We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model that, while less capable than humans in many real-world scenarios, exhibits human-level performance on various professional and academic benchmarks.
At 1am today, the Open AI team tweeted the official announcement that GPT-4 is here!
GPT-4 will be one of the largest and most powerful language models developed by OpenAI, and OpenAI hopes to improve the language understanding and generation capabilities of GPT-4 by using more training data and higher model parameters.
The model parameters are expected to exceed trillions, several orders of magnitude more than the current state-of-the-art language model, GPT-3. This means GPT-4 will be better able to handle complex natural language processing tasks.
GPT-4 is a large multimodal model that receives image and text inputs and then outputs correct text responses. According to experimental results, GPT-4 performs at a human level on various professional tests and academic benchmarks. For example, it passed the mock bar exam and scored in the top 10% of test takers. In contrast, GPT-3.5 scored in the bottom 10%.
OpenAI spent six months using lessons learned from the adversarial testing program and ChatGPT to iteratively tweak GPT-4 to get the best results ever in terms of realism, controllability, and more.
Over the past two years, OpenAI has rebuilt its entire deep learning stack and worked with Azure to design a supercomputer from scratch for its workloads. A year ago, OpenAI tried the supercomputer for the first time while training GPT-3.5 and has successively found and fixed bugs and improved its theoretical foundation. The result of these improvements was an unprecedented stability in the training runs of GPT-4, so much so that OpenAI was able to accurately predict the training performance of GPT-4 ahead of time. This is the first large model to achieve this, and OpenAI says they will continue to focus on reliable extensions to further refine the method to help it achieve more robust advance prediction performance and the ability to plan for the future, which is critical for security.
OpenAI is releasing text input functionality for GPT-4 to the public via ChatGPT and APIs (with waitlists). OpenAI is actively collaborating with other companies in order to improve the usability of image input capabilities.
Today, OpenAI also released the open source code for OpenAI Evals, its framework for automatically evaluating the performance of AI models. This initiative is designed to enable a wide range of users to point out flaws in models and help OpenAI further improve model performance.
Ability
It is worth noting that the differences between GPT-3.5 and GPT-4 are subtle and significant. The difference only becomes apparent when the task complexity reaches a high enough threshold - GPT-4 is more reliable, more creative, and capable of handling more subtle instructions than GPT-3.5. To compare the differences between the two models, OpenAI conducted experiments in various benchmark tests and some mock exams designed for humans.
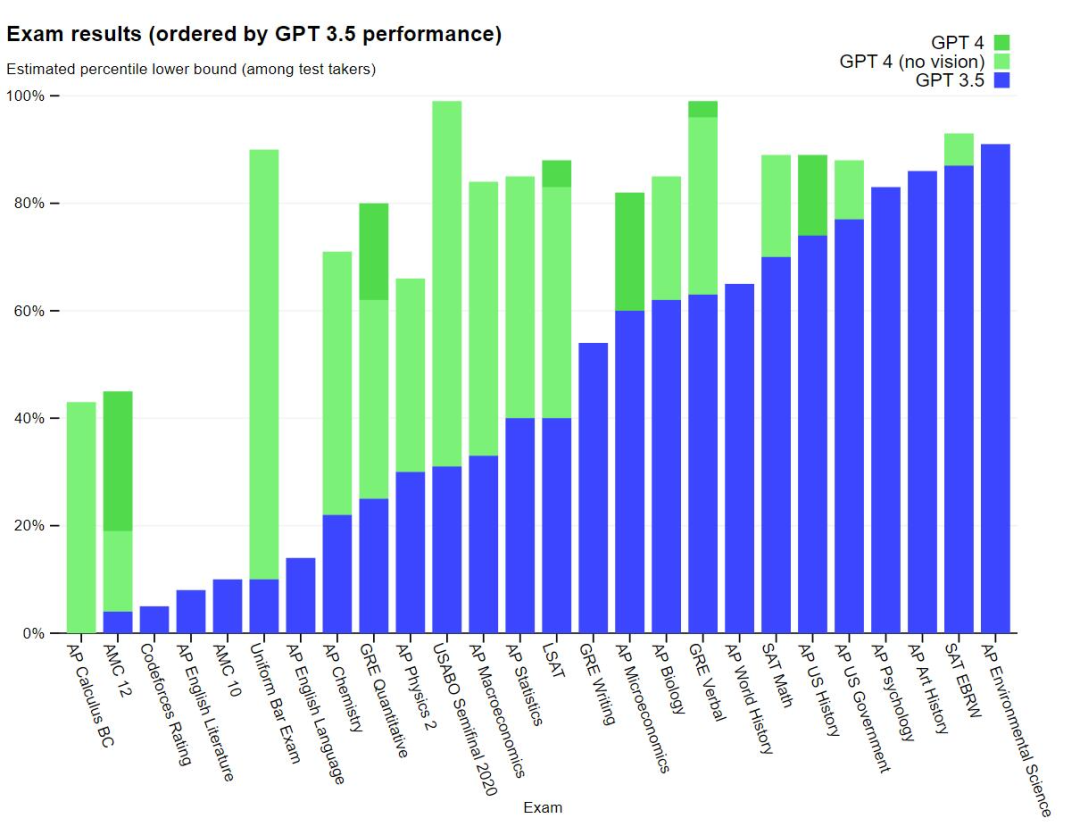
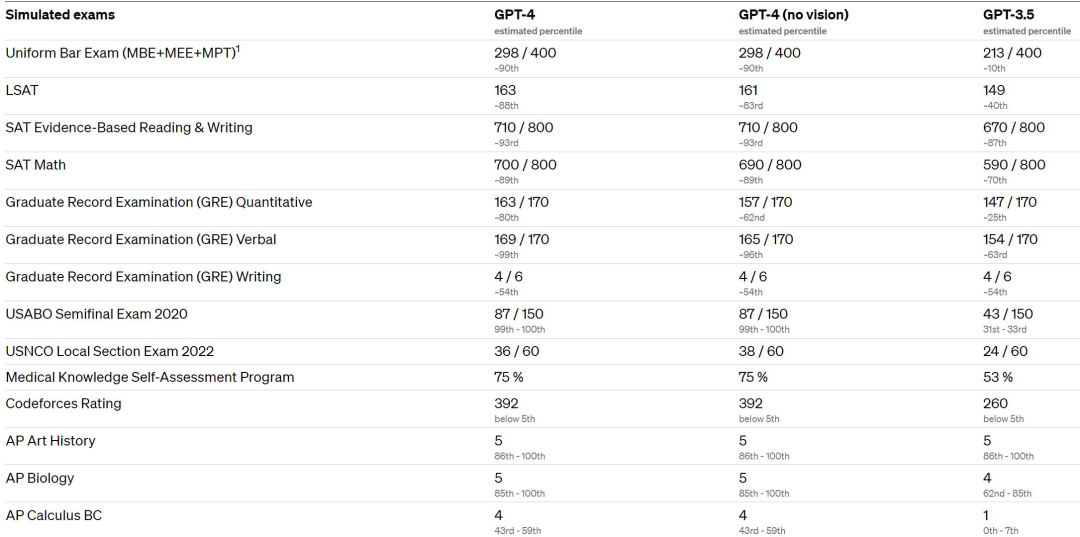
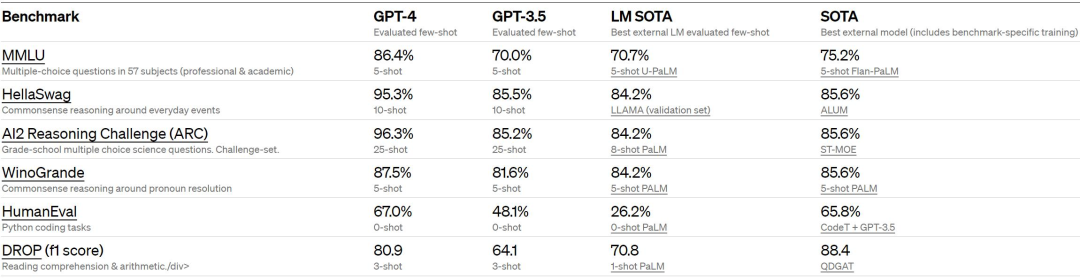
OpenAI conducted a traditional benchmark test on GPT-4 to evaluate its machine learning model performance. The results show that GPT-4 performs significantly better in large language models and most SOTA models.
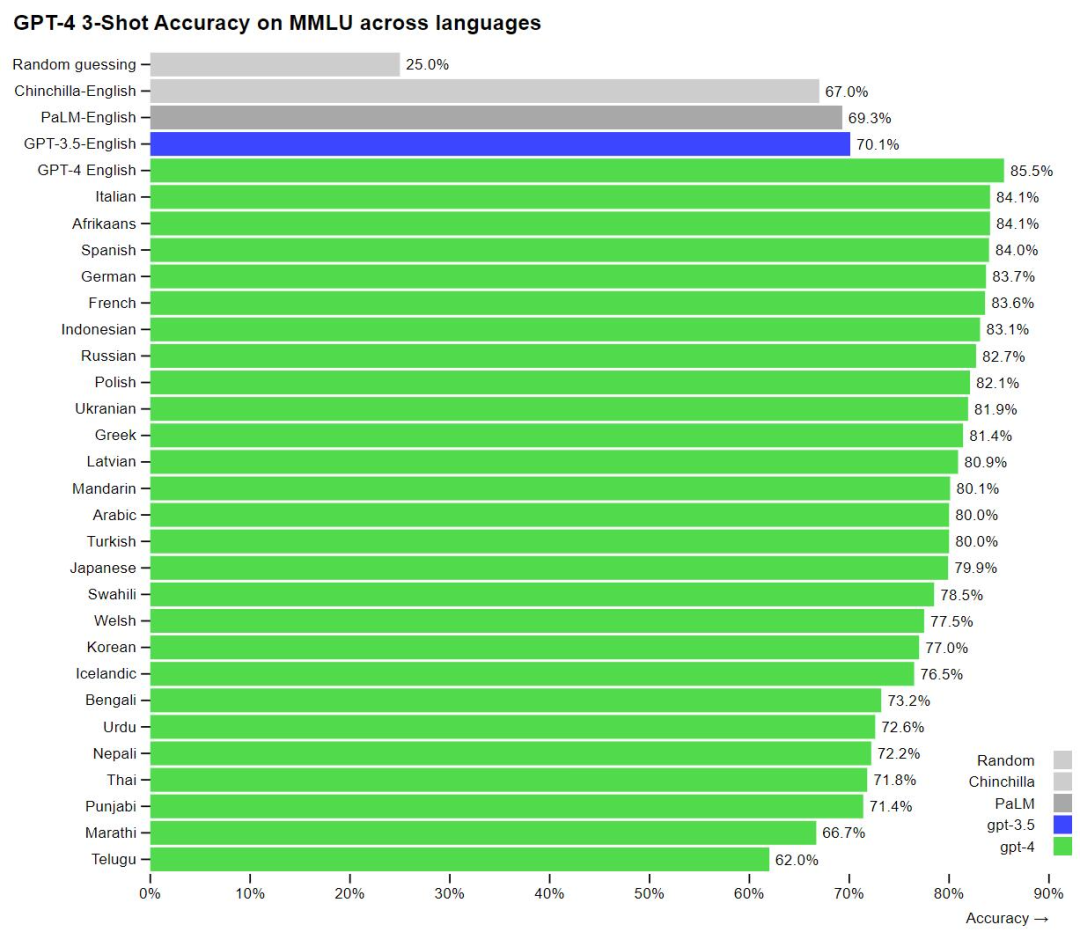
To test GPT-4’s performance on other languages, the research team used Azure Translate to translate the MMLU benchmark, which contains more than 14,000 multiple-choice questions on 57 topics, into multiple languages. The experimental results showed that GPT-4 outperformed other large language models such as GPT-3.5, Chinchilla, and PaLM in 24 of the 26 languages tested in terms of English performance.
Like many companies using ChatGPT, OpenAI is using GPT-4 internally and focusing on its effectiveness in areas such as content generation, sales, and programming. OpenAI is also using GPT-4 to assist people in evaluating AI output, the second phase of OpenAI’s implementation of its strategy. openAI is both a developer and a user of GPT-4.
Visual input
GPT-4 can accept prompts containing both text and images, allowing the user to specify any visual or linguistic task as opposed to a text-only setup. Specifically, it can generate textual output (natural language, code, etc.) given interleaved text and image inputs. In multiple domains, including documents composed of text and photos, diagrams, or screenshots, GPT-4 exhibits capabilities similar to those of text-only input. In addition, it can be augmented with test-time techniques developed for plain text language models, including fewer samples and thought chain cues. Image input is still in the research preview phase and is not available to the public.
Input a funny image to GPT-4.

The user enters “What’s weird about this picture? Describe it one image at a time” and GPT-4 will describe each image separately and point out that it is ridiculous to plug a large, outdated VGA port into a small, modern smartphone charging port.

Reason out the answer based on the graph. The user asks what is the total average daily meat consumption in Georgia and West Asia.
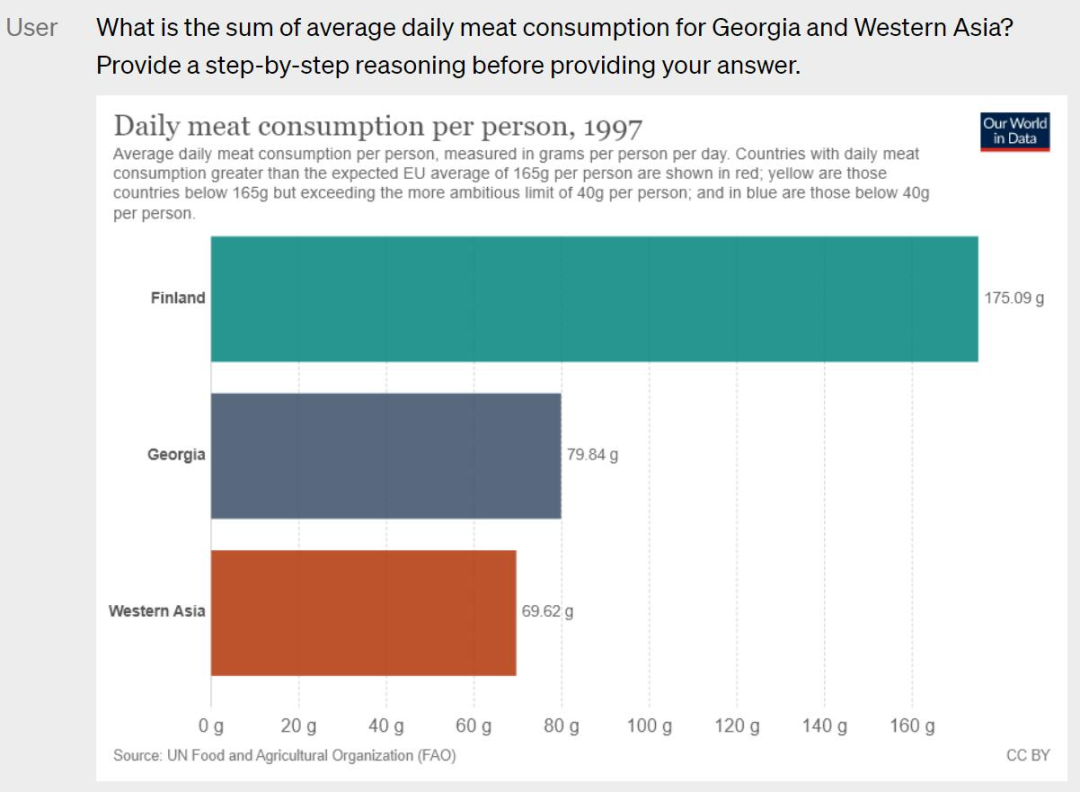
The GPT-4 can also be answered on demand.

Users can also directly give a photo of the exam question and let GPT-4 think about the answer step by step.

GPT-4 not only reads and understands, but also gives a complete answer.

What’s strange about this image?

GPT-4 succinctly answers the question “The unusual thing about this image is that a man is roning clothes on an ironing board attached tothe roof of a moving taxi.”.
OpenA I has previewed the performance of GPT-4 by evaluating it on a set of standard academic vision benchmarks. However, these numbers do not fully represent the extent of its capabilities, as OpenAI continues to find models capable of handling new and exciting tasks. openAI plans to release additional analysis and evaluation data soon, as well as a thorough investigation of the impact of the time-to-test technology.
Controllability
Unlike the classic ChatGPT personality with its fixed lengthy, calm tone and style, developers (and ChatGPT users) can now specify the style and tasks of their AI by describing these directions in a “system” message.
System messages allow API users to customize to achieve different user experiences within certain limits. openAI encourages you to do the same.
Restrictive
Despite its already powerful capabilities, GPT-4 still has similar limitations to earlier GPT models, not the least of which is that it is still not completely reliable. openAI says that GPT-4 still produces illusions, generates wrong answers, and makes inference errors.
For now, the use of language models should be carefully reviewed for output content, using exact protocols that match the needs of a particular use case if necessary (e.g., manual review, additional context, or avoiding use altogether) .
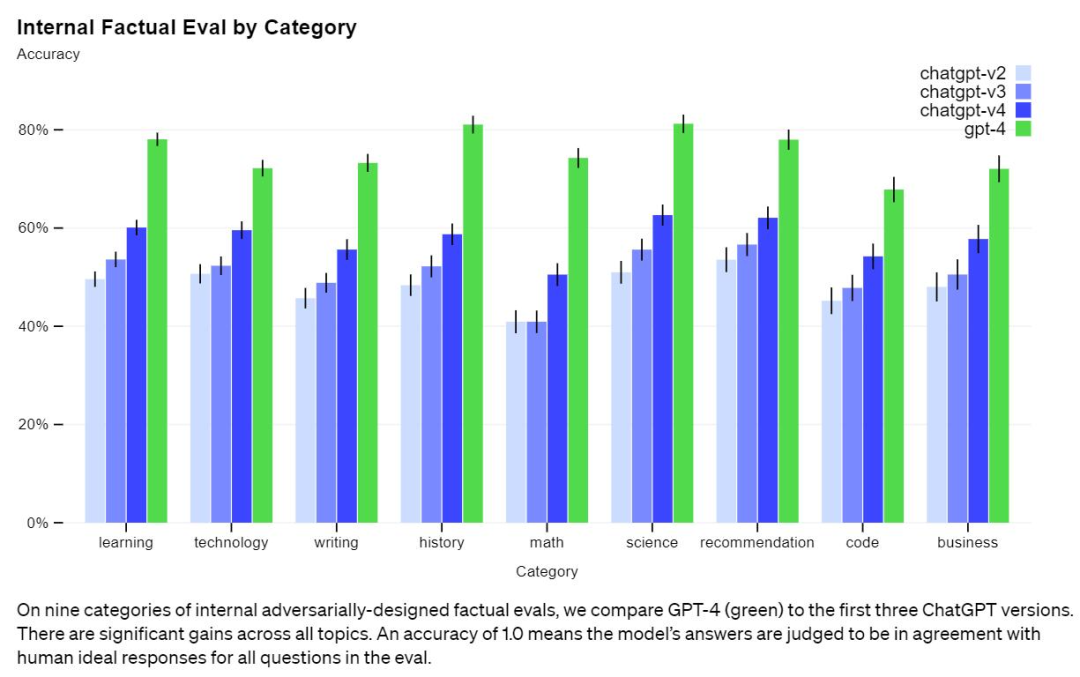
While this remains a real problem, GPT-4 significantly reduces the number of illusions relative to previous models (which themselves have been improved with each iteration). In an internal counterfactuality evaluation, GPT-4 scored 40% higher than the latest GPT-3.5.
GPT-4 has also made progress on external benchmarks such as TruthfulQA, where OpenAI tested the model’s ability to distinguish facts from adversarial choices of misrepresentation, with the results shown below.
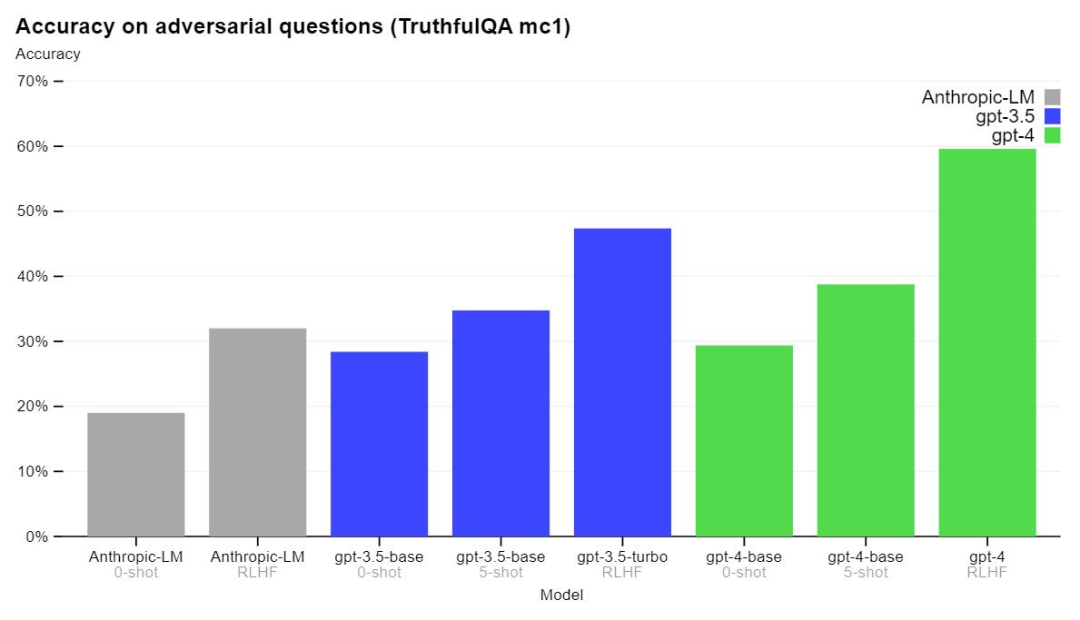
The experimental results show that the basic model of GPT-4 is only slightly better than GPT-3.5 based on this task, but after RLHF training, the difference between them becomes significant. Below is an example of GPT-4 in the test, and it is important to note that it does not make the right choice in all cases.

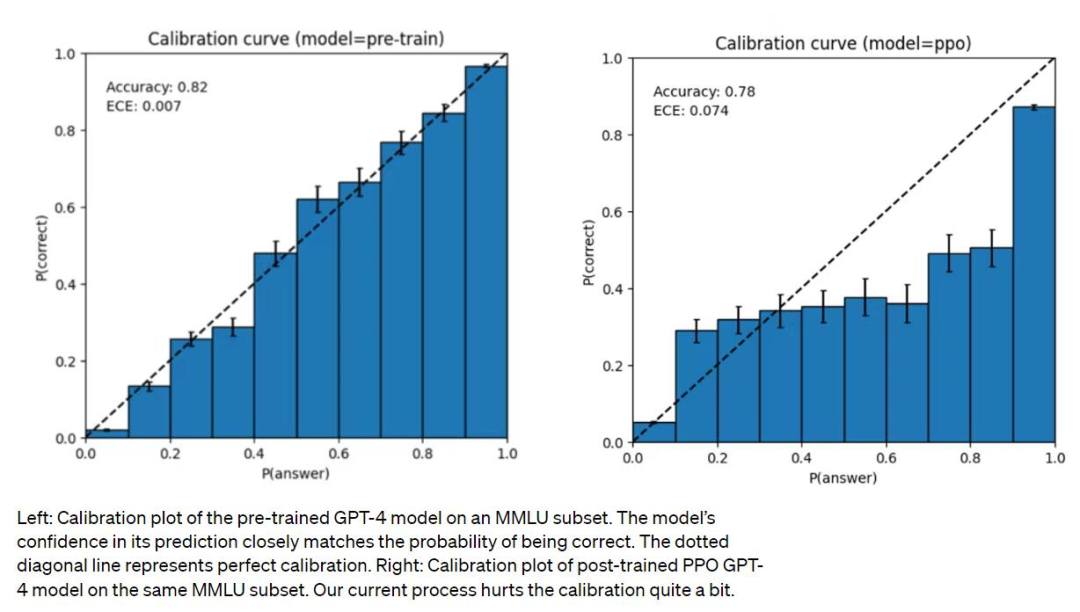
OpenAI is working to remove bias from AI models. Although the GPT-4 model is trained on data through September 2021, it does not learn from experience as humans do, and sometimes makes simple inference errors and places excessive trust in false statements. It also sometimes fails in dealing with difficult problems. In addition, GPT-4 may also make errors when predicting, but is confident enough not to check again. While the underlying pre-trained model is highly calibrated, calibration is reduced through OpenAI’s post-training process. openAI’s goal is to have AI systems with reasonable default behavior that reflects a wide range of user values.
Risks and Mitigation Measures
OpenAI says they have been iterating on GPT-4 to make it safer and more consistent from the start of training. To do this, they have taken a number of steps, including selecting and filtering pre-training data, conducting evaluations and expert engagement, improving model security, and monitoring and enforcement.
While GPT-4 has similar risks to previous models, such as generating harmful suggestions, incorrect code, or inaccurate information, GPT-4’s additional capabilities also lead to new risks. To assess the extent of these risks, the OpenAI team engaged more than 50 experts from the areas of AI alignment risk, cybersecurity, biorisk, trust and security, and international security to conduct adversarial tests of the models’ behavior in high-risk areas. These areas required expertise to assess, and feedback and data from the experts informed mitigation measures and model improvements.
Risk Prevention
According to OpenAI engineers in the demo video, the training of GPT-4 was completed in August last year, followed by fine-tuning and enhancement, and the most important removal of content generation.
In RLHF training, GPT-4 adds an additional safety reward signal to reduce harmful output by training the model to reject requests for harmful content. The reward is provided by GPT-4’s zero-sample classifier, which evaluates security boundaries and the way security-related prompts are completed. To prevent the model from rejecting valid requests, the team collects diverse datasets from various sources (e.g., labeled production data, model-generated prompts) and applies the security reward signal (with positive or negative values) on the allowed and disallowed categories.
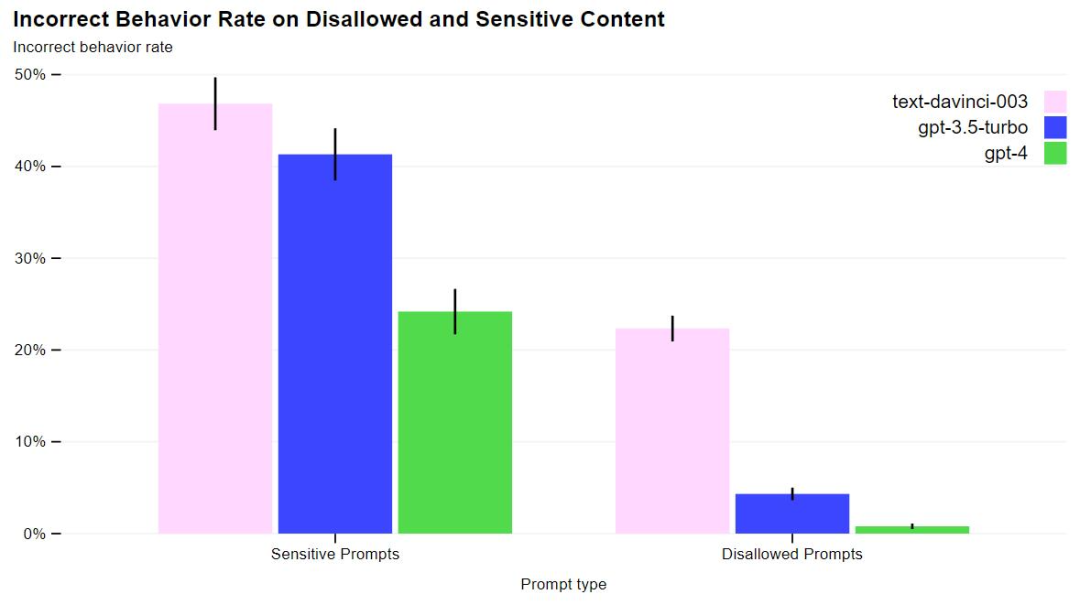
These measures significantly improved GPT-4’s security performance in many areas. Compared to GPT-3.5, the model’s propensity to respond to requests for impermissible content was reduced by 82%, while the frequency of responses to sensitive requests (such as medical advice and self-harm) was increased by 29% in compliance with the policy.
Training process
Like previous GPT models, the GPT-4 base model is trained to predict the next word in a text. openAI uses publicly available data (e.g., Internet data) and licensed data for training, and the dataset includes a large number of correct and incorrect solutions to mathematical problems, weak and strong reasoning, contradictory and consistent statements, and a wide range of ideologies and ideas.
Since the base model’s responses may not match the user’s intent, OpenAI employs Reinforcement Learning Human Feedback (RLHF) to fine-tune the model’s behavior in order to maintain its consistency with the user’s intent. It is important to note that the model’s ability seems to come mainly from the pre-training process, and RLHF does not improve test performance (and may even degrade it). However, the control of the model comes from the post-training process and even requires timely engineering to answer the questions.
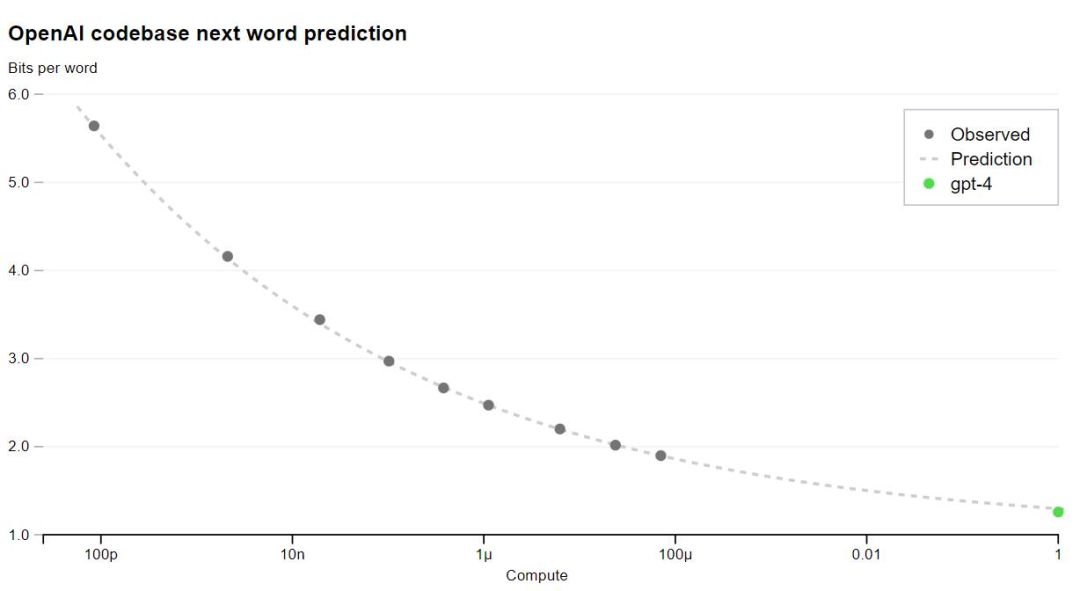
A major focus of GPT-4 is to build a predictable deep learning stack. This is primarily because for training at a scale as large as GPT-4, extensive model-specific tuning is not feasible. The team developed infrastructure and optimizations that can exhibit predictable behavior at multiple scales. To verify this scalability, they predicted the final loss of GPT-4 on an internal codebase (not part of the training set), extrapolating through a model trained using the same approach but using only 1/10,000th of the original computation.
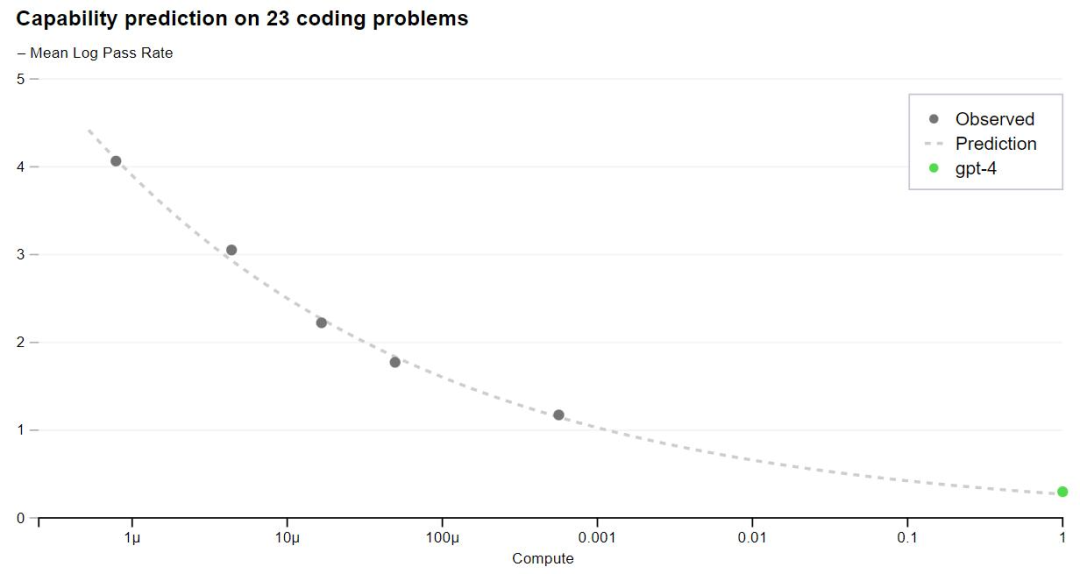
OpenAI can now accurately predict the metrics (losses) that are optimized during training. For example, the pass rate of a subset of the HumanEval dataset was inferred and successfully predicted from a model with 1/1000th of the computation.
Some capabilities remain unpredictable. For example, the Inverse Scaling competition aims to find a metric that gets worse as the model computes more, and the hindsight neglect task was one of the winners. gpt-4 reverses this trend.
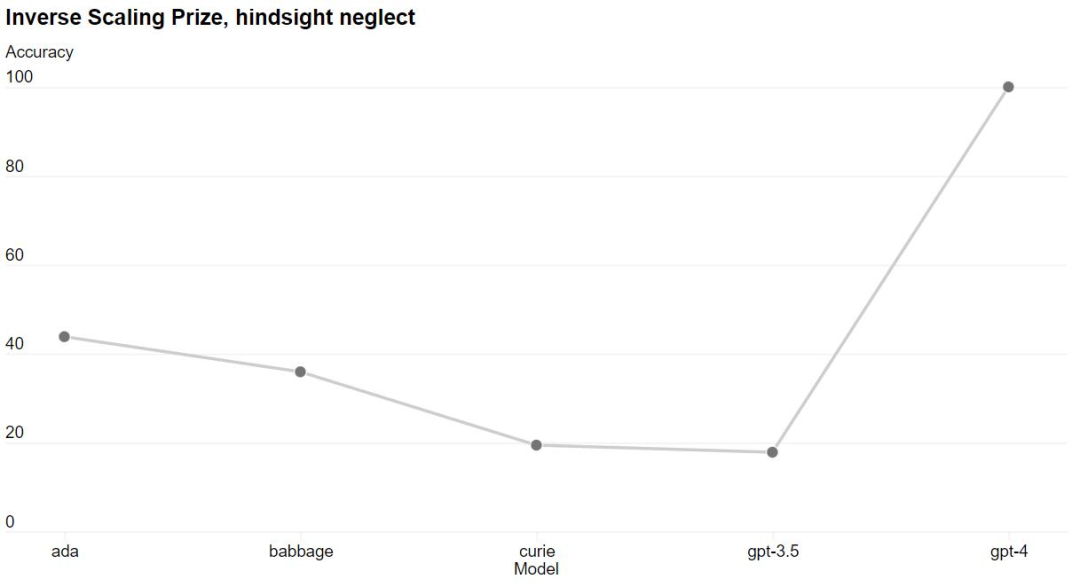
The ability to accurately predict the future of machine learning models is critical to technology security, but the issue has not received enough attention. openAI says they are putting more effort into developing relevant methods and are calling on the industry to work together to address this issue.
OpenAI Evals
OpenAI says it is open-sourcing the OpenAI Evals software framework, which is used to create and run benchmark tests to evaluate models such as GPT-4, while allowing model performance to be examined on a sample-by-sample basis.
OpenAI upgraded ChatGPT directly after the release of GPT-4. ChatGPT Plus subscribers can get access to GPT-4 with usage caps at chat.openai.com.
API
To access the GPT-4 API (which uses the same ChatCompletions API as gpt-3.5-turbo), users can register to wait. openAI will invite some developers to experience it.
Currently, users can send plain text requests to GPT-4 models by gaining access (image input is still in a limited alpha stage). Pricing is $0.03 per 1k prompt token and $0.06 per 1k completion token. The default rate limit is 40k tokens per minute and 200 requests per minute.
OpenAI has released two versions of GPT-4, one with a context length of 8,192 tokens and the other with a context length of 32,768 tokens (equivalent to about 50 pages of text), and this version has limited access and will also be updated automatically over time (The current version is gpt-4-32k-0314, supported until June 14). According to the pricing strategy, the price per 1K prompt token is $0.06 and per 1K completion token is $0.12.
Summary
OpenAI expects GPT-4 to be a valuable tool to improve people’s lives by powering many applications. While there is still much work to be done, OpenAI expects the community to keep building, exploring, and contributing on top of the model to continuously improve its capabilities.