As we know, inside the computer, in order to convert binary data to the display, it is necessary to encode, that is, the displayable characters correspond to the binary data one by one, such as ASCII code, which is a Byte of data to represent the English characters plus some English symbols.
As for Chinese, we obviously can not use just one Byte to represent, we need to use a larger space.
Unicode and Code point
In today’s small world village, with so many languages and scripts, Unicode emerged to be compatible with all characters, but it needed more Bytes to include all the characters in the world (this even includes Emoji).
In order to understand Unicode, you need to understand the Code point, which is a 4 Byte size number that represents all characters.
As for Unicode itself, you can think of it as a collection of Code points, and what about UTF-8? That’s the way Unicode is encoded.
Unicode and UTF-8 encoding
The following diagram is a screenshot from UTF-8.
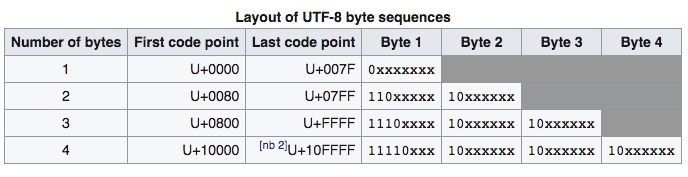
This diagram tells us simply and clearly that the encoding of UTF-8, such as Chinese characters generally use three Byte, the beginning of each Byte is fixed, a variety of text software parsing UTF-8 encoding, it will follow this format to parse, once the parsing error (after all, there may still be data that does not meet the requirements, or the file is wrong), the wrong byte will be replaced with "�" (U+FFFD), and here comes the magic: even if it encounters such an error, it will not affect the parsing of the rest of the characters, because this encoding does not have to start from scratch, making it Self-synchronizing. At the same time, some other encodings have problems when they encounter an incorrect encoding, causing the incorrect encoding to be followed by the correct encoding.
Of course, UTF-8 has its drawbacks, as it is variable, it saves space when there are more English characters, but when there are more Chinese characters, for example, it will theoretically (3 Byte) take up to 1/3 more storage space than GBK (2 Byte).
Example of UTF-8
Let’s take the most popular Emoji in Unicode 😂 as an example: its code point is U+1F602 (yes, 1F602 is in hexadecimal), but in memory it’s is stored in memory as 0xf09f9882, why? This is the UTF-8 encoding (note the comparison of the above encoding).
By extracting the data from the UTF-8 encoding grid, we can get the Code point 1F602.
You can also use Golang to see the encoding of other characters.
Other encodings of Unicode
Of course, Unicode has more than one encoding, there are also UTF-16, UTF-32, etc. Their relationship is that UTF-16 uses 2 Byte to represent UTF-8 characters with 1/2/3 Byte respectively, and then 4 Byte is consistent with UTF-8, UTF-32 uses 4 Byte to represent all characters completely, in addition, the detailed You can see the details in Comparison of Unicode encodings.
OK, we’re done with the basics, now let’s start the formal introduction.
Unicode and Golang
The relationship between Golang and UTF-8 is particularly important here. The men behind them are Ken Thompson and Rob Pike, so you can see how important Golang’s UTF-8 design is as a reference. For example, Golang designed a rune type to replace the meaning of Code point.
rune is int32, which is exactly 4 Byte, and can just be used to represent all Unicode encodings UTF-8 and UTF-16.
Before we continue, I want to help you understand the fact that Golang’s source code is UTF-8 encoded by default, as you can see from the example I gave above, so the emoji character is already parsed when it’s compiled.
Okay, so let’s take a look at Golang’s unicode package, which will have a lot of useful judgment functions.
|
|
In addition, in src/unicode/tables.go, there are a lot of Code point intervals for various characters in Unicode, which will be of great reference value.
Look at the unicode/utf8 package, which contains functions that you won’t use most of the time, but there are several types of situations where you have to use them.
- counting the number of characters.
- encoding conversion, such as GBK to UTF-8.
- determining whether a string is UTF-8 encoded or contains characters that are not UTF-8 encoded.
The last two can be ignored, the first needs special reminder.
What is the output of this sentence? As mentioned above, it’s exactly 4. So you can’t use len to get the number of characters, and you can’t use that to determine if the user has entered more characters than the system limit. Also, you can’t use s[0] to get the characters, because you can only get the first of the 4 Bytes, which is 0xf0.
What you should do is convert the string to a rune array and then go back to the character manipulation.
I’m not going to go into the details of how to use it, but I’m sure you can handle it.
Also, here is another hint: in Node.js, string itself is Unicode, not binary like Golang’s string, so you can think of Node.js Buffer as Golang’s string.
Well, I’ll leave you with one last thought: why can’t you just splice in Node.js when dealing with Buffer?