The author has recently attempted to write some Rust code, and this article focuses on a view of Rust and some of the differences between Rust and C++.
Background
S2 studied the CPP core guidelines when advancing the team’s code specification, which led to learning about clang-tidy, and Google Chrome’s exploration of security.
C++ is a very powerful language, but with great power comes great responsibility, and it has been criticised for its memory safety issues; the NSA has even made it clear that C++ is a memory insecure language to stop using.
C++ itself has proposed a number of improvements, but implementation is long overdue, and Bjarne’s solution to the NSA challenge is only partially solved and appears to be out of reach.
Rust, an up-and-coming language invented by Mozilla in response to memory security issues (it also used C++ before), is starting to be embraced by both Linux and Chrome, and Tikv, along with most blockchain projects, chose it on day one.
After encountering several memory trap problems, I got the urge to learn about Rust.
Risks in C++ code
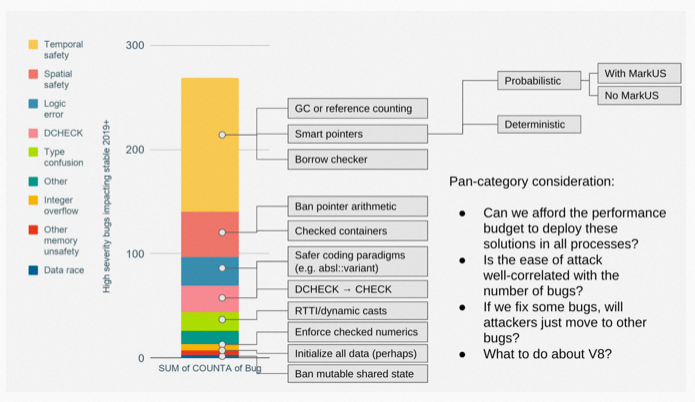
This chart shows the distribution of bug types in Chrome’s code that have been attacked, as published by the Chrome team, and you can see that memory safety accounts for more than half of them.
- Temporal safety: Simply put, use after free
- Spatial safety: Simply put, out of bound access
- Logic error
- DCHECK: simply means that the debug assert condition was triggered in the release version
Not much else to expand on.
First experiences with Rust
The first experience with Rust is actually more about feeling that it has some very sweet little designs that will make our programming comfortable.
Simply put, the C++ writing style required in “Best Practice/Effective C++ etc” is all compiler enforced in Rust.
Immutable by default
In Rust, all variables are immutable by default, and mutability requires additional typing, which is the exact opposite of C++. However, this is consistent with the recommendations in the C++ Core Guidelines.
Disable integer implicit conversion
This is a general rule in the software world, but it is counter-intuitive that it does not apply at all in C/C++.
Simplifying constructs, copying and destructions
The Rule of 3 or 5 or 6 in C++ is a big deal and we have had to write the following code countless times
It’s obviously a very routine thing, but so complicated to write.
Rust is so simple that objects only support Destructive move by default (done via memcpy). To copy, the class has to explicitly implement the Clone trait and write .clone() when copying, and for trivial objects, which are expected to be copied implicitly via =, it has to explicitly implement Copy, and when implementing Copy, the class is not allowed to implement Drop (i.e. the destructor) again.
|
|
Rust’s approach is far superior to C++’s move and its introduction of the use after move problem and all the Best Practices.
I don’t have to worry about accidentally copying a vector with 10 million elements anymore, and I don’t have to wonder whether to use value or const& when reviewing it.
Explicit Parameter Passing
The Best Practice of function argument passing in C++ can be written a bunch of times, and there is no clear specification of how in/out/inout arguments should be handled. rust simplifies argument passing and turns everything from implicit to explicit.
Unified error handling
Error handling has always been a very divisive area in C++, and as of C++23, the following functions for error handling are currently available in the C++ standard library:
- errno
- std::exception
- std::error_code/std::error_condition
- std::expected
See, even the standard library itself does this. std::filesystem, all interfaces have at least two overloads, one that throws an exception and always passes std::error_code.
Rust’s solution is similar to the static exception proposed by Herb, and makes error handling very easy with syntactic sugar.
|
|
Error handling is always done via Result<T, ErrorType>, by ? , propagating errors upwards with one click (e.g. also supporting automatic conversion from ErrorType1 to ErrorType2, provided you have implemented the relevant trait) and automatically unpacking when there are no errors. The compiler will report an error when it forgets to handle processing the Result.
Built in formatting and lint
Rust’s build tool, cargo, has built-in cargo fmt and cargo clippy, one-click formatting and lint, no more manual configuration of clang-format and clang-tidy.
Standardised development process and package management
Rust is the envy of C++ programmers because it has an official package management tool, cargo. conan, the unofficial C++ package management tool, currently has 1,472 packages, and cargo’s package management platform has 106,672 packages.
cargo also has native support for test and benchmark, which can be run quickly.
cargo specifies the style of the catalogue.
Rust’s improvements in security
What was mentioned in the previous section is actually still non-fatal; it’s Rust’s improvements in memory security that make it stand out.
lifetime security
use-after-free is one of the most famous bugs in the world. The solution to it has always relied on runtime checks, the two main schools of thought being GC and reference counting. Rust introduces a new mechanism in addition to this: Borrow Check.
Rust specifies that all objects are owned, and that assignment implies a transfer of ownership. Rust allows the ownership of an object to be temporarily rented to other references. Ownership can be leased to a number of immutable references, or to an exclusive mutable reference.
As an example:
|
|
This unique ownership + borrow check mechanism effectively avoids the pointer/iterator invalidation bug and the performance problems caused by aliasing.
On top of this, Rust introduces the concept of lifetime, i.e. each variable has a lifetime, and when multiple variables are referenced, the compiler checks the lifetime relationship between them, forbidding a non-owning reference to be accessed after the lifetime of the original object.
This is a relatively simple example, so let’s look at some more complex ones.
|
|
Look at another, more complex one, involving multiple threads.
This is a very typical lifetime error, C++ may not find the problem until runtime, but with Rust the compilation of similar code will fail. Because latch is a stack variable, its lifetime is very short, and when passing a reference across threads, the reference can actually be called at any time, and its lifetime is the whole process lifetime, for which Rust has a special name, ‘static’. as the cpp core guidelines say: CP.24: Think of a thread as a global container, never save a pointer in a global container.
In Rust, the rust compiler forces you to use reference counting to show that shared requirements are stated (anyone who finds a problem with this statement is already a Rust master).
To look at a more concrete example, suppose you are writing a file reader that returns one line at a time. To reduce overhead, we expect the returned line to refer directly to the buffer maintained internally by the parser, thus avoiding copying.
Then look at Rust.
In summary, Rust defines a set of rules to code by and there is absolutely no problem with lifetimes. When the Rust compiler cannot deduce the correctness of a write, it forces you to use reference counting to solve the problem.
Boundary security
Buffer overflow and out of bound access are also a very important class of problems, which are relatively easy to solve by adding a bound check to the standard library implementation; Rust’s standard library does a bound check.
This can be avoided with a little effort in C++.
What? Poor performance of bound check. Then look at the vulnerability reports released by Chrome. Don’t be too confident, after all, Bjarne is starting to compromise, and Herb’s slide has some numbers on the out of bound issue.
Type safety
Rust forces variable initialization by default and disables implicit type conversion.
Multithreaded Security in Rust
If the lifetime + ownership model is the core of Rust’s security, Rust’s multi-threaded security is the fruit of that; Rust’s multi-threaded security is implemented entirely through the library mechanism.
Firstly, two basic concepts are introduced:
- Send: A type is Send, indicating that, ownership of objects of this type, can be passed across threads. When all members of a new type are Send, the type is also Send. Almost all built-in types and standard library types are Send, except for Rc (similar to local shared_ptr), which is internally counted with a normal int.
- Sync: A type being Sync indicates that the type allows multiple threads to share (in Rust, sharing must imply immutable references, i.e. concurrent access via its immutable references).
Send/Sync are two Traits of the standard library, which define them in such a way as to provide a counterpart implementation for existing types or to disable the counterpart implementation.
With Send/Sync and the Ownership model, Rust makes Data races completely impossible.
In brief:
- the lifetime mechanism requires: an object to be passed across threads must be wrapped using Arc (Arc for atomic reference counted) (Rc does not work because it is specifically marked as !Send, i.e. it cannot be passed across threads)
- The ownership+borrow mechanism requires that objects wrapped in Rc/Arc are only allowed to be dereferenced to immutable references, and multi-threaded access to an immutable object is inherently guaranteed to be safe.
- Internal mutability is used to solve the shared writing problem: by default, shared must mean immutable in Rust, and only exclusive, is mutable allowed. If both sharing and mutability are required, an additional mechanism needs to be used, which Rust officially calls internal mutability, but in fact it is probably easier to understand by calling it shared mutability, which is a mechanism for providing safe changes to shared objects. If multiple threads are required to change the same shared object, internal/shared mutability must be obtained using additional synchronization primitives (RefCell/Mutex/RwLock) that ensure that there is only one writer. meaning that if it is used with Arc, Arc is not Send, and thus
Arc<RefCell<T>>cannot be cross-threaded.
Look at an example: suppose I have implemented a Counter object that I want multiple threads to use at the same time. To solve the ownership problem, you need to use Arc<Counter>, to pass this shared object. However, the following code does not compile.
This rule in Arc prevents data races from occurring, because Arc shares an object, and in order to guarantee the borrow mechanism, access to internal Arc objects is restricted to immutable references (the borrow mechanism specifies either one mutable reference or several immutable references).
To solve this problem, Rust introduces the concept of internal mutability. Simply put, a wrapper can get a mutable reference to an internal object, but the wrapper does a borrow check to ensure that there is only one mutable reference, or several immutable references.
Under single thread, this wrapper is a RefCell, under multi-thread, it is a Mutex/RwLock etc. Of course, if you try to write code like this, it will also fail to compile.
Why? Because RefCell is not Sync, i.e. it does not allow multi-threaded access. Arc is Send only if its internal type is Sync. i.e. Arc<Cell<T>> is not Send and cannot be passed across threads.
Mutex is Send, so it can be written as such.
Performance of Rust
As a challenger to C++, more people will be interested in how well Rust performs; the official philosophy of Rust is the zero cost principle, which is similar to C++’s zero overhead principle, isn’t it? Of course, the name is actually not as good as C++, after all, there is a cost to doing things, so how can it be zero cost?
Rust adds a bound check, which may be a little weaker than C++, but it is limited. Rust also supports unsafe mode, which skips the bound check altogether, making Rust’s upper bound equal to C++’s.
Also, Rust disables a lot of conditionally correct usage, and there is some performance loss, such as having to share_ptr across threads (extra dynamic allocation).
Here, latch must use Arc (i.e. shared_ptr).
In some scenarios, Rust will be faster than C++. The optimization bible has it that there are two natural enemies that prevent compiler optimization.
- function calls
- pointer aliases
C++ and Rust can both eliminate the overhead of function calls with inline, but C++ is largely helpless when it comes to pointer aliasing, and C++ relies on the strict aliasing rule for pointer aliasing, but this rule is notoriously nasty and Linus has complained about it a few times. -fno-strict-aliasing is used to disable this rule in Linux code.
However, C at least has __restricted__ to save the day, C++ programmers have only god knows what.
Rust, through its ownership and borrowing mechanisms, is guaranteed to be free of aliasing. Consider the following code
rust.
The corresponding compilation is as follows.
Can you see the difference?
Thoughts
I recently tried writing some Rust code and found it to be a really good experience. According to the Rust community, with Rust you can program fearlessly and never have to worry about memory errors or Data Race.
However, C++ is a liability and more of an asset for products that are heavily implemented in C++. The already existing C++ ecosystem is difficult to migrate to Rust, and Chrome only allows Rust code to be used in a three-party library.
There is also a heated debate on the internet about Rust versus C++. From my perspective.
- C++’s security evolution is trending, but the future is very uncertain: C++ has billions of lines of stock code worldwide, and expecting C++ to improve memory security while maintaining compatibility is a nearly impossible task. clang-format and clang-tidy, both provide line-filter to check for specific lines, to This avoids the situation where a change to an old file requires the whole file to be reformatted or all lint changes to fail. It is probably for this reason that Bjarne has been trying to improve the memory security of C++ by static analysis + local checking.
- Rust facilitates large team collaboration: as long as Rust code compiles and does not use the unsafe feature, it is guaranteed to have absolutely no memory safety or thread safety issues. This greatly reduces the mental burden of writing complex code. However, Rust’s safety is gained at the expense of language expressiveness, which can be a good thing for teamwork and code readability. As for the rest, I can’t make a further judgement until I have enough practical experience with Rust.