Go is a compiled language, and the *.go text files we write are called source files, and the contents of the source files are our source code.
For the source code to run on the target machine, it must be compiled into a binary machine code file, or executable, that is directly recognized by the operating system using the Go compiler (abbreviated gc, which stands for Go compiler). The operating system then loads the file and runs the machine code directly on the CPU. This is the main reason why compiled languages run so efficiently.
What is the Go compiler implemented with
The compiler itself is a program, and its role is to translate a program written in one language (the source language) into the equivalent program written in another language (the target language).
And the compiler, the program itself, is written without relation to the programming language; any Turing-complete language can write a compiler for any formal language.
The first Go compilers (Go 1.4 and earlier) were written in both C and assembly, and in 2015 Google began announcing plans to implement Go 1.5 bootstrapping.
This implementation of the source language compiler in the source language itself is called bootstrapping. So the Go compiler from Go 1.5 onwards is implemented in the Go language itself.
The structure of a compiler
If we open the black box that is the compiler a little bit, the components of the compiler can be divided into Front End and Back End, depending on the task to be performed.
The front end of the compiler is responsible for the analysis part, which breaks down the source program into its constituent elements and adds a syntax structure on top of them, then uses this structure to create an intermediate representation of the source program, and finally stores the information of the source program in a data structure called a symbol table and passes it along with the intermediate representation to the synthesis part.
As you can see, if we write a piece of code with a syntax error, it will be intercepted on the front end and given a hint. This is a bit similar to the parameter checking part of our web development.
After the front-end is finished, the back-end is compiled, and the back-end takes care of the synthesis part, constructing the target program that the user expects based on the intermediate representation and the information in the symbol table sent from the front-end.
Between the compilation front-end and the back-end, there are often several optional, machine-independent optimization steps that further optimize the intermediate representation so that the subsequent back-end can generate a better target program.
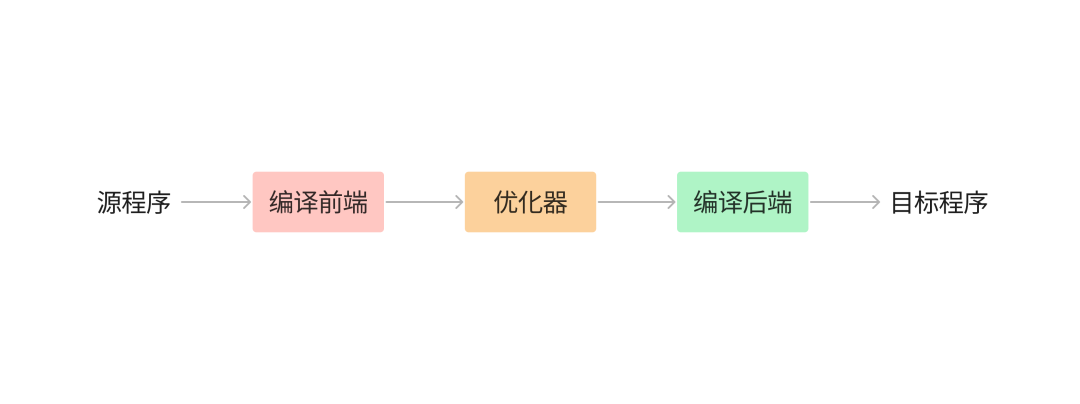
Multi-stage process for Go compiler
Take the latest stable version of Go 1.18.4 as an example, the source code of Go compiler is located at: https://github.com/golang/go/tree/go1.18.4/src/cmd/compile
All subsequent code examples and source code references are also based on this version.
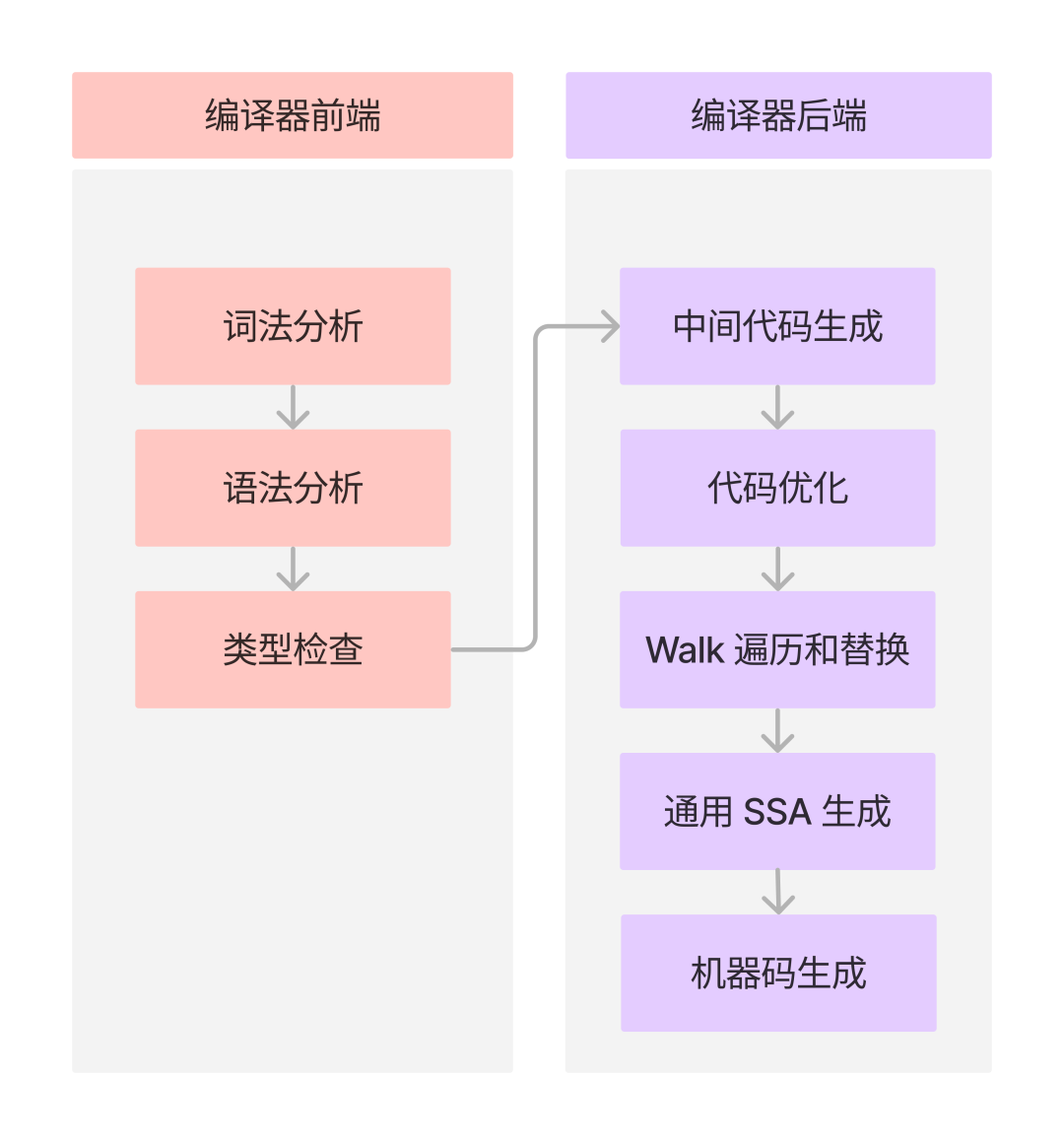
By applying the structure of the compiler to the Go compiler, we can also divide the Go compiler stages into a compiler front-end and a compiler back-end (the optimizer part is also placed in the compiler back-end).
The front-end of Go compiler includes lexical analysis, syntax analysis, and type checking.
The back-end includes: intermediate code generation, code optimization, Walk traversal and replacement, generic SSA generation, and machine code generation.
Lexical analysis
The first step of the compiler is called lexical analysis or scanning. The corresponding source code is located at cmd/compile/internal/syntax/scanner.go. This translates our source code into the lexical unit token.
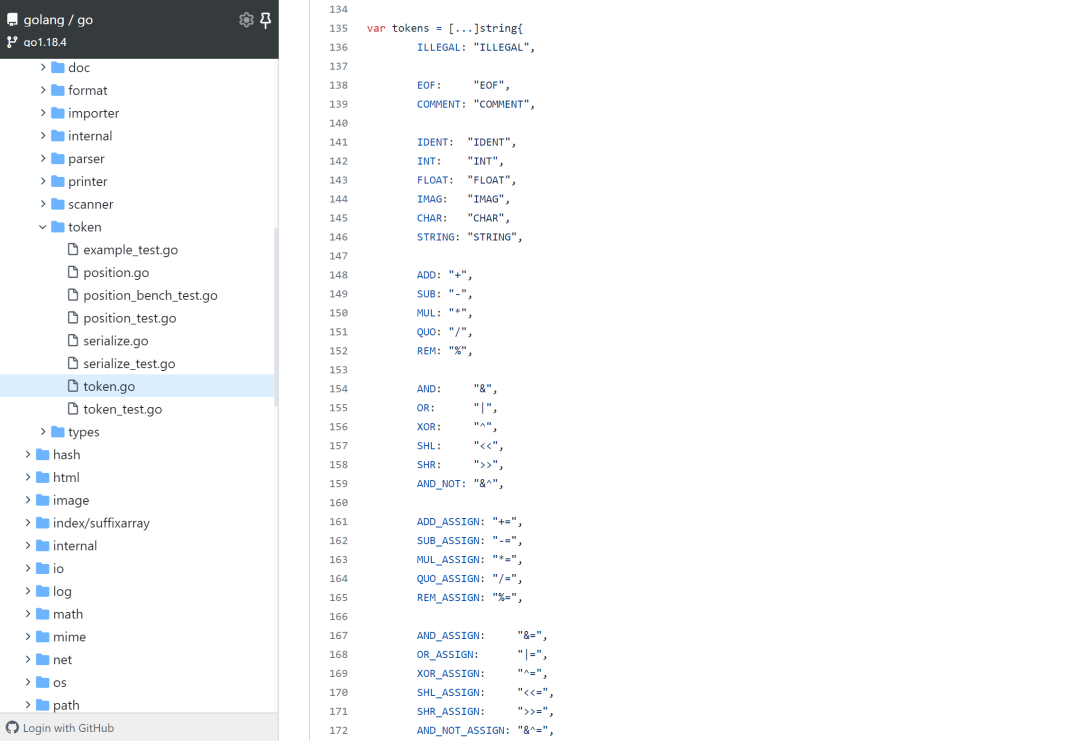
The token is defined in go/token/token.go as an enumerated value, essentially an integer declared in iota, which has the advantage of being processed more efficiently in subsequent operations.
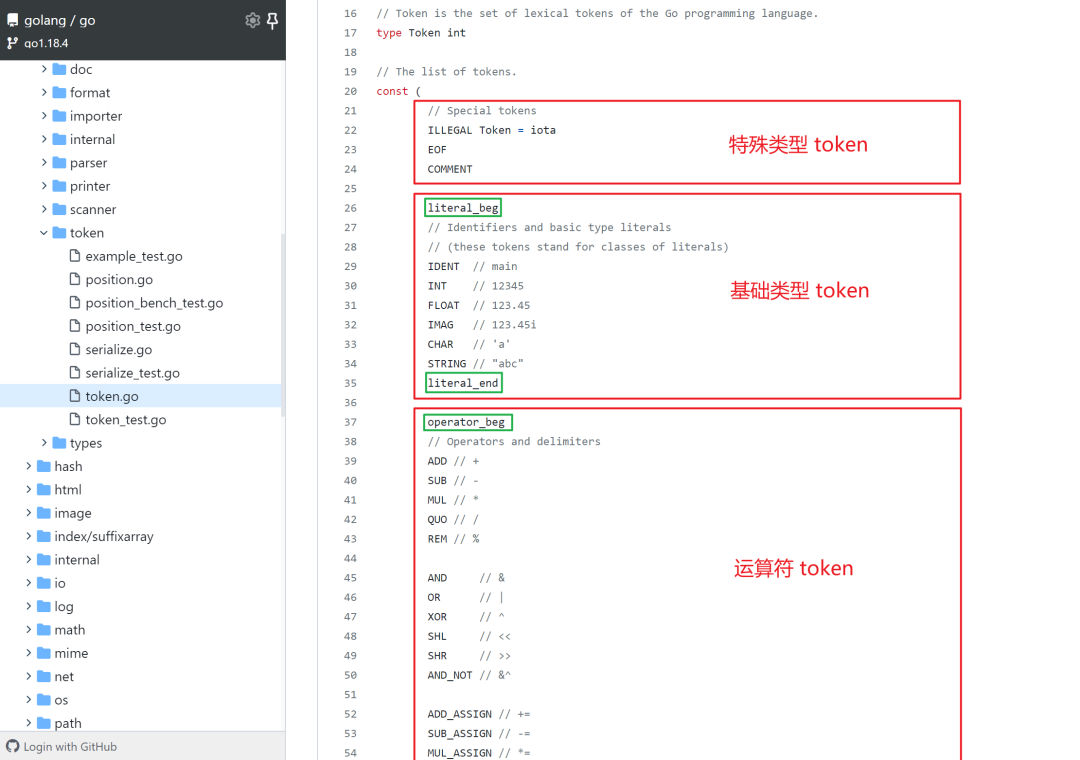
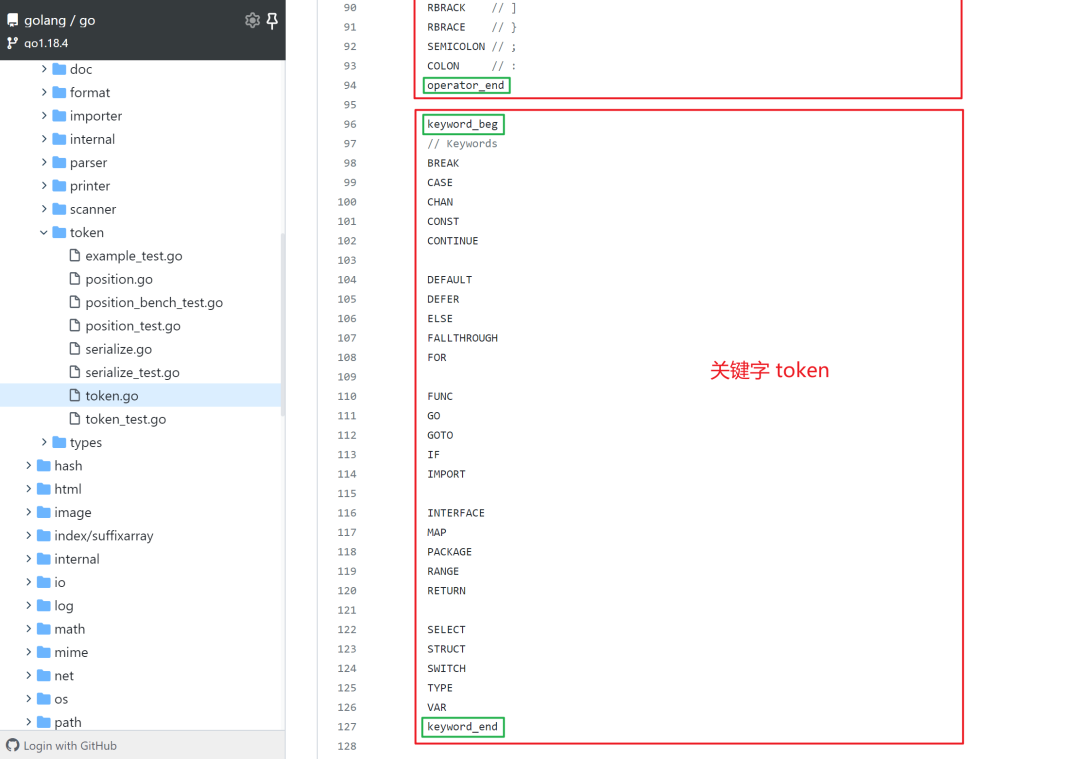
All tokens are divided into four main categories: special types, base types, operators, and keywords.
If there is a lexical error, ILLEGAL is returned uniformly to simplify the error handling during lexical analysis.
The private constants suffixed with _beg and _end are used to indicate the range of the token’s value.
Finally, all tokens are put into a var tokens = [...] string array, which maps a subscript (token value) to the token face value.
It is worth mentioning that lexical analysis is not only used in the compiler, but is also provided in the go standard library go/scanner, which can be used to test how a piece of source code looks like when translated into a token.
|
|
The output after translation into token is as follows.
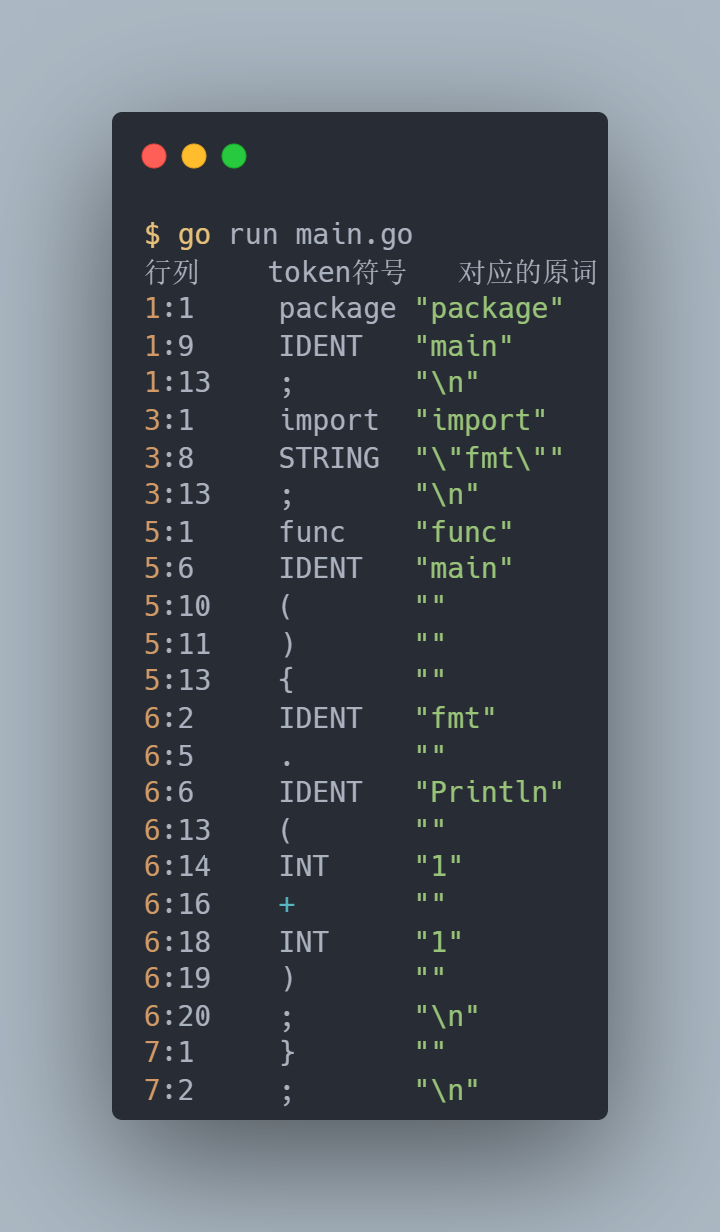
One small detail: when a \n line break is encountered, it is translated into a ; semicolon, which is why Go does not need ; endings.
Syntax analysis
The second step of the compiler is called syntax analysis or parsing. Syntax analysis transforms the token from the first step into a program syntax structure represented using the AST abstract syntax tree.
The source code for syntax analysis is located at cmd/compile/internal/syntax/parser.go. We can also use the standard library go/parser for testing.
|
|
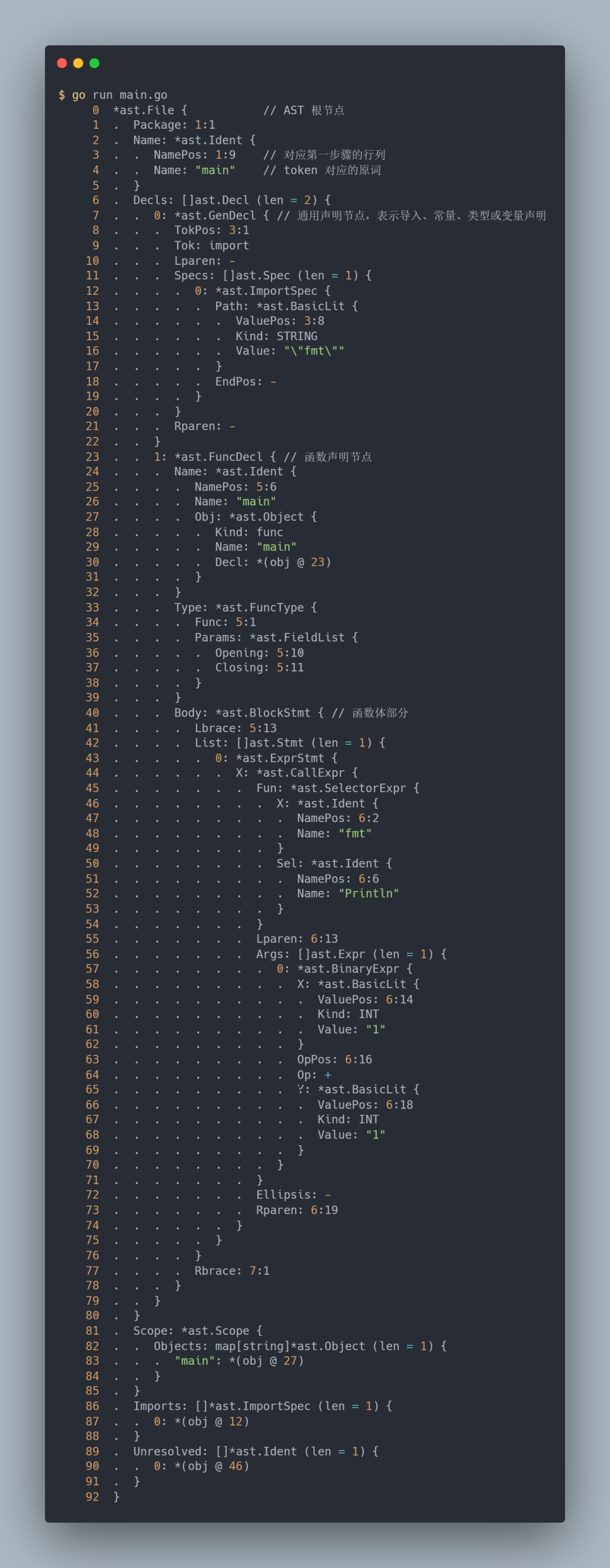
Each syntax tree constructed after syntax analysis is an exact representation of the corresponding source file, with nodes corresponding to various elements of the source file, such as expressions, declarations and statements. The syntax tree also includes location information for error reporting and creating debugging information.
Up to this stage, the source code has only been processed at the string level. From source code to token and then to AST.
Type checking
In the compilation principle, after the AST is built, it comes to the semantic analyzer stage, which mainly consists of type checking and automatic type conversion (coercion).
In the Go compiler, this phase is directly combined with type checking, whose source code is defined in cmd/compile/internal/types2.
In this phase, type checking goes through the nodes of the AST, checking the type of each node, such as whether each operator has a matching operator component, whether the subscript of the array is a positive integer, and so on. In addition, the type checking phase also performs type derivation, e.g., using the short variable declaration i := 1, it automatically infers that the variable i is of type int.
In short, the processing of the type system is all done in the type checking phase.
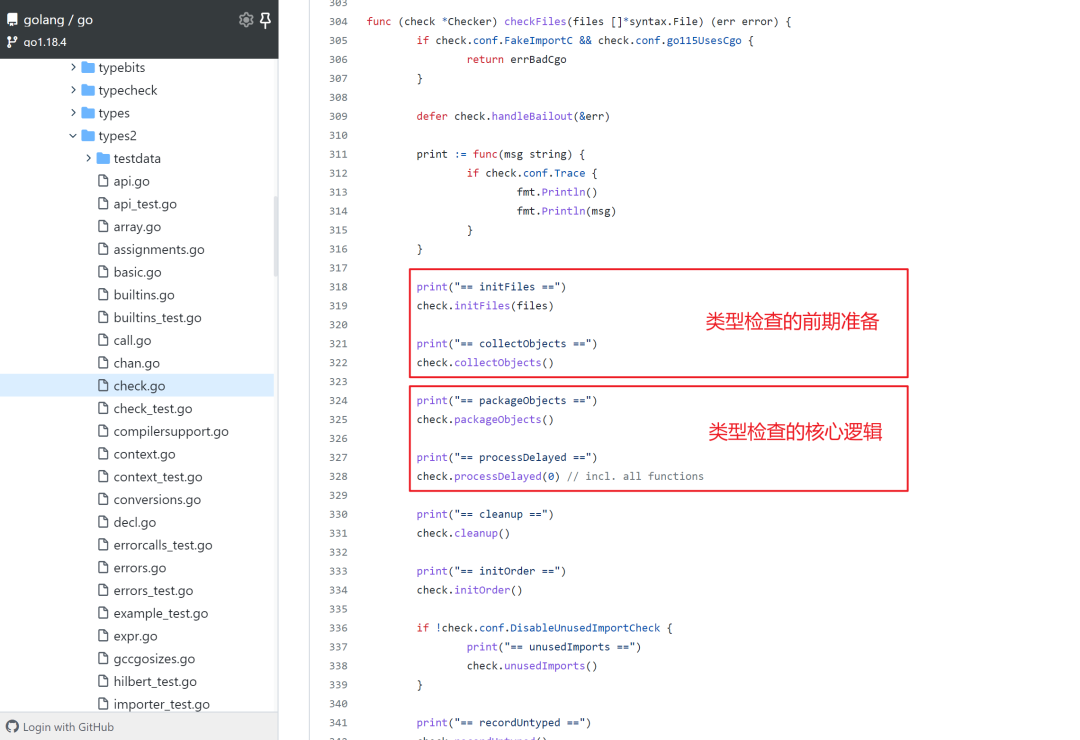
The general flow of type checking can be found in cmd/compile/internal/types2/check.go:
Intermediate code generation
Once the type checking phase is completed, it means that the compilation front-end is finished and the code is now free of syntax errors. It is logically ready to be translated directly into machine code, but before that, it needs to be translated into an intermediate representation (IR) between the source code and the target machine code.
Using intermediate code to bridge the front and back ends has great benefits. Because the intermediate code does not contain any information related to the source code or to a specific target machine, we can perform some machine-independent optimization based on the intermediate code.
In addition, with the intermediate code, the back-end compilation can also be reused. For example, if I want to create a new language now, I just need to write the compiler front-end and construct the same intermediate code, and the compiler back-end can use the ready-made one directly without having to build it again and again.
In fact, this is what we usually call decoupling in programming.
Back to the intermediate code generation itself, in this phase, an IR Tree is generated based on the AST constructed earlier.
Since we are analyzing based on Go 1.18.4, the Go Team has added many new language features (including generics), and many of the previous modules have been refactored to make the code structure clearer. However, it is inevitable that some of the previous packages will be associated with older versions (where IR Tree generation and type checking were done at the same time).
During the IR generation phase, the following directories will be involved.
cmd/compile/internal/typescmd/compile/internal/ircmd/compile/internal/typecheckcmd/compile/internal/noder
The entry point for IR generation is at cmd/compile/internal/noder/irgen.go.
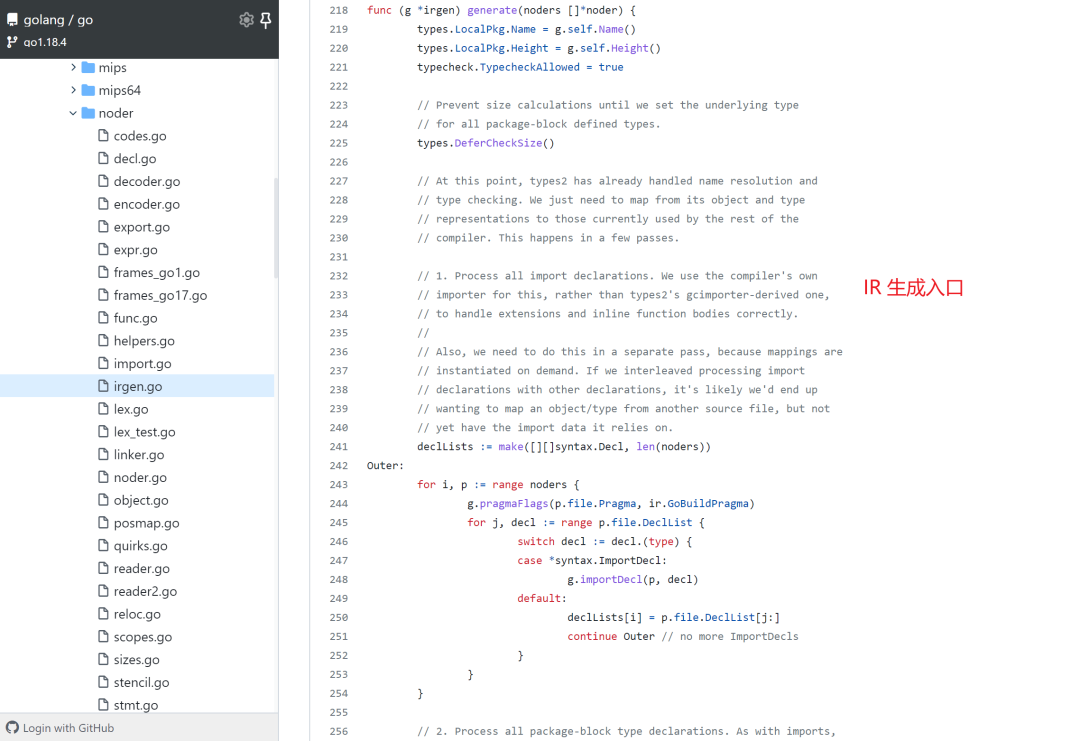
The argument noders in func (g *irgen) generate(noders []*noder) is the output of type checking AST.
To summarize, the compiler front-end does the translation of source code -> token -> AST, and now the intermediate code generation stage does the translation of AST -> AST-based IR Tree. So that’s why the compiler’s job is to translate.
Code optimization
Finally we come to code optimization, which can be the worst part of the interview questions. Even if you don’t understand the compilation process, you have heard these terms: dead code elimination, function call inlining, escape analysis.
These are the further optimization process of IR. The source code is located at
cmd/compile/internal/deadcodecmd/compile/internal/inlinecmd/compile/internal/escape
The purpose of code optimization is to make code execution more efficient. For example, there may be code that has semantic value but may never be executed at runtime, and dead code elimination removes this useless code (like the condition true in if).
If there are a large number of small function calls in the program, function inlining directly replaces the function call with the function body to reduce the additional context switching overhead caused by the function call.
Finally escape analysis can determine whether variables should use stack or heap memory, laying the groundwork for Go’s automatic memory management.
Walk traversal and replacement
IR, having undergone code optimization, will make its final stop on the tour of life: Walk, whose source code is located at cmd/compile/internal/walk.
Walk will traverse functions to break complex statements into separate, simpler statements, and may introduce temporary variables to reorder certain expressions and statements. It also replaces higher-level Go structures with more primitive ones.
For example, n += 2 will be replaced with n = n + 2; switch select branches will be replaced with dichotomous lookups or jump tables; make operations for map and chan will be replaced with makemap and makechan called at runtime, and so on.
Generic SSA generation
Walk is the final leg of the AST-based IR, meaning it’s time to come here and translate again.
This time the IR will be converted to Static Single Assignment (SSA), a lower-level intermediate representation with specific properties that make it easier to implement optimizations and eventually generate machine code.
The rules for SSA are defined in: cmd/compile/internal/ssa and the code for IR to SSA is located in: cmd/compile/internal/ssagen.
The entry point for translation is in the func Compile(fn *ir.Func, worker int) function.
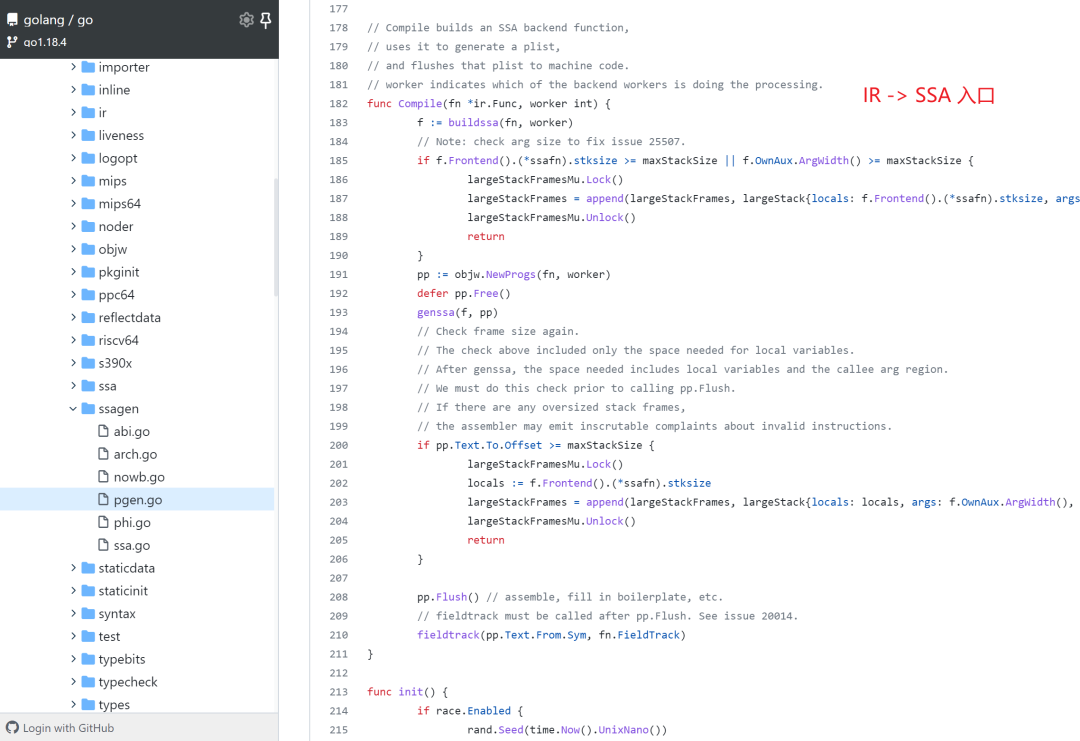
We can see how SSA is generated by adding the GOSSAFUNC=function name environment variable to the compilation process.
Again, take this code as an example.
When prompted, the ssa.html file is generated.

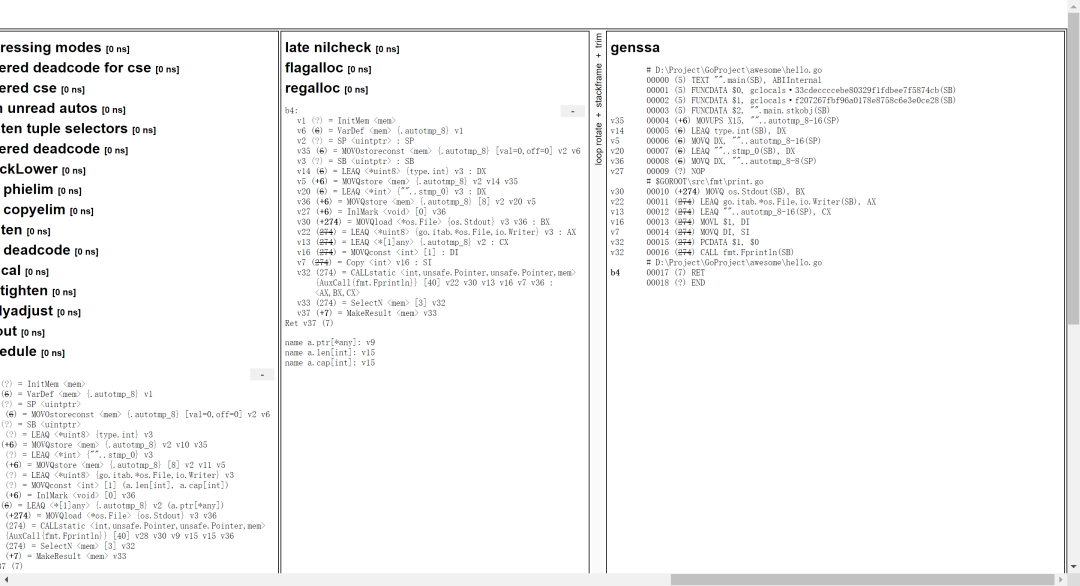
You can see that the SSA goes through several rounds of conversion before generating the final SSA in order to maximize the efficiency of execution.
Machine code generation
Coming to the last step, and the final puzzle from .go text file to executable, translating SSA into machine code for a specific target machine (target CPU architecture).
The SSA first needs to be lowered to perform multiple rounds of conversions for the specific target architecture to perform code optimizations, including dead code elimination (unlike in the previous code optimization), moving values closer to their intended use, removing redundant local variables, register allocation, etc.
The final result of this lowered operation is actually the genssa at the end of our ssa.html file above.
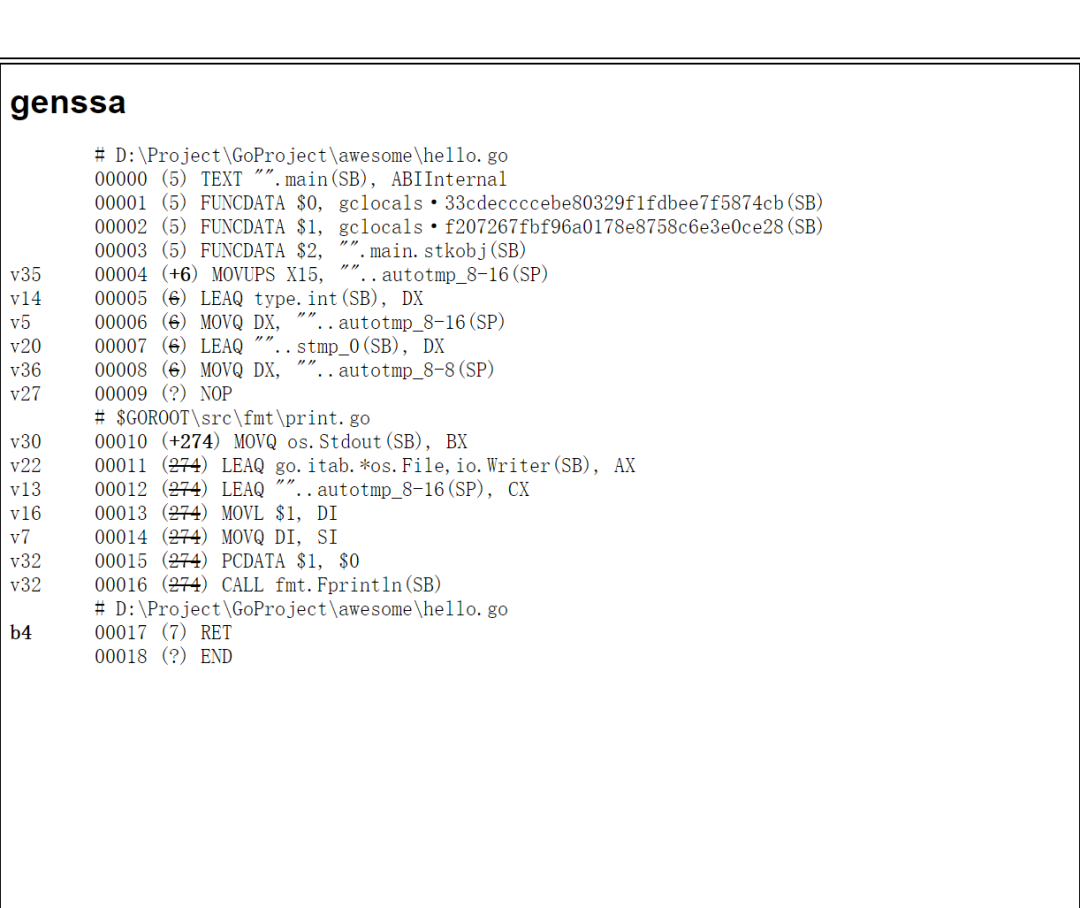
After converting SSA to genssa in multiple rounds (which is very close to assembly at this point), it continues to translate genssa into assembly code (Plan9) before calling the assembler (cmd/internal/obj) to convert them into machine code and write the final target file. The target file will also contain reflection data, exported data and debugging information. This step requires a good understanding of the CPU instruction set architecture.
Finally, if the program uses other programs or libraries, you will need to reference them using static or dynamic links. Go defaults to static links when no CGO is used, but you can specify this in go build.
Finally
The compilation principle is a very complex system, and the body of knowledge involved in each phase is intimidating enough.
This article is just a slapdash walk through, about some of the details I am not too clear, but also let me understand a little bit of truth: no matter how complex multi-layer system, but also through the decoupling of layers, reuse, and is also constantly iterative optimization to complete.
In addition, knowing the code optimization in the Go language compilation process also allows us to write more high-performance code with the corresponding features, such as allocating objects on the stack as much as possible, and reducing variables escaping to the heap can also improve GC efficiency. These will be covered in a separate article later.