single Source of Truth
Because all of the declarative configuration of your application, including your infrastructure, is stored in Git, and you use Git as the only source of truth for your application, you can use the power of Git to manipulate everything, such as version control, history, auditing, rollbacks, and more, without having to use a tool like kubectl to do it.
Increase Productivity
Git is also a tool that developers are very familiar with, and by iterating through Git, you can increase productivity, speed up development and deployment, and get new products out faster, while improving the stability and reliability of your system.
Easier Compliance Auditing
Infrastructure using GitOps can be managed using Git just like any software project, so it can be audited for quality as well. When someone needs to make a change to the infrastructure, a Pull Request is created, and the change can be applied to the system only after a Code Review is performed by the appropriate people.
Summary
GitOps complements the existing DevOps culture by using a version control system like Git to automate the deployment of infrastructure, with clear visibility into the deployment process and the ability to see and track any changes made to the system, improving productivity, security, and compliance. And GitOps provides more elegant observability, allowing you to see the state of your deployment in real time and take action to keep the actual state consistent with the desired state.
And in GitOps, the entire system is described declaratively, which naturally fits into cloud-native environments because Kubernetes is designed to do the same.