In daily life, biometric technology is already standard in most smartphones, and most phones are equipped with face recognition and fingerprint recognition, and the current fingerprint recognition technology is already very mature. But what we want to talk about today is not the fingerprint recognition in biometric technology, but the browser fingerprint. Many people love and hate this technology, why is this? Then we’ll take a deeper look at browser fingerprinting today.
What is a browser fingerprint?
Human fingerprints are highly variable and unique, and can be used as a person’s identification. Also a person’s name, ID number, and facial features can be used as unique identifiers. Device fingerprint or machine fingerprint is the information collected about the software and hardware of a remote computing device for identification purposes. For example, the hardware ID of a device, like a cell phone is given a unique IMEI number during the production process to uniquely identify the unit. Like a computer’s network card, it is given a unique MAC address during the production process. A fingerprinting algorithm is usually used to assimilate the information into a short identifier. And a browser fingerprint is information that is collected specifically by interacting with the device’s web browser.
Browser fingerprinting is a method of tracking Web browsers through configuration and setting information visible to the browser. Browser fingerprinting is like the fingerprints on our human hands, with individual recognition, except that at this stage, browser fingerprinting identifies the browser.
The fingerprints on the human hand are unique because each fingerprint has a unique pattern, which is formed by the bumpy skin. The differences in the fingerprint patterns of each person create their unique characteristics. The same is true for browser fingerprints. We obtain the information that identifies the browser and perform some calculations to get a value, which is the browser fingerprint. The identifier can be UA, time zone, geographic location or the language you use, etc. The information you choose determines the accuracy of your browser fingerprint.

For websites, there is no real value in getting a browser fingerprint; what is really valuable is the user information corresponding to this browser fingerprint. As a website webmaster, collecting user browser fingerprint and recording user’s operation is a valuable action, especially for scenarios where there is no user identity. For example, on a content distribution site, user A likes to browse secondary content, and by recording this interest through the browser fingerprint, then the next time the user can push secondary information to user A without logging in. At a time when personal PCs are so popular, this is also a way to distribute content.
For users, establishing a link between your personal online behavior and your browser fingerprint is more or less an invasion of privacy, especially if it associates your browser fingerprint with real user information. Browser fingerprinting is essentially an invasion of privacy. In most cases, you do not know that you are being tracked. Even if you do know, it can be difficult to prevent.
The value of browser fingerprinting
In theory, with no login and no persistent cookies read or stored in the browser, no access to the client’s IP, or switching between browsers on the same device, we can still fully or partially identify individual devices through browser fingerprinting.
- enable service providers to detect and prevent identity theft and some fraud
- Comprise a long-term record of an individual’s browsing history (and provide targeted advertising or even launch corresponding attacks on the target)
Main scenarios.
- Targeted ad push. Browse a certain product on a website, learn about the product information, but do not place an order to buy it, or even perform a login operation. When you visit other websites with the same computer two days later, you find many advertisements for similar products.
- Assist in recognizing the same device. In a certain blog you have multiple accounts (water army), these accounts exist to refresh the popularity of a post or to guide public opinion. Even if you clear the cookies, local cache, reopen the router or even use vpn to do the operation when you switch accounts, the management may still know that it is the same person operating and thus be cracked down.
Development of Browser Fingerprinting
The development of browser fingerprinting technology, like most technologies, did not happen overnight. The existing generations of browser fingerprinting technology are as follows.
- The first generation was stateful and focused on the user’s cookie and evercookie, requiring the user to be logged in to get valid information.
- The second generation has the concept of browser fingerprinting, by increasing the value of browser features to make the user more distinguishable, such as UA, browser plug-in information, etc.
- The third generation is already focused on people, by collecting users’ behavior and habits to build feature values and even models for users, which can realize real tracking technology. However, the implementation is currently more complicated and still under exploration.
At present, the tracking technology of browser fingerprint can be considered to enter the 2.5 generation, so to say because the problem of cross-browser fingerprint recognition is still not solved.
Capture of browser fingerprints
Information entropy (entropy) is the average amount of information contained in each message received. Higher information entropy means more information can be transmitted, and lower information entropy means less information is transmitted. The browser fingerprint is a combination of information about the features of many browsers, in which the information entropy of feature values varies. Therefore, fingerprints are also divided into basic and advanced fingerprints.
Browser Basic Fingerprint
Basic fingerprint is a feature that any browser has, such as hardware type (Apple), operating system (Mac OS), user agent, system font, language, screen resolution, browser plug-ins (Flash, Silverlight, Java, etc), browser extensions, browser settings (Do-Not- Track, etc), Browser GMT Offset, etc. These fingerprints are “similar” to human height, age, etc., and have a high probability of conflict, so they can only be used as auxiliary identification.
Browser feature fingerprint acquisition.
| Fingerprint content | Method of obtaining fingerprints |
|---|---|
| userAgent | navigator.userAgent |
| Language of the browser | navigator.language |
| Browser plug-ins | Array.from(navigatorObj.plugins).map(item => item.name).join(',') |
System characteristics fingerprint acquisition.
| Fingerprint content | Method of acquiring fingerprints |
|---|---|
| operating system | navigator.platform |
Time zone feature fingerprint acquisition.
| Fingerprint content | Method of acquiring fingerprints |
|---|---|
| Time difference between Greenwich Mean Time and Local Time | new Date().getTimezoneOffset() |
| Time-zone belongs to | You need to query the server to get the corresponding information |
| Area latitude and longitude | navigator.geolocation.getCurrentPosition(need to be called in https secure environment) or query the server to get the corresponding information |
| Geographic area name | need to query the server for the corresponding information |
| IP address | You need to query the server for the corresponding information |
Hardware feature fingerprint acquisition.
| Fingerprint content | Method of obtaining fingerprints |
|---|---|
| The maximum number of simultaneous touches the device can support | navigator.maxTouchPoints |
| Number of available logical processor cores | navigator.hardwareConcurrency |
| Device screen width, height and color information | ${screen.width}*${screen.height}*${screen.colorDepth} |
Browser Advanced Fingerprinting
Ordinary fingerprints are not enough to distinguish unique individuals, and this is where advanced fingerprints are needed to narrow down the scope even further and even generate a unique cross-browser identity. The individual pieces of information used to produce the fingerprint have a greater or lesser weight, and those with greater information entropy will have a greater weight.
Canvas Fingerprint
Canvas is a dynamic drawing tag in HTML5, which can also be used to generate images or process images. Even if the same elements are drawn using Canvas, the results obtained by canvas when converting the same text to images are different due to system differences, different font rendering engines, different algorithms for anti-aliasing, sub-pixel rendering, etc.
Since fingerprinting is mainly based on the browser, operating system and installed graphics hardware, it is still not possible to fully uniquely identify the user (the repetition rate is very low).
The implementation code is roughly: render some text on canvas and convert it out with toDataURL, even if privacy mode is turned on you can get the same value.
|
|
Then the obtained canvasImageData is passed through the hash algorithm to come up with a unique value (md5 or sha256, etc.), which is the canvas fingerprint we have obtained.
WebGL Fingerprinting
WebGL (Web Graphics Library) is a JavaScript API that renders high-performance interactive 3D and 2D graphics in any compatible Web browser without the use of plug-ins. WebGL does this by introducing a very consistent API with OpenGL ES 2.0 that can be used in HTML5 elements. This consistency allows the API to take advantage of the hardware graphics acceleration provided by the user’s device. Web sites can use WebGL to identify device fingerprints, and fingerprint production can generally be done in two ways.
- WebGL reports, where the full WebGL browser report form is available and detectable. In some cases, it will be converted to a hash for faster analysis.
- WebGL images, rendered and converted to hashes of hidden 3D images. This method generates unique values for different combinations of devices and their drivers, since the final result depends on the hardware device performing the computation. This way unique values are generated for different combinations of devices and drivers.
The principle of generating WebGL fingerprints is that you first need to draw a gradient object with shaders (shaders) and convert this image to a Base64 string. Then enumerate all the WebGL extensions and features and add them to the Base64 string, resulting in a huge string that can be very unique on each device.
For example the fingerprint2js library’s WebGL fingerprint production approach.
|
|
Audio Fingerprinting
AudioContext fingerprint is similar to Canvas also based on the difference of hardware device or software to generate different audio output, and then calculate to get different hash to use as a flag.
- Method 1: Generate audio stream (triangle wave), perform FFT transform on it, and calculate SHA value as fingerprint.
- Method 2: Generate audio information stream (sine wave), perform dynamic compression process, and calculate MD5 value.
Both methods are cleared before the audio is output to the audio device, and the user is simply unaware that the fingerprint has been obtained.
Take fingerprintjs2’s audio fingerprint source code as an example.
|
|
WebRTC
WebRTC (Web Real Time Communication), which allows browsers to have the ability to communicate in real time with audio and video, provides three main APIs to allow JS to obtain and exchange audio and video data in real time, MediaStream, RTCPeerConnection and RTCDataChannel. Of course, if you want to use WebRTC to get the ability to communicate, the user’s real IP will have to be exposed (NAT penetration), so RTCPeerConnection provides such an API, the direct use of JS can get the user’s IP address.
Fingerprint calculation
In addition to the fingerprint from http, it is also possible to get the browser feature information by other means, and some feasible feature values are displayed in this document (https://panopticlick.eff.org/about).
- The user agent string for each browser
- HTTP ACCEPT header sent by the browser
- Screen resolution and color depth
- System settings to time zone
- Browser extensions/plug-ins installed in the browser, such as Quicktime, Flash, Java, or Acrobat, and the versions of those plug-ins
- Fonts installed on the computer, as reported by Flash or Java.
- Whether the browser executes JavaScript scripts
- Whether or not the browser can seed various cookies and “super cookies”
- Hashing of images generated by Canvas fingerprinting
- Hash of images generated by WebGL fingerprinting
- Whether the browser is set to “Do Not Track”
- System platform (e.g. Win32, Linux x86)
- System language (e.g., cn, en-US)
- Whether the browser supports touch screen
After getting these values some operations can be performed to get the specific information entropy of the browser fingerprint and the uuid of the browser.
The following figure shows the information entropy, repetition probability and specific values of several feature values.
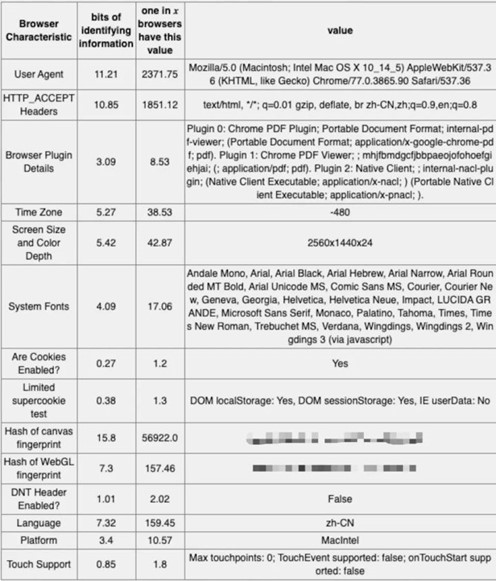
Combining the above fingerprint information can greatly reduce the collision rate and improve the accuracy of client-side uuid. Fingerprint’s also have the weight of weight, in the paper “Cross-Browser Fingerprinting via OS and Hardware Level Features” is more detailed study of the information entropy and stability of each indicator.
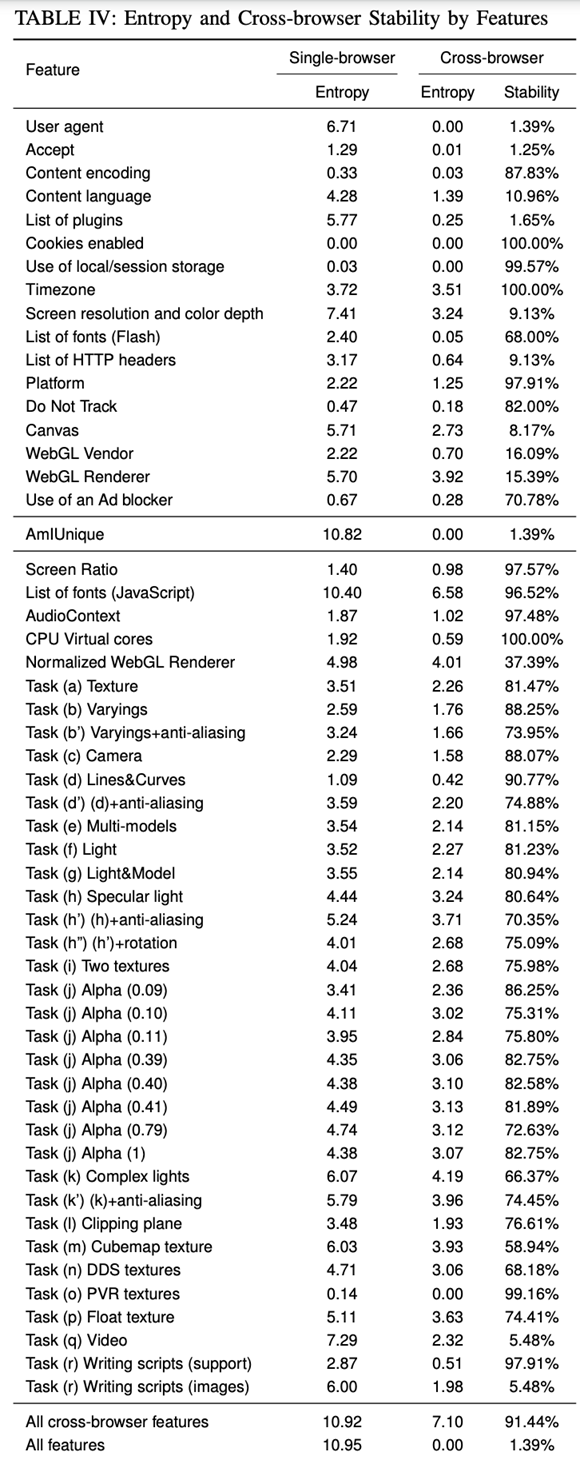
From that paper, we can see that the information entropy of time zone, screen resolution and color depth, Canvas, and webGL are weighted more heavily on cross-browser fingerprinting.
Cross-Browser Fingerprinting
In summary the browser fingerprints mentioned above are obtained from the same browser. However, many feature values are unstable, for example, UA and canvas fingerprints will open completely differently in different browsers on the same device. The same set of browser fingerprinting algorithms will not be available in different browsers.
Cross-browser fingerprinting is a stable browser feature that can obtain the same or approximate values even in different browsers.
Cross-browser fingerprinting has also been studied.
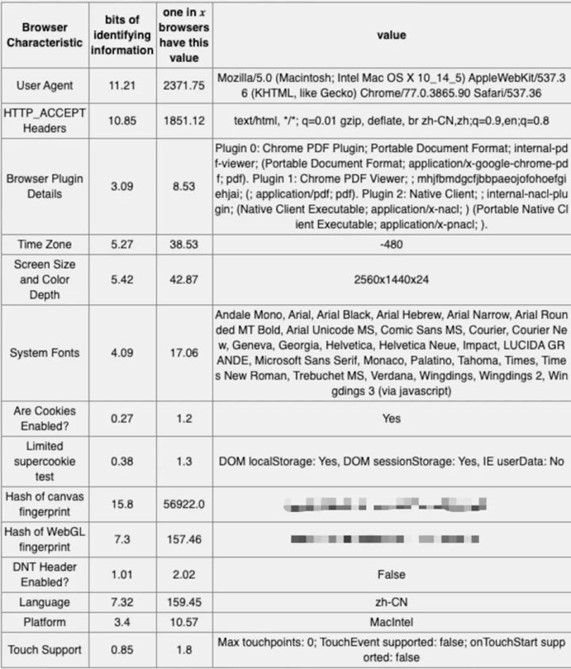
The information entropy and stability of browser eigenvalues in single browser and cross-browser are listed, and the stability of canvas fingerprint mentioned in the above appeal is only 8.17%.
It is difficult for regular eigenvalues to maintain high stability with sufficient information.
Pick a few tables of values Task(a)~Task(r), List of fonts (JS), TimeZone and CPU Vritual cores, that match these features.
- Task(a)~Task(r), which is a kind of graphics card rendering (Rendering Tasks) image feature values. For example, Task(a) Texture, which is a test of the texture function in a regular fragment shader, by rendering a pixel with a random triple base color value, the fragment shader needs to insert points in the texture in order to map the texture to each point on the model, and this insertion algorithm is again inconsistent across different graphics cards. If the texture is more variable, then the more significant the difference will be, and we can make a differentiation for this graphics card by recording this difference.
- List of fonts (JS), which gets the fonts supported by the page through JS. List of fonts is the value of getting the fonts supported by the page through JS and how to draw the fonts, by measuring the fill size of the text HTML elements with different fonts, to make a distinction with other devices.
- TimeZone, the time zone, this is better understood, since it is the same device then the time zone should also be the same.
- CUP Vritual cores is the number of CPU cores, the easiest way to get it is through a hardwareConcurrency.
Although this API is not supported in low version browsers, you can also get it through this polyfill. The principle of implementation is roughly borrowing the ability of Web Worker, listening to the time of the payload, and the number of kernels can be obtained when the computation reaches the maximum concurrency of the hardware.
Browser Fingerprinting Confrontation
It’s almost 100% possible to locate a user by browser fingerprinting if you don’t have enough expertise or change browser information very often, which of course doesn’t have to be all bad.
- The privacy leaked is very one-sided, and can only say that it leaks part of the user’s behavior when browsing the web.
- Not enough value, user behavior does not correspond to actual accounts or specific people, generating limited value.
- Beneficial use, using browser fingerprinting can isolate some of the blackmail users and prevent swiping or some malicious behaviors.
But even so, there are some measures that can be taken to prevent browser fingerprinting.
Anti-browser fingerprint tracking simply breaks the three properties of fingerprint tracking described above.
- Fingerprint determinism. No effective method has been found to produce identical fingerprints for two browser platforms;
- Ease of access to fingerprints. Tracking can be slowed down using various browser settings or plug-ins, but this approach may affect the user experience, e.g., the inability to use cookies and JavaScript;
- Fingerprint stability. Dr. Pierre Laprise, a researcher from INRIA Rennes University, France, proposed a solution that allows the formation of a dynamic browsing platform that generates a different fingerprint each time the user browses the web.
And Pierre breaks the stability of fingerprints by two methods.
- Blurring the fingerprints of actual devices by automatically combining and reconfiguring multiple levels of software components using virtualization and modular architecture to generate random browsing environments that generate random fingerprints for each browsing session.
- Break the stability of very specific fingerprinting technologies (Canvas, Audio, JavaScript engines) by introducing enough noise into the fingerprinting process so that trackers cannot bind fresh fingerprints to old ones, thus making tracking across multiple sessions impossible.
Do Not Track
In the http header you can declare a flag “DNT” which means “Do Not Track”, if the value is 1 it means do not track my web page behavior, 0 means you can track it. Even without cookies you can use this flag to tell the server that I don’t want to be tracked and not to record my behavior.
The bad news is that most sites do not currently follow this convention and completely ignore the “Do Not Track” signal.
The EFF provides such a tool, Privacy Badger, which is an ad blocker in the form of a browser plug-in. Companies that comply with this agreement are whitelisted on this ad blocker and allowed to display ads, thus motivating more companies to comply with “Do Not Track” in order to display ads at all.
Personally, I think this is a good direction to take, as if the user uses this tool, the site will choose between the interests of the user’s behavior before taking it, thus mitigating the risk of privacy breaches.
More information about Privacy Badger can be viewed here (https://www.eff.org/privacybadger).
Tor Browser
With the above understanding of browser fingerprinting, it is easy to see that the more features your browser has, the easier it is to track. On the contrary, if you want to deliberately hide or magically alter certain browser features, then congratulations, your browser may have a unique browser fingerprint that doesn’t even need to be calculated deliberately, and can directly distinguish you from other users.
So the effective way is to make the feature value as popular as possible. For example, if Window 10 + Chrome is the most widely used combination on the market, then changing your UA to this combination is an effective way to do this, while trying to avoid websites that get very high entropy features, such as canvas fingerprints.
Tor Browser has done a lot of work on this to prevent them from being used to track Tor users, and in response to Panopticlick and other fingerprinting experiments, Tor Browser now includes patches to prevent font fingerprinting (by limiting the fonts a site can use) and Canvas fingerprinting (by detecting the reading of HTML5 Canvas objects and requiring user approval) to prevent, for example, the code above to obtain Canvas fingerprints pops up on Tor with the following warning.
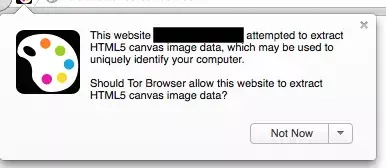
It is also possible to configure the Tor Browser to actively block JavaScript. in summary, these measures make the Tor Browser a powerful defensive tool against fingerprinting. But what such a secure browser sacrifices is its speed, and accessing pages with Tor Browser can be much slower than with commercially available browsers. Try Tor Browser if you are interested.
Disabling JS
The most effective way to stop a site from capturing browser information is to disable JavaScript on the browser. JavaScript is a front-end scripting language that can be used to make a site responsive and provide a better user experience. However, they are the primary tool sites use to obtain browser fingerprint information. If JavaScript is disabled, the site will not be able to create a browser fingerprint because only a few pieces of browser information (such as the User-Agent string name) and some other information will be available.
For browser fingerprinting, the more information that is available, the better the system will perform in uniquely identifying the browser. However, disabling JavaScript means that you will not be able to access certain sites that rely heavily on JavaScript. However, this will result in a larger portion of the page being unavailable.
And unfortunately, even if JS is disabled it is still possible to take browser information through CSS, e.g.
You can look at the request logs of 1080.png images in the server to know which users’ screens are 1080px.