Introduction to Nginx
Nginx is an open source software originally designed as a high-performance web server. Today, Nginx can perform a number of other tasks, including caching servers, reverse proxy servers, load balancers, and more.
WEB SERVER
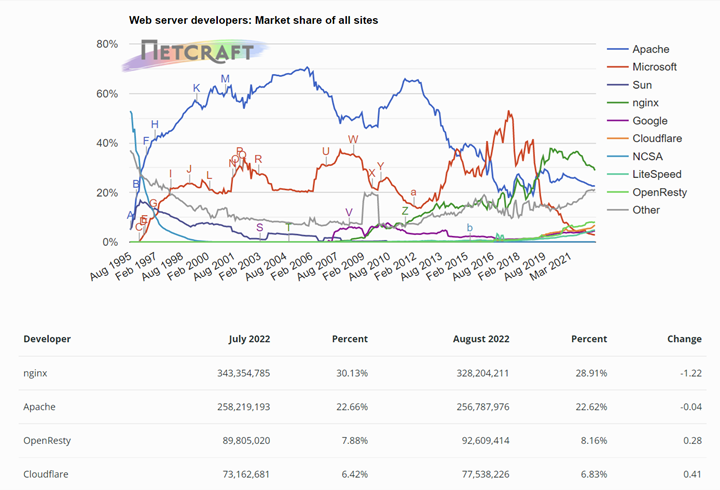
At present, the mainstream use of web server software, mainly apache, nginx, tomcat, iis, etc., on a global scale, Apache is the most popular existing web server, but the most popular web server in the high-traffic website is indeed nginx, in our country, whether large or small Internet companies, the mainstream choice is also nginx as web server software. A survey from Netcraft found that the usage rate of Apache was 31.54% and the usage rate of Nginx was 26.20%.
HTTP proxy server
HTTP proxy, there are two types: one of forward proxy and one of reverse proxy.
Forward Proxy
The most important feature of Forward Proxy is that the client is very clear about the address of the server to be accessed, and it proxies the client and makes the request for the client.

Suppose the client wants to access Google and it knows that the address of the server to be accessed is https://www.google.com/, but due to constraints, it finds a “friend” who can access Google: a proxy server. The client sends the request to the proxy server, which requests Google on its behalf, and eventually returns the response to the client. This is a forward proxy process, in which the server does not know who is actually sending the request.
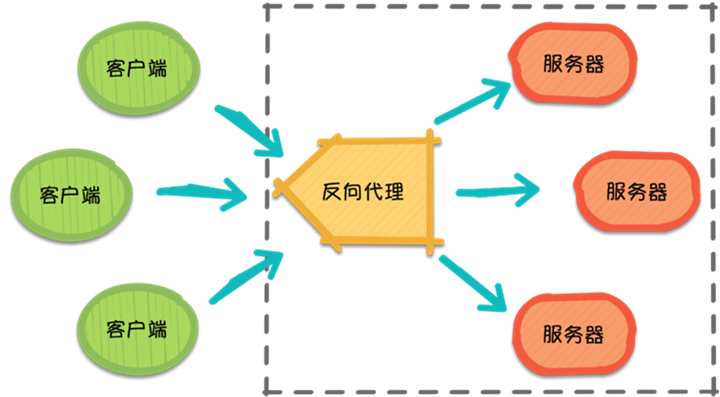
Reverse Proxy
Then, with the explosive growth of requests, the server feels that it is always unable to cope with it alone and needs help from its brother servers, so it calls for its brothers as well as its proxy server friends. At this point, all requests from different clients are actually sent to the proxy server, which then distributes the requests to each server according to certain rules.
This is the reverse proxy (Reverse Proxy), the reverse proxy hides the information of the server, it proxies the server side, receiving requests on its behalf. In other words, during the reverse proxy process, the client does not know which server is handling its request. In this way, the access speed is improved and security is provided.
In this, the reverse proxy needs to consider the problem of how to carry out a balanced division of labor, control the traffic and avoid the problem of excessive local node load. In layman’s terms, it is how to reasonably allocate requests for each server, so that it has a higher efficiency and resource utilization as a whole.
Based on nginx reverse proxy, it is possible to achieve distributed (different sub-domains access different service back-end nodes) and load balancing (the same domain name accesses multiple identical back-end nodes).
Difference between reverse proxy and forward proxy.
- Forward proxy: For the client, the proxy server acts as a proxy for the client, forwards the request, and returns the obtained content to the client.
- Reverse proxy: For the client, the proxy server is like the original server, which proxies the web node servers of the cluster to return the results.
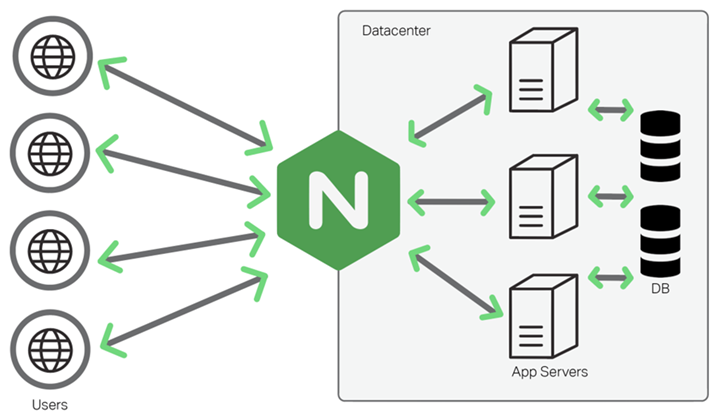
Load balancer
Load balancing is also a common feature of Nginx, based on the nginx reverse proxy. Load balancing means spreading the execution across multiple operating units, such as web servers, FTP servers, enterprise critical application servers, and other mission-critical servers, so that they can work together to complete work tasks. Simply put, when there are 2 or more servers, requests are randomly distributed to the designated servers for processing based on rules. Nginx currently supports three load balancing policies (polling, weighted polling, IP hashing) and two common third-party policies (fair, url hashing).
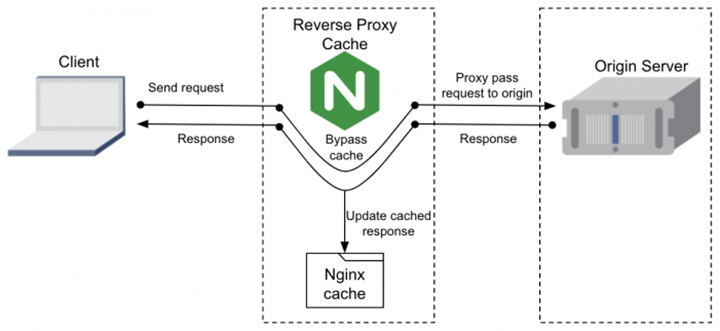
Caching server
nginx can cache static resource files such as images, css, and js. nginx is used as a caching server together with nginx as a reverse proxy server. When a client first requests a static resource from a back-end resource server via nginx, the response is given to the corresponding client while caching a copy of itself, and subsequent requests for the same resource do not need to be requested from the back-end server again unless the cache is cleared or the cache expires.
Introduction to Nginx Load Balancing
Load balancing provides an inexpensive, efficient, and transparent way to extend the bandwidth of network devices and servers on top of the existing network structure, and can increase throughput, enhance network data processing, and improve network flexibility and availability to some extent. In the words of the official website, it acts as a “traffic commander” in the network flow, “standing in front” of the servers and handling all requests between servers and clients, thus maximizing response rates and capacity utilization, while ensuring that no server is No server is overloaded. If a single server fails, the load balancing approach redirects traffic to the remaining clustered servers to ensure service stability. When new servers are added to the server group, they can also be load balanced to start automatically processing requests from clients.
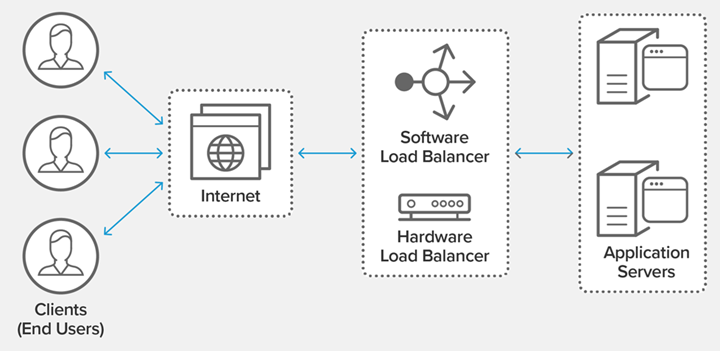
In short, load balancing is actually a strategy to distribute a large number of requests.
Load balancing is to spread the load to be executed on multiple operating units, thus improving the availability and responsiveness of the service and bringing a better experience to the users. For web applications, through load balancing, the work of one server can be extended to be executed in multiple servers, increasing the load capacity of the whole website. The essence of this is load balancing, which uses a scheduler to ensure that all back-end servers bring their performance to full play, thus maintaining the best overall performance of the server cluster.
Load balancing is one of the more common features of Nginx, optimizing resource utilization, maximizing throughput, reducing latency, ensuring fault-tolerant configurations, and distributing traffic to multiple back-end servers.
Nginx on AKF scalable cubes.
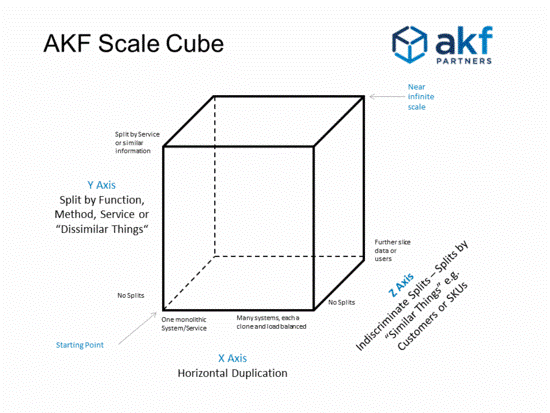
- On the x-axis, you can horizontally scale a cluster of application servers, and Nginx distributes requests based on the Round-Robin or Least-Connected algorithms. However, horizontal scaling does not solve all the problems. When the data volume is large, the amount of data on a single server remains large no matter how many services are scaled.
- On the y-axis, you can distribute different functions based on URLs. This requires URL-based configuration of Nginx locations, which is costly.
- On the z-axis, you can scale based on user information. For example, you can map user IP addresses or other information to a specific service or cluster.
This is the load balancing feature of Nginx, and its main purpose is to enhance the processing power and disaster recovery capabilities of the service.
- When the bandwidth and performance of a server is affected by a surge in visits per unit of time, and the impact is too great for the server to handle, the server will go down and crash.
- When one server goes down, the load balancer allocates other servers to users, which greatly increases the stability of the site. When users access the Web, they first access the load balancer, which then forwards requests to the backend server.
Nginx is used as a load balancer for several reasons.
- Highly concurrent connections
- Low memory consumption
- Very simple configuration files
- Low cost
- Support for Rewrite rewrite rules
- Built-in health checks
- Bandwidth saving
- High stability
Nginx works at Layer 7 of the network, and can do triage policies for HTTP applications themselves. It supports load balancing for seven layers of HTTP and HTTPS protocols. Support for Layer 4 protocols requires a third-party plug-in. -yaoweibin’s ngx_tcp_proxy_module implements TCP upstream.
The main reasons why Nginx is called dynamic load balancing are.
- Self-monitoring. Built-in health checks for back-end servers. If a server on the Nginx Proxy backend goes down, it resubmits the requests that return errors to another node, without affecting front-end access. It does not have a separate health check module, but uses business requests as health checks, which eliminates the need for separate health check threads, which is a benefit. The bad thing is that when the business is complex, there may be misjudgment, for example, the back-end response timeout, which may be the back-end is down, or it may be a problem with a business request itself, which has nothing to do with the back-end.
- **Scalability.**Nginx is a typical microkernel design with a very simple and elegant kernel that is also very scalable.
- Nginx is a pure C implementation, and its extensibility lies in its modular design. Currently, Nginx has many third-party modules that extend its functionality. nginx_lua_module embeds the Lua language into the Nginx configuration, thus using Lua to greatly enhance Nginx’s own programming capabilities, even without the need for other scripting languages (such as PHP or Python), just by relying on Nginx itself. can be used to handle complex operations.
- **Configuration changes.**Nginx supports hot deployment, so it can run almost 24/7, even for months, without restarting. Nginx has a very simple configuration file that is as easy to understand as the program, and supports perl syntax. The configuration file can be loaded at runtime using nginx -s reload, which facilitates runtime expansion/decapacity. When reloading the configuration, the master process sends a command to the currently running worker process. The worker process receives the command and exits after processing the current task. At the same time, the master process will start a new worker process to take over the work.
Nginx Load Balancing Strategies
Nginx is an excellent reverse proxy server, and has different load balancing algorithms to solve server resource allocation problems when there are too many requests.
- Built-in policies include polling, weighted polling, and ip hash. By default, these two policies are compiled into the Nginx kernel and only need to be specified in the Nginx configuration.
- Extended policies, such as fair, generic hash, and consistent hash, are not compiled into the Nginx kernel by default.
| Strategy | Role |
|---|---|
| polling | assign to different back-end servers one by one in chronological order, if the back-end service hangs, it can automatically reject |
| weighted polling | weight assignment, specify the polling probability, the larger the weight value, the higher the probability of access assigned, used in the case of uneven performance of the back-end server |
| ip_hash | Each request is assigned according to the hash result of the visited IP, so that each visitor has a fixed access to one backend server, which can solve the dynamic web session sharing problem. Load balancing redirects each request to one of the server clusters, so users who have already logged in to one server will lose their login information if they redirect to another server, which is obviously not a good idea. |
| least_conn | Minimum number of links, that machine with fewer connections will be assigned |
| url_hash | The request is distributed according to the hash result of the accessed url, and each url is directed to the same backend server |
| hash key value | hash Customized key |
| fair (third party) | Assignment is based on the response time of the backend server, with priority given to those with shorter response times, relying on the third-party plugin nginx-upstream-fair, which needs to be installed first |
Here are a few examples of commonly used scheduling algorithm strategies.
Polling Policy
Polling policy (default), requests are assigned to web tier services one by one in chronological order, and then the requests are automatically rejected if the web tier service hangs.
Polling is a more basic and simple algorithm in load balancing, it does not require additional parameters to be configured. Assuming that there are M servers in the configuration file, the algorithm iterates through the list of server nodes and selects one server per round to process requests in node order. After all nodes have been called once, the algorithm starts a new round of traversal from the first node.
Features: Since each request in this algorithm is assigned to a different server one by one in time order, it is suitable for the case of clusters with similar server performance, where each server carries the same load. However, for clusters with different server performance, this algorithm is prone to problems such as unreasonable resource allocation.
Weighted polling
To avoid the drawbacks of normal polling, weighted polling was created. In weighted polling, each server has its own weight, and in general, a higher weight means that the server has better performance and can carry more requests. In this algorithm, client requests are assigned in proportion to the weight, and when a request arrives, the server with the highest weight is assigned first.
Features: Weighted polling can be applied to clusters with unequal server performance, allowing for more rational resource allocation.
The Nginx weighted polling source code can be found at: ngx_http_upstream_round_robin.c. The core idea is to iterate through the server nodes and calculate the node weights as the sum of current_weight and its corresponding effective_weight, and select the node with the highest weight as the best server node in each round. The effective_weight changes with the resource and response situation during the execution of the algorithm.
backup is marked as a backup server. When the primary server is not available, the backup server is used.
IP hash
Client IP binding: ip_hash maintains a session and guarantees that the same client always accesses a server.
ip_hash assigns servers based on the hash value of the client IP that sent the request. This algorithm ensures that requests sent from the same IP are mapped to the same server, or different IPs with the same hash value are mapped to the same server.
Features: This algorithm solves the problem of Session non-sharing in a cluster deployment environment to a certain extent.
The Session non-sharing problem means that if a user has already logged in and the request is assigned to server A, but server A suddenly goes down, the user’s request will be forwarded to server B. However, because of the Session non-sharing problem, server B cannot share the request with server A. However, because the session is not shared, B cannot read the user’s login information directly to perform other operations.
In practice, we can use ip_hash to forward some of the requests under IP to the server running the new version of the service, and some to the old version of the server to achieve grayscale publishing. Furthermore, if we encounter a request timeout due to a large file size, we can also use ip_hash to slice and upload the file, which ensures that the file slices sent by the same client are forwarded to the same server, facilitating its receipt of the slices and subsequent file merging operations.
Minimum connection policy
least_conn prioritizes the server with the least number of connections to avoid overloading the server with requests.
Assuming there are M servers, when a new request is made, the list of server nodes is traversed and the server with the lowest number of connections is selected to respond to the current request. The number of connections can be interpreted as the number of requests currently being processed.
Fastest response time policy
fair relies on Nginx Plus, with a limited allocation to the server with the shortest response time.
When we need to proxy a cluster, we can do so in the following way.
|
|
Standard configuration.
|
|
The status of the server in load balancing scheduling.
- down: the current Server is temporarily not participating in load balancing
- backup: the reserved backup server
- max_fails: the number of failed requests allowed
- fail_timeout: how long the service will be suspended after max_fails
- max_conns: limit the maximum number of incoming connections