
Istio is known to have health checks for the VMs it accesses, and for services on k8s, the health check section is included in the Pod.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: k8s.gcr.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
|
And for VM-accessed Workload, istio provides a similar capability.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
apiVersion: networking.istio.io/v1alpha3
kind: WorkloadGroup
metadata:
name: reviews
namespace: bookinfo
spec:
metadata:
labels:
app.kubernetes.io/name: reviews
app.kubernetes.io/version: "1.3.4"
template:
ports:
grpc: 3550
http: 8080
serviceAccount: default
probe:
initialDelaySeconds: 5
timeoutSeconds: 3
periodSeconds: 4
successThreshold: 3
failureThreshold: 3
httpGet:
path: /foo/bar
host: 127.0.0.1
port: 3100
scheme: HTTPS
httpHeaders:
- name: Lit-Header
value: Im-The-Best
|
How does this work? Let’s explore this today.
How it works
In the initXdsProxy function, we can see that the istio-agent Proxy` object is created during initialization and this object will be used to handle some work.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
go proxy.healthChecker.PerformApplicationHealthCheck(func(healthEvent *health.ProbeEvent) {
// Store the same response as Delta and SotW. Depending on how Envoy connects we will use one or the other.
// Based on the results of PerformApplicationHealthCheck, different DiscoveryRequests are created for the healthy and unhealthy states respectively.
var req *discovery.DiscoveryRequest
if healthEvent.Healthy {
req = &discovery.DiscoveryRequest{TypeUrl: v3.HealthInfoType}
} else {
req = &discovery.DiscoveryRequest{
TypeUrl: v3.HealthInfoType,
ErrorDetail: &google_rpc.Status{
Code: int32(codes.Internal),
Message: healthEvent.UnhealthyMessage,
},
}
}
proxy.PersistRequest(req)
// skip DeltaDiscoveryRequest
}, proxy.stopChan)
|
For PerformApplicationHealthCheck is not expanded here, it is roughly the same as simulating sending a request.
HealthInfoType DiscoveryRequest
So what is the purpose of the DiscoveryRequest that we sent to Poilt, we continue to explore the next.
In shouldProcessRequest we can see the following code.
1
2
3
4
5
6
7
8
|
if features.WorkloadEntryHealthChecks {
event := workloadentry.HealthEvent{}
event.Healthy = req.ErrorDetail == nil // If ErrorDetail is not null, it is unhealthy
if !event.Healthy {
event.Message = req.ErrorDetail.Message
}
s.WorkloadEntryController.QueueWorkloadEntryHealth(proxy, event) // Triggered into QueueWorkloadEntryHealth
}
|
And in QueueWorkloadEntryHealth the logic is also very simple.
1
2
3
4
5
6
7
|
func (c *Controller) QueueWorkloadEntryHealth(proxy *model.Proxy, event HealthEvent) {
// replace the updated status
wle := status.UpdateConfigCondition(*cfg, condition.condition)
// update the status
_, err := c.store.UpdateStatus(wle)
return nil
}
|
At this point, our logic for workloadEntry is completely finished.
ServiceRegistry Controller
In InstancesByPort we don’t return any unhealthy instances, so how is this part implemented?
In workloadEntryHandler, we find the processing in place.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
func (s *ServiceEntryStore) workloadEntryHandler(old, curr config.Config, event model.Event) {
// If an entry is unhealthy, we will mark this as a delete instead
// This ensures we do not track unhealthy endpoints
if features.WorkloadEntryHealthChecks && !isHealthy(curr) {
event = model.EventDelete
}
// The following is too long, you can read the original article, it roughly triggers the deletion of the ServiceInstance in memory and triggers an EdsUpdate
s.serviceInstances.deleteInstances(key, instancesDeleted)
if event == model.EventDelete {
s.workloadInstances.delete(types.NamespacedName{Namespace: curr.Namespace, Name: curr.Name})
s.serviceInstances.deleteInstances(key, instancesUpdated)
} else {
s.workloadInstances.update(wi)
s.serviceInstances.updateInstances(key, instancesUpdated)
}
s.mutex.Unlock()
}
|
Summary
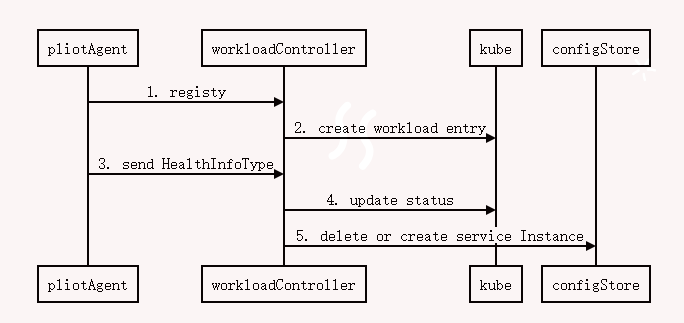
Reference
https://github.com/istio/istio/blob/release-1.13/pilot/pkg/serviceregistry/serviceregistry_test.go#L890-L923