What is eBPF
eBPF, known as Extended Berkeley Packet Filter, is derived from BPF (Berkeley Packet Filter), which is a functional module for network message filtering. However, eBPF has evolved into a general-purpose execution engine, essentially a virtual machine-like function module in the kernel. eBPF allows developers to write custom code that runs in the kernel and is dynamically loaded into the kernel, attached to a kernel event that handles the execution of the eBPF program, without the need to recompile a new kernel module, and can dynamically load and unload eBPF programs as needed. eBPF programs can be dynamically loaded and unloaded as needed. This allows developers to develop a variety of networking, observability, and security tools based on eBPF, which is why eBPF is so popular in the cloud-native world.
Note: The original BPF was widely used in unix-like kernels, and the redesigned eBPF was first integrated into the linux kernel in 3.18. Since then the BPF has been called the classic BPF, or cBPF (classic BPF). Today’s linux kernels do not run cBPF, the kernel transparently converts the loaded cBPF bytecode into eBPF before executing it.
How eBPF works
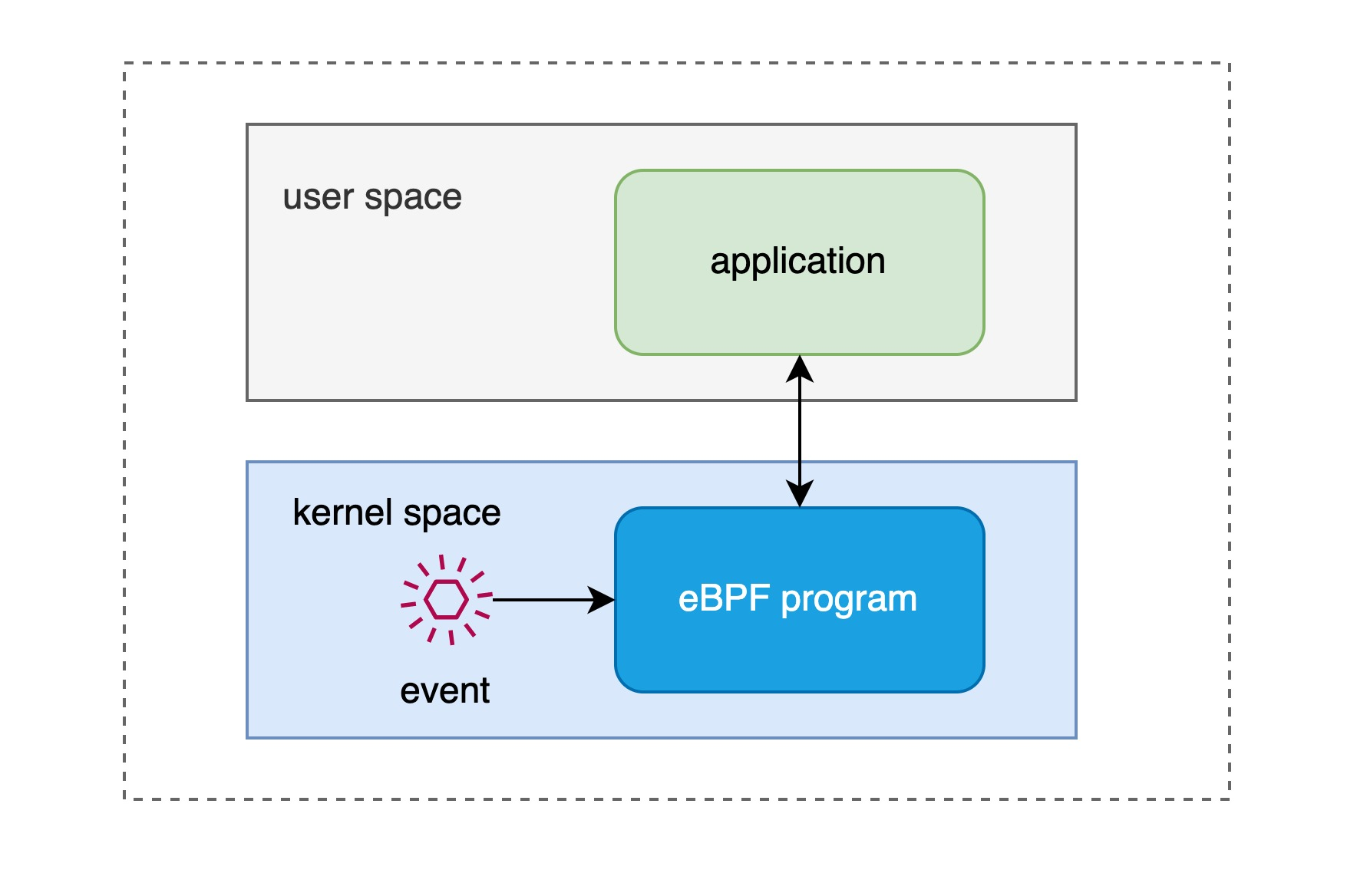
In general, the eBPF program consists of two parts.
- the eBPF program itself
- the application that uses eBPF
Let’s start with an application that uses eBPF, which runs in user space and loads an eBPF program via a system call to attach it to some kernel event that emits this eBPF. Today’s versions of the kernel already support loading eBPF programs to many types of kernel events, most typically to events where the kernel receives a network packet, which is what BPF was originally designed for, filtering of network messages. In addition, eBPF programs can be attached to function entries (kprobe), trace points, etc. eBPF applications sometimes need to read statistics, event reports, etc. from eBPF programs.
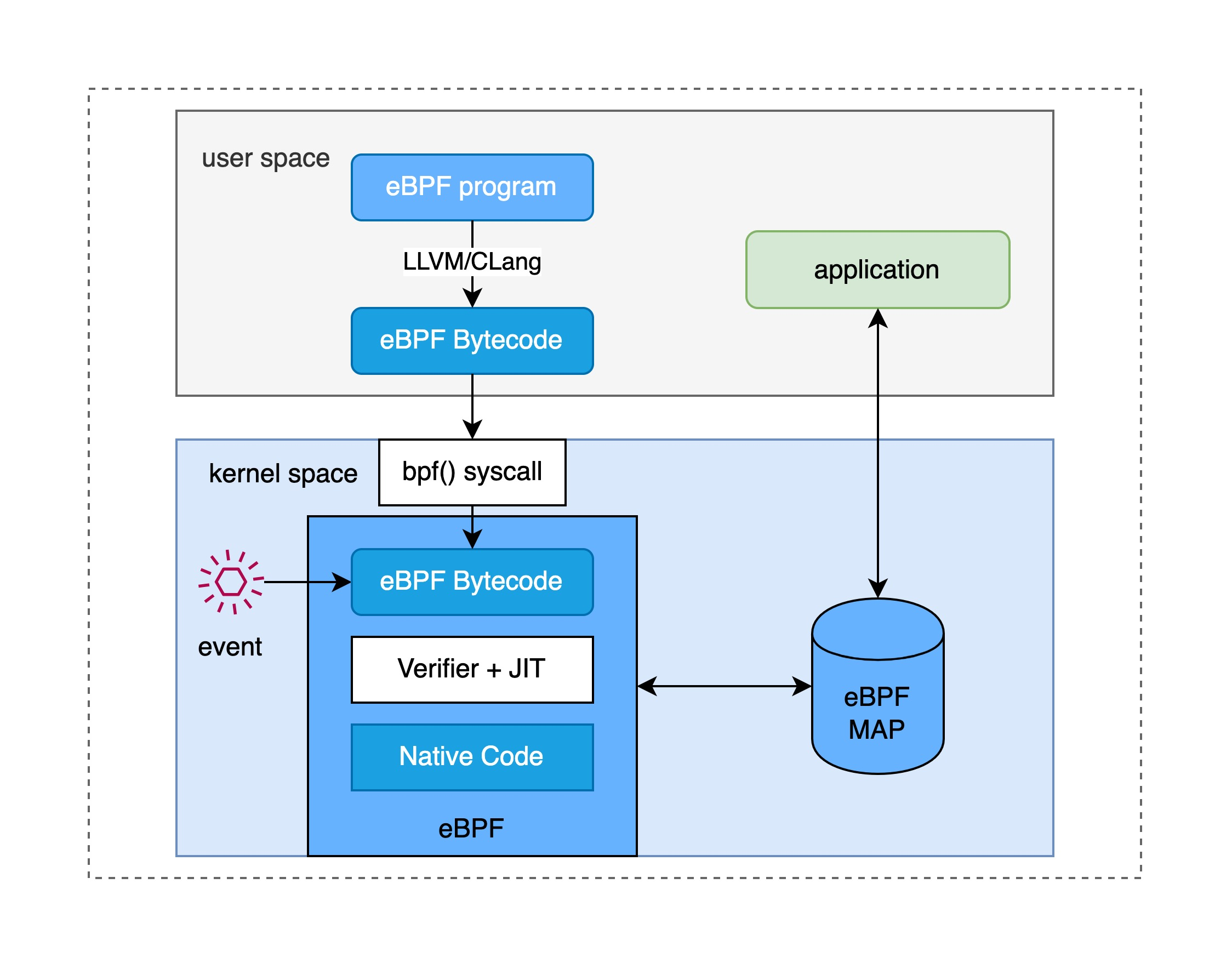
The eBPF program itself uses “kernel code” written in C. Before injecting it into the kernel, it needs to be compiled with the LLVM compiler to get the BPF bytecode, and then the loader loads the bytecode into the kernel. Of course, in order to prevent the injected eBPF programs from crashing the kernel, there are special validators in the kernel to ensure the security of the eBPF programs, e.g. eBPF cannot call the kernel parameters at will, but is restricted to BPF helpers helpers.7.html) function; in addition to that, eBPF programs cannot contain logic that cannot be reached, loops must be completed in a limited time and a limited number of times, etc.
eBPF programs and applications can communicate in both directions through an eBPF MAP located in the kernel, which is resident in memory and can transmit summary statistics from the kernel back to the application in user space. In addition, the eBPF MAP can be used for communication between eBPF programs and kernel-state programs as well as between eBPF programs.
eBPF Example
As is traditional, we need to write an eBPF version of Hello World and get it up and running. Our eBPF program is written in C, and the eBPF application chooses to use Golang + libbpfgo, although you can of course choose to use C as well.
The runtime environment information for the examples in this article is as follows.
- Ubuntu 20.04 LTS
- Kernel Version 5.15.0
- Golang 18.7
Installation dependencies.
Note: where
llvmandclangare the compilers we use, andlibbpf-devandlibelf-devcontain the libraries we depend on to write our eBPF programs.
Let’s look at the eBPF program itself. The code information is very simple, the entry point of the program is specified by the compiler macro kprobe/sys_execve, the parameters of the entry function have different parameters for different eBPF program types, in this case *ctx. The core header file <linux/bpf.h> is from the kernel header file, which is installed by default in /usr/include/linux/bpf.h, while <bpf/bpf_helpers.h> contains the eBPF helpers function from libbpf, which needs to be installed separately. We’ve already installed all of them in the dependency preparation. The core function of this code calls bpf_trace_printk from the helpers function of eBPF. The final code declares the SEC macro to define the license, since the eBPF program loaded into the kernel needs to have a license check.
|
|
Let’s take a look at the application that loads eBPF. We wrote it in Golang and used libbpfgo to load the eBPF program into the kernel, and since this is very simple, it does not involve using eBPF MAP to communicate with the eBPF program. The loading program runs in the user state and eventually requires a system call to bpf() to load the eBPF bytecode. Here we use libbpfgo to simplify the process by calling NewModuleFromFile directly to create a bpfModule and then get the eBPF program hello from it and attach it to the kernel kprobe.
Note that a bpfModule can contain multiple eBPF programs.
|
|
Next, let’s see how to compile and run the eBPF program. In this simple example we first build the object file and then build the user-space application that will load the eBPF bytecode into the kernel and run the application in user space.
|
|
With the makefile, we know that we have to execute make all to build the executable application we need and the eBPF bytecode as the target file. Then run the application (as privileged or with CAP_BPF) and you should see code output similar to the following.
|
|
If at this point we run bash in another terminal with process ID 36395, then the output above shows the process calls of bash-36395, which shows that this simple eBPF version of Hello World can see the execution of all these different process calls, which is the power of eBPF, the eBPF program in the kernel knows all the process activity information on this machine and passes it back to the application in user space.
eBPF and Kubernetes
eBPF makes the kernel programmable, making it a big deal in the cloud-native space, especially in the Kubernetes universe. Imagine a container or pod in Kubernetes running on top of the physical or virtual machine where the node is located, running primarily in user space and sharing the same kernel. We can now inject the developer’s eBPF program into the node’s kernel, which means that we can use eBPF to know information about all the applications in the container or pod, including but not limited to the network traffic sent/received by the application, read/write files, assign IPs to newly created pods, and so on. In fact, there are many mature monitoring, network management and security detection components based on eBPF, the most famous being Cilium.
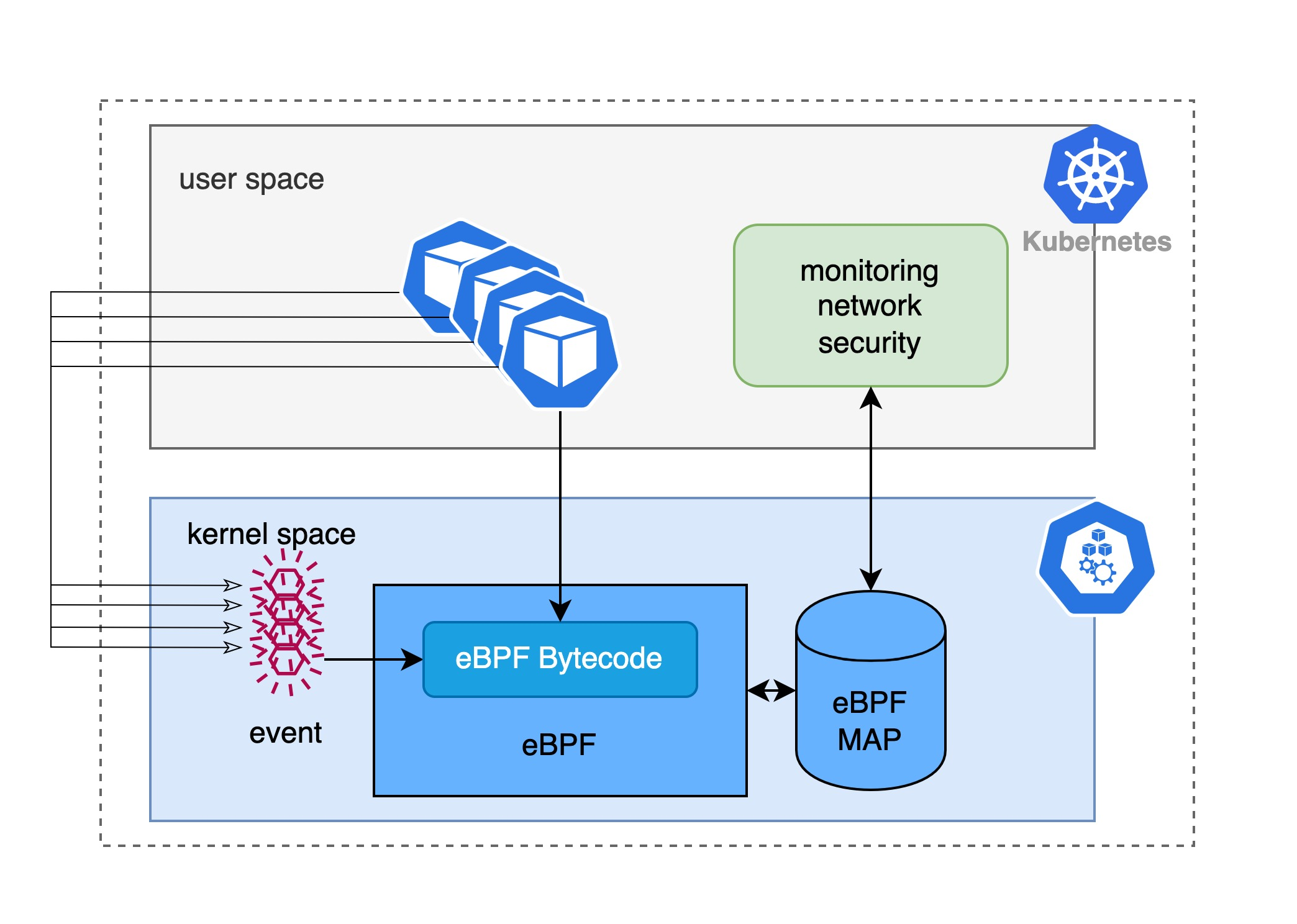
In addition, in the kubernetes universe, many architectures use the Sidecar pattern to achieve observability, traffic management, and security policy enforcement through, for example, sidecars, most notably Istio which uses istio sidecars to manage network traffic to pods to build service grid. This model takes advantage of the fact that pod contenters share the same network namespace and mount volumes, so that information about the activity of the target pod is obtained by injecting (either manually or automatically via an admission webhook) a sidecar. The problem with the sidecar model is that once a sidecar has been injected, it introduces additional performance overhead, and once the Once the sidecar is configured correctly, it may not work properly or even affect the operation of the application itself, so it is difficult to achieve complete transparency for the sidecar model. The benefit of eBPF, on the other hand, is that the application can be deployed without making any changes to know everything that is happening in all the containers or pods, which is one of the reasons why eBPF, a kernel programmable technology, is exciting to use for observability, network management, and security policy enforcement tools.
Summary
eBPF is a new technology that improves observability, networking, and security in the kernel. It allows the kernel to implement more complex functionality without changes, making it simpler and more flexible for developers to create richer tools to support the operation of the underlying system infrastructure. We already have a good idea of what eBPF is, how it works, and why it has so much potential in the Kubernetes universe. Of course eBPF is perfect, writing eBPF code is not an easy task, and the eBPF program has many limitations, it is not a Turing-complete, and hopefully as the kernel version changes, the eBPF ecosystem becomes more mature. Finally, we have to mention another popular virtual machine technology in the cloud-native domain - WebAssembly, which runs in user space but can handle many kernel-like tasks, so much so that CNCF has developed a cloud-native WebAssembly runtime based on LLVM WasmEdge Runtime so that the native application merges all sandbox checks into the native library, which allows WebAssembly programs to behave like a standalone unikernel library operating system.