Linux provides the memory map feature, which implements the mapping of physical memory pages into the process address space for efficient data manipulation or transfer. The kernel uses three important data structures struct vm_area_struct , struct anon_vma and struct anon_vma_chain to handle this feature, so it is important to understand these three data structures, and this article tries to clarify the origin and connection between them.
vma
The struct vm_area_struct is often referred to as vma in kernel code, so This structure is referred to by vma in the following.
vma is a unit of memory mapping, which represents a contiguous segment of the process address space, where the fields vm_start and vm_end indicate the starting virtual address of this contiguous segment. When creating a map using the mmap system call, the user specifies the start address (optional) and length, and the kernel will look for a legal vma in the process address space for the map accordingly. cat /proc/<pid>/maps allows you to see all the mapped intervals for a process.
anon_vma
The introduction of anon_vma needs some explanation.
Introduction of reverse mapping
When the Linux system runs out of memory, the swap subsystem releases some pages and swaps them into the swap device to free up extra memory pages. The idea of virtual memory is to maintain a mapping of virtual addresses to physical addresses through page-tables. However, page-table is a one-way mapping, i.e., it is easy to find a physical address through a virtual address, but conversely it is troublesome to find a virtual address through a physical address. This problem is more serious in the case of shared memory. The swap subsystem encounters this problem when releasing a page. For a particular page (physical address), it has to find the ``Page Table Entry (PTE)` mapped to it and modify the PTE to point to the location of that page in the swap device. In pre-2.4 kernels, this was a time-consuming task because the kernel had to traverse all page tables for each process to find all page table entries that mapped to that page.
The solution to this problem is to introduce the concept of reverse mapping. This is done by maintaining a data structure for each memory page (struct page) that contains all the PTEs mapped to that page, so that when looking for the reverse mapping of a memory page, one can simply scan this structure, which greatly improves efficiency. This is exactly what Rik van Riel did by adding a pte_chain field to the struct page, which is a pointer to a chain of all the PTEs mapped to that page.
Of course, it comes at a cost.
- Each
struct pageadds a field, and each memory page in the system corresponds to astruct pagestructure, which means that a considerable amount of memory is used to maintain this field. This means that a significant amount of memory is used to maintain this field. Sincestruct pageis an important kernel data structure stored in limited low-end memory, adding a field wastes a significant amount of valuable low-end memory, and this is especially true when the physical memory is large, which causes scalability problems. - Other functions that need to manipulate a large number of pages slow down. The
fork()system call is one. Since Linux adopts the semantics of Copy On Write (COW), which means that the new process shares the parent’s page table, all pages in the process address space have a new PTE pointing to it, so a new reverse map is needed for each page, which slows things down significantly.
Object-based reverse mapping
This cost was clearly intolerable, so Dave McCracken proposed a solution called object-based reverse mapping. His observation was that the costs described earlier came from the introduction of the reverse mapping field, whereas if there were all the page table entries that could be fetched from a struct page that mapped to that page, the field would not be needed, and there would be no need for these costs. He did find a way to do this.
Linux user state memory pages are divided into two broad usage cases:
- A large part of them is called file-backed page, which, as the name implies, is a memory page whose contents are associated with a file in the backing storage system, such as program code, or a normal text file, which is generally mapped into address space using the
mmapsystem call mentioned above, and, in case of memory crunch, can simply be This type of memory page is usually mapped to address space by themmapsystem call described above, and can be simply discarded when memory is tight because it can be easily recovered from a backup file. - This is a general type of memory page, such as stack or heap memory, which has no backup file, which is why it is called anonymous.
The object in Dave’s scheme refers to the first type of memory page backup file. He calculates the PTE in a roundabout way by backing file object, which will not be described too much in this paper.
Reverse mapping of anonymous pages
Dave’s solution only solves the first kind of reverse mapping of memory pages, so Andrea Arcangeli follows Dave’s lead and gives a solution for reverse mapping of anonymous pages.
As mentioned earlier, there is no such thing as a backup file for anonymous pages, but one of the characteristics of anonymous pages is that they are private, not shared (e.g., stacks and vertex memory are process-independent and not shared). This means that for each anonymous memory page, there is only one PTE associated with it, that is, there is only one vma associated with it . Andrea’s solution is to reuse the mapping field of the struct page, because for anonymous pages, mapping is null and does not point to a fallback space. In the case of anonymous pages, the mapping field is not a pointer to the struct address_space, but to the unique vma associated with the memory page, using the C language union. This also makes it easy to calculate the PTE.
However, things are not so simple. When a process is copied by fork, as already mentioned, due to the semantics of COW, the new process just copies the page table of the parent process, which means that now one anonymous page has two page tables pointing to it, so the above simple reuse of the mapping field doesn’t work, because how can one pointer, represent two vma’s.
Andrea’s approach is to add an extra layer. Create a new struct anon_vma structure, which now has the mapping field pointing to it, and anon_vma which, not surprisingly, contains a link to all the vmas. Whenever a process forks a child process, the child process copies the vma of the parent process due to the COW mechanism, and this new vma is linked to the anon_vma of the parent process. In this way, every time a memory page is unmaped, the anon_vma pointed by the mapping field can find the vma chain that may be associated with that page, and traverse the chain to find all the PTEs mapped to that anonymous page.
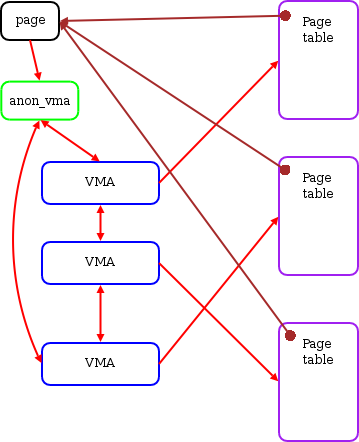
This has a cost, too, in that
- Each
struct vm_area_structstructure has an extralist_headstructure field to string together all thevmas. - Additional memory needs to be allocated for the
anon_vmastructure.
However, this solution requires much less memory than adding a reverse mapping field to each struct page as mentioned above, so it is acceptable.
This is the end of the introduction of the anon_vma structure and its role.
anon_vma_chain
The anon_vma structure was proposed to improve the reverse mapping mechanism, and it seems to be a perfect solution in terms of efficiency and memory usage. However, reality continues to pose problems. Rik van Riel, mentioned at the beginning, cites a workload example to argue against the flawed solution.
The previous anonymous page reverse mapping mechanism, when unmapping a page, accesses the vma linked list by accessing anon_vma and traversing the entire vma linked list, to find a PTE that might map to that page.
However, this approach misses one point: if a write access occurs to a vma in a child process copied by a process fork, a new anonymous page will be allocated and the vma will be pointed to this new anonymous page, which is no longer related to the original anonymous page, but the original vma linked list does not reflect this change, resulting in unnecessary access to the vma. This leads to unnecessary checking of the vma. The example given by Rik describes this extreme case.
Rik’s solution is to add another layer, a new structure called anon_vma_chain:
|
|
Each anon_vma_chain (AVC) maintains two linked lists
- same_vma: all the
anon_vmaassociated with the givenvma - same_anon_vma: all
vmaassociated with the givenanon_vma
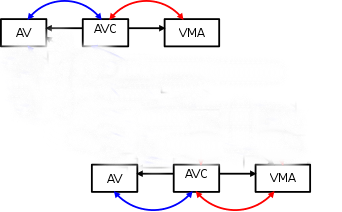
Initially, we have a process with an anonymous vma.
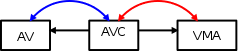
Here, “AV” is anon_vma and “AVC” is the anon_vma_chain seen above. AVC links directly to anon_vma and vma via pointers. (The (blue) linked list is the same_anon_vma linked list, and the (red) linked list is the same_vma linked list.
Imagine that the process performs a fork operation, causing the child process to copy vma; now there is a new vma in isolation.
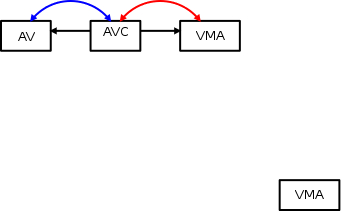
The kernel needs to link this vma to the anon_vma of the parent process; this requires adding a new anon_vma_chain.
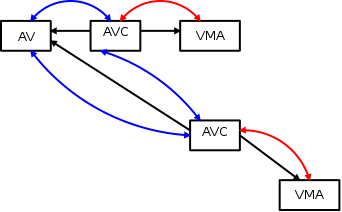
Note that the new AVC has been added to the same_anon_vma chain. The new vma also needs its own anon_vma :
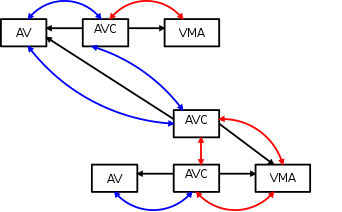
There is now another anon_vma_chain linked in the new anon_vma. The new AVC has been added to the same_vma linked list.
At this moment, according to the figure above, you can verify the role of the two chains in anon_vma_chain (AVC).
The “same_vma” list contains the anon_vma_chains linking all the anon_vmas associated with this VMA. The “same_anon_vma” list contains the anon_vma_chains which link all the VMAs associated with this anon_vma.
When a child process writes a memory page, COW occurs and the child process’s vma will point to its own anonymous page, and at the same time, this new anonymous page points to the child process’s anon_vma (at this point the same_anon_vma chain is unlinked from the same_vma chain).
In this way, when unmapping a page, for the child process’s own anonymous page, it only needs to traverse the vma chain under the child process’s own anon_vma. This greatly reduces the number of vmas that the parent process needs to traverse.
The name anon_vma_chain is like a glue and a chain that links the vma and anon_vma associated with the parent and child processes at the beginning, and when the child process has its own anonymous page through the COW, it will unlink the chain and manage it separately with a split policy, thus reducing the number of vma vmas traversed by the parent process when unmapping a page, which also reduces the corresponding lock conflicts and thus improves efficiency.