We know that the Go team redefined the team’s release cadence in 2015, setting the frequency of major Go releases to twice a year, with release windows set for February and August each year. The Go 1.5 release, which implements the bootstrap, is the first release under this cadence. Generally, the Go team releases releases in the middle of these two windows, but there have been accidents in the past few years, for example, Go 1.18, which carries the responsibility of generalization implementation, was released with a month delay.
Just when we thought that Go 1.19 would not be released soon, on August 2, 2022 US time, the Go core team officially released Go 1.19, not only within the release window but also earlier than usual. Why? Simple, Go 1.19 is a “small” release, as opposed to a “large” release like Go 1.18. The development cycle for Go 1.19 is only about 2 months (March to early May), so the Go team has compressed the number of features added to Go 1.19.
But despite this, there are still a few changes in Go 1.19 that we should focus on, and I’ll take a look at them with you in this article.
1. Overview
In June (when Go 1.19 was already Freeze), I wrote a “Go 1.19 New Feature Preview”, which briefly introduced some of the new features of Go 1.19 that were basically confirmed at that time, and now it looks like Go 1.19 is not very different from the official version.
-
Generics
Considering that Go 1.18 generic types have just landed, the generic types in Go 1.18 version are not the full version. However, Go 1.19 also did not rush to implement those features in the generic design document) that have not yet been implemented, but instead The main focus has been on fixing the generic implementation issues found in Go 1.18, in order to solidify the base of Go generic To lay the foundation for Go 1.20 and subsequent versions to achieve the full version of the generic type (details can be found in the article “Go 1.19 New Feature Preview”).
-
Other syntax aspects
None.
In this way, Go 1.19 still maintains the Go1 compatibility promise.
-
Officially support Longxin architecture on linux (GOOS=linux, GOARCH=loong64)
This has to be mentioned, because this change is all contributed by the domestic Longcore team. However, the minimum version of linux kernel currently supported by Longxin is also 5.19, which means that Longxin is not yet able to use Go on older versions of linux.
-
go env supports
CGO_CFLAGS,CGO_CPPFLAGS,CGO_CXXFLAGS,CGO_FFLAGS,CGO_LDFLAGSandGOGCCFLAGS
When you want to set global rather than package level CGO build options, you can do so with these newly added CGO-related environment variables, which avoids having to use the cgo indicator in each Go source file that uses CGO to set them separately.
The current default values for these go environment variables for CGO are as follows (using the default values on my macos as an example).
```txx
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
GOGCCFLAGS="-fPIC -arch x86_64 -m64 -pthread -fno-caret-diagnostics -Qunused-arguments -fmessage-length=0 -fdebug-prefix-map=/var/folders/cz/sbj5kg2d3m3c6j650z0qfm800000gn/T/go-build1672298076=/tmp/go-build -gno-record-gcc-switches -fno-common"
```
Other more specific changes will not be elaborated, you can move to “Go 1.19 New Features Preview” to see them.
Let’s focus on two important changes in Go 1.19: the new Go memory model document and the introduction of the Soft memory limit at Go runtime.
2. Revising the Go memory model documentation
I remember when I first learned Go, the most difficult of all the official Go documents was the Go memory model document (below), and I believe that many gophers must have had similar feelings to mine when they first read this document.
To view the old Go memory model documentation:
godoc -http=:6060 -goroot /Users/tonybai/.bin/go1.18.3, where godoc is no longer distributed with the go installation package, you need to install it separately with the command: go installgo install golang.org/x/tools/cmd/godoc.
So, what does the old memory model document say? Why was it revised? By clarifying these two questions, we will have a general idea of what the new memory model document means. Let’s start by looking at what is the memory model of a programming language.
1. What is the memory model?
When it comes to the memory model, we have to start with the famous computer scientist and 2013 Turing Award winner Leslie Lamport’s 1979 paper titled “How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs”.
In this article, Lamport gives a condition for concurrent programs to run correctly on a multiprocessor computer with shared memory, i.e., for the multiprocessor to satisfy sequentially consistent .
It is mentioned in the text that a processor running at high speed does not necessarily execute in the order (code order) specified by the program. A processor is said to be sequential if the result of its execution (which may be chaotic) is the same as the result of execution in the order (code order) specified by the program.
For a multiprocessor with shared memory, on the other hand, it can be considered to satisfy sequential consistency only if the following conditions are met, i.e., if it has the conditions to guarantee the correct operation of a concurrent program.
- The result of any one execution is the same as the result of all processor operations executed in some order;
- Each processor is also executed in the order specified by the program (code order) when each processor is viewed separately in “some order of execution”.
Sequential consistency is a typical shared-memory, multiprocessor memory model , a model that guarantees that all memory accesses are performed atomically and in programmatic order. The following is a schematic diagram of an abstract machine model for shared memory with sequential consistency, taken from A Tutorial Introduction to the ARM and POWER Relaxed Memory Models.
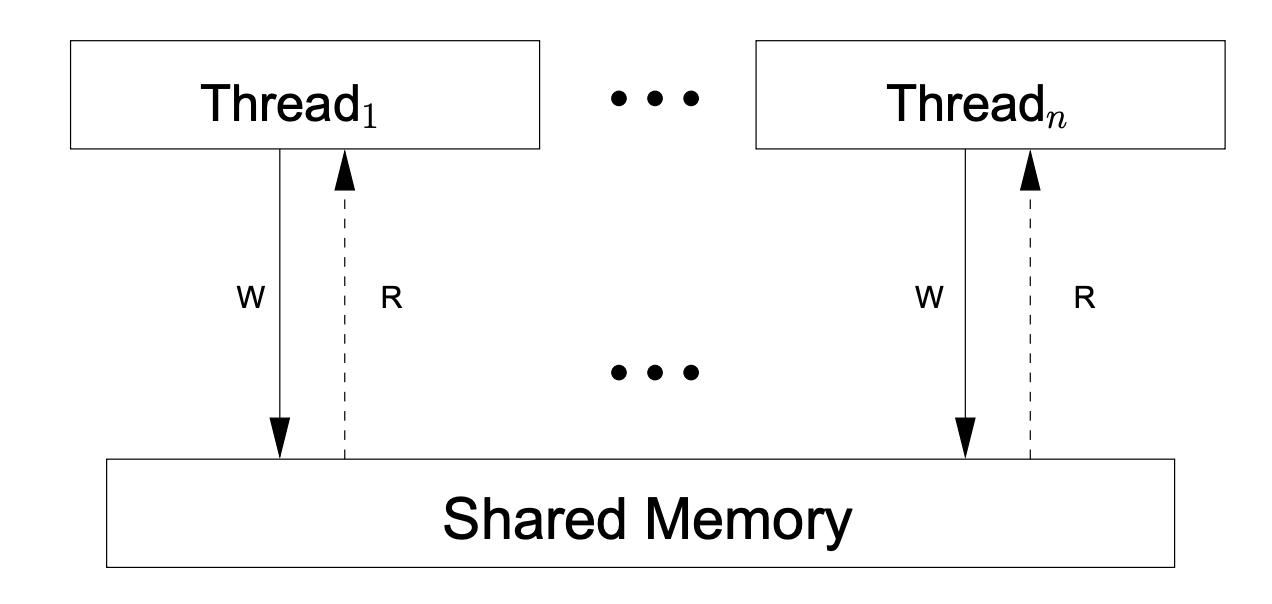
Based on sequential consistency, the abstract machine in the above diagram has the following characteristics.
- There is no local reordering: each hardware thread executes instructions in the order specified by the program, completing each instruction (including any reads or writes to shared memory) before starting the next one.
- Each write instruction is visible to all threads (including the thread doing the write) at the same time.
From a programmer’s point of view, a sequentially consistent memory model could not be more ideal. All read and write operations are directed to memory, there is no cache, and the value written to memory by one processor (or hardware thread) is observed by other processors (or hardware threads). With the sequential consistency (SC) provided by the hardware, we can achieve “what you write is what you get”.
But does such a machine really exist? Not really, at least not in mass-produced machines. Why? Because sequential consistency is not conducive to hardware and software performance optimization. A common machine model for real-world shared memory multiprocessor computers looks like this, also known as Total Store Ordering, the TSO model (diagram from A Tutorial Introduction to the ARM and POWER Relaxed Memory Models).
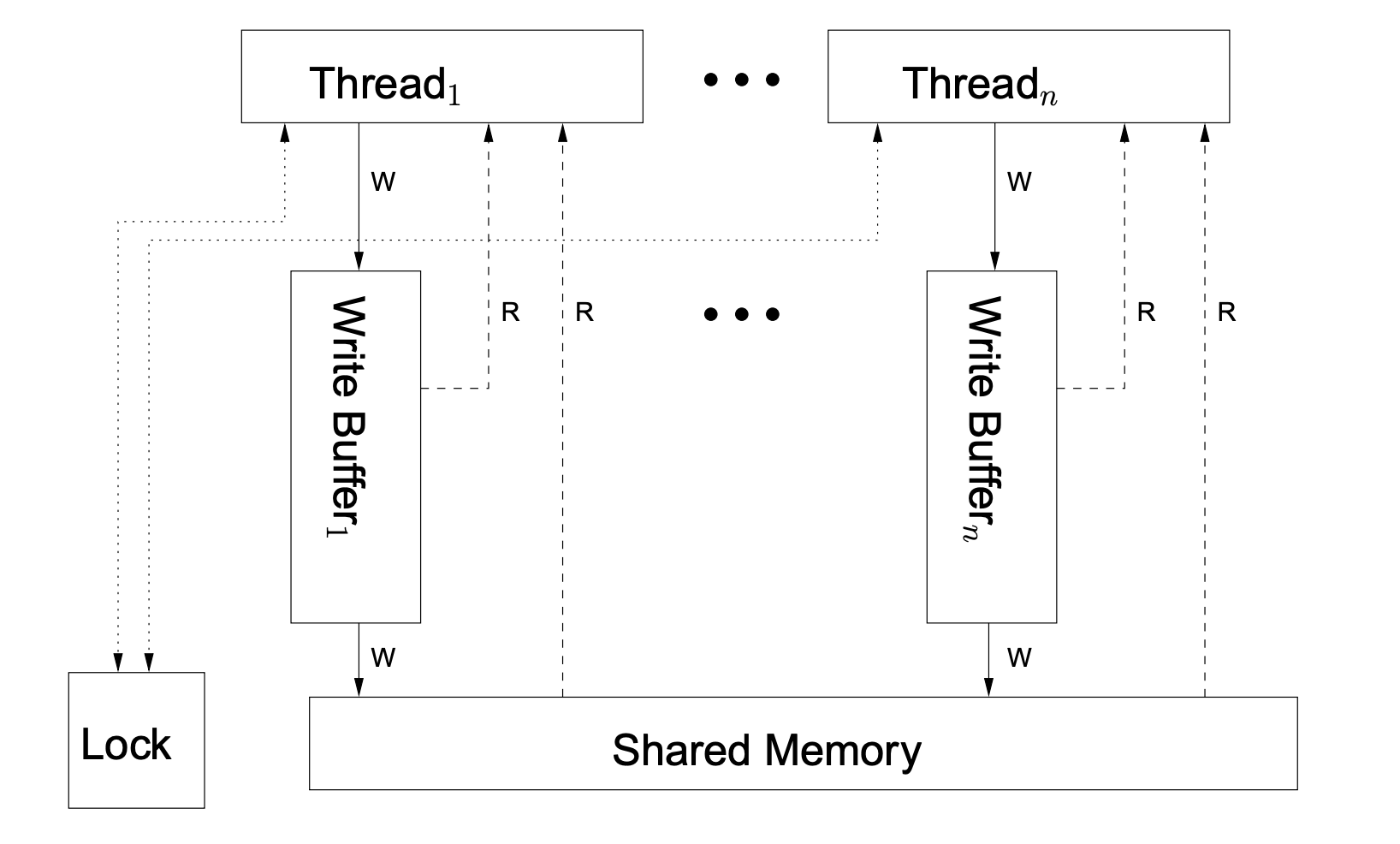
We see that in this machine, all processors are still connected to a single shared memory, but each processor’s write memory operation changes from writing to the shared memory to writing to the processor’s write buffer first, so that the processors do not have to wait for a write complete and the read memory operation on one processor also consults The processor’s write buffer queue is consulted first (but not the write buffer queues of other processors). The existence of a write cache queue greatly improves the speed of processor write memory operations.
However, due to the existence of the write cache, the TSO model cannot satisfy sequential consistency, e.g., the property that “each write instruction is visible to all threads (including the thread doing the writing) at the same time”, because the data written to the local write cache queue is only visible to itself and not to other processors (hardware threads) until it is actually written to shared memory.
According to Lamport’s theory, a programmer cannot develop a concurrent program (Data Race Free (DRF)) that runs correctly on a multiprocessor machine that does not satisfy SC, so what can be done? The processor provides synchronization instructions to the developer. For the developer, a non-SC machine with synchronization instructions has the properties of an SC machine. Only this is not automatic/transparent to the developer anymore, and requires the developer to be familiar with the synchronization instructions and use them correctly in appropriate situations, such as scenarios involving Data Race of data competition, which greatly increases the mental burden of the developer.
Developers usually do not face the hardware directly, which requires high-level programming languages to encapsulate the synchronization instructions provided by the hardware and provide them to developers, which is the synchronization primitives for programming languages . And which hardware synchronization instructions the programming language uses, what behavior of the synchronization primitives are encapsulated, how to apply them, examples of incorrect applications, etc. are all required to be explained to the users of the programming language. And these will be part of the programming language memory model documentation.
The memory model of today’s mainstream programming languages is the Sequential Consistency (SC) model , which provides developers with an ideal SC machine (although in practice the machine is not SC) on which programs are built. But as stated earlier, developers must also understand the synchronization primitives encapsulated by the programming language and their semantics in order to implement a correct concurrent program. As long as the programmer follows the synchronization requirements of the concurrent program and uses these synchronization primitives wisely, then the concurrent program can be written to run sequentially consistent on non-SC machines.
Once you know what the programming language memory model means, let’s take a look at what the old Go memory model document actually states.
2. Go Memory Model Documentation
As stated above, the Go memory model documentation should describe the conditions that must be met in order to write a correct concurrent program in Go.
To be more specific, as the old memory model documentation begins: The Go memory model specifies conditions that, once satisfied, when a variable is read in one goroutine, Go can guarantee that it can observe the new value resulting from a write to the same variable in a different goroutine.
Next, the memory model documentation gives the various synchronization operations provided by Go and their semantics based on the regular happens-before definition, including.
- If a package p imports a package q, then the completion of q’s init function occurs before the start of any of p’s functions.
- The start of function main.main occurs after the completion of all init functions.
- The go statement that starts a new goroutine occurs before the start of the goroutine’s execution.
- A send operation on a channel occurs before the corresponding receive operation on that channel completes.
- The closing of a channel occurs before a receive that returns a zero value (because the channel is already closed).
- A receive on an unbuffered channel occurs before the completion of a send operation on that channel.
- The kth receive operation on a channel with capacity C occurs before the completion of the kth+Cth send operation on that channel.
- For any sync.Mutex or sync.RWMutex variable l, when n<m, the nth l.Unlock call occurs before the mth call to l.Lock() returns.
- The f() call in once.Do(f) occurs before the return of any call to once.Do(f).
Next, the memory model document also defines some examples of misuse of the synchronization primitive.
So what exactly has been updated in the new memory model document? Let’s move on to the next section.
3. What has changed in the revised memory model documentation
Russ Cox, who is responsible for updating the memory model documentation, first added the Go memory model’s overall approach .
The general approach of Go is somewhere between C/C++ and Java/Js, neither defining a program with Data race as illegal like C/C++ and letting the compiler dispose of it with undefined behavior, i.e., exhibiting arbitrary possible behavior at runtime; nor is it exactly like Java/Js, which tries to specify various semantics in the case of Data race, so as to minimize the impact brought by Data race. The impact of data race is limited to a minimum, making the program more reliable.
Go outputs a race report and terminates the program for some cases of data race, such as concurrent reads and writes to a map by multiple goroutines without using synchronization. In addition, Go has explicit semantics for other data race scenarios, which makes the program more reliable and easier to debug.
Secondly, the new Go memory model documentation adds descriptions of the new APIs added to the sync package over the years, such as: mutex.TryLock, mutex.TryRLock and so on. Cond, Map, Pool, WaitGroup, etc. The documentation does not describe them one by one, but suggests looking at the API documentation.
In the old memory model documentation, there was no description of the sync/atom package. The new version of the documentation adds a description of the atom package and runtime.SetFinalizer.
Finally, the documentation adds a description of examples of incorrect compilation in addition to providing examples of incorrect synchronization.
By the way, Go 1.19 introduced some new atomic types in the atomic package, including: Bool, Int32, Int64, Uint32, Uint64, Uintptr and Pointer. these new types make it easier for developers to use the atomic package, for example, the following is a comparison between Go 1.18 and Go 1.19 code comparison using atomic variables of type Uint64.
Compare the two approaches to Uint64.
To fix a violation of this rule, use a consistent style (indentation or code fencing).
The specified style can be specific (fenced, indented) or simply require consistent usage across the document (consistent).
The rationale: consistent formatting makes the document easier to understand.
The new Pointer added to the atomic package avoids the hassle for developers to transform themselves using unsafe.Pointer when using atomic pointers. Pointer is a generic type, and if I remember correctly, it was the first time a generic-based standard library type was introduced into Go after Go 1.18 added comparable predefined generic types.
|
|
In addition, the new Int64 and Uint64 types of the atomic package have the added quality that Go guarantees that their addresses are automatically aligned to 8 bytes (i.e., the addresses are divisible by 64), even on 32-bit platforms, which is something that even native int64 and uint64 are not yet able to do.
go101 shared a tip based on atomic Int64 and Uint64 on Twitter. Using the new atomic.Int64/Uint64 in go 1.19, we can guarantee that a field in a structure must be 8 byte aligned in the following way, i.e. the address of the field can be divided by 64.
The previous code, why not use _atomic.Int64 it, why use an empty array it, it is because the empty array in go does not occupy space, you can try to output the above structure T size, see if it is 8.
3. Introduction of Soft memory limit
1. The only GC tuning option: GOGC
In the last few major releases, there have been no major changes/optimizations to Go GC. Compared to other programming languages with GC, Go GC is an oddity: for developers, before Go 1.19, Go GC had only one tuning parameter: GOGC (which can also be adjusted via runtime/debug.SetGCPercent).
The default value of GOGC is 100, and by adjusting its value, we can tune the timing of GC triggering. The formula to calculate the heap memory size for the next GC trigger is as follows.
Go 1.18 onwards incorporates GC roots (including goroutine stack size and size of pointer objects in global variables) into the calculation of target heap size
Take the version before Go 1.18 as an example, when GOGC=100(default value), if the live heap after a certain GC is 10M, then the target heap heap size opened by the next GC is 20M, that is, between two GCs, the application can allocate 10M new heap objects.
It can be said that GOGC controls the frequency of GC operation. When the GOGC value is set to a smaller value, the GC runs more frequently and the proportion of cpu involved in GC work is more; when the GOGC value is set to a larger value, the GC runs less frequently and the proportion of cpu involved in GC work is smaller accordingly, but it has to take the risk that the memory allocation is close to the resource limit.
Thus, the problem in front of the developer is that the value of GOGC is hard to choose, and this only tuning option becomes a poser.
At the same time, Go runtime does not care about the resource limit, it just keeps allocating memory according to the application’s needs and requests new memory resources from the OS when its own memory pool is insufficient, until it runs out of memory (or reaches the memory limit allocated to the application by the platform) and is oom killed!
Why is it that with GC, a Go application can still be oom killed by running out of system memory resources? Let’s move on to the next section.
2. Pacer’s problem
The above formula for calculating the target heap size for triggering GC is called the pacer algorithm inside Go runtime. pacer is translated into Chinese as “pacemaker” or “pacemaker”. Regardless of the translation, in short, it is used to control the rhythm of GC trigger.
However, the current algorithm of pacer can not guarantee that your application will not be OOM killed, for example (see the following figure).
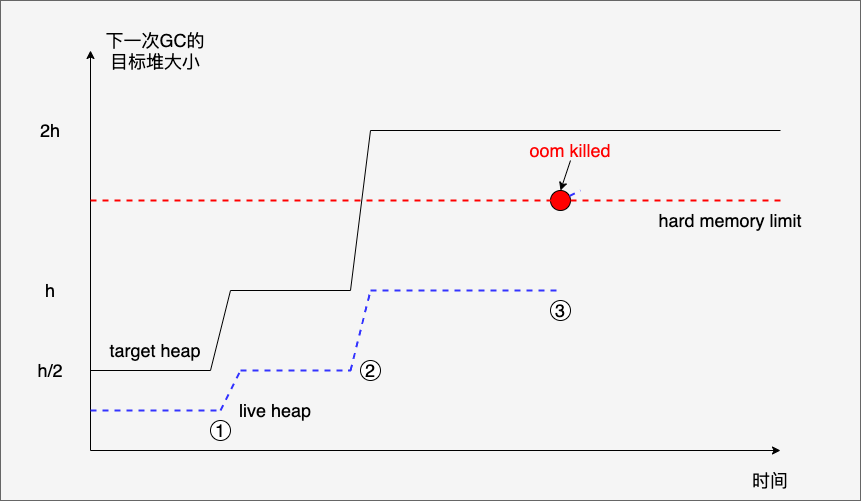
In this example.
- At first the live heap is always smooth, and the net increase in heap objects stays at 0, i.e. the newly allocated heap objects cancel each other out with the heap objects that are cleared out.
- A subsequent jump in target heap (from h/2->h) occurs at (1), apparently because the live heap object becomes too many and they are all in use, and cannot be cleared even if GC is triggered. However, at this point target heap(h) is less than the hard memory limit.
- The program continues to execute, and at (2), there is another jump in target heap (from h->2h), and the live heap object also becomes more and stabilizes at h. At this time, target heap becomes 2h, which is higher than the hard memory limit.
- The subsequent program continues to execute, and when the live heap object reaches (3), the actual Go’s heap memory (including the uncleared one) exceeds the hard memory limit, but since it has not yet reached the target heap (2h), the GC is not executed, so the application is oom killed.
We see that in this example, it is not that the Go application really needs that much memory (the live heap object is at the height of (3) if there is a GC to clean it up in time), but rather the Pacer algorithm causes the GC not to be triggered in time.
So how can we avoid oom killed as much as possible? Let’s look at the two “folk remedies” given by the Go community.
3. GC tuning solutions from the Go community
These two “prescriptions”, one is memory ballast from twitch games, and the other is the automatic GC dynamic tuning solution used by big players like uber. Of course these two schemes are not only to avoid oom, but also to optimize GC and improve the efficiency of program execution.
Let’s briefly introduce each of them. Let’s start with twitch’s memory ballast. twitch’s Go service runs on a VM with 64G of physical memory, and through observation the operations staff found that the service’s resident physical memory consumption was just over 400M, but Go GCs were started very frequently, which resulted in a long response time for the service. twitch’s engineers considered fully utilizing memory and reduce the frequency of GC starts, thus reducing the service’s response latency.
So they came up with a way to do this by declaring a large 10G slice in the initialization of the service’s main function like the following, and ensuring that the slice is not released by GC until the program exits.
This slice, being too large, will be allocated on the heap and tracked by runtime, but this slice does not bring a substantial physical memory consumption to the application, thanks to os’ delayed bookkeeping of the application process memory: only the memory read and written will cause a page out interrupt and have physical memory allocated for it by OS. From a tool like top, these 10 gigabytes will be recorded only on VIRT/VSZ (virtual memory) and not on RES/RSS (resident memory).
In this way, according to the principle of the previous Pacer algorithm, the next target heap size for triggering GC will be at least 20G. GC will not be triggered until the Go service allocates heap memory to 20G, and all cpu resources will be used to handle business, which is also consistent with twitch’s actual test results (99% drop in GC count).
Once it reaches 20G, since the previous observation is that the service only needs 400+M physical memory, a lot of heap objects will be recycled and the Go service’s live heap will go back to 400+M, but when the target heap memory is recalculated, the target heap memory will already be at least 20G due to the presence of the previous “ballast”. When the target heap memory is recalculated, the target heap memory will already be at least 20G, so there will be less GCs, less GCs, less time for the worker goroutine to participate in “labor”, higher cpu utilization, and lower latency of service response.
The “labor” refers to the worker goroutine being forced to “labor” by the runtime when mallocgc memory: stopping its task at hand to assist the GC in doing the mark of the heap live object.
However, the prerequisite for using this scheme is that you have an accurate knowledge of your Go service’s memory consumption (busy and idle times) so that you can set a reasonable ballast value in conjunction with your hardware resources.
According to Soft memory limit proposal, the drawbacks of this solution are as follows.
- Cannot be ported across platforms and is said to be inapplicable on Windows (the value of ballast would be directly reflected as the physical memory footprint of the application).
- No guarantee that it will continue to work properly as the Go runtime evolves (e.g., once the pacer algorithm has changed dramatically).
- Developers need to perform complex calculations and estimate runtime memory overhead to choose the right ballast size.
Next, let’s take a look at the automated GC dynamic tuning scheme.
Last December, uber shared on its official blog the semi-automated Go GC tuning scheme used internally by uber , according to uber, the implementation of this scheme helped uber save 70K cpu cores of computing power. The principle behind it is still based on Pacer’s algorithm formula, changing the original practice of keeping the GOGC value static throughout the life cycle of Go services, and dynamically calculating and setting the GOGC value based on the memory limit of the container and the current live heap size at each GC, so as to achieve the protection of memory shortage oom-killed, while maximizing the utilization of The GOGC value is dynamically calculated and set based on the memory limit of the container and the current live heap size.
Obviously this solution is more complex and requires a team of experts to ensure the setting of parameters and implementation of this auto-tuning solution.
4. Introducing Soft memory limit
In fact, there are many more Go GC pacer problems, and Go core team developer Michael Knyszek has submitted a pacer problem overview issue that summarizes these problems. But the problems need to be solved one by one, in this version of Go 1.19, Michael Knyszek has brought his solution Soft memory limit.
This solution adds a function called SetMemoryLimit and the GOMEMLIMIT environment variable to the runtime/debug package, either of which can set the Memory limit of a Go application.
Once the Memory limit is set, a GC round will be triggered when the Go heap size reaches the “Memory limit minus non-heap memory”. Even if you manually turn off GC (GOGC=off), GC will be triggered.
As we can see by the principle, this feature is the most direct solution to the oom-killed problem! Just like the example in the pacer problem diagram, if we set a soft memory limit that is smaller than the hard memory limit, then oom-killed will not occur at point (3) because the soft memory limit will trigger a GC before then, and some useless heap memory is reclaimed.
But we should also note that soft memory limit does not guarantee that oom-killed will not occur, which is also well understood. If the live heap object reaches the limit, it means that your application memory resources are really not enough, and it is time to expand the memory stick resources, which is a problem that GC can’t solve anyway.
However, if a Go application’s live heap object exceeds the soft memory limit but has not yet been killed, then the GC will be triggered continuously, but to ensure that business can still continue in this case, the soft memory limit scheme ensures that the GC will only use up to 50% of the CPU power to ensure that business processing still get cpu resources.
For the case that GC triggers frequently and the GC frequency should be reduced, the soft memory limit scheme is shutdown GC(GOGC=off), so that GC will be triggered only when the heap memory reaches the soft memory limit value, which can improve cpu utilization. There is one case though, which is not recommended in Go’s official GC guide, and that is when your Go program is sharing some limited memory with other programs. At that point it is sufficient to keep the memory limit and set it to a smaller reasonable value, as it may help to suppress undesirable transient behavior.
So what is a reasonable value for the soft memory limit? A good rule of thumb when it comes to Go services monopolizing container resources is to leave an extra 5-10% to account for memory sources unknown to the Go runtime. uber’s limit set in his blog at 70% of the resource limit is also a good rule of thumb.
4. Summary
Maybe Go 1.19 doesn’t bring you many surprises due to the compressed development cycle. But the features, though few, are very useful, such as the soft memory limit above, which once used well, can help solve big problems.
Go 1.20, which has a normal development cycle, is already under active development. From the features and improvements planned in the current milestone, the Go generic syntax will be further complemented and will move towards the full version, so it’s worth waiting for that!
5. Reference
https://research.swtch.com/mmhttps://github.com/golang/go/discussions/47141https://www.microsoft.com/en-us/research/publication/make-multiprocessor-computer-correctly-executes-multiprocess-programshttps://www.cl.cam.ac.uk/~pes20/ppc-supplemental/test7.pdfhttps://people.eecs.berkeley.edu/~kubitron/courses/cs258-S08/handouts/papers/adve-isca90.pdfhttps://www.hpl.hp.com/techreports/2008/HPL-2008-56.pdfhttps://docs.google.com/document/d/1wmjrocXIWTr1JxU-3EQBI6BK6KgtiFArkG47XK73xIQ/edithttps://tonybai.com/2022/08/22/some-changes-in-go-1-19/