fork is the most widely used process creation mechanism, where a process can create several new processes, the former called parent processes and the latter called child processes, through the system call fork. In order to reduce the process creation overhead, modern operating systems use copy-on-write techniques, where the parent and child processes share the same memory space, thus enabling a “copy” of the data, which will be analyzed in this article.

Overview
Every process in the operating system has a parent process, and all processes form a tree structure. When the system starts, an init process is created (with ID 1), and all other processes are created by the init process through fork. init process has its own parent, and if a process ends before its children, then its children will be adopted by the init process and become direct children of the direct child of the init process.
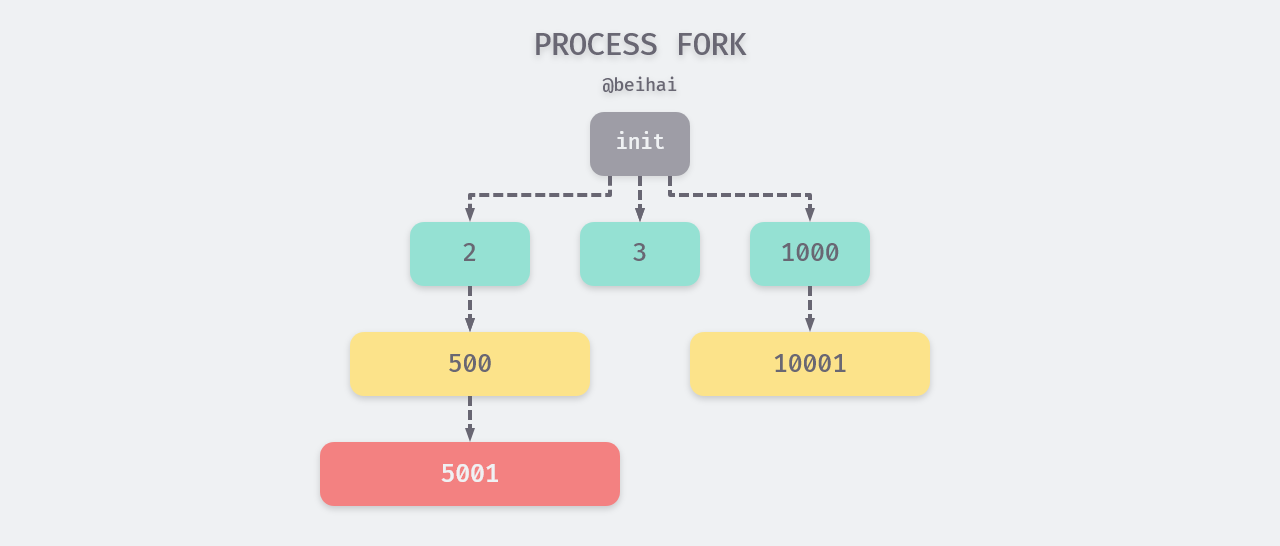
An existing process can create a new child process by using the fork function. When the fork method is called, it returns two values, which we can use to determine the parent and child processes and perform different actions.
- the
forkfunction returns 0, meaning that the current process is a child process. - When the
forkfunction returns greater than 0, it means that the current process is the parent process and the return value is thepidof the child process.
|
|
fork flow
Memory layout
When a process is created, the system kernel allocates virtual memory space for the process. The kernel divides the virtual memory into user space and kernel space, with the user space occupying the lower part of the address, size 0 to TASK_SIZE, and the remaining part being the kernel space. The division is shown in the figure below.
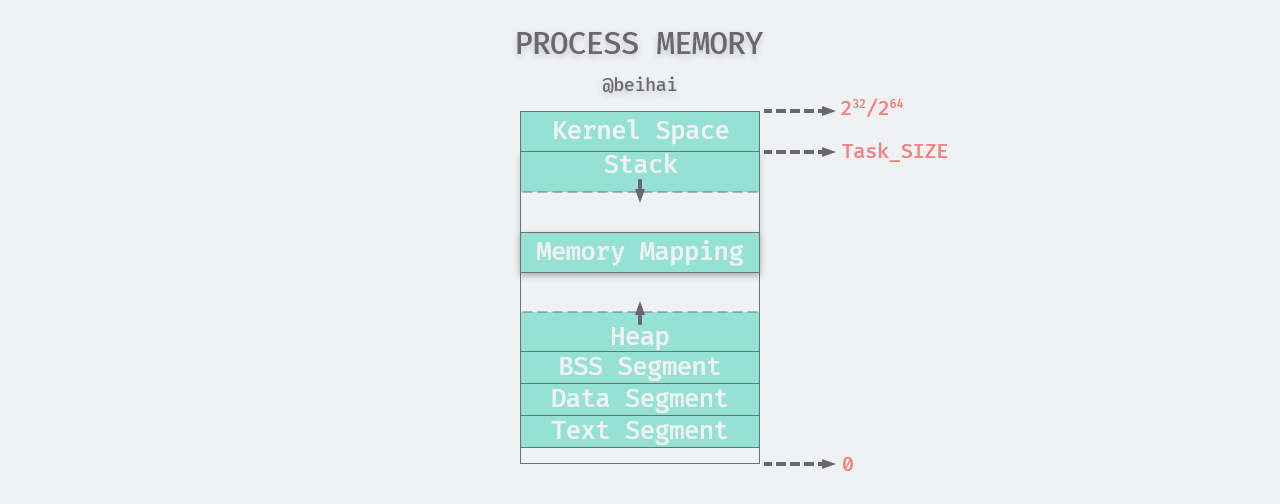
The user space memory areas from low address to high address are arranged as follows
- program segment (Text): the part of the program instruction executed by the CPU, which is normally read-only for the security of the program; the program segment can be shared by parent and child processes.
- initialized data segment (Data): the part of the variable that has been explicitly assigned a value before the program is executed.
- uninitialized data segment (BSS): data for which variables are not initialized before program execution; the kernel defines this data segment as 0 or empty.
- runtime heap (Heap): stores dynamic memory allocations that need to be manually allocated and freed by the programmer, with the heap area growing from low to high addresses.
- memory mapping segment (Memory Mapping): memory mapping file area, load dynamic link library, file descriptors, etc., can be extended to high/low addresses.
- runtime stack (Stack): stores local, temporary variables, return pointers to functions, etc., and is used to control function calls and returns. Memory is automatically allocated at the beginning of the block and automatically freed at the end, and the stack area grows from high to low addresses.
When fork occurs the child process copies the memory data of the parent process, and the child process is almost a complete copy of the parent process, getting a copy of the parent’s data segments, heap and stack. The memory space of both processes has almost identical contents.
But on the other hand, after calling fork, the parent and child processes will run in separate memory spaces, writing and modifying memory, and mapping files are independent, and the processes will not affect each other.
System call exec
When the fork function creates a new child process, the child process will often call another system call function: exec. The exec function will load and replace the Text and Data segments of the calling process from the program file, reinitialize the BSS segment, etc. This will cause the memory data copied during fork to be overwritten again, wasting resources for nothing.
exec is the collective name for a series of execxxx() functions, see wiki
When a process calls the exec function, the source process program is completely replaced by the new program, which starts execution from its main function. Because calling exec does not create a new process, the process IDs before and after do not change. exec simply replaces the body, data, heap, and stack segments of the current process with another new program. In particular, file descriptors that were already open in the original process will remain open in the new process, unless their “close on execution flag” is set.
In fact, the new program inherits many properties of the calling process, some of which are listed below.
- Process ID, parent process ID, process group ID
- Actual user ID and actual group ID
- Current working directory
- File lock
- ······
Copy-on-write
Now we understand that the process copies almost all the data of the parent process when fork creates a child process, which may lead to a very inefficient process creation; in addition, the child process usually loads a new program to overwrite the copied data segments, stack, etc., which makes all the previously copied data wasted; even if the exec function is not executed, the large amount of memory data copied from the parent process may have no meaning for the child process.
As an alternative, the kernel uses Copy-On-Write technology for fork. The main function of Copy-On-Write is to delay copying until the write operation actually occurs, which avoids a lot of pointless copying. In most operating systems today, fork does not immediately copy the memory space of the parent process, but takes advantage of sharing the same physical memory.
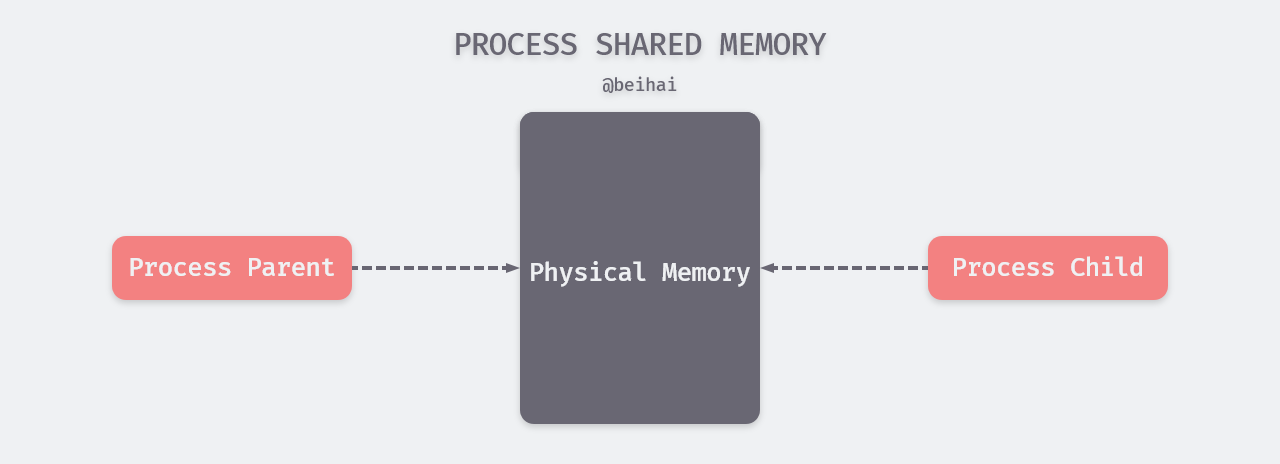
When the fork function is called, the parent process and the child process are allocated different virtual memory spaces by the kernel, so from the process perspective they access different memory.
- When a read operation is performed in the virtual memory space, the kernel maps the virtual memory to physical memory and the parent and child processes share the physical memory space.
- When the parent process makes changes to the shared memory, the shared memory is copied on a page-by-page basis and the parent process makes changes to the original physical space, while the child process uses the new physical space after the copy.
- When a child process makes a modification to the shared memory, the child process will make the modification on the new physical space after the copy without altering the original physical space to avoid affecting the memory space of the parent process.
Write-time replication reduces the overhead of unnecessary physical memory, makes process creation very fast, and provides a good idea of shared memory usage. It is useful in some application scenarios such as in-memory database and big data analysis.
Summary
Back to the topic, why is the write-time copy technique used in fork?
- A large amount of memory data needs to be copied during
fork. - The copied data may not be of any use to the child process.
- If the child process calls
execit also overwrites the copied data. - If the parent process takes up a lot of physical memory resources, the remaining memory space may not be sufficient for the child process.
However, the copy-on-write technique also has some disadvantages. If the parent and child processes perform frequent write operations, a large number of paging errors (page-fault exceptions) may be generated, which will not be worth the cost. Therefore, when using write-time replication, pay special attention to whether the demand is to write more and read less or write less and read more, and choose the appropriate application scenario.
Reference
https://draveness.me/whys-the-design-redis-bgsave-forkhttps://blog.csdn.net/wangxiaolong_china/article/details/6844325https://www.yanbinghu.com/2019/08/11/28423.htmlhttps://wingsxdu.com/posts/linux/concurrency-oriented-programming/fork-and-cow/