Interaction inside concurrent programs
Why should we consider the problem of synchronization? In many cases, we need multiple processes or threads to cooperate with each other to complete a task, and multiple serial programs may all have to access a shared resource, or pass some data to each other. In this case, we need to coordinate the execution of the programs. The role of synchronization is to avoid possible conflicts during concurrent access to shared resources, as well as to ensure the orderly passing of information.

According to the principle of synchronization, if a program wants to use a shared resource, it must first request the resource and obtain access to it. When a program no longer needs a resource, it needs to give up access to it (release the resource). At the same time, a resource should be occupied by only one program, and a program’s request for a resource should not cause other programs that are accessing the resource to interrupt, but should wait until the occupying program releases the resource before requesting it.
Data transfer is also known as communication within a concurrent program, and in addition to synchronization, we can also manage communication using asynchronous, which allows data to be sent to the data recipient without delay. If the data recipient is not ready to receive the data, it does not cause the data recipient to wait and the data is temporarily stored in the communication cache. The communication cache is a special shared resource that can be used by multiple programs at the same time, and the data receiver can receive it when it is ready by organizing the queue according to the FIFO.
Synchronization issues
Whether it’s multiple CPUs, multiple processes or multiple threads, as long as there is data sharing between them, synchronization issues are bound to be involved.
Counters
To get a better idea of the synchronization problem, let’s illustrate it with a counter example. Suppose that thread A creates a counter Count with an initial value of 1, which is shared with thread B. Thread A and B perform the same task concurrently: query the database for the eligible data and write it to . /temp file. The task flow is roughly as follows.
- read the value from the counter.
- query 10,000 pieces of data from the database at a time, if a is used to represent the counter value, then the query range is: [a, a+10000).
- iterate through the query data and compose a new data set of the data that meet the conditions
- write the data set to the . /temp file.
- add 10000 to the value of the counter, i.e. c = c+10000.
- check whether all the data is read, if so, the program exits, otherwise repeat the above steps.
Note: Assuming the above example is running on a single logical processor, thread scheduling may be slightly different for multi-core processors.
Threads A and B repeat the six steps above each time they migrate the specified data set. However, since the kernel switches and schedules threads, in practice, threads A and B may be executed interleaved and at a much smaller granularity than the steps described above for context switching. However, for the sake of clarity, we can assume a possible thread scheduling process.
- the kernel makes the CPU run thread A, initializing the counter.
- thread A reads the initial value of the counter 1.
- the CPU is seized by thread B, which reads counter initial value 1 and filters the data according to this query to get a new set of data, at which point the kernel assumes that thread B has run long enough to switch A to the CPU.
- thread A starts querying and filtering data to obtain a data set that is identical to thread B.
- thread A writes the data set to the . /temp file. 6.
- thread A updates the counter value to 10001.
- the kernel replaces thread A and lets the CPU run B. 8.
- thread B writes the data set to . /temp file.
- thread B updates the counter to 10001.
The scheduling process is shown in the following diagram.
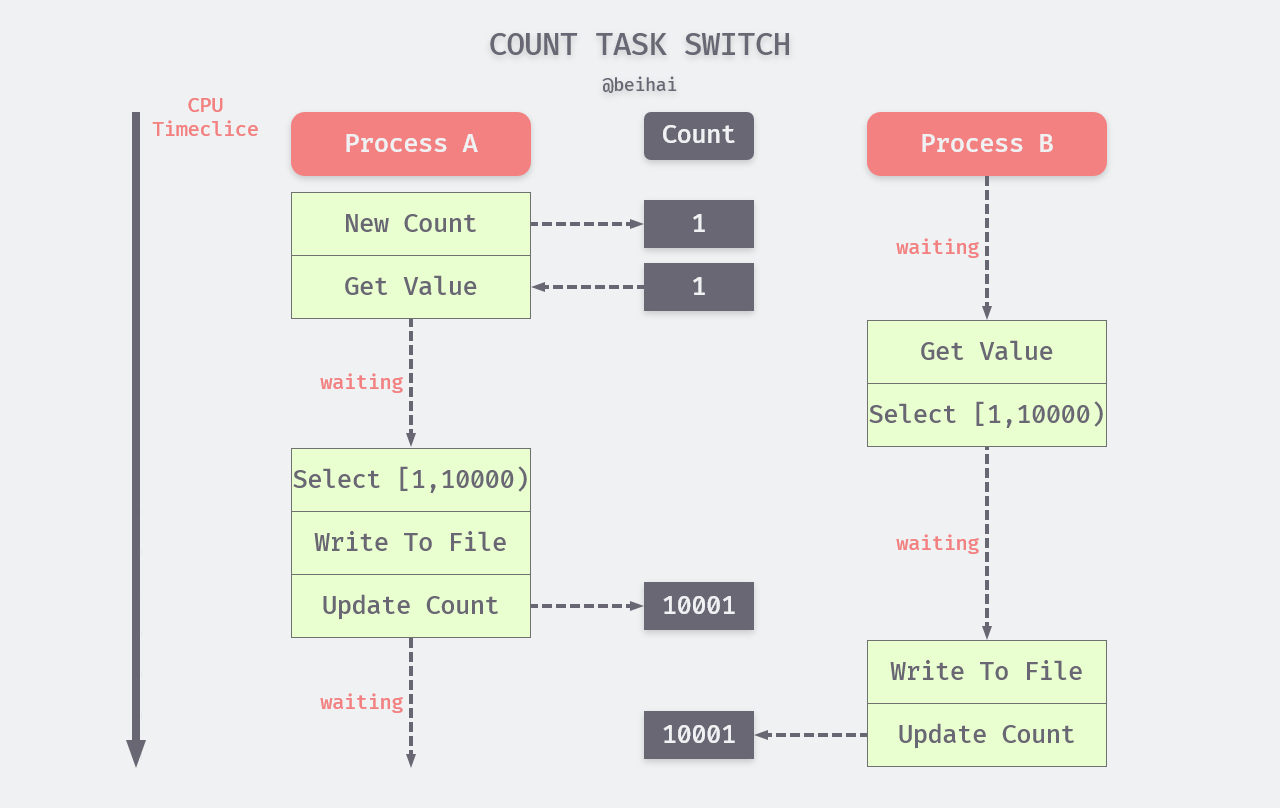
The example diagram shows an obvious problem where threads A and B are doing duplicate things, resulting in double the resource consumption while getting the same result. This is due to the fact that the access time span of the counter value by the same thread is too large, and the counter only achieves the purpose of recording the task progress without task coordination for multiple threads, resulting in a completely random execution process for the threads.
If we improve the counter by moving the fifth step in the process to after the first step, i.e., update the counter immediately after fetching the counter value. This does have a significant effect and greatly reduces the probability of the “half-measure” problem, but it still does not solve the problem completely. There is still the possibility that the CPU will switch the thread before the counter value is updated.
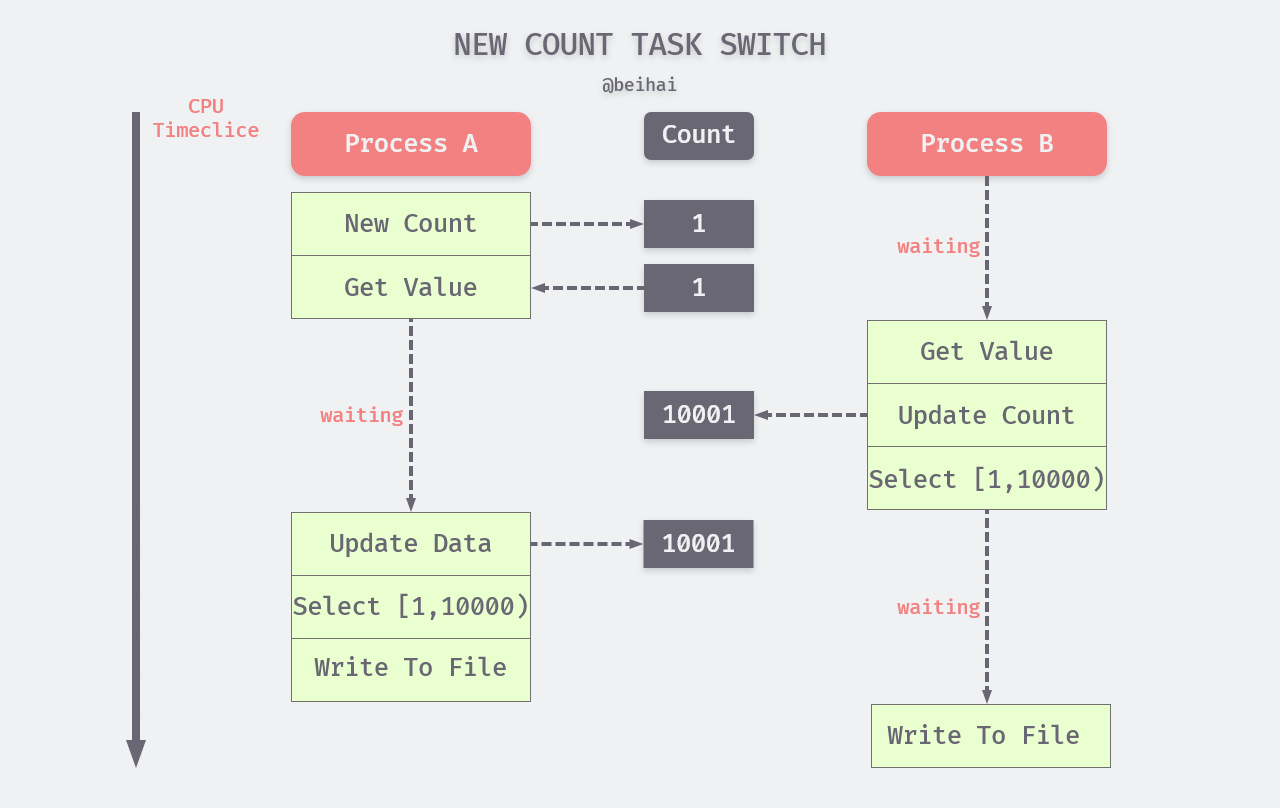
Atomic operations and critical areas
In concurrent programming, multiple threads accessing the same resource may interfere with each other, a situation known as a contention condition. The root cause of a contention condition is that a thread is interrupted in the middle of some operation, and although the thread will resume its state as before when it runs again, the external environment may have changed in the intervening time. In the improved counter example, the uncontrollable nature of thread scheduling makes it possible for a race condition to occur, although it has been avoided as much as possible. To solve this problem, we introduce the concepts of atomic operations and critical zones.
Atomic operation means “an operation or series of operations that cannot be interrupted during execution”. Atomic operations must be represented by a single assembly instruction and need to be supported at the chip level, so they are the most fine-grained synchronous operations for interacting with data between threads, and they guarantee atomicity and absolute concurrency safety for reading and writing a value between threads. Atomic operations perform only the most basic functions, of which there are five: increment or decrement, compare and swap, load, store, and swap .
It is more general to have several threads of code executing serially form a critical zone than an atomic operation. A critical zone allows access to a shared resource by only one thread at any given moment. If more than one thread tries to access the critical zone at the same time, all other threads that try to access the critical zone after one thread enters will be hung and will continue until the thread that entered the critical zone leaves. After the critical zone is released, other threads can continue to seize it, thus achieving the goal of operating on shared resources in a pseudo-atomic manner. Atomic operations look similar to critical zones, but atomic operations cannot be interrupted, while critical zones are not enforced to be interrupted, as long as no other visitors are allowed to enter while a visitor is in the critical zone.
Common synchronization methods for critical zones are mutual exclusions and conditional variables.
Mutual exclusion
A mutex is essentially a lock that is placed on a shared resource before it is accessed, and released when the access is complete. After we lock the mutex, any other thread that tries to lock the mutex again will be blocked until the current thread releases the mutex. If more than one thread blocks while releasing the mutex, then all the threads that tried to lock the mutex before become runnable, and when the first thread that becomes runnable locks the mutex, the other threads can only block again. In this way, only one thread at a time can execute the code in the critical zone.
Mutual Exclusion Locks
A mutually exclusive lock is a sleep-waiting type of lock. For example, on a dual-core machine there are two threads (thread A and thread B) running on Core0 and Core1 respectively. Suppose Thread A wants to get a lock on a critical zone through a mutual exclusion lock operation, and the lock is being held by Thread B, then Thread A will be blocked. If the mutually exclusive lock does not get a lock, Thread A will go to sleep and Core0 will perform a context switch to put Thread A in the wait queue, so that Core0 can run other tasks (e.g. Thread C) without having to wait.
Spin Lock
A spinlock is a busy-waiting type of lock. If thread A uses a spinlock operation to request a lock, then thread A will stay busy waiting on Core0, repeatedly checking the lock with lock requests until it gets the lock. As you can imagine, when a processor is in a spin state, it cannot do any useful work, so spin locks do not make sense for single-processor non-preemptible kernels. Spin locks are mainly used in cases where the critical area locking time is very short and CPU resources are not strained, while mutual exclusion locks are used for operations where the critical area locking time is longer.
Read-Write Locks
A read-write lock is a special kind of spinlock that divides the visitors to a shared resource into readers and writers; readers can only read access to the shared resource, and writers need to write to the shared resource. This locking phase improves concurrency for spin locks because it allows multiple readers to access the shared resource at the same time in a multiprocessor system, with the maximum possible number of readers being the actual number of logical CPUs. Writers, on the other hand, are exclusive, and a read/write lock can have only one writer or multiple readers at the same time (related to the number of CPUs), nor can it have both readers and writers at the same time.
Deadlock
If a concurrent task contains more than one critical zone, for example, thread A holds exclusive lock a and tries to get exclusive lock b, while thread B holds exclusive lock b and tries to get exclusive lock a, a deadlock will occur between threads A and B because they hold the locks needed by each other, and threads A and B will block indefinitely.
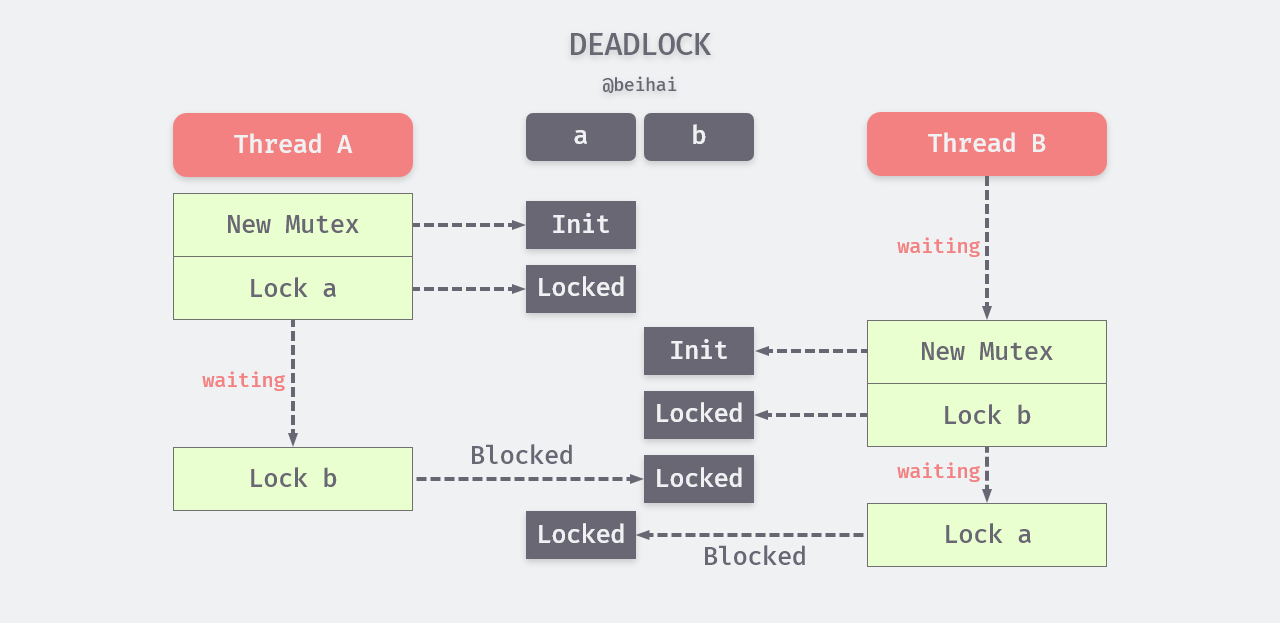
There are two common ways to solve deadlocks, one is fixed locking order , which locks a before locking b. While this is effective in avoiding deadlocks, it is not possible in all cases. The other way is try-lock-back, which actively releases the first locked resource when the thread fails to try to acquire the second exclusive lock.
Conditional Variables
Conditional variables are a common way to implement “wait-wake” logic in multi-threaded programs. Conditional variables are a mechanism to synchronize global variables shared between threads, and consist of two main actions: one thread waits for the “condition of the conditional variable to hold” and hangs; the other thread makes the “condition hold”. For example, Thread A needs to wait for a condition to hold before it can continue its execution. If the condition does not hold, Thread A will call the system call function pthread_cond_wait to put itself in the list of waiting threads. When Thread B makes this condition hold during execution, it wakes up Thread A to continue execution.
A condition variable is a notification mechanism that wakes up other threads to perform a task when the condition holds, either by a single system call to pthread_cond_singal or by a pthread_cond_broadcast broadcast. However, POSIX allows pthread_cond_singal to wake up more than one thread in order to simplify the implementation.
Conditional variables are usually used in conjunction with mutually exclusive locks. This is to deal with the situation where thread A wakes up thread B before it has called pthread_cond_wait but has not yet entered the wait cond state. If a mutex lock is not used, this wakeup signal will be lost. When a lock is added, thread A is unlocked after it enters the wait state, and thread B can only wake up after that.
Summary
Synchronization is a solution to the problem of “interference” that can occur during data sharing, often through (pseudo) atomic operations or locking. These traditional solutions have different scenarios and should be used with care, following the principle of using simple operations whenever possible.
Reference
https://www.jianshu.com/p/01ad36b91d39https://wingsxdu.com/posts/linux/concurrency-oriented-programming/synchronous/