Redis is an in-memory database that stores data in memory in exchange for faster read speeds. However, because memory is volatile, Redis stored data can be lost once a process quits or a hardware device fails. To solve the data persistence problem, Redis provides two solutions, RDB snapshot and AOF write operation logging, and this article analyzes the implementation of these two sub-cases.
The so-called persistence is to back up the server data at a certain point in time to a disk file, so that when the program exits or the server is down, the data can be recovered at the next restart using the previously persisted file. There are generally three common strategies to perform persistence operations to prevent data loss.
- Method 1: Setting up backup files or snapshots to recover through data backup or snapshots after equipment failure.
- Method 2: Use independent logs to record the operational behavior of the database in order to recover to a consistent state through logs after a failure, since logs are written in a sequential append fashion, so there is no log corruption.
- Method 3: The database is not modified with old data, and write operations are done in an appended manner, and the data itself is a log.
The first two strategies are RDB and AOF persistence in Redis, and the third scheme is not used for Redis. One is that Redis is often used in buffering scenarios with a lot of read and write operations, and modifying data in an appending manner will take up a lot of memory space. Second, the third option does not back up the data to disk, and once the device fails, it will still cause data loss.
Disk synchronization
Traditional UNIX or Linux systems have multiple buffers in the kernel, classified as cache or page cache, and most disk I/O is performed through the buffers. When data is written to a file, the kernel usually copies the data to a buffer first. If the buffer is not full, it is not queued to the output queue, but rather waits until the buffer is full or when the kernel runs out of free memory and needs to reuse the buffer to store other disk blocks. When this buffer reaches the head of the output queue, the actual I/O operation is performed. This type of output is called a delayed write.
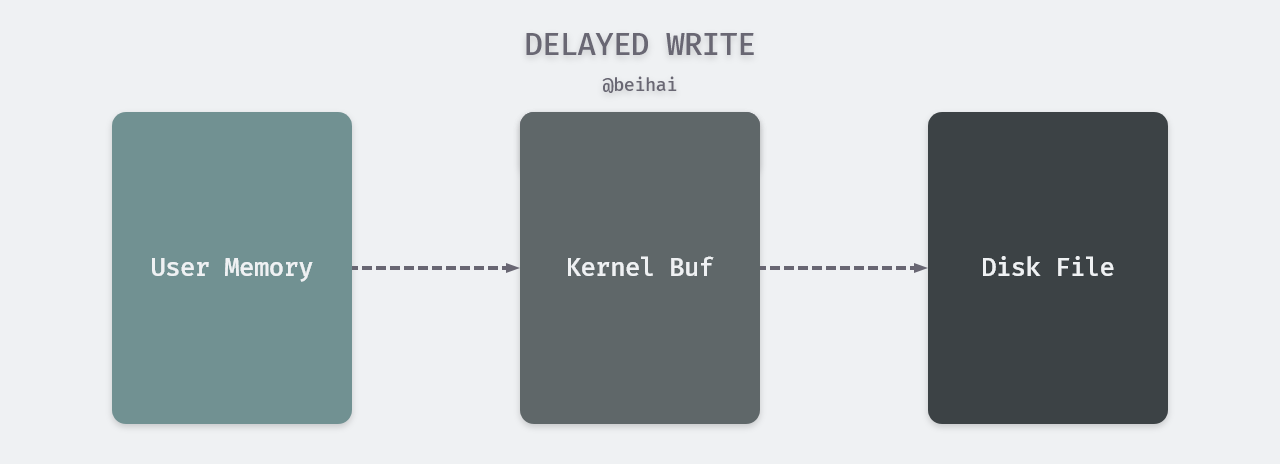
Delayed write
When we call the write() function to write data, the function writes the data to the kernel’s buffer (just to the buffer) and then returns immediately. Due to the design of the operating system, the data is written to the file for the caller and can be read by other processes, but it does not mean that they have been written to an external permanent storage medium, even after the close() function is called to close the file, because the data in the buffer may still be waiting to be output.
At the hardware level, data written with the write() function is not written to disk synchronously, the data is written by a dedicated flusher kernel thread when certain conditions are met (e.g., a certain time interval, a certain percentage of dirty pages in memory) . The time interval for this asynchronous operation depends on the operating system’s buffer refresh time, which is typically 30s in the Linux kernel, depending on the amount of data written and the state of the I/O buffers. This interval is indeed long for some scenarios, such as Redis persistence, where seconds of data loss may be unavoidable if the server fails while the data is in the kernel buffer.
The data in the kernel buffer is “written” to the disk file. The “write” here is not to move the data in the buffer to the disk file, but to copy it to the disk file, which means that the buffer contents are not cleared at this time. There is a reason for this design. Suppose the write is done to the disk file and the disk is bad or full, etc. If the buffer is cleared, the data will be lost. The kernel will wait until the write to disk operation is complete before deleting the data from the buffer.
Delayed writes reduce the number of disk writes, but reduce the speed of file content updates. To ensure consistency between the actual file system on disk and the contents of the buffer cache, the UNIX system provides three system calls, sync(), fsync() and fdatasync(), for refreshing the buffer in the kernel. fsync function.
The fsync() system call works only on a single file specified by the file descriptor fd, immediately adds that file’s block buffer to the output queue, and waits for the flusher kernel thread to finish writing that buffer to disk and then returns.
fsync() synchronizes not only the update of file data, but also the update of file attributes (atime, mtime, etc.), and is commonly used in database applications, which need to ensure that modified buffer blocks are written to disk immediately.
To put it simply, the write() system call is called to write data to the kernel buffer, and the *sync function queues the buffer to the output queue, where the daemon is responsible for writing the buffer in the queue to disk.
Persistence Process
A brief overview of the Redis persistence process is given in Redis persistence demystified by Reids author antirez.
- the client sends a write command to the database (the data is in the client’s memory)
- the database receives the write command (the data is in the server’s memory)
- the database calls the
write()system call to write the data to disk (the data is in the system kernel buffer) - the operating system transfers the data to the disk controller (data is on the disk cache)
- the disk controller writes the data to the physical media
As you can see from the previous summary, the write() system call can control step 3, the fsync system call can control step 4, but step 5 depends on the disk hardware and is out of our hands.

If the failure we are considering involves only the database software level and not the OS kernel (e.g., the database process is killed or crashed), the write operation can be considered safe after a successful return from step 3. After the write() system call returns, the data is transferred to the kernel, which writes the data to disk even if the database process crashes. If you consider a sudden power outage or a more catastrophic situation where all caches have been invalidated, the write operation can be considered safe only after step 5 is completed.
After understanding the deferred write and persistence process, let’s analyze how Redis persists.
RDB Snapshot
RDB (Redis DataBase) is a snapshot storage persistence method that saves the in-memory data of Redis at a certain point in time to a file on disk, with the default file name dump.rdb. When the Redis server starts, it will reload the data from the dump.rdb file into the memory to restore the data.
There are two ways to start RDB snapshot backup, one is the client sends execute RDB command to the server to start backup manually, the other is to set the conditions to trigger RDB snapshot, and the program automatically checks whether backup is needed.
No matter which backup method is used, the backup process of RDB is as follows.
- write the memory data to a temporary rdb file.
- replace the original official rdb file with the temporary one after the data is written.
- delete the original rdb file.
Data structure
Since the structure definition about RDB snapshot is rather complicated, involving RDB state, pipeline communication, sub-process information, etc., only the main variable definitions are listed below.
|
|
Manually triggered
There are two scenarios to trigger a manual backup, one is to execute a Redis program command (not to force kill the process), where the program will perform an RDB snapshot backup to load the data the next time Redis is started. The other is that the client sends SAVE or BGSAVE commands to the server, the difference between these two commands is that the SAVE command uses Redis’ main process to perform the backup, which causes the Redis server to block and all command requests sent by the client will be rejected until the RDB file is created. The BGSAVE command will fork a child process to perform I/O writes, while the main process can still process the command requests. Note that the child process snapshot backs up the data as it was when it was created; data added, modified, or deleted during the execution of the backup is not backed up.
Both commands eventually call the rdbSave() function to save the database to disk, and fsync is executed immediately after executing write to avoid data being left in the kernel buffer.
|
|
If the BGSAVE command is executed, Redis will store the child process IDs in redisServer.rdb_child_pid, which will be set to -1 when the BGSAVE command is executed, to determine if there are any child processes executing the task.
For performance and avoiding concurrency problems, Redis checks the current server state when executing RDB commands, and does not allow any more persistence operations during the BGSAVE command, and the AOF command is also delayed until the RDB snapshot is completed to avoid conflicts caused by multiple processes doing a lot of write operations. In addition, before BGSAVE (and AOF and MODULE related commands) is executed, the program will check if there are other sub-processes running, and if there are, it will terminate the execution and return an error.
Automatic triggering
In addition to letting clients send commands to trigger backups manually, Redis also provides automatic interval RDB backups, where we can set one or more trigger conditions with the save <seconds> <changes> command, indicating that if at least changes of data changes occur within seconds seconds, it will automatically trigger the bgsave command.
The trigger conditions are stored in redisServer.saveparams and are represented using the structure saveparam.
Redis also holds a redisServer.dirty counter that holds the number of times the database has been modified since the last successful RDB execution, and redisServer.lastsave that keeps track of the time since the last successful RDB execution. In the server-side cycle function serverCron() will periodically check if there is currently a child process performing persistence tasks, and if not, it will check if RDB or AOF persistence needs to be performed.
|
|
This section also posts the code to execute AOF, and the detailed process is described below.
AOF Logging
AOF is an Append Only File persistence scheme that records each modified database command as an append independent log. AOF files are saved in Redis RESP communication protocol format for AOF data recovery. For example, execute the following command.
The first 3 of these commands change the database, while the 4th command does not, because the key does not exist in the database. The AOF logs generated are as follows.
You can see that the last delete command is not logged to avoid unnecessary I/O write operations affecting performance.
Data structures
There are also many variables associated with AOF, and some of the main ones are selected here as well.
|
|
The AOF feature provides three aof_fsync policies to perform logging functions at different time frequencies, and Redis adds commands and parameters to the buffer redisServer.aof_buf before entering the event loop. Depending on the fsync policy, the size of the buffer may change.
- always: Redis calls the
write()system call in each event loop to write everything in the AOF buffer to the kernel cache and immediately calls thefsync()system call to synchronize the AOF file. always is the least efficient of the three policies, but it is also the safest, and in the event of a failover, the AOF persistence also only loses command data from the most recent event loop. - everysec: Redis calls the
write()system call in each event loop to write all the contents of the AOF buffer to the kernel cache, and thefsync()system call every second to synchronize the AOF file. This process is performed in a subthread, which is more efficient and only loses up to the last second of data. - no: Redis calls the
write()system call in each event loop to write all the contents of the AOF buffer to the kernel cache, while the synchronization of the AOF file is controlled by the operating system. The speed in this mode is comparable to the RDB method, but the synchronization interval is longer and more data may be lost in case of failure.
Of the three file synchronization policies provided by Redis, the more frequently the system call fsync() is used, the less efficient it is to read and write, but the more secure it is and the less data is lost in the event of downtime.
AOF file rewrites
Because AOF persistence records Redis state by storing the executed write commands, as Redis runs longer, the size of the AOF file grows, and if left unchecked, an oversized AOF file is likely to impact the server.
To address the problem of AOF file size bloat, Redis provides an AOF file rewrite feature that creates a new AOF file to replace the existing AOF file. Both the old and new AOF files hold the same Redis state, but are typically much smaller than the old AOF file because the new AOF file does not contain redundant commands, as in the following example.
- Expired data is no longer written to the AOF file.
- Invalid commands are no longer written to the AOF file.
- Multiple commands can be combined into a single one. For example:
sadd myset v1, sadd myset v2, sadd myset v3can be merged intosadd myset v1 v2 v3.
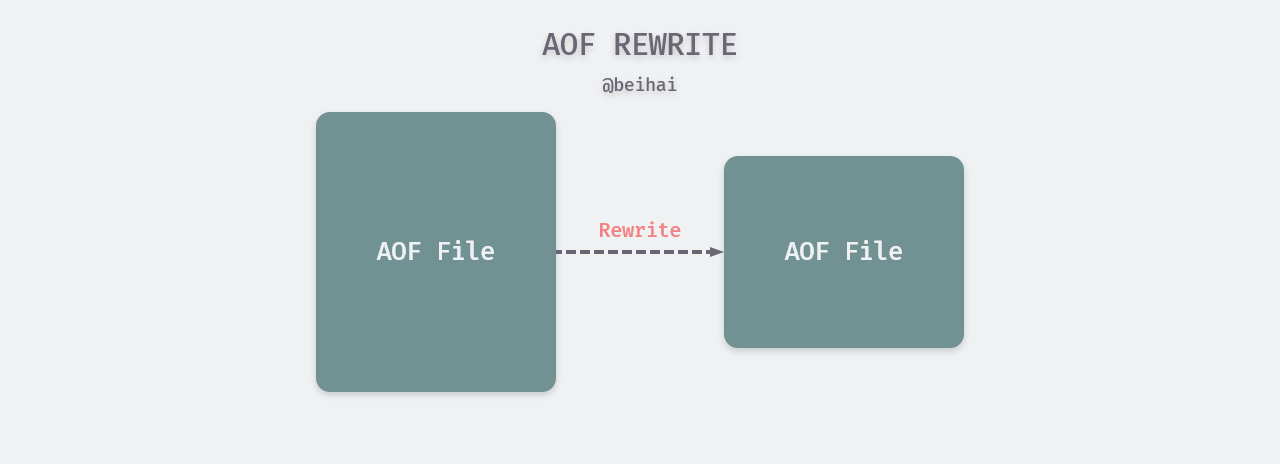
Enabling AOF rewriting can be triggered manually by executing BGREWRITEAOF, or you can set the following two configuration items to let the program determine the trigger timing automatically.
- auto-aof-rewrite-min-size: the minimum size of the file when performing AOF rewrites, the default value is 64MB.
- auto-aof-rewrite-percentage: the ratio of the current AOF size (aof_current_size) to the last rewritten AOF size (aof_base_size) when performing AOF rewrites.
When the user executes the BGREWRITEAOF command, Redis calls the rewriteAppendOnlyFileBackground() function, which forks a child process that rewrites the AOF file in a temporary file, at which point the main process appends the newly entered write command to the redisServer .aof_rewrite_buf buffer.
|
|
The Redis server-side cycle executor constantly checks to see if any child processes have finished executing their tasks (this code is posted in the RDB auto-trigger subsection). When a child process completes an AOF rewrite, the parent process calls the backgroundRewriteDoneHandler() function, which writes the accumulated rewrite cache to a temporary file, renames the new file, and sets the fd of the new file as the write target of the AOF program.
Summary
Finally, to summarize the advantages and disadvantages of RDB and AOF.
- RDB will call
fsync()to write data to disk cache immediately after callingwrite(), while AOF will write data to disk at different timing according toaof_fsyncpolicy. - RDB is a compact compressed binary file representing a backup of Redis data at a point in time, suitable for full replication scenarios, such as performing a
BGSAVEbackup every 6 hours and copying the RDB file to a remote machine or file system for disaster recovery. - Redis loads RDB to recover data much faster than the AOF approach.
- RDB way data can’t do real-time persistence, whether AOF way can do real-time persistence, you need to set
aof_fsyncpolicy to always.
Redis’ persistence scheme makes some trade-offs between performance and speed, using subprocesses to improve performance for non-real-time persistence. While there is some performance loss in performing true real-time persistence, the most common scenario for Redis is as a data cache, possibly as a fallback option.
Reference
https://wingsxdu.com/posts/database/redis/rdb-and-aof/http://antirez.com/post/redis-persistence-demystified.htmlhttp://byteliu.com/2019/03/09/Linux-IO%E5%90%8C%E6%AD%A5%E5%87%BD%E6%95%B0-sync%E3%80%81fsync%E3%80%81fdatasync/