Redis has long been known for its high performance, yet Redis runs as a single thread, which is often contrary to perception. So what mechanisms does Redis use to keep up with the huge volume of processing required? How to achieve high performance with “single threadedness” is the main question explored in this article.
The word “single-threaded” is in quotes in the title because Redis is single-threaded in the sense that it uses a single thread for the network request module, and Redis uses the concept of thread closure to avoid multi-threaded safety issues by enclosing tasks in a single thread, while other modules still use multiple threads. In addition, Redis uses an I/O reuse model to handle client-side network requests more efficiently.
Single-threaded advantages
Using multiple threads often results in greater throughput rates and shorter response times, however, using multiple threads is not necessarily faster than single-threaded programs. the CPU executes only one thread in a time slice, and when the kernel threads switch, it needs to save the execution context of thread A and then load the execution context of thread B. The registers involved include.
16 general purpose registers, PC (Program Counter), SP (Stack Pointer), segment registers, 16 XMM registers, FP coprocessor state, 16 AVX registers, all MSRs etc.
As you can see the overhead of threads performing context switches is not low and should be minimized if not necessary. And using multiple threads tends to make the design more complex, requiring us to be more careful when accessing shared data - putting locks on the data is not a cost-effective option for Redis.
On the other hand, the vast majority of Redis requests are purely in-memory operations, a process that is so fast that the CPU is not a performance bottleneck, and even with single-threaded instances a single instance can handle tens of thousands of data requests per second. For higher concurrency requirements, Redis also supports cluster deployments, where multiple instances are started on one or more servers to share access pressure.

Because Redis is not a CPU-intensive application, a single thread is sufficient to meet computing requirements, avoiding unnecessary context switching and data contention, and making operation more stable. Since the performance is sufficient, there is no need to over-engineer it to introduce multi-threading.
I/O Multiplexing
Unix-like systems contain five available I/O models: blocking I/O, non-blocking I/O, I/O multiplexing, signaling I/O, and asynchronous I/O. In the operating system, the kernel uses a File Descriptor (FD) to identify a file or other I/O resource, such as a network socket, that is being accessed by a particular process, and the different I/O models Different I/O models use FD to read and write to files.
In Redis, when a client initiates communication, the server’s acceptance of the data typically consists of two distinct phases.
- waiting for the data to arrive from the network, and when the waiting packet arrives, it is copied to some buffer in the kernel.
- copying the data from the kernel buffer to the application process buffer.
Of the above five I/O models, the first four are called synchronous I/O. The difference between them lies in the state of the process during the first phase while waiting for data to arrive, and in the second phase, the processes all block due to data copying. The following is a brief description of these four types.
Blocking I/O
Blocking I/O is the most popular I/O model. By default, reading and writing to the FD is blocked, and the application process may block when the process calls read or recvfrom to read or write to the FD. As shown in the figure below, the application switches from user state to kernel state, the kernel checks if the corresponding file descriptor is ready, and when the OS kernel copies the data to the application process, it switches from kernel state to user state and the application process continues execution.
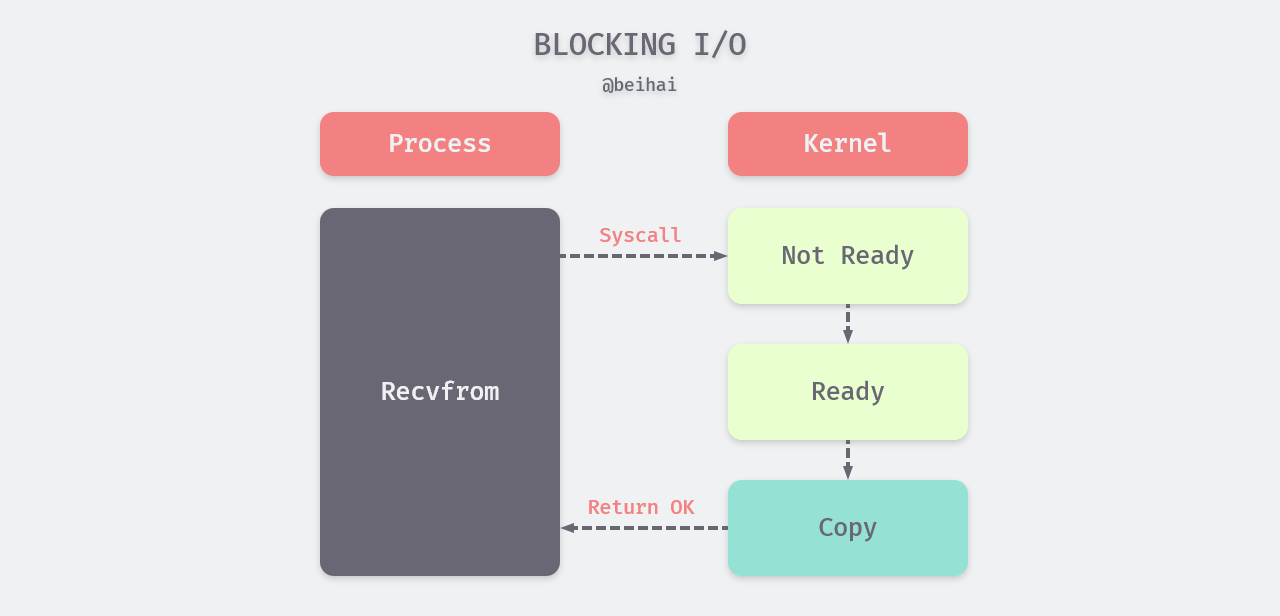
Since thread execution is linear, when we call recvfrom on blocking I/O, the process is stuck waiting until the I/O operation is finished, during which time no other operation can be performed.
Non-blocking I/O
When a process sets a process descriptor to non-blocking, the kernel will return immediately when performing I/O operations such as recvfrom. If the socket is not ready, the kernel returns an EWOULDBLOCK error. Since the process has not received the data, it initiates a polling operation and keeps calling I/O functions until the datagram is ready and copied to the process buffer and the kernel returns a success indication.
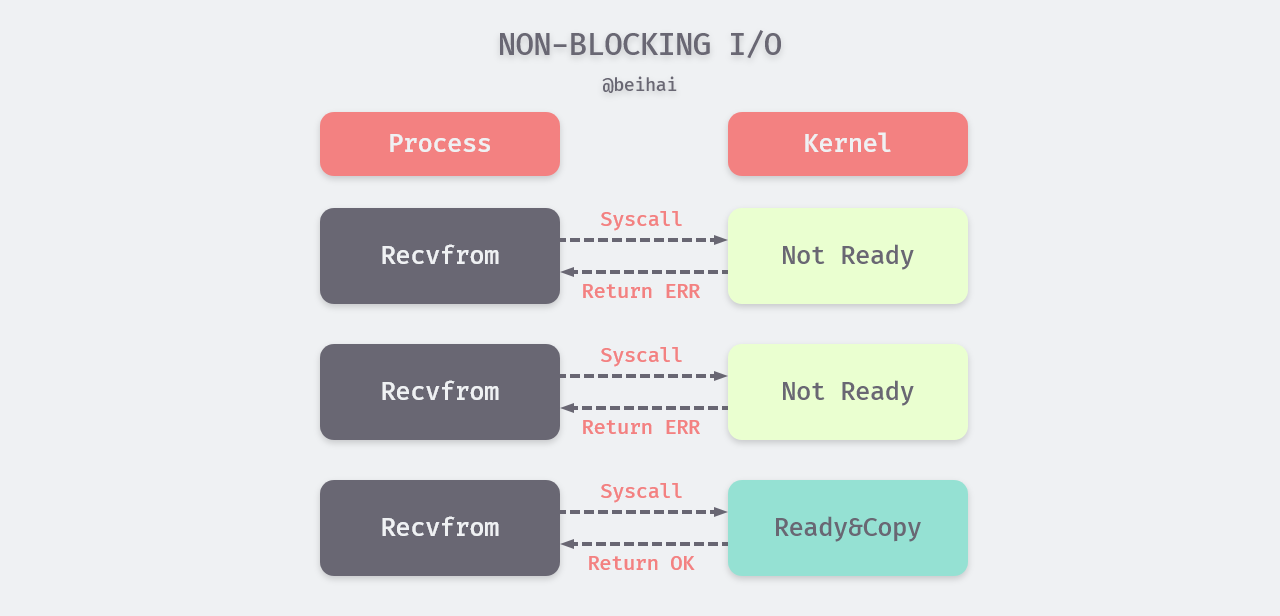
When a process uses non-blocking I/O, it can perform other tasks while waiting to improve CPU utilization. However, the application process continuously polls the kernel to see if an FD is ready, and this operation consumes some CPU resources.
I/O Multiplexing
I/O multiplexing is an I/O model used by Redis to handle multiple I/Os in the same event loop. I/O multiplexing requires the execution of specific system calls, the most common of which is select, which can listen to up to 1024 file descriptors at once. In Redis, in addition to implementing the cross-platform select function, more efficient multiplexing functions are prioritized as the underlying implementation based on the different system platforms, including evport in Solaries 10, epoll in Linux, and kqueue in macOS/FreeBSD, which can serve hundreds of thousands of file descriptors.
Take select for example, after calling the I/O multiplexing function, the process blocks on the function and listens to multiple file descriptors. When select returns FD readable, the process then calls recvfrom to copy the corresponding datagram to the application process buffer.
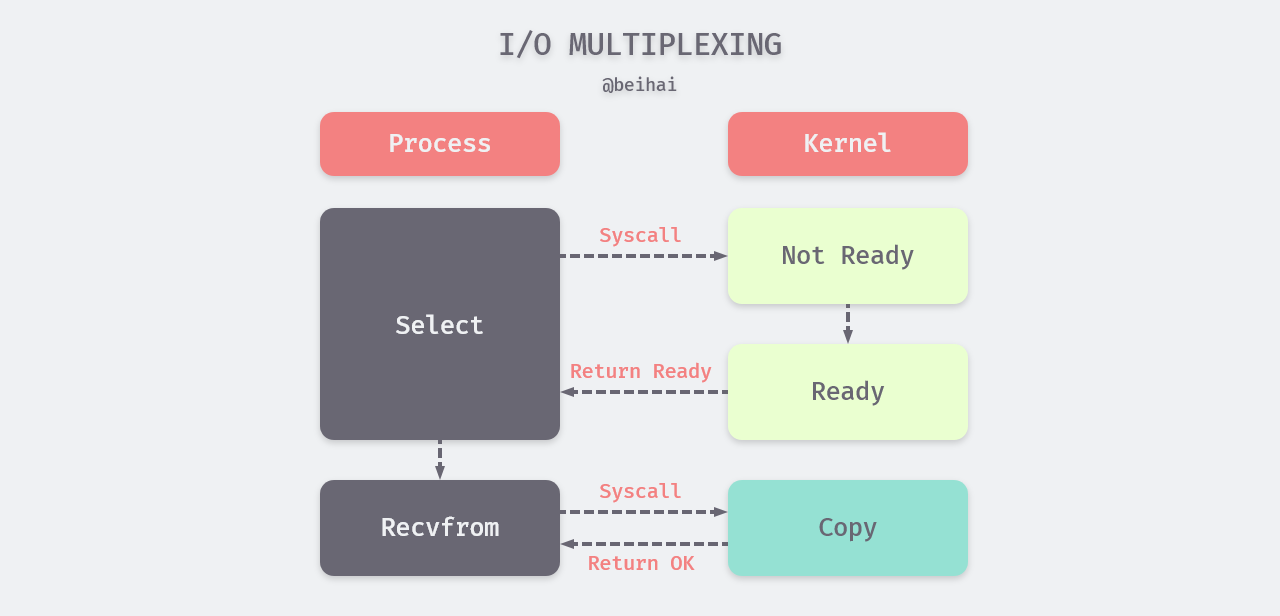
There is also a slight disadvantage to using I/O multiplexing when we are dealing with a single file descriptor, as two system calls are required while the other model requires only one. The performance advantage becomes more apparent as more I/O events need to be processed.
Signaling I/O
When a process uses a signal, the process notifies the kernel to perform a signal handling function via the sigaction system call, which returns immediately and the process can continue working on other tasks. When the datagram is ready, the kernel sends a SIGIO signal to the process, which then calls recvfrom to copy the datagram to the application process buffer.
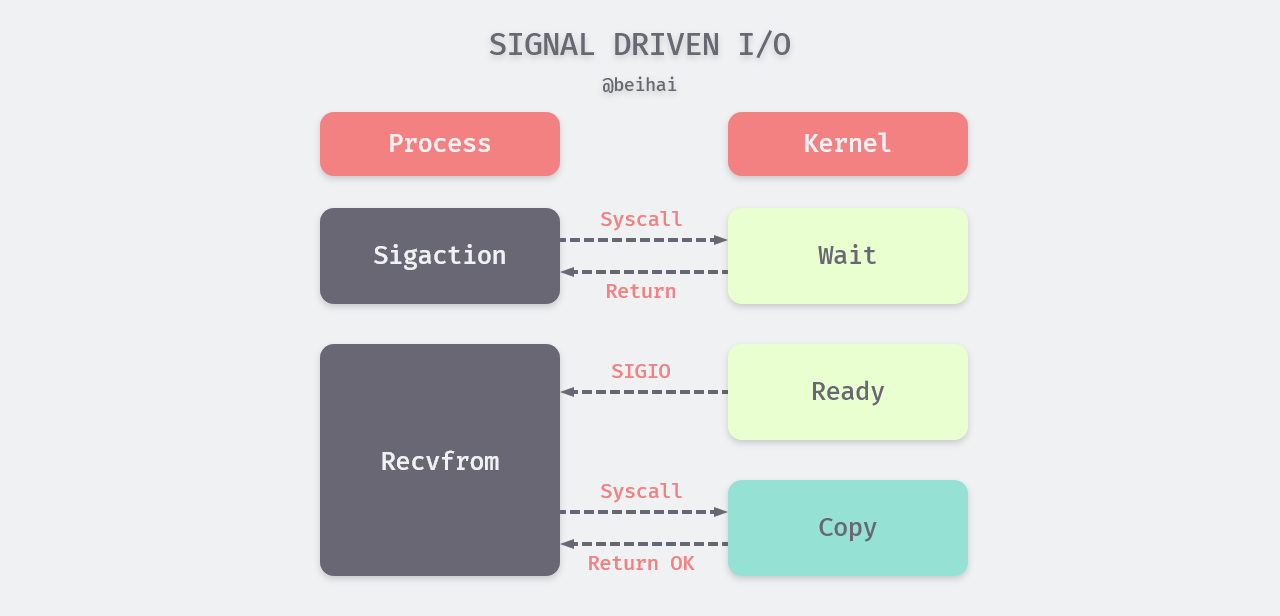
Similar to non-blocking I/O, signal I/O can perform other tasks while waiting, and without initiating a polling operation, the kernel notifies the process to process the data.
Summary
Redis typically processes tens of thousands of data requests per second, so choose efficient I/O multiplexing functions (such as epoll) to reduce unnecessary overhead and support the large number of network requests without blocking when processing multiple tasks.
Time-Consuming Task Processing
Redis is an event-driven application that abstracts client commands and timed tasks into events, which are executed by the corresponding event handlers. Normally, events are all processed sequentially within a single thread, with no other threads involved. However, as mentioned earlier, in some cases Redis may create new threads (processes).
- Redis will
forka child process to write in-memory data to disk when generating an RDB snapshot. - The
UNLINKcommand was introduced in Redis 4.0. When the key deleted with theUNLINKcommand is large, Redis removes the key from the key space and leaves the deletion of the value to a background thread to be handled asynchronously. - Redis 6.0 adds multi-threaded I/O, where the I/O thread is responsible for reading, writing, and parsing data, and the main thread is responsible for the specific execution of commands.
Redis has been optimizing its multitasking capabilities to take advantage of multi-core processors. As you can see from the examples above, Redis is optimized for multi-threaded operations such as data backups, deletion of large key-value pairs (e.g., hash tables of more than a dozen MB), and I/O event processing to reduce the computational pressure on the main thread. These operations, which are relegated to the main thread, have little to no impact on the execution of client commands and do not create a data contention situation.
Summary
Redis takes advantage of many features provided by the operating system, making its design and implementation uncomplicated, powerful, and easy to develop. The authors of the project have a deep understanding of the operating system and are skilled at engineering solutions to problems.
- Delegating time-consuming tasks to background threads.
- CPU is not a performance bottleneck for the main thread, even with single threads.
- Use I/O multiplexing to handle I/O-intensive tasks.
These strategies provide good ideas for programming, and their flexible use can be useful in performance optimization.
Reference
[linux五种IO模型](https://juejin.im/post/5c725dbe51882575e37ef9ed`[正式支持多线程!Redis 6.0 与老版性能对比评测](https://www.chainnews.com/articles/610212461536.htm`https://wingsxdu.com/posts/database/redis/high-performance/