Inappropriate indexes are the most common cause of poor performance in relational database systems. Common situations include not having enough indexes, some SELECT statements may not have valid indexes, index columns are not in the right order, etc. Some developers believe that if a SQL statement uses indexes, then the query performance of the statement will be greatly improved, and that professional index design should be done by the DBA. However, we can design efficient indexes as long as we know how the database handles the task internally.
The text is based on MySQL as an example, other relational databases may have some differences, but the basic principles are largely the same. Before we discuss how to design indexes, we need to understand the concept of indexes.
Organization of Indexes
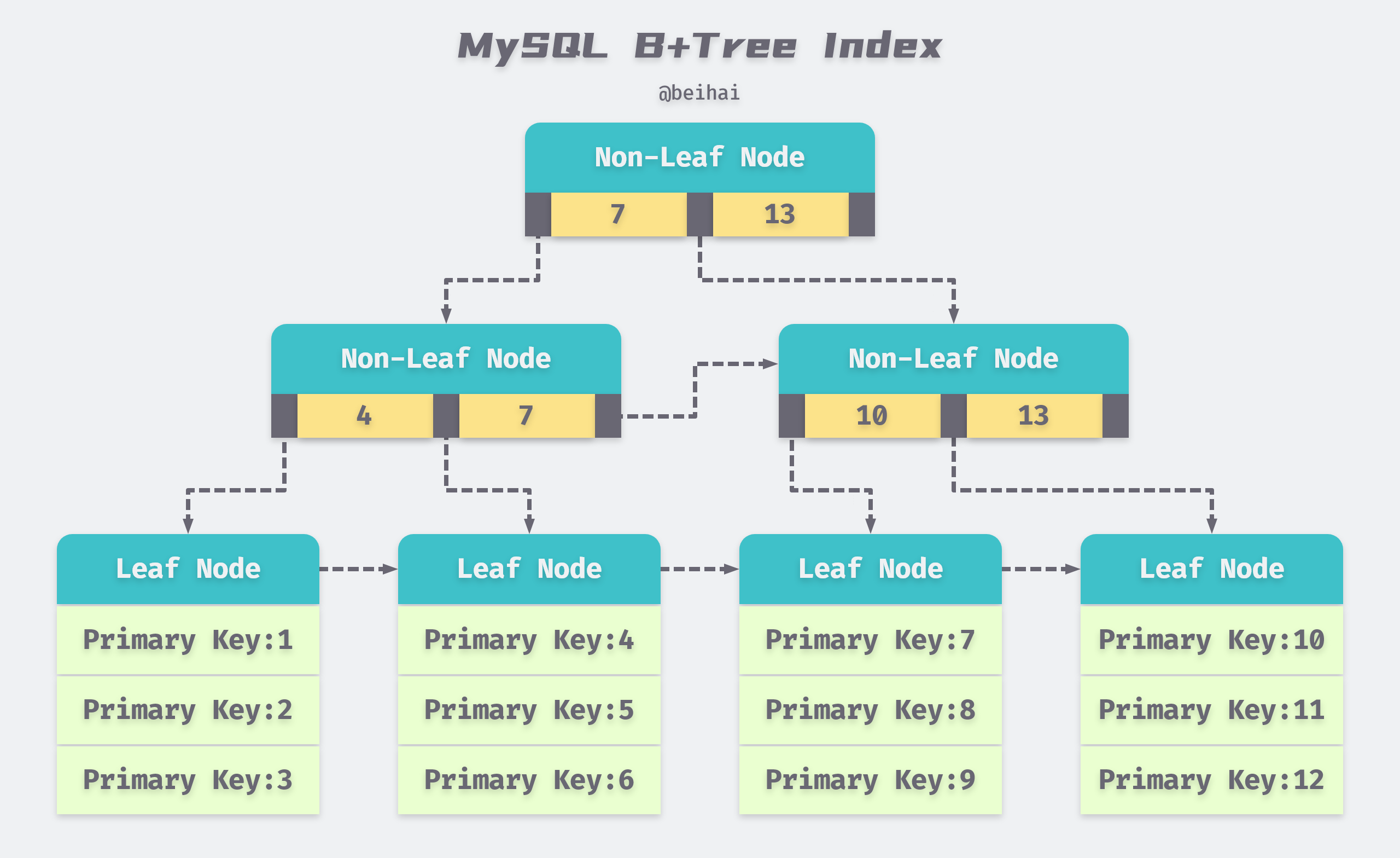
The data rows and index rows of a relational database are stored in pages, which are typically 4KB in size in most operating systems, and the default size of a page in MySQL is 16KB. the size of a page does not affect our analysis of performance, it simply determines how many rows of data can be stored on a page. In MySQL, a secondary index is also organized by a B+Tree, which contains the primary key of the data. When you use a secondary index to look up rows, you need to get the primary key and then go to the aggregated index to find the page where the row data is located, and then load the page into memory to iterate through the row data.
Cost of I/O
To better estimate the time cost of a query, we need to specify some underlying assumptions that run throughout the text.
- Random I/O speed of the disk: 10ms per page.
- Sequential I/O speed of the disk: 160MB/s.
Disk performance depends on the specific hardware level, but the order of magnitude relationship is essentially the same and we just need to keep this rough figure in mind.
The random I/O of a disk represents the addressing capability of the disk, i.e. the average time required for a head seek to read a page of data at a specified location and transfer it out. Although the sequential read/write speed of disks has been greatly improved nowadays, the time overhead for a random read is still huge.
In the database system, random reading and sequential reading of a large number of data pages required time gap is huge, for example, random reading of 10000 pages need time cost is 10000 × 10ms = 100s, if it is sequential reading, then only a random I/O time plus the time required for sequential reading of 160MB (estimated at 16KB per page): 10ms + 10000 × 16KB ÷ 160MB/s = 1.01s.
Assisted Random Reads
We have seen that random reads are very costly, and to reduce this cost, SQL optimizers or database developers optimize for random I/O scenarios. If a series of discrete rows are scanned in the same direction, the access pattern will be jump order and the average I/O time per row will be much shorter than a random access.
Some database systems can proactively create jump-order accesses in cases where the table and index rows are not in the same order. It will first access all index rows that meet the conditions, then sort them in the order of the table pages before accessing the table, turning random I/O into jump-order reads to speed up reads.
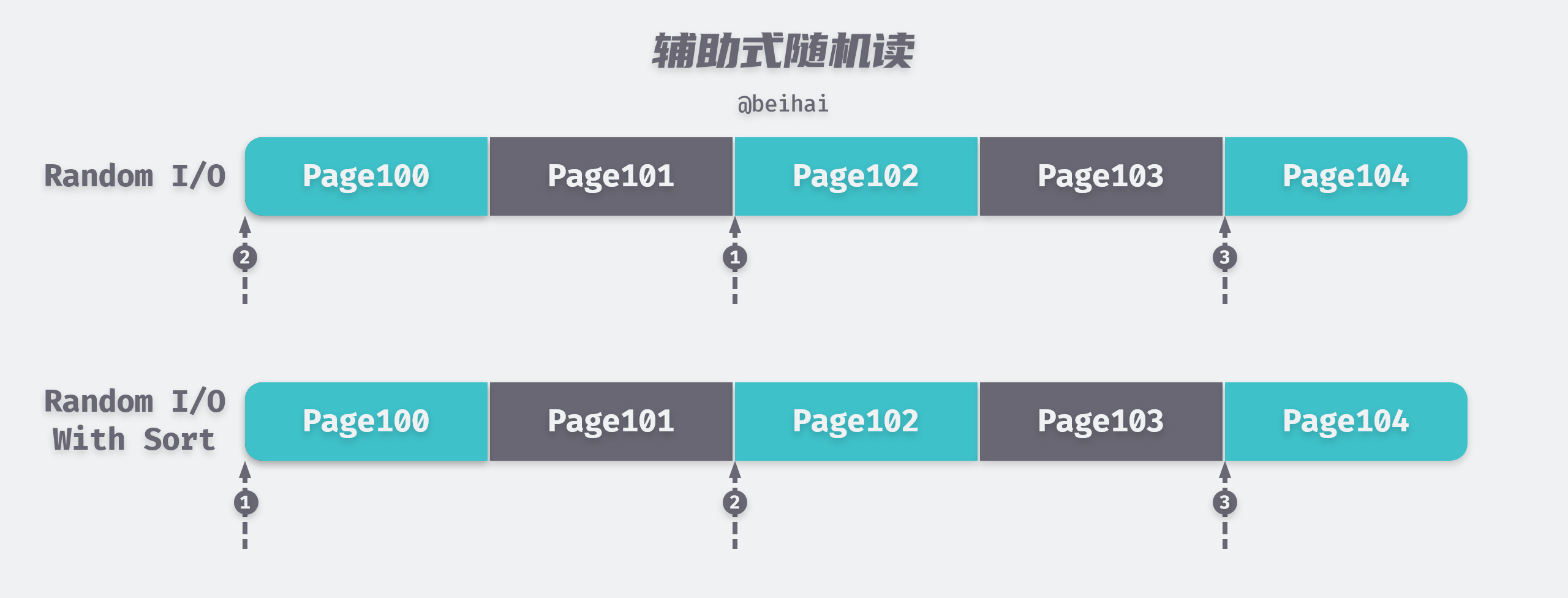
The benefits of jumping sequential reads are amplified in data pre-reading scenarios. For example, when accessing data through aggregated indexes in MySQL, the database instance may read multiple pages forward in advance depending on the data access, and if the SELECT statement accesses index pages or data pages in an almost sequential manner, it will greatly increase the hit rate of pre-reading data and improve I/O efficiency.
Buffering
Due to the divide between CPU speed and disk speed, disk-based database systems often use buffering techniques to improve the overall performance of the database. Database systems cache frequently accessed pages in memory, and when an index or data page is requested, it is looked up from the memory buffer first, and if it is not in the memory buffer, then it is looked up from the disk buffer, and only if the data is not in any buffer is a read request made to the disk drive.
Although it is not officially stated that MySQL has this mechanism, we can assume that all index pages are cached in memory. a B+ Tree in MySQL is usually 3 to 4 levels high, and with an average length of 100 bytes of index page row data (index page row data does not take up much space), and taking into account discrete free space, a page can contain roughly 100 indexed rows of data. For example, a four-tier table with one million index rows would have about 10,000 index pages and occupy less than 200 MB of memory, which is affordable for today’s machine configurations, even with multiple indexes for one row of data.
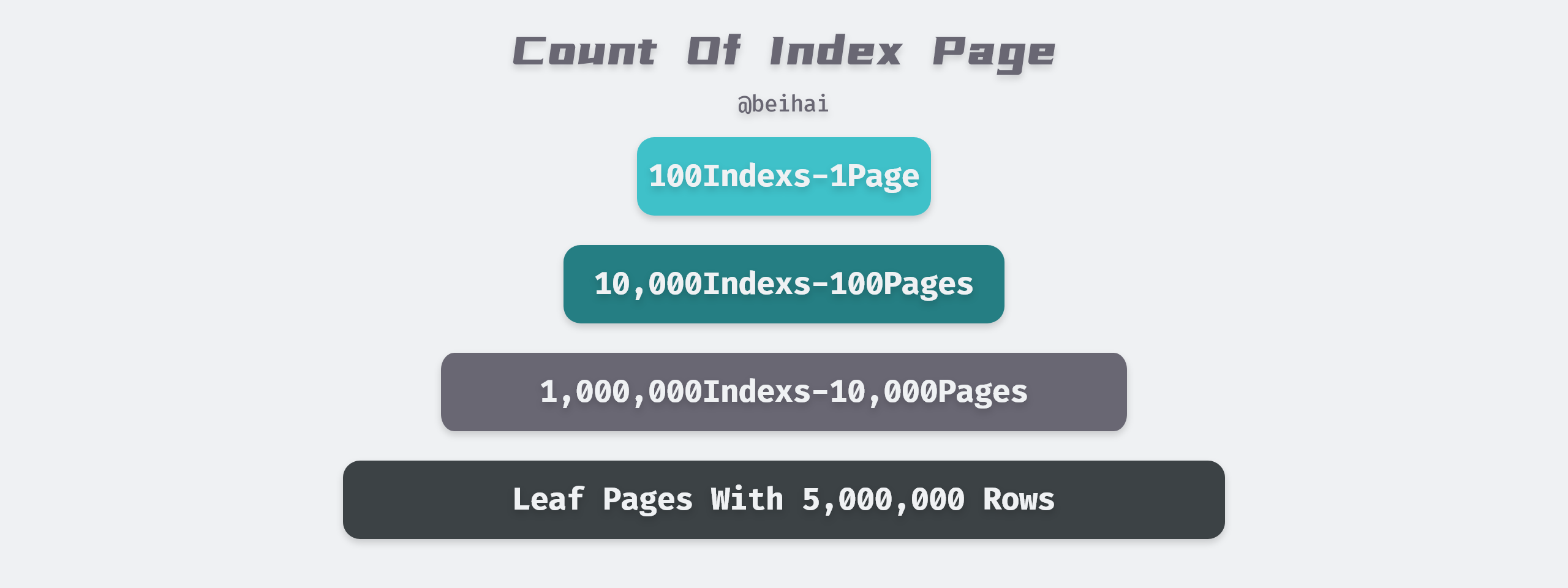
In contrast, the cost of reading data from the memory buffer is so low that this time consumption can usually be ignored. A single query of an aggregated index for a B+ Tree of level 4 requires access to four pages: three index pages and one data page, but only one random I/O is required, which, together with the data pre-reading mechanism, greatly reduces the time required for the query.
Summary of this section
As you can see from the above, the impact of random I/O on performance is huge. In order to improve the performance of the system, auxiliary random reads and data buffering have been adopted to reduce the occurrence of random I/O. When designing indexes, more consideration should be given to optimizing this aspect as well.
SQL Optimizer
In a relational database system, the optimizer is the core of SQL processing. Before a SQL statement can be actually executed, the optimizer must first determine the access path to the data. Designing appropriate indexes for query statements can help the SQL optimizer choose a better data access path.
Index Slice
An index slice is a fragment of an index scanned during the execution of a SQL query, and the indexes in this range will be scanned sequentially, and the cost of the access path depends greatly on the thickness of the index slice. The thicker the index slice is, the more index pages need to be scanned sequentially and the corresponding row data needs to be read from the table simultaneously. If the index slice is thinner, the number of random I/Os required for synchronous reads can be reduced.
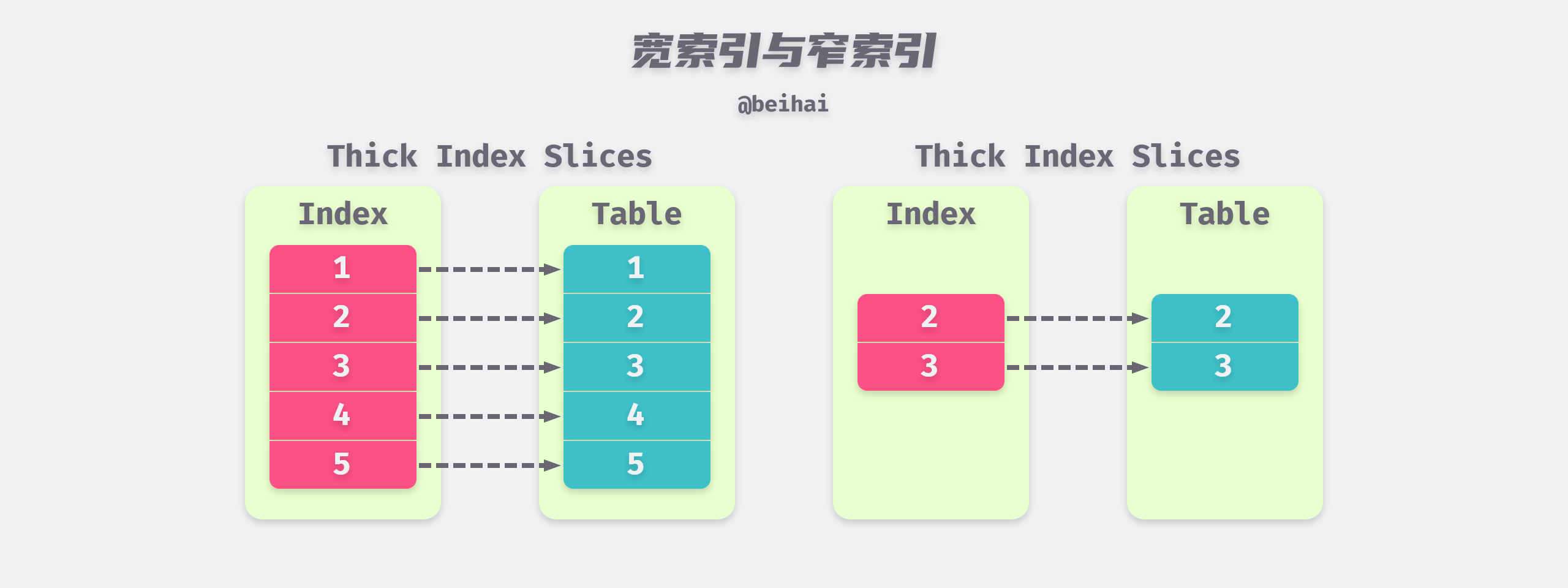
In addition, indexes can be classified as wide indexes or narrow indexes depending on the number of columns they contain: if an index contains all the data columns needed for a SELECT statement, then it is a wide index; if one or more of the data columns needed for a query are not on the index, then it is a narrow index. For the SQL statement SELECT id, title, author FROM pages WHERE author="beihai", (author, title, id) is a wide index for the query, and (author, id) is a narrow index for the query because the index does not contain the title column.
Wide indexes are able to avoid secondary random I/O, while narrow indexes require additional random read operations to be performed to obtain the remaining data from the aggregated index after a sequential read of the index, which can lead to too many random reads and affect performance if the result set is very large.
Matching and Filtering Columns
The conditional expression after the WHERE clause is used to help the SQL optimizer to define the index slice range, but not all conditional expressions can match on the index. Those that can match on an index are called matching columns, and their matching rules are as follows.
- In the WHERE clause, if the column has a equivalent conditional expression corresponding to it, then the column is a matching column, if not, then the column and the indexed columns following it are non-matching columns.
- If the column possesses a range conditional expression, then the remaining index columns are all non-matching columns.
- The index column after the last matching column is a filter column if it possesses an equivalence conditional expression corresponding to it.
In particular, the order of the columns in the above rule is the order of the columns in the index, not the order of the conditional expressions in the SQL statement.
Suppose there is a secondary index (author, years, tags) in the pages table, when we use the following query statement.
Although we have (author, years, tags) index which contains all the columns in the above query, but according to the above rule, only author and years are the matching columns in this SQL statement, MySQL will scan all the data rows which meet the condition, and then use tags as the filter column to filter the data rows which meet the condition.

Filter columns do not reduce the size of index slices, but they do reduce the number of random I/Os and play a very important role in indexing.
Filter Factor
The Filter Factor is the proportion of the total number of rows in the table that satisfy the conditional expression, and represents the distribution of column values. For example, in the pages table, a filter factor of 0.1% for tags="MySQL" would result in a query with 10,000 rows of data. When designing indexes, you can use the filtering factor to help us get thinner slices of indexes.
If the columns that make up a conditional expression are non-correlated, the filtering factor of a joint index can be obtained by multiplying the filtering factors of individual indexes directly. For example, the filter factor of index (author, years, tags) can be calculated by FF(author) × FF(years) × FF(tags). If the filtering factor of each column is 1%, then the filtering factor of the combined condition has reached one millionth, which greatly reduces the thickness of the index piece.
When using the product directly to calculate the filter factor for a combination of conditions, a special attention needs to be paid to one issue: there should not be too strong correlation between columns, and if there is correlation between different columns, then the actual filter factor will deviate significantly from the one obtained by direct multiplication. For example, there is a very strong correlation between the city and the postal code, but this is not a big problem in most cases.
In practice, the filter factors for different values of the same column can also be very different, e.g. the number of users with an age of 30 is much larger than the number with an age of 100, which results in a significant difference in query performance between different values of the same column. When we evaluate the suitability of an index, the worst-case filtering factor is more important than the average filtering factor because queries in the worst input case will consume the most time, and some SQL statements that work well in the average case may not finish on time in the worst environment.
Summary of this section
The SQL optimizer determines the number of indexes to be scanned sequentially and the number of random I/Os to be performed, and we need to optimize for this aspect when designing indexes to design a suitable index for the query statement
Index Design
After understanding the basics, you can design a suitable index for these principles. First, let’s discuss an extreme case: the ideal index for a query statement.
Three-star index
If a SQL statement uses a three-star index, then a query usually requires only one random disk read and one scan of a narrow index slice. For a SQL statement to achieve a three-star index, the following conditions need to be met.
- the first star: find all columns of the equivalence conditional expression in the WHERE conditional statement and use them as the starting columns in the index.
- the second star: adding the columns in GROUP BY and ORDER BY to the index.
- third star: add the columns contained in the SELECT statement to the index slice.
For example, for the following SQL statement, the index (author, years, tags, title, id) is a three-star index of this query statement.
Each star of the three-star index has its own role in reducing the time overhead required for queries from different perspectives.
- the first star serves to reduce the thickness of the index slice in order to reduce the number of index rows that need to be scanned sequentially.
- the second star is used to avoid the need for a sort for each query to reduce CPU and memory usage.
- the third star is used to avoid a large number of secondary random I/Os.
As you can see, the index that satisfies the third star is also the wide index mentioned above. In fact, the third star is also the easiest to obtain, and you only need to add the columns contained in the SELECT statement to the index slice. A three-star index increases the number of index columns, which not only increases the pressure on the buffer if the data volume is large, but also increases the cost of maintenance by requiring synchronous updates to the columns in the index when updating row data.
It should be noted that in some complex queries, we may not be able to get both the first star and the second star.
In the above query statement, if we want to get the first star, the prefix of the index must be (author, years), then the second star cannot be obtained because the column tags which needs to be sorted is behind the range index column years, so we cannot get the sorted tags column directly from the index, we must do a sorting operation in the memory, in this case In this case, the final index is (author, years, tags, id). If we want to avoid sorting, we need to swap the positions of tags and years, sacrificing the thinness of the index slice, and end up with the index (author, tags, years, id).
For a SQL statement, a three-star index is the ideal way to index, but there is a trade-off at runtime, usually two out of three stars (1,3 or 2,3) are enough to meet the requirement.
Summary
In general, the most important issue when designing indexes is how to reduce the number of random reads. The design principles of three-star indexes are: minimizing index slices, avoiding sorting at runtime, and avoiding secondary queries. The process of following the above principles to design the best index for each query is simple, but Samsung is not suitable for all query cases, and the maintenance cost of indexes also needs to be considered when using them, such as whether the indexes are duplicated, whether they can be shared, the overhead of index updates, etc. The ultimate goal of index design is to make query statements fast and economical.