Raft is a consistency protocol based on a message-passing communication model for managing log replication, which allows a group of machines to work as a whole and provide services even if some of them have errors. The Paxos protocol was the first proven consistency algorithm before Raft was proposed, but the principles of Paxos were difficult to understand and engineer. Raft is an implementation of Paxos that aims to provide a better understood algorithm and has been shown to provide the same fault tolerance and performance as Paxos.
Overview
Raft is a distributed consensus algorithm that can be used as an alternative to Paxos, and it is easier to understand and implement than Paxos. In order to achieve the goal of easy understanding, Raft uses problem decomposition to divide the complex problem of ‘replicated cluster node consistency’ into four sub-problems that can be independently explained and handled: Leader Election, Log Replication, Safety, and Membership Changes.
In this paper, we introduce the mechanism of Raft’s algorithm from these four aspects.

Data consistency
There are two models for node communication in distributed systems: Shared Memory and Messages Passing. Distributed systems based on the message-passing communication model are inevitably subject to the following errors: processes run slowly, get killed, or restart, and messages may be delayed, lost, or duplicated as a result. The Paxos algorithm solves this problem without considering the Byzantine General problem, how to agree on a value in a distributed system where the above exceptions may occur, ensuring that the consensus is not broken regardless of any of the above exceptions, i.e., ensuring data consistency.
Three common consistency models in distributed systems.
- Strong consistency: when an update operation is executed successfully on a particular replica, all subsequent read operations should be able to obtain the latest data.
- Weak consistency: when updating a certain data, it takes a delay for users to read the latest data.
- Final Consistency: It is a special kind of weak consistency, when a certain data is updated, after a time slice, all subsequent operations are able to get the new data, and within this time slice, the data may be inconsistent.
Raft is a strong consistency algorithm in the distributed domain. When one of the nodes receives a set of instructions from a client, it must communicate with the other nodes to ensure that all nodes receive the same instructions in the same order, and eventually all nodes will produce consistent results, just like a machine.
State Machine Replication
In a distributed environment, if we want to make a service fault-tolerant, the most common way is to have multiple copies of a service running on different nodes at the same time. State Machine Replication is used to ensure that the state of multiple replicas is synchronized at runtime, i.e., that the client gets the same result regardless of which node it sends the request to.
Each server node stores a log containing a series of commands, and its state machine executes the commands in the log sequentially, with the same commands in each log and in the same order, so that each state machine processes the same sequence of commands, which results in the same state and output sequence.
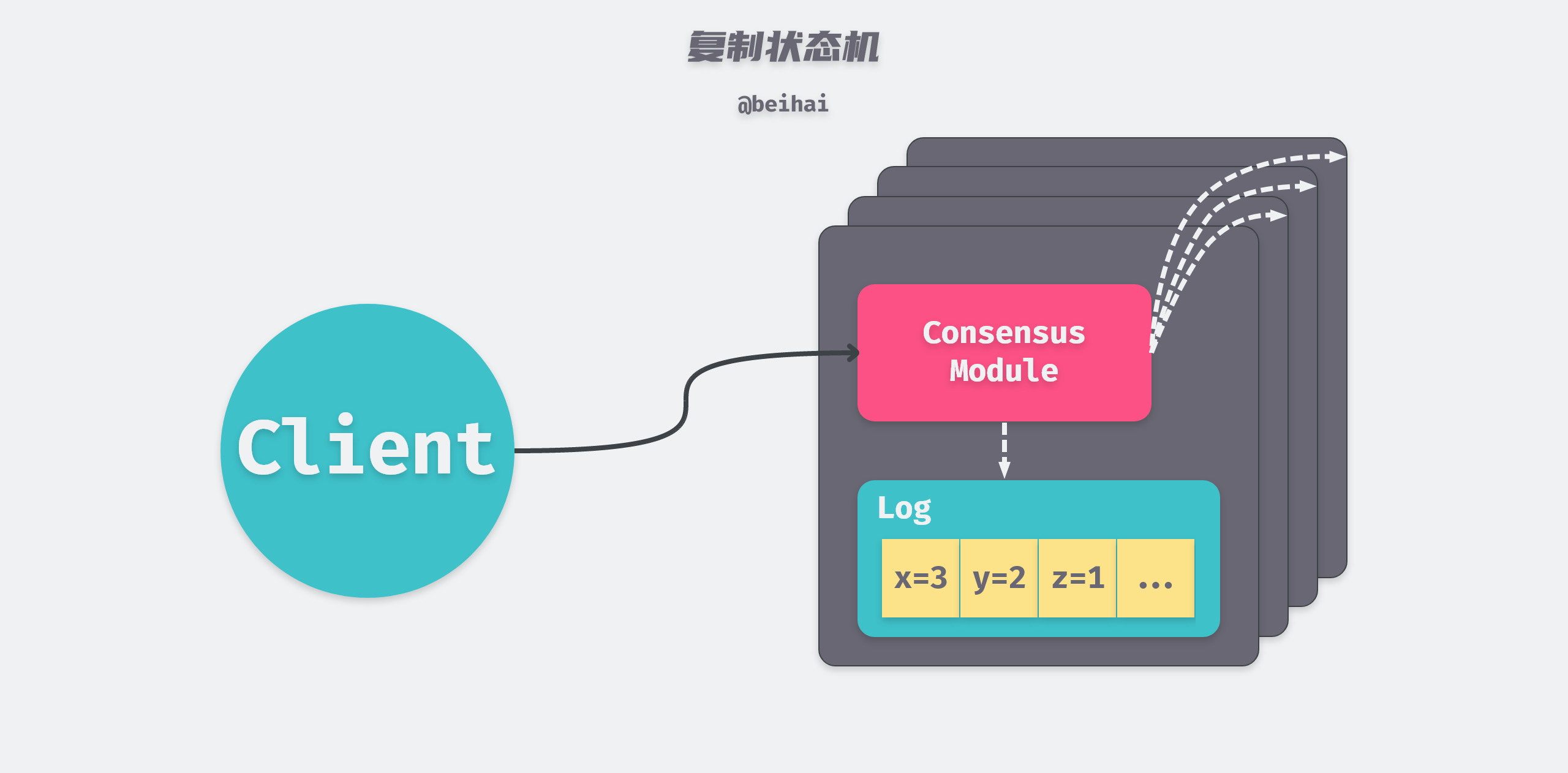
Raft’s job is to ensure that the replication logs are consistent, with the Consensus module on the server receiving commands from the client and adding them to the logs. The server then communicates with the Consensus modules on the other servers to ensure that the same log sequence is available on each server, even if a small number of servers fail to communicate. The state machine on each server executes the commands sequentially and returns the output to the client, thus creating a highly available replicated state machine.
The Raft algorithm, like the Paxos algorithm, has the following properties of distributed consensus algorithms.
- security (no incorrect results are returned) under all non-Byzantine conditions (including network latency, partitioning and packet loss, duplication, disorder).
- The consistency algorithm is available as long as more than half (n/2+1) of the servers are operational and can communicate with each other and with clients. Thus, a typical cluster of five servers can tolerate the failure of any two servers. they can later recover their state and rejoin the cluster if a server suddenly goes down.
- that they do not rely on timing to ensure consistent logging, since faulty clocks and extreme message delays can cause availability problems in the worst case.
- In general, commands can be completed as long as most servers in the cluster have responded to a single round of remote procedure calls, and a few slow servers will not affect overall system performance.
Leader Election
Raft is an algorithm used to manage the log replication process described above. Raft elects a Leader through a “leader election mechanism” that manages log replication for consistency. A Raft cluster contains several server nodes, each with a unique ID, and at any given moment, each server node is in one of the following three states.
- Leader: The Leader handles all client requests, in the usual case there is only one Leader in the system and all other nodes are Follower.
- Follower: the Follower does not send any requests, but simply responds to requests from the Leader or Candidate, and if a client contacts the Follower, then the Follower redirects the request to the Leader.
- Candidate: If the Follower does not receive a message from the Leader, then it becomes Candidate and initiates an election, and the candidate with the majority of votes in the cluster (more than n/2+1) becomes the new Leader.

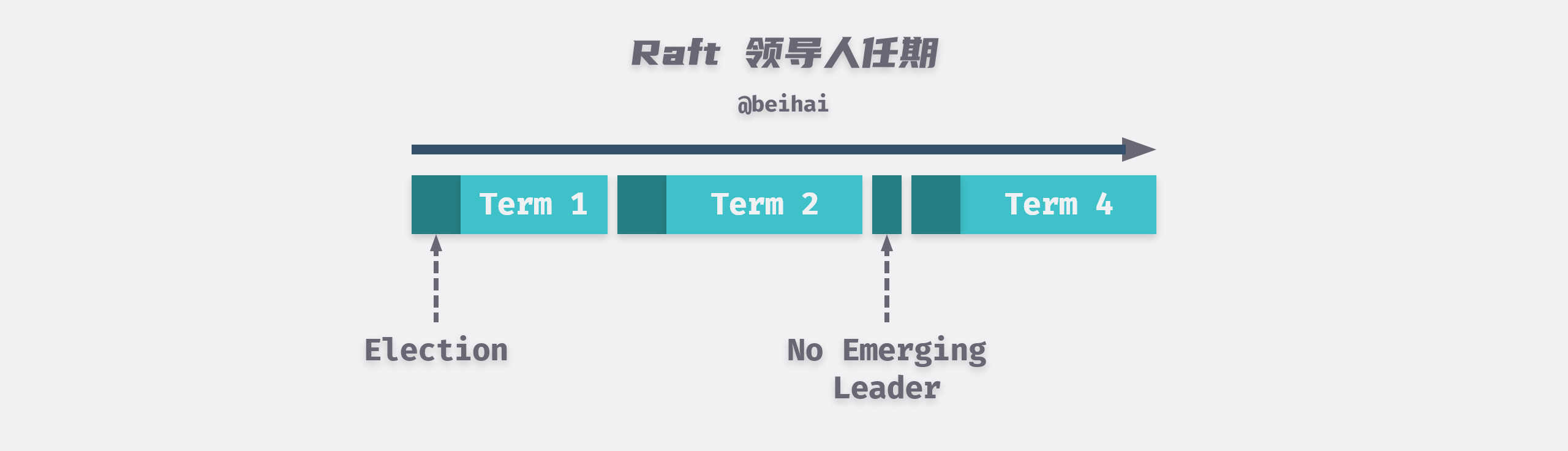
Raft splits time into arbitrary lengths of Term (Term), which are marked by consecutive integers. Each Term begins with an election, and if a Candidate wins the election, it serves as the leader for that term. In some cases, an election may be split, with each Candidate receiving less than n/2+1 votes. The term then ends without a Leader, and a new term and a new election begin again.
Raft guarantees that there will be at most one Leader for a given term.
Node communication
Nodes in a cluster communicate using Remote Procedure Calls (RPCs). There are three types of RPCs in Raft: AppendEntries RPC initiated by the Leader; RequestVote RPC initiated by the Candidate during an election; and InstallSnapshot RPC initiated by the Leader to send snapshots to the Follower who is behind in the logs. The first two RPCs are described first in this subsection.
AppendEntries RPC is used for log replication and heartbeat messages. The Leader sends client commands to all nodes in parallel via the AppendEntries RPC, which contains the following main fields.
| parameters | meaning |
|---|---|
| term | Leader’s term number |
| leaderId | Leader Id to allow followers to redirect requests |
| prevLogIndex | Index value of the previous log entry |
| prevLogTerm | Previous log entry term number |
| entries[] | Log entries ready for storage (empty when indicating heartbeat messages; more than one can be sent at a time to improve communication efficiency) |
| leaderCommit | The index value of the log that the Leader has committed |
RequestVote RPC is used for Candidate to initiate elections to other nodes, with the following main elements.
| parameters | meaning |
|---|---|
| term | Candidate’s term number |
| candidateId | Candidate Id for ballot request |
| lastLogIndex | Candidate Index value of the last log entry |
| lastLogTerm | Candidate The term number of the last log entry |
Election process
When a Raft cluster is started, all nodes are in Follower status, and a node remains in Follower status when it receives a valid RPC from a leader or candidate. the Leader periodically sends heartbeat messages (AppendEntries RPCs without log content) to all followers to maintain its authority. If a Follower does not receive any messages for a period of time, it assumes that there is no leader available in the system and initiates an election to select a new leader.
Note that a node maintains the Follower state as long as it receives a valid RPC from another node. If the term of the RPC sender is small, then the receiving node ignores the message.
To start an election process, a Follower first adds 1 to its current term number and converts to Candidate, then it sends a RequestVote RPC to the other nodes in the cluster to vote for itself in parallel.
-
The first is that it wins the election itself: When a Candidate receives votes for the same term number from most of the nodes in the cluster, it wins the election and becomes the leader. Each node casts at most one ballot for a term number on a first-come, first-served basis, and once the Candidate wins the election, it immediately becomes the Leader, and then it sends heartbeat messages to the other nodes to establish its authority and prevent the creation of a new Leader.
-
The second case is when another node becomes Leader: While waiting for a vote, Candidate may receive an AppendEntries RPC from another server node declaring that it is the leader, and if this node’s
termfield is not less than Candidate’s current term number, then Candidate will recognize the Leader’s legitimacy and returns to the Follower state. If the term number in this RPC is smaller than its own, then Candidate rejects the RPC and remains in Candidate status. -
The third scenario is that if more than one Follower becomes a Candidate at the same time, the votes may be split so that no Candidate can win the majority of the nodes. When this happens, the Candidate will experience an election timeout and then add the current term number to start a new round of elections.

The first two cases are better understood, but in the third case, without an additional mechanism, each Candidate will enter the election timeout state and open the next round of election, and the votes may be repeatedly divided indefinitely. To avoid clusters getting stuck in a dead-end election loop, Raft uses Random Election Timeout to solve this problem.
Random election timeout
The Raft algorithm uses a random election timeout mechanism to ensure that vote splitting rarely occurs. The election timeout is chosen randomly from a fixed interval (e.g., 150-300 ms), so that the election timeouts are spread out and in most cases only one Candidate will time out.
The same mechanism is used in the case of ballot splitting. Each candidate resets a random election timeout at the beginning of an election, and waits for the results of the vote during the timeout, thus reducing the possibility of additional vote splitting in a new election.
Leadership elections are the most critical aspect of Raft in terms of time requirements. In order for Raft to elect and maintain a stable leader, the system needs to meet the following timing requirements.
|
|
The broadcast time is the average time it takes to send an RPC from one server node to the other nodes in the cluster in parallel and receive a response. The mean time between failures is the average time between failures for a server.
Raft requires the broadcast time to be an order of magnitude smaller than the election timeout, so a broadcast time of about 10ms is required to meet the election timeout requirement. The mean time between failures requirement is easy to achieve for a stable server that does not go down every few minutes.
Log Replication
When the Leader is elected, it starts serving the client. Each request from a client contains an instruction that is executed by the state machine. The Leader appends this instruction to the log as a new log entry and then launches an AppendEntries RPC to other nodes in parallel. When this log entry is safely replicated, the Leader applies the log entry to its state machine (which executes the instruction) and then returns the result of the execution to the client. If the Follower crashes or runs slowly or loses packets on the network, the Leader keeps retrying to send AppendEntries RPCs (even if the Leader has replied to the client) until all Follower eventually stores all log entries.
Each log entry stores a State Machine Instruction and the Leader’s Term Number when it receives that instruction. The term number is used to detect inconsistencies between multiple copies of the log, and each log entry has an integer index value to indicate its position in the log.
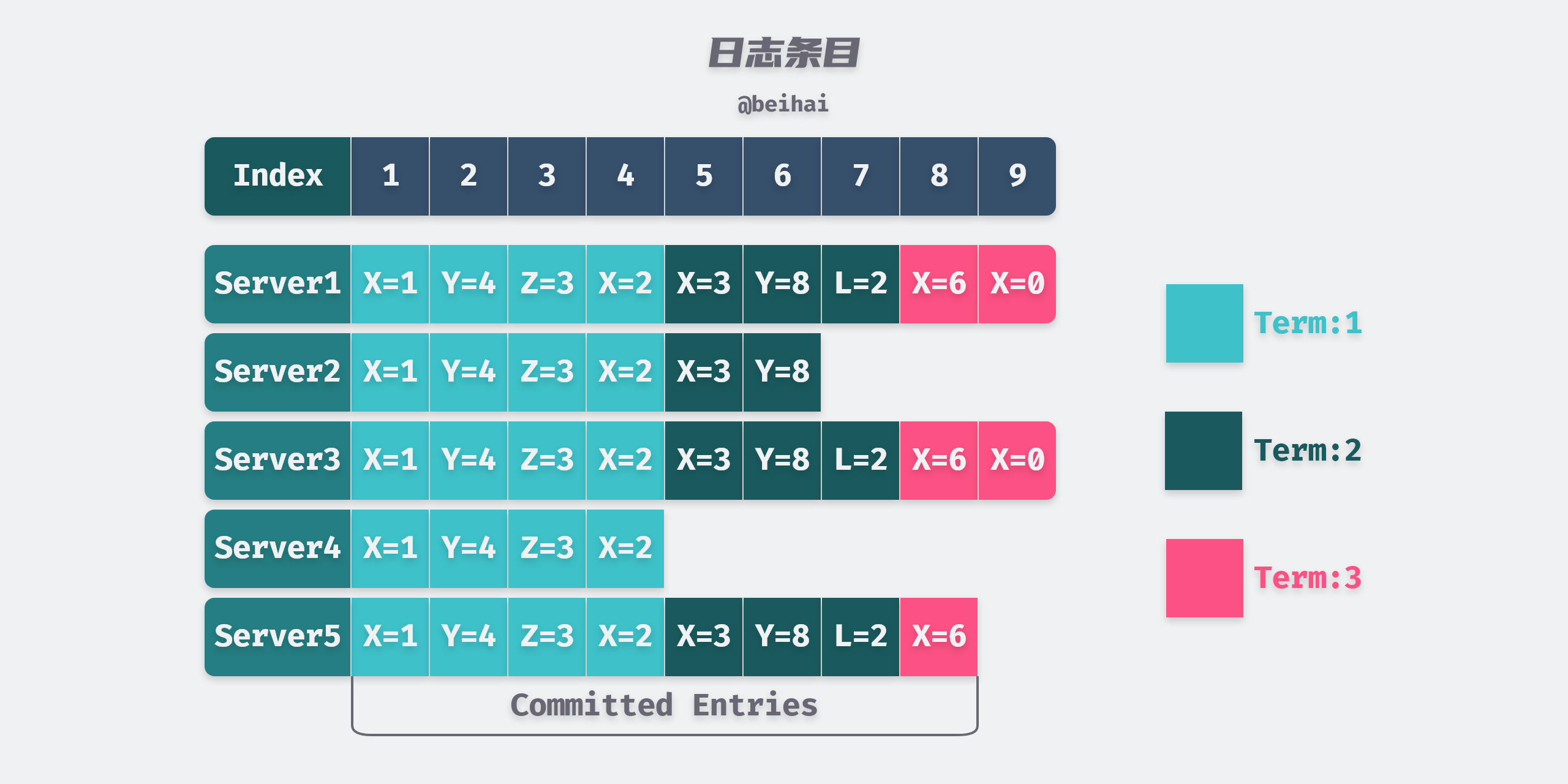
The Leader decides when it is safe to apply a log entry to a state machine: such log entries are called Committed. The Raft algorithm ensures that all committed log entries are persistent and will eventually be executed by all available state machines. Once the Leader that created the log entry copies it to more than half of the servers, the log entry is committed. At the same time, all log entries prior to that log entry in the Leader’s log are committed, including those created by other Leaders.
Log Matching
Raft has a logging mechanism to maintain a high level of consistency in logs across servers. This not only simplifies and makes the system behavior more predictable, but is also an important part of security.
Raft maintains the following Log Matching features.
- If two entries in different logs have the same index and term number, then they store the same command.
- If two entries in different logs have the same index and term number, then all their previous log entries are also the same.
The Leader creates at most one log entry at a log index within a specific term number, while the location of the log entry in the log never changes either, a point that guarantees the first characteristic. The second feature is guaranteed by the AppendEntries RPC performing a simple consistency check: when sending the AppendEntries RPC, the Leader includes the index location prevLogIndex and the term number prevLogTerm of the previous log entry. If the Follower cannot find an entry in its logs that contains the same index location and term number, then he rejects the new log entry.
Thus, whenever the AppendEntries RPC returns a success, the Leader knows that the Follower’s log must be the same as its own. However, a Leader crash will leave the log in an inconsistent state.
Log consistency checking
In the Raft algorithm, the Leader handles inconsistencies by forcing the Follower to replicate its own logs - this means that conflicting log entries in the Follower are overwritten by the Leader’s logs.
To keep the Follower’s logs and the Leader in a consistent state, the Leader must find the last log entry that they agree on, then delete all logs from the Follower after that log entry and send its own logs to the Follower. These operations are done during the consistency check of the AppendEntries RPC.
The Leader maintains a nextIndex field for each Follower, indicating the index value of the next log entry to be sent to that Follower. When a Leader first gains power, he initializes all nextIndex values to the index of his last log plus 1.
If a Follower’s logs do not match the Leader’s, then the consistency check fails on the next RPC of the additional logs. After being rejected by the Follower, the Leader decreases the nextIndex value and retries. Eventually nextIndex will be at a point where both parties agree. Then a log overwrite operation is performed to make the Follower’s log consistent with the Leader’s.
With the log consistency check mechanism, the Leader does not need any special operation to restore consistency when it gains power. the Follower log automatically converges when the consistency check of AppendEntries RPC fails.
Safety
Since the Raft algorithm ensures data consistency by forcing the Follower logs to be overwritten, and the Leader has the Append-Only feature of never overwriting or deleting its own logs. If a node with a small number of log entries is elected as Leader, it can cause a large amount of data loss. To avoid this, Raft adds some restrictions to the leader election to ensure that any Leader has all committed log entries for a given term number.
Election restrictions
The transfer of log entries in Raft is one-way, only from the Leader to the Follower, and the Leader never overwrites entries that already exist in its own local log. Raft therefore uses voting to prevent a Candidate from winning an election unless that Candidate contains all the log entries that have been submitted.
The Candidate must contact most of the nodes in the cluster in order to win the election, which means that every log entry that has been submitted must exist on at least one node in the cluster. If Candidate’s logs are as new as most of the nodes, then he must have all the committed log entries.
The RequestVote RPC implements the restriction that the RPC contains the Candidate’s log information, and Follower rejects voting requests from Candidates whose logs are not new themselves.
Raft defines whose log is newer by comparing the
lastLogIndexandtermof the last log entry in the two logs. If the last entries of the two logs have differentterm, then the log with the largertermis more recent. If the last entrytermof both logs is the same, then the log with the largerlastLogIndexis newer.
Membership Changes
While the project is running, we may change the configuration of the cluster, such as adding nodes or machines to the configuration. Although this can be done by taking the entire cluster offline, updating all configurations, and then restarting the entire cluster, the cluster will be unavailable for the duration of the change. In addition, if there are manual steps, there is a risk of operational errors. To avoid these problems, Raft incorporates configuration change automation into the algorithm.
In order to make the configuration change mechanism secure, there cannot be any point in time during the conversion process that makes it possible to elect multiple Leaders in the same term. However, any solution where the server directly switches from the old configuration to the new configuration is not safe, because it is impossible to make all nodes switch from the old configuration to the new configuration at the same moment when the members change, then directly switching from the old configuration to the new configuration there may be a node that satisfies the ‘more than half’ principle for both the old and new configurations.
It is not safe to go directly from one configuration to another because the individual machines will switch at different times. In the above diagram, the cluster goes from 3 machines to 5 machines. Unfortunately, there exists a point in time where Server1 can become Leader by its own votes and those of Server2 (satisfying the principle of receiving the majority of votes in the old configuration), and Server3 can become Leader by its own votes and those of Server4 and Server5 (satisfying the majority of votes in the new configuration, i.e., the cluster with 5 nodes). votes principle). At this point, the entire cluster may have two Leaders in the same term, which is contrary to the protocol.
Common Consistency
For security purposes, Raft configuration changes are made using a two-phase approach. During the configuration change process old and new configurations are not aware of each other, and configuration turnover cannot be done overnight. So before configuration turnover, the cluster is guided into a transition phase so that neither the machines using the new configuration nor the old configuration process logs independently. In Raft, the cluster first switches to a transitional configuration, called a common consistent state, and once the common consistency is committed, then the system switches to the new configuration.
The first phase is called joint consensus, when joint consensus is committed and switched to the new configuration, in the first phase.
- log entries are replicated to all servers in the cluster in both the old and new configurations.
- servers in both the old and new configurations can become Leaders.
- reaching consensus (for election and commit) requires majority support on both configurations separately.
The specific switching process is as follows.
- when the Leader receives a configuration change request, it creates a log
C-old-newcontaining the old and new configurations and replicates it to the other nodes. - the Follower makes a decision with the latest configuration present in the log, even if it is not committed, and the Leader makes a decision with this configuration only after
C-old-newis copied to most nodes, which is in the process of co-decision. - the new configuration is later committed to all nodes and once the new configuration is committed, the old configuration is discarded.
Once a server adds a new configuration log entry to its log, he uses that configuration to make all future decisions (the server always uses the latest configuration, whether it has been committed or not). Co-consistency allows independent servers to perform the configuration transition process at different times without compromising security. In addition, common consistency allows clusters to still respond to client requests during configuration transitions.
Boundary issues
There are three more boundary issues to resolve regarding the reconfiguration. The first issue is that the new servers do not store any log entries when they are initialized. When these servers are added to the cluster in this state, it takes a while for updates to catch up. To avoid this availability interval, Raft uses an additional phase before configuration updates in which new servers join the cluster as non-voting (leaders replicate logs to them, but do not consider them a majority). Once the new server catches up with the other machines in the cluster, reconfiguration can be handled as described above.
The second problem is that the Leader of the cluster may not be part of the new configuration. In this case, the Leader will fall back to the Follower state after committing the new configuration log. This means that there is a period of time when the Leader manages the cluster but not himself; he replicates the logs but does not count himself as one of the nodes. The Leader transition occurs when the new configuration is committed, because this is the earliest point at which the new configuration can work independently, before which the leader may only be selected from the old configuration.
The third issue is that removing servers that are not in the new configuration may disrupt the cluster. These servers will no longer receive heartbeats, so when the election times out, they will perform a new election process. They will send a RequestVote RPC with a new term number, which will cause the current Leader to fall back into the Follower state. A new Leader is eventually elected, but the removed server will time out again, and the process will then repeat itself, resulting in a significant reduction in overall availability.
To avoid this problem, the server ignores the RequestVote RPC when it confirms the existence of the current Leader. when the server receives a RequestVote RPC within the current minimum election timeout, it does not update the current term number or cast a ballot. Each server waits at least one minimum election timeout before starting an election. This helps to avoid disruption by removed servers: If the leader can send a heartbeat message to the cluster in time, then it will not be deposed by a larger term number.
Network Partitioning
In a cluster, network partitioning occurs when the network of some nodes fails and the connection to another part of the cluster is broken, forming a relatively independent subnet. the Raft algorithm has different countermeasures for network partitioning in different cases.
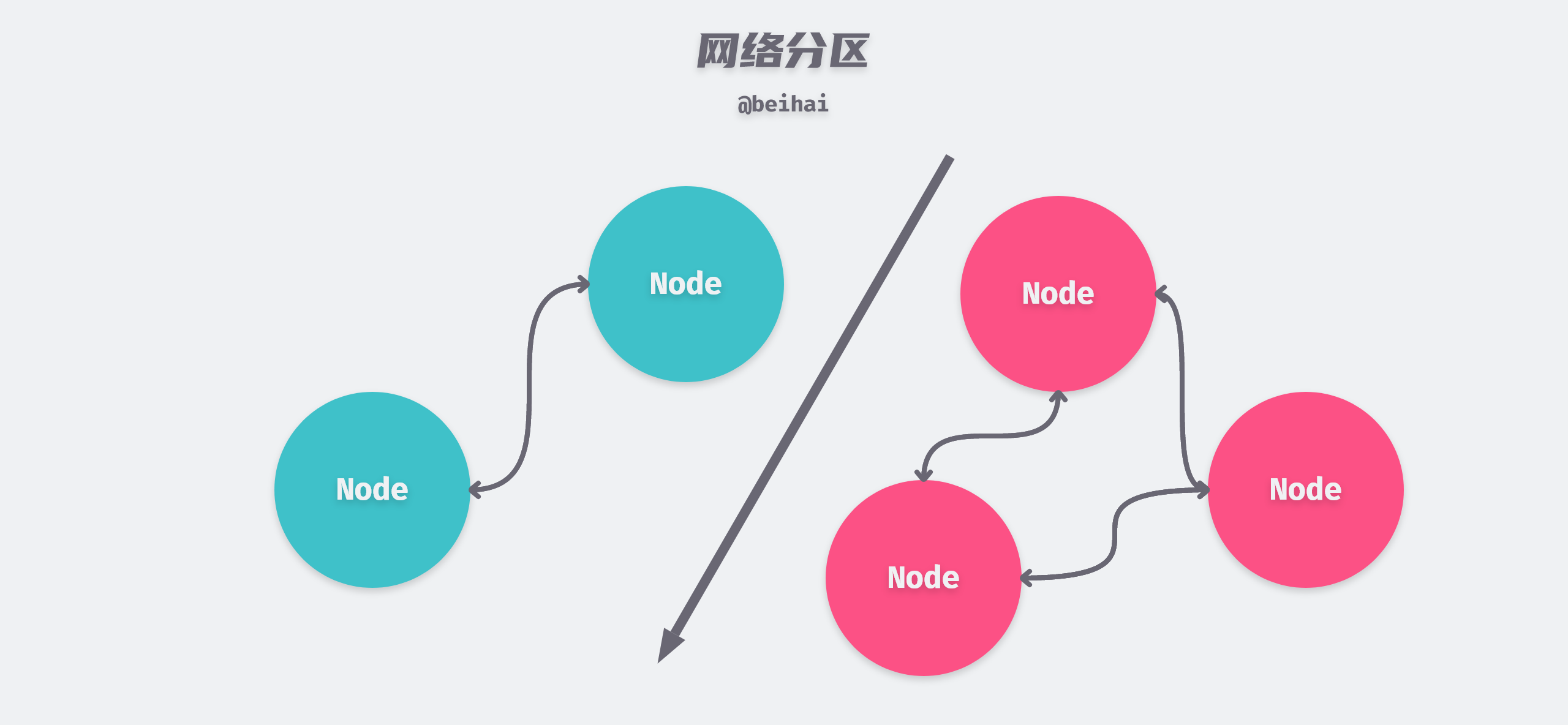
Leader in a few-node partition
In the above figure, assume that Leader node S1 is partitioned in the minority node partition on the left. As time passes, the election timer of the first node in the isolated network partition of the cluster from the Leader node will time out. Assuming that this node is S5, S5 switches to Candidate state and initiates the next round of election. Due to network partitioning, only nodes S4 and S5 in the cluster can receive election requests from node S5, and assuming that node S5 eventually wins the election, there will be two Leaders in the cluster at this time.
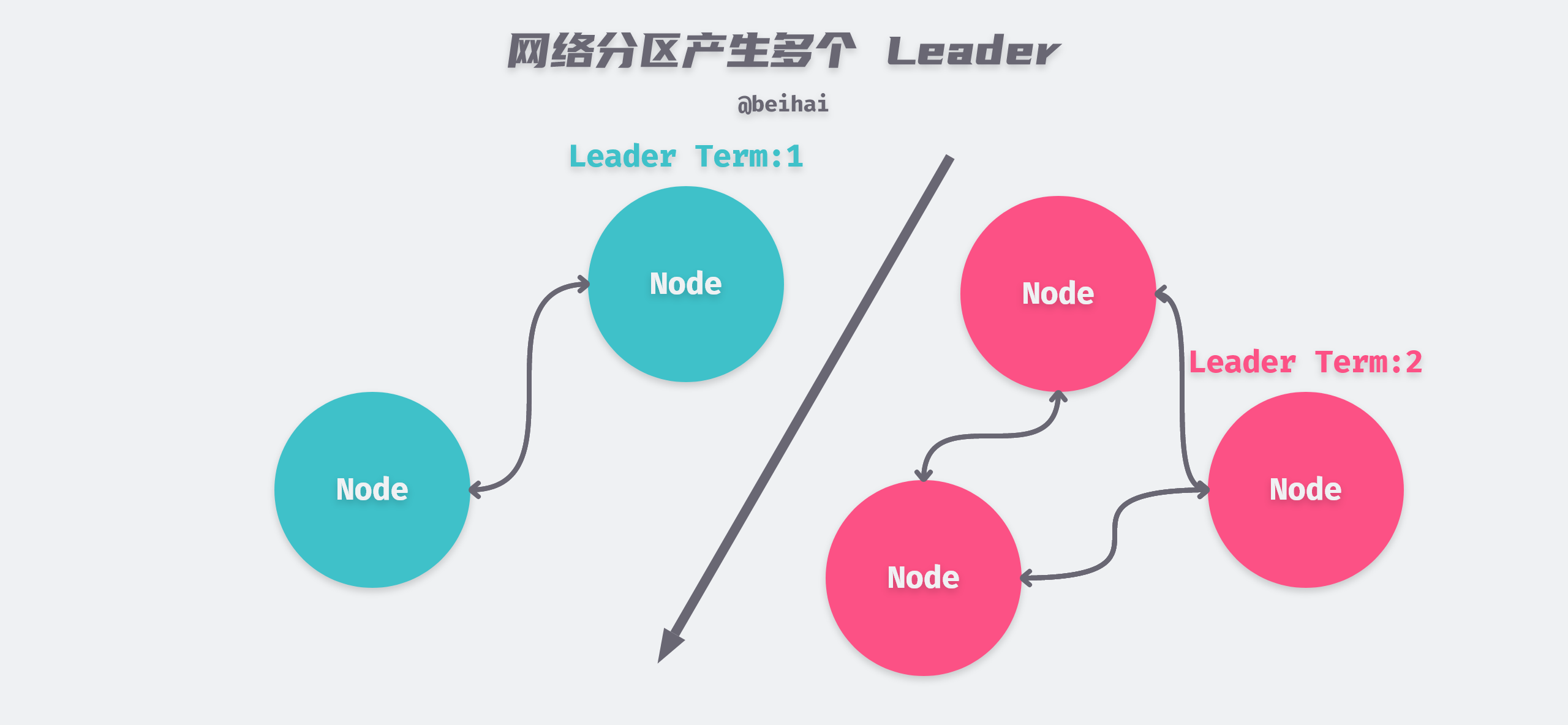
When this happens, the Raft algorithm needs to guarantee the consistency of the data requested by the client, and to solve this problem, the cluster needs to do the following.
- Have the Leader handle the read requests.
- Ensure that the current Leader is still a valid Leader.
When a client first connects to the cluster, it randomly picks a server node to communicate with, and if the node it first picks is a Follower node, it will redirect the request to the Leader node, which will handle the read and write requests. The Leader initiates a broadcast to ensure that most nodes in the cluster are contacted to ensure its authority before processing the client request.
In the above figure, since S1 node cannot communicate with most of the nodes in the cluster, it cannot process the client requests properly and all the requests are processed by S5. Eventually, the data state of S1 partition stays at the moment of partition occurrence, while all data processing after partition occurrence is stored in S5 partition.
When the network partition failure is repaired, the heartbeat messages sent by node S1 will be received by nodes S3, S4, and S5. However, the Term values carried in these heartbeat messages are smaller than the current Term values of S3, S4, and S5 nodes, so they are ignored by S3, S4, and S5 nodes; meanwhile, the heartbeat messages sent by node S5 are received by nodes S1 and S2. Since the Term value of these heartbeat messages is greater than the Term value of current S1 and S2 nodes, nodes S1 and S2 will switch to Follower state, and finally node S5 becomes the Leader of the whole cluster.
Leader in a majority-node partition
If a Leader node is partitioned into a partition with more nodes when the network is partitioned, the election timer of a node in the partition with fewer nodes will time out, switch to Candidate and initiate a new round of election. However, since the number of nodes in the partition is less than half, it is not possible to elect a new Leader, which results in the nodes in the partition continuously initiating elections and increasing the Term number.
Raft protocol deals with this situation, when a node wants to initiate an election, it needs to enter the state of PreVote first, and the node will try to connect to other nodes in the cluster first, and if it can successfully connect to more than half of the nodes, it can switch to Candidate status and actually initiate a new round of election.
Log Compression
When there are more and more logs in the system, they can take up a lot of space.
The Raft algorithm uses a snapshot mechanism to compress the huge logs. At a certain point in time, all the state of the entire system is steadily written to persistable storage, and then all logs after that point in time are cleared.
Usually servers create snapshots independently, but the Leader occasionally sends snapshots to some lagging nodes, such as a slow Follower or a new server joining the cluster, and sends snapshots over the network to bring the Follower up to date.
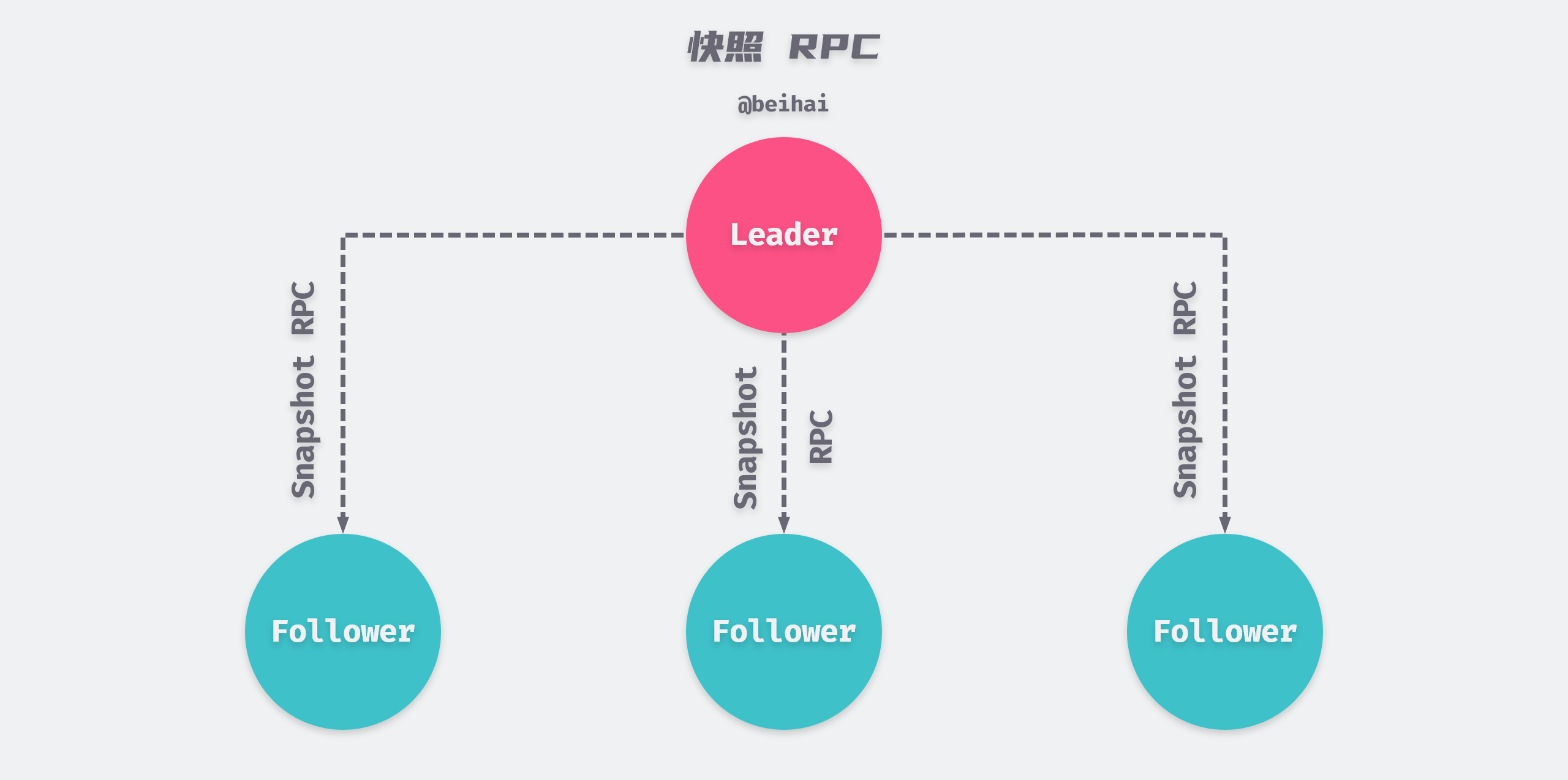
The Leader uses InstallSnapshot RPC chunks to send snapshots to Follower that is too far behind. If the snapshot contains duplicate log entries, then Follower removes the entries that exist in the log and adopts the data in the snapshot.
Follower can create snapshots without the Leader’s knowledge, and although the snapshot approach deviates from Raft’s strong leader principle, we believe the deviation is worthwhile. Leaders exist to resolve conflicts when consistency is reached, but by the time a snapshot is created, consistency has been reached and there is no conflict, so it is possible to do without a Leader. The data is still passed from the Leader to the Follower, but the Follower can reorganize their data.
Summary
The implementation of the Raft algorithm is clear, logically follows human intuition, and is described in detail, taking into account some boundary issues that not only improve Raft’s comprehensibility but also convince of its correctness.
The Raft algorithm decomposes the consensus problem into several relatively independent word problems, and the overall process is that the nodes elect the Leader, who is responsible for log replication and commit. In order to keep the system error-free in any abnormal situation, Raft imposes a number of constraints on leader election and log replication.
- Using random election timeouts to avoid vote splitting.
- Using consistency checks to handle log inconsistencies.
- Keeping new Leader data up-to-date with election restriction policies.
- Using minimum election timeout to ensure the authority of the Leader.
This design idea of decomposing complex problems is a good description of how Raft solves consistency problems in distributed systems, and suggests certain solutions to help developers better apply them to their projects.
The main content and some images are from the paper In Search of an Understandable Consensus Algorithm and Finding an Understandable Consensus Algorithm (extended version)
Reference
https://zh.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86https://zh.wikipedia.org/zh-cn/Paxos%E7%AE%97%E6%B3%95https://zh.wikipedia.org/wiki/Rafthttps://zh.wikipedia.org/wiki/%E6%8B%9C%E5%8D%A0%E5%BA%AD%E5%B0%86%E5%86%9B%E9%97%AE%E9%A2%98https://zh.wikipedia.org/wiki/%E7%8A%B6%E6%80%81%E6%9C%BA%E5%A4%8D%E5%88%B6https://web.stanford.edu/~ouster/cgi-bin/papers/raft-atc14https://github.com/maemual/raft-zh_cn/blob/master/raft-zh_cn.mdhttps://raft.github.io/https://www.jianshu.com/p/2a2ba021f721http://ifeve.com/%E8%A7%A3%E8%AF%BBraft%EF%BC%88%E5%9B%9B-%E6%88%90%E5%91%98%E5%8F%98%E6%9B%B4%EF%BC%89/https://www.infoq.cn/article/cap-twelve-years-later-how-the-rules-have-changed/https://wingsxdu.com/posts/algorithms/raft/