
1. Introduction to the Arrow Project
According to the official description of the Arrow project: “Apache Arrow is a development platform for in-memory analytics. It contains a set of technologies that enable big data systems to process and move data quickly. It specifies a standardised language-independent columnar in-memory format for flat and hierarchical data, organised with efficient analytical operations for data on modern hardware in mind”.
-
Apache Arrow has written a programming language-independent in-memory format specification (currently at v1.3), a columnar storage format that enables compressed storage of highly compressed data, efficient performance analysis operations and low-overhead data transfer without serialisation and deserialisation.
The diagram below shows Arrow’s columnar storage format. At the top is a logical table which has three columns: ARCHER, LOCATION and YEAR. In the bottom left is the in-memory storage method of implementing a logical table using row storage, while in the bottom right is Arrow’s solution of implementing a logical table using a columnar storage format.
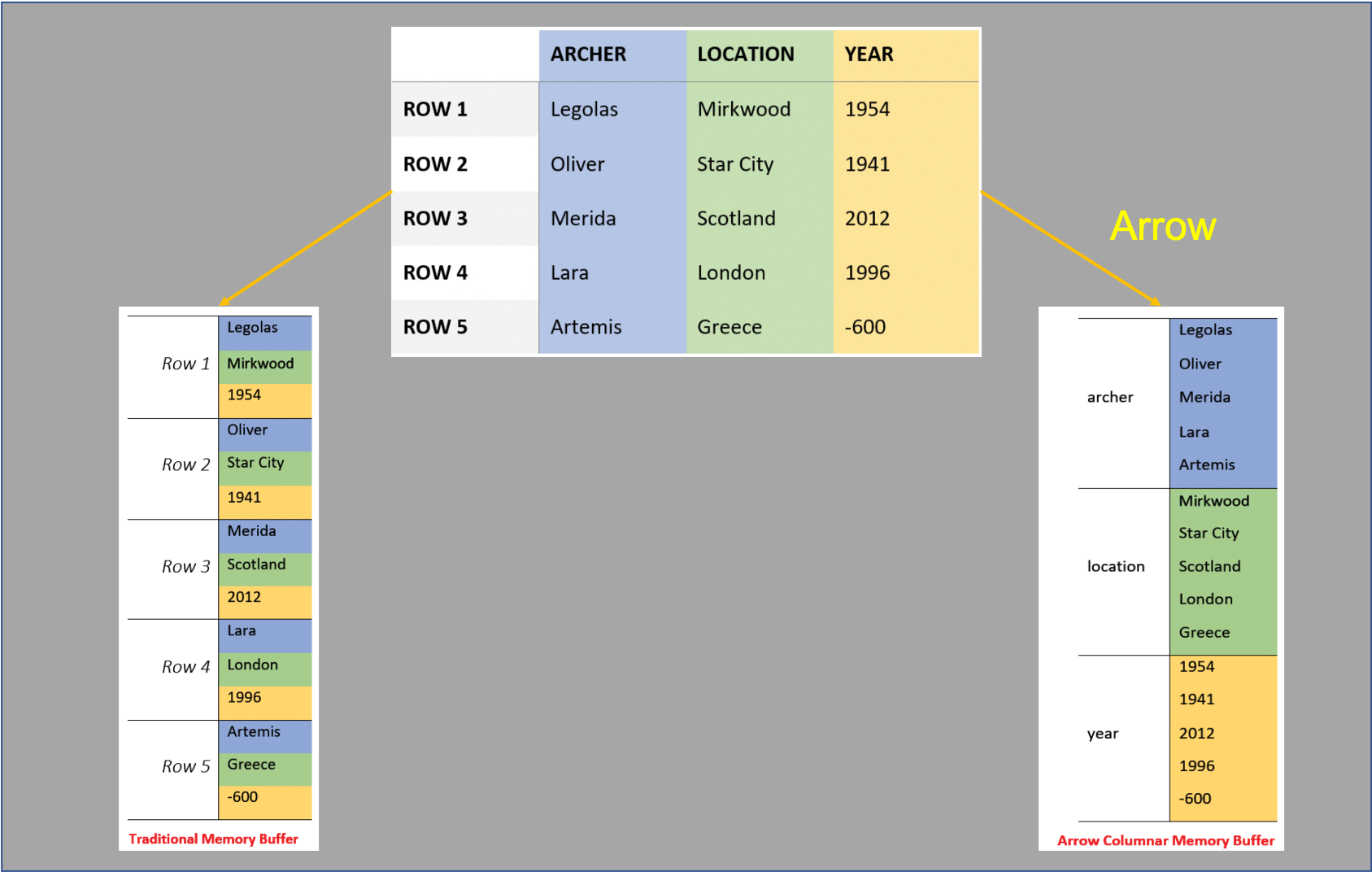
Note: The above image is a stitching together of several images from the book “In-Memory Analytics with Apache Arrow”.
-
A set of specifications that everyone follows so that data is passed and processed without the need for serialisation and deserialisation.
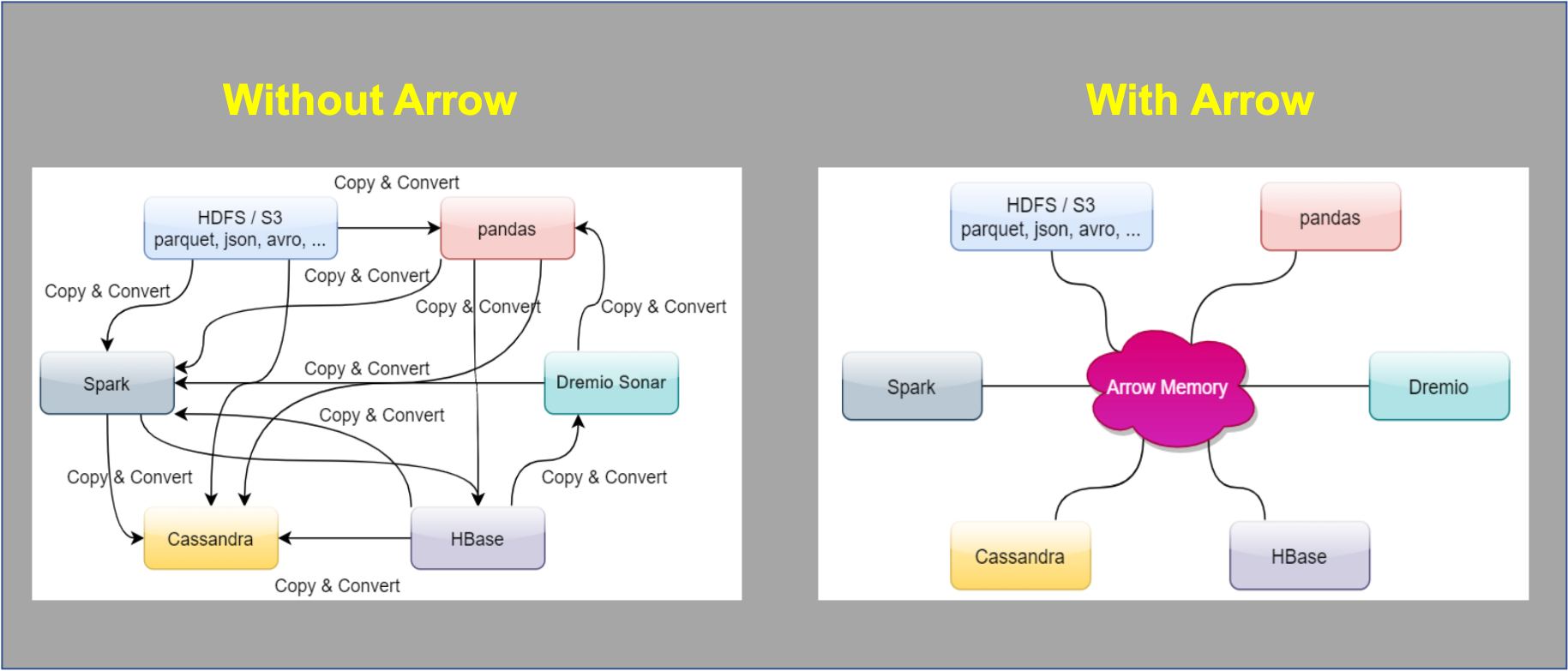
Note: The image above is also a stitching of 2 images from the book In-Memory Analytics with Apache Arrow.
-
Multiple implementations of major programming languages.
Below is the implementation and support matrix for each programming language of the Arrow project.
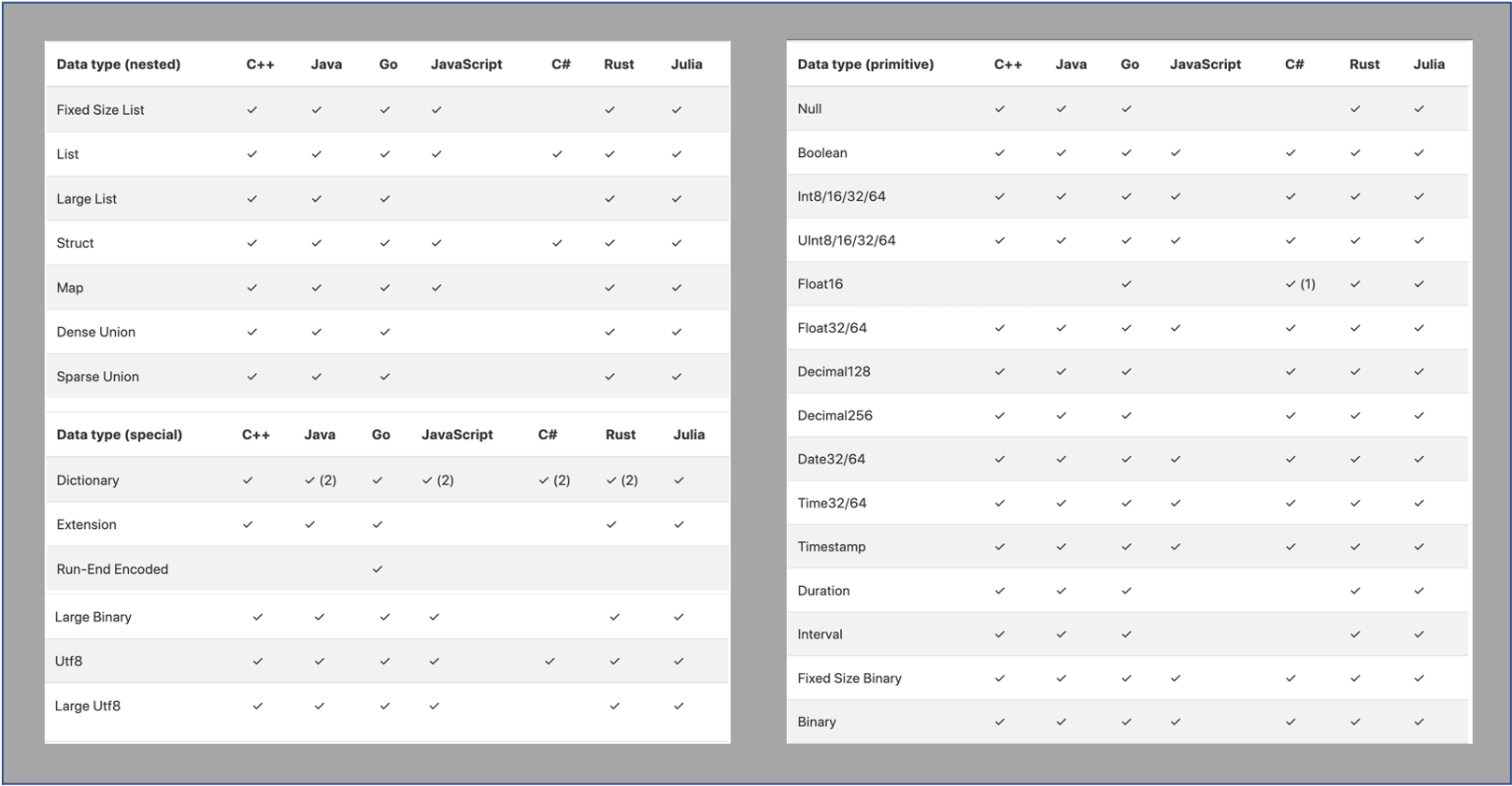
We have seen that Arrow is currently more comprehensively supported in C++, Java, Go and Rust.
-
Communication transfer and disk storage
Arrow’s sub-project Arrow Flight RPC provides a standard method of communication transfer for systems using Arrow’s in-memory format.
Apache’s other top-level project, Parquet, is often used as a disk storage format for Arrow data, and the InfluxDB iox project converts in-memory Arrow format data into Parquet for storage in object storage.
Having understood the general context of the Arrow project, let’s move on to the core specification of the Arrow project: the Arrow Columnar Format.
Many people hate reading so-called “specifications”, they are too abstract, too conceptual, and too mind-boggling to chew on. Unfortunately, the Arrow Columnar Format specification also falls into this category.
Without understanding the terminology and concepts in the specification, we would probably not have been able to get going later on. Luckily we had the help of In-Memory Analytics with Apache Arrow to sort of get a grip and read the book and the specification together to make it slightly less difficult to understand.
Arrow’s columnar format has some key features, which are quoted here.
- Sequential access (scanning) for data adjacency
- O(1) (constant time) random access
- SIMD and vectorisation friendly
- Relocatable, no “pointer wiggle”, allowing true zero-copy access in shared memory
All of these key features tell us that Arrow has one advantage: it’s fast! This is why the influxdb iox engine uses Arrow as a form of in-memory data organisation, and Andrew Lamb gives a performance comparison between Rust using Arrow and not using Arrow in his presentation.

We see that an Arrow-based implementation is much faster than a native Rust implementation!
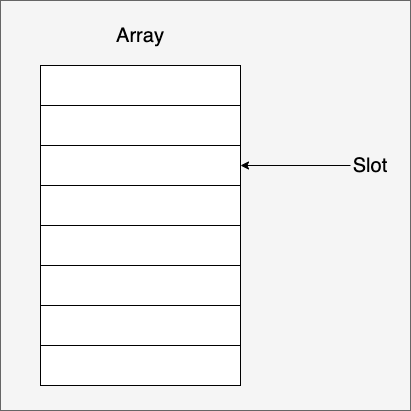
As mentioned earlier: Arrow is a columnar storage format, and its core type is Array.
An Array is a sequence of isomorphic type values of known length, and a value in an Array is called a slot:
The specification also defines the physical layout of the memory representation of an Array, which usually consists of multiple buffers, each of which is effectively a contiguous region of fixed length.
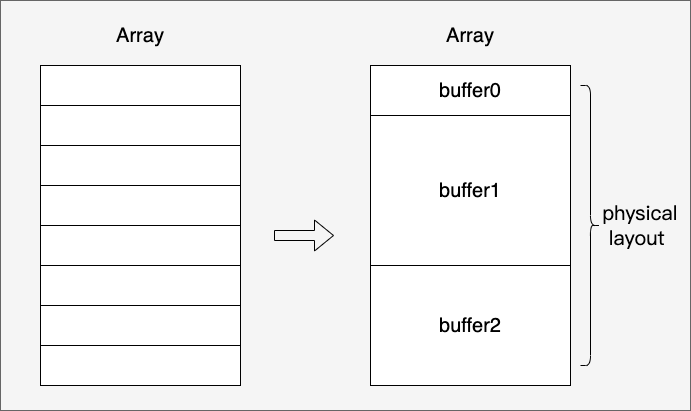
An Array supports nesting, like List<U> is a Nested type, while List<U> is called a parent array type and U is called a child array type. if an Array is not a nested type, then it is called a Primitive type.
To really understand Arrow, it is important to understand the physical layout of each array type, an array type is also called a logical type; Arrow defines several logical types, which have different physical layouts, but of course can also have the same physical layout. The logical types with the same physical layout can be grouped into one category and classified by layout type, which gives us the following table (from the book “In-Memory Analytics with Apache Arrow”).
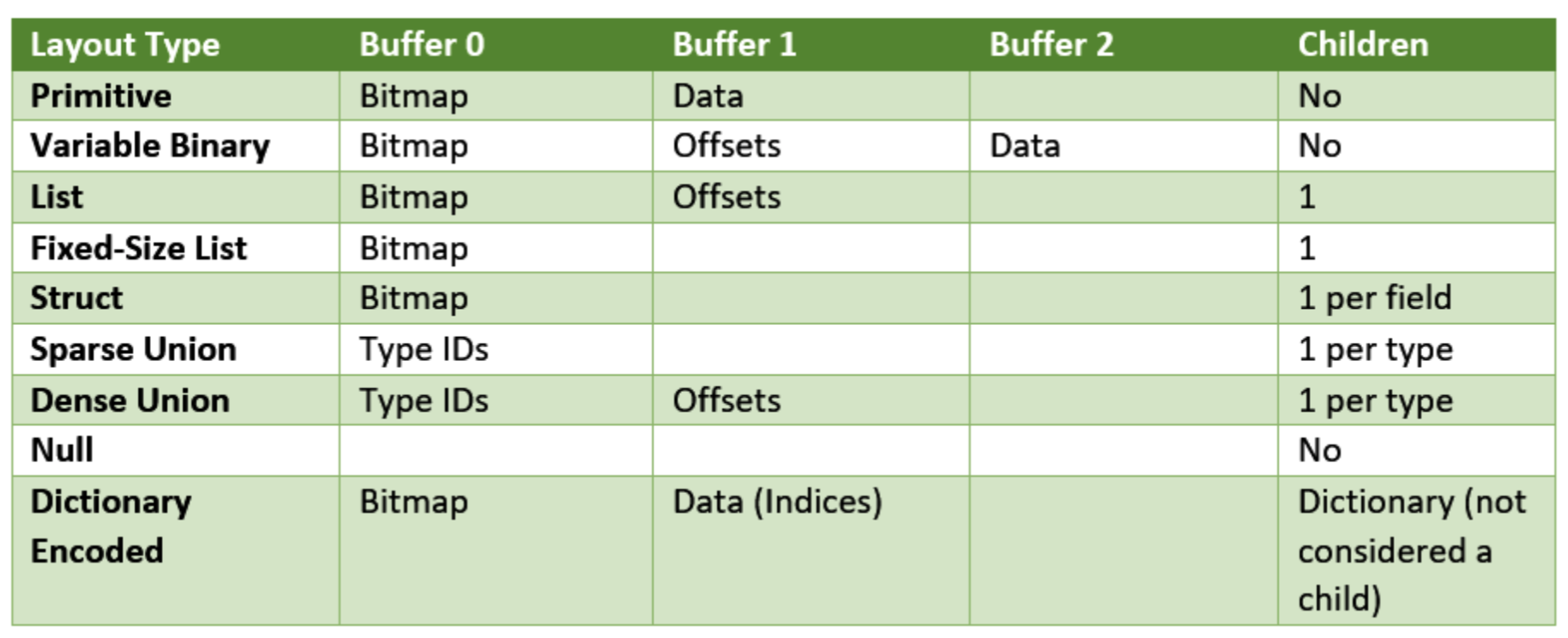
We see that there are buffer0s in different layouts that are not used to store data, for example, most layouts store a bitmap in buffer0 and some buffer1s store an offset, this non-data information is called metadata; in fact, an array is made up of some metadata and In fact, an array is a combination of some metadata and real data.
Let’s take a look at each of these layouts in turn.
3. data types
Before introducing Arrow’s array type, let’s briefly talk about metadata.
The Arrow array has the following common attributes that are stored in the metadata:
- Array length: the number of slots in the array, i.e. how many elements the array has, usually expressed as a 64-bit signed integer;
- Null count: the number of null value slots, also usually expressed as a 64-bit signed integer;
- Validity bitmaps: the bits in the bitmap indicate whether the corresponding array slot is null or not, and the array uses a “small-end bit order” of one byte (8 bits). The rightmost bit of the bitmap indicates whether the first slot in the array is null (unset means null), as shown in the following diagram:
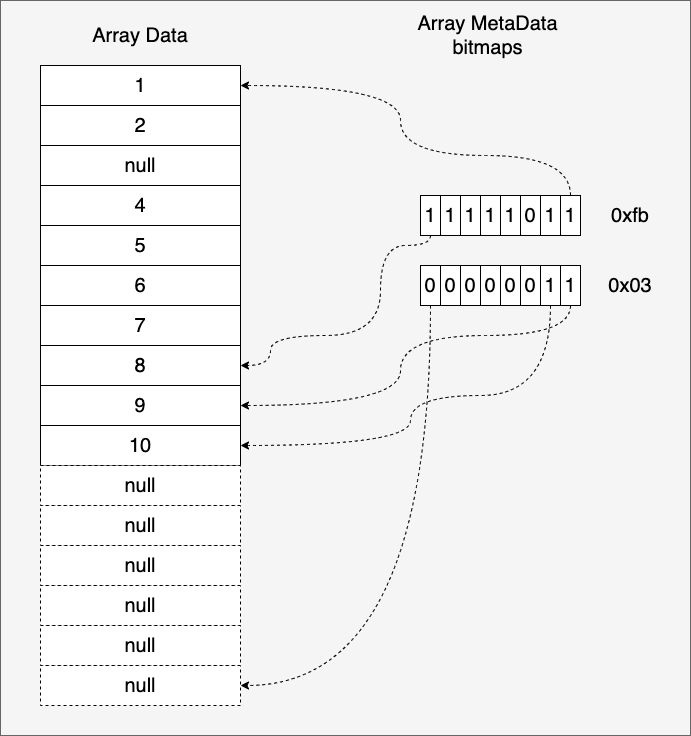
The following is an example of the code in the above schematic implemented with arrow’s go package:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// bitmap_of_array.go
package main
import (
"encoding/hex"
"fmt"
"github.com/apache/arrow/go/v13/arrow/array"
"github.com/apache/arrow/go/v13/arrow/memory"
)
func main() {
bldr := array.NewInt64Builder(memory.DefaultAllocator)
defer bldr.Release()
bldr.AppendValues([]int64{1, 2}, nil)
bldr.AppendNull()
bldr.AppendValues([]int64{4, 5, 6, 7, 8, 9, 10}, nil)
arr := bldr.NewArray()
defer arr.Release()
bitmaps := arr.NullBitmapBytes()
fmt.Println(hex.Dump(bitmaps)) // fb 03 00 00
fmt.Println(arr) // [1 2 (null) 4 5 6 7 8 9 10]
}
|
If an array has no null elements, then the bitmap can also be omitted.
After looking at the metadata, we will then look at some of the array logical types defined by arrow.
3.2 Null type
Null type is not null, it is a logical type that does not really need to allocate memory, here is the definition of NullType in the arrow go implementation.
1
2
|
// NullType describes a degenerate array, with zero physical storage.
type NullType struct{}
|
We know that struct{} does not take up any real memory space, and that NullType “inherits” this.
3.3 Primitive Type
Primitive type refers to an arrow array type with the same type of slot elements and a fixed length, and the following Primitive Types can be found in the Go source code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
var (
PrimitiveTypes = struct {
Int8 DataType
Int16 DataType
Int32 DataType
Int64 DataType
Uint8 DataType
Uint16 DataType
Uint32 DataType
Uint64 DataType
Float32 DataType
Float64 DataType
Date32 DataType
Date64 DataType
}{
... ...
}
)
|
Here are some highlights.
3.3.1 Boolean Type
Boolean Types are not included in the Primitive Types above, but in essence, Boolean Types also belong to the PrimitiveType category. In Arrow, Boolean array Types are stored using bits for each slot. Let’s look at an example.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
// boolean_array_type.go
package main
import (
"encoding/hex"
"fmt"
"github.com/apache/arrow/go/v13/arrow/array"
"github.com/apache/arrow/go/v13/arrow/memory"
)
func main() {
bldr := array.NewBooleanBuilder(memory.DefaultAllocator)
defer bldr.Release()
bldr.AppendValues([]bool{true, false}, nil)
bldr.AppendNull()
bldr.AppendValues([]bool{true, true, true, false, false, false, true}, nil)
arr := bldr.NewArray()
defer arr.Release()
bitmaps := arr.NullBitmapBytes()
fmt.Println(hex.Dump(bitmaps))
bufs := arr.Data().Buffers()
for _, buf := range bufs {
fmt.Println(hex.Dump(buf.Buf()))
}
fmt.Println(arr)
}
|
The output of this example is as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
$go run boolean_array_type.go
00000000 fb 03 00 00 |....|
00000000 fb 03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 39 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |9...............|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
[true false (null) true true true false false false true]
|
The first line of the output is the bitmap section.
The next two paragraphs are the layout of the two buffers that make up the boolean array. We see that the first buffer stores the bitmap and the second buffer stores the boolean data.
The first thing you think when you see this output is: why are so many bytes used? We counted that each buffer uses 64 bytes, which is inseparable from the alignment requirements of the array, which by default requires the buffer to be aligned to 64 bytes.
3.3.2 Integer types
arrow supports various integer types as primitive types, here is an example of int32:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// int32_array_type.go
func main() {
bldr := array.NewInt32Builder(memory.DefaultAllocator)
defer bldr.Release()
bldr.AppendValues([]int32{1, 2}, nil)
bldr.AppendNull()
bldr.AppendValues([]int32{4, 5, 6, 7, 8, 9, 10}, nil)
arr := bldr.NewArray()
defer arr.Release()
bitmaps := arr.NullBitmapBytes()
fmt.Println(hex.Dump(bitmaps))
bufs := arr.Data().Buffers()
for _, buf := range bufs {
fmt.Println(hex.Dump(buf.Buf()))
}
fmt.Println(arr)
}
|
The result of the execution of the above code is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
$go run int32_array_type.go
00000000 fb 03 00 00 |....|
00000000 fb 03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 01 00 00 00 02 00 00 00 00 00 00 00 04 00 00 00 |................|
00000010 05 00 00 00 06 00 00 00 07 00 00 00 08 00 00 00 |................|
00000020 09 00 00 00 0a 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
[1 2 (null) 4 5 6 7 8 9 10]
|
It is worth noting that the data buffer contains int32 stored in small-terminated byte order.
3.3.3 Float types
Go’s implementation of arrow supports float16, float32 and float64 precision floating point types, here is an example of the layout of float32.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// float32_array_type.go
func main() {
bldr := array.NewFloat32Builder(memory.DefaultAllocator)
defer bldr.Release()
bldr.AppendValues([]float32{1.0, 2.0}, nil)
bldr.AppendNull()
bldr.AppendValues([]float32{4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.1}, nil)
arr := bldr.NewArray()
defer arr.Release()
bitmaps := arr.NullBitmapBytes()
fmt.Println(hex.Dump(bitmaps))
bufs := arr.Data().Buffers()
for _, buf := range bufs {
fmt.Println(hex.Dump(buf.Buf()))
}
fmt.Println(arr)
}
|
The result of the execution of the above code is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
$go run float32_array_type.go
00000000 fb 03 00 00 |....|
00000000 fb 03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 00 00 80 3f 00 00 00 40 00 00 00 00 00 00 80 40 |...?...@.......@|
00000010 00 00 a0 40 00 00 c0 40 00 00 e0 40 00 00 00 41 |...@...@...@...A|
00000020 00 00 10 41 9a 99 21 41 00 00 00 00 00 00 00 00 |...A..!A........|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
[1 2 (null) 4 5 6 7 8 9 10.1]
|
3.4 Variable-size Binary Type
The Primitive Types slot is a fixed-length type; for the Variable-size slot, Arrow defines the Variable-size Binary Type.
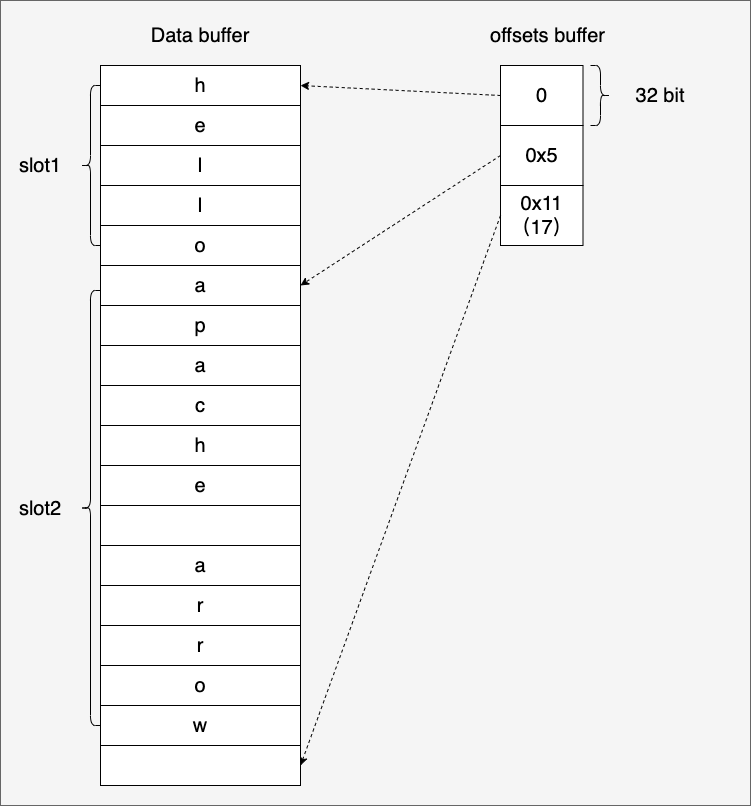
In the previous table of different types of layout we saw that the Variable-size Binary Type has a bitmap buffer, a data buffer and an offset buffer.
Let’s take the typical string array as an example and see what the layout of the Variable-size Binary Type looks like.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// string_array_type.go
func main() {
bldr := array.NewStringBuilder(memory.DefaultAllocator)
defer bldr.Release()
bldr.AppendValues([]string{"hello", "apache arrow"}, nil)
arr := bldr.NewArray()
defer arr.Release()
bitmaps := arr.NullBitmapBytes()
fmt.Println(hex.Dump(bitmaps))
bufs := arr.Data().Buffers()
for _, buf := range bufs {
fmt.Println(hex.Dump(buf.Buf()))
}
fmt.Println(arr)
}
|
Run the example.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
$go run string_array_type.go
00000000 03 |.|
00000000 03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 00 00 00 00 05 00 00 00 11 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 68 65 6c 6c 6f 61 70 61 63 68 65 20 61 72 72 6f |helloapache arro|
00000010 77 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |w...............|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
["hello" "apache arrow"]
|
We see that the Variable-size Binary Type uses three buffers, except for the first bitmap buffer and the last data buffer, the middle one is the offset buffer. In the offset buffer, the arrow uses an integer to indicate the starting offset of each slot, and the above example is organized into a diagram to make it clearer.
3.5 Fixed-Size List type
Based on the Primitive Types above, arrow provides “nested types” such as List types. list types are divided into two categories, Fixed-Size List types and Variable-Size List types. Let’s look at the Fixed-Size List type first.
As the name implies, Fixed-Size List type means that each slot of a list stores a value of the same type and a fixed length, which can be written as FixedSizeList<T>[N]; T can be a Primitive type or another nested type, and N is the length of T.
The following is an example of a fixed-size list type, where the Fixed-Size List type can be represented as FixedSizeList<Int32>[3], i.e. each slot in the list stores a [3]int32 array:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
// fixed_list_array_type.go
func main() {
const N = 3
var (
vs = [][N]int32{{0, 1, 2}, {3, 4, 5}, {6, 7, 8}, {9, -9, -8}}
)
lb := array.NewFixedSizeListBuilder(memory.DefaultAllocator, N, arrow.PrimitiveTypes.Int32)
defer lb.Release()
vb := lb.ValueBuilder().(*array.Int32Builder)
vb.Reserve(len(vs))
for _, v := range vs {
lb.Append(true)
vb.AppendValues(v[:], nil)
}
arr := lb.NewArray().(*array.FixedSizeList)
defer arr.Release()
bitmaps := arr.NullBitmapBytes()
fmt.Println(hex.Dump(bitmaps))
varr := arr.ListValues().(*array.Int32)
bufs := varr.Data().Buffers()
for _, buf := range bufs {
fmt.Println(hex.Dump(buf.Buf()))
}
fmt.Println(arr)
}
|
We no longer print the Buffer layout of FixedSizeList directly as before, we only output the bitmap buffer of FixedSizeList, the buffer of its value needs to be obtained to its values and then output through the buffer of values type. The above example outputs the following:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
$go run fixed_list_array_type.go
00000000 0f 00 00 00 |....|
00000000 ff 0f 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 00 00 00 00 01 00 00 00 02 00 00 00 03 00 00 00 |................|
00000010 04 00 00 00 05 00 00 00 06 00 00 00 07 00 00 00 |................|
00000020 08 00 00 00 09 00 00 00 f7 ff ff ff f8 ff ff ff |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
[[0 1 2] [3 4 5] [6 7 8] [9 -9 -8]]
|
There are two bitmaps, one for FixedSizeList and one for its values type, whose value type is a fixed-length int32 primitive array type. In-Memory Analytics with Apache Arrow, you can also take a deeper look at the layout of a FixedSizeList with the help of a diagram in the book.
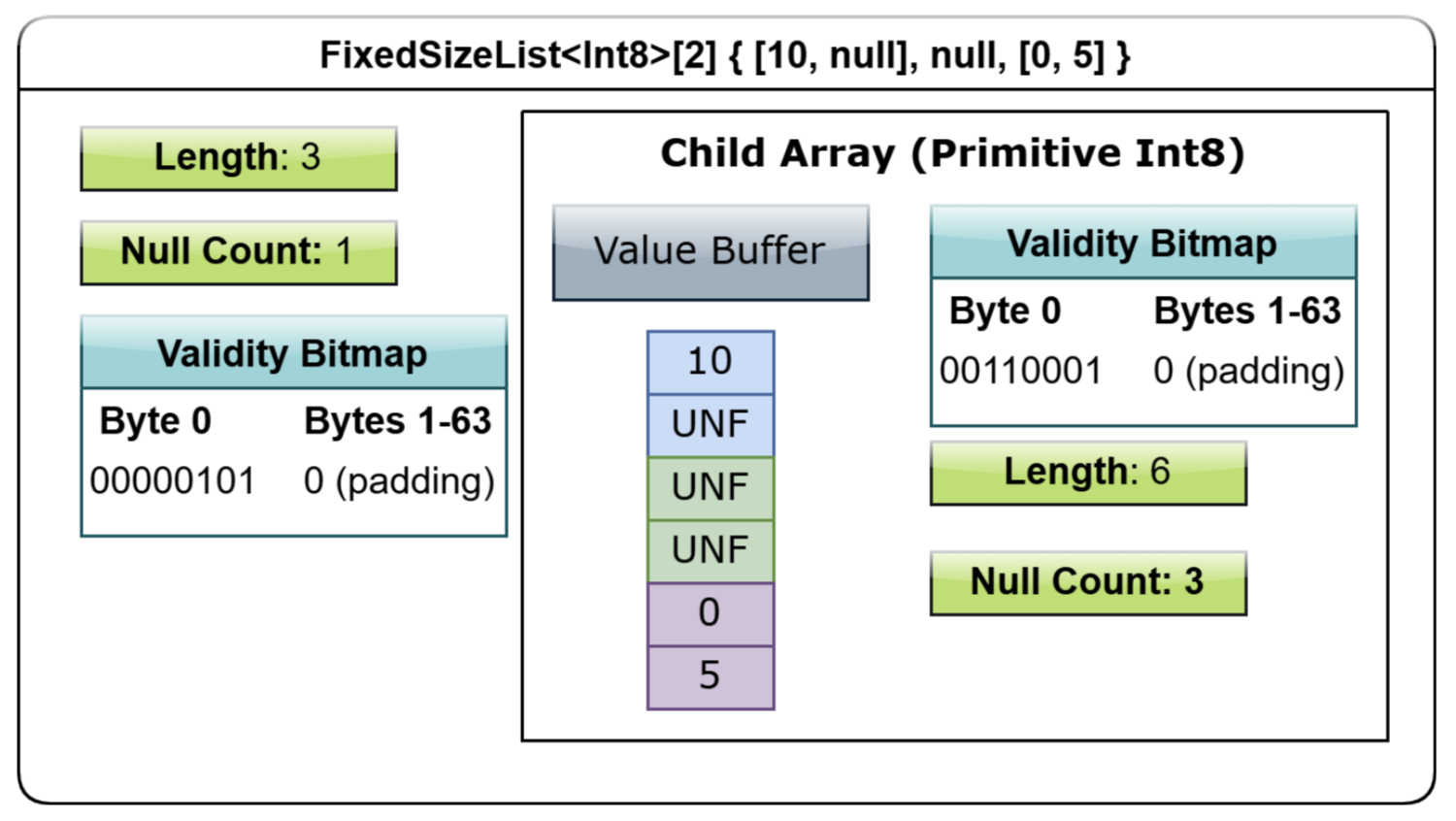
3.6 Variable-Size List type
The Variable-Size List type is easier to understand than the FixedSizeList. Like the variable-size binary type, the Variable-Size List type adds an offset buffer to the bitmap buffer compared to the FixedSizeList, as we see in the following example.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
// variable_list_array_type.go
func main() {
var (
vs = [][]int32{{0, 1}, {2, 3, 4, 5}, {6}, {7, 8, 9}}
)
lb := array.NewListBuilder(memory.DefaultAllocator, arrow.PrimitiveTypes.Int32)
defer lb.Release()
vb := lb.ValueBuilder().(*array.Int32Builder)
vb.Reserve(len(vs))
for _, v := range vs {
lb.Append(true)
vb.AppendValues(v[:], nil)
}
arr := lb.NewArray().(*array.List)
defer arr.Release()
bitmaps := arr.NullBitmapBytes()
fmt.Println(hex.Dump(bitmaps))
bufs := arr.Data().Buffers()
for _, buf := range bufs {
fmt.Println(hex.Dump(buf.Buf()))
}
varr := arr.ListValues().(*array.Int32)
bufs = varr.Data().Buffers()
for _, buf := range bufs {
fmt.Println(hex.Dump(buf.Buf()))
}
fmt.Println(arr)
}
|
The results of the above example run are as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
$go run variable_list_array_type.go
00000000 0f 00 00 00 |....|
00000000 0f 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 00 00 00 00 02 00 00 00 06 00 00 00 07 00 00 00 |................|
00000010 0a 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 ff 03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 00 00 00 00 01 00 00 00 02 00 00 00 03 00 00 00 |................|
00000010 04 00 00 00 05 00 00 00 06 00 00 00 07 00 00 00 |................|
00000020 08 00 00 00 09 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
[[0 1] [2 3 4 5] [6] [7 8 9]]
|
The first two blocks of data are the bitmap buffer and offset buffer of the Variable-Size List type, while the second two blocks of data are the bitmap buffer and data buffer of the int32 array type. buffer of the Variable-Size List type has four offsets: 0, 2, 6, 7, each pointing to the corresponding position in the data buffer of the int32 array type.
A diagram from the book In-Memory Analytics with Apache Arrow can help us understand the layout of a Variable-size List.
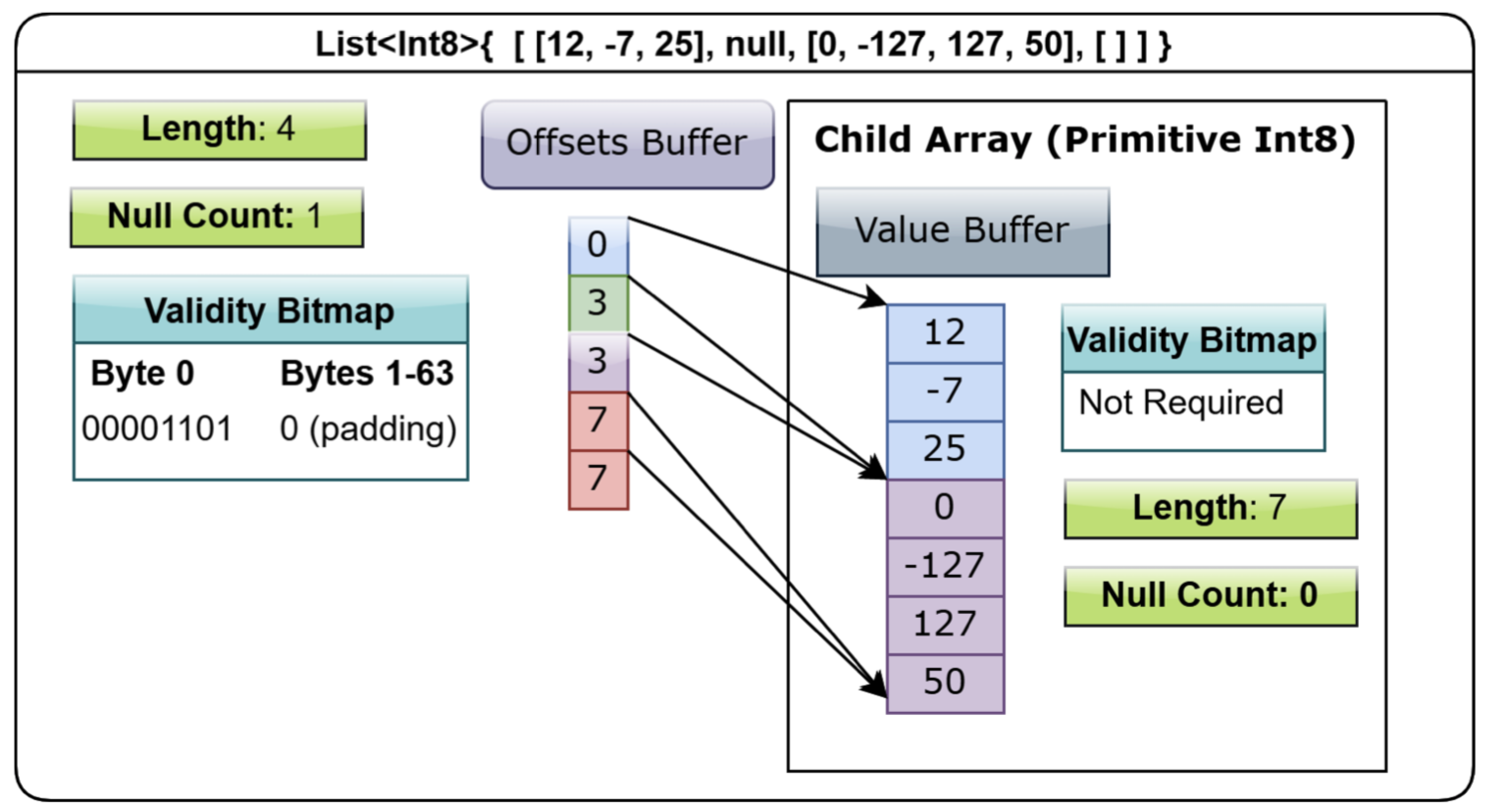
3.7 Struct type
A struct is also a nested type that can contain multiple fields, each of which is an array type. struct’s layout contains the bitmap buffer, followed by the field value buffer. Each field has its own layout, depending on the type of field. Here is an example of a struct with two fields: name and age, name is an array of type String and age is an array of type int32.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
// struct_array_type.go
func main() {
fields := []arrow.Field{
arrow.Field{Name: "name", Type: arrow.BinaryTypes.String},
arrow.Field{Name: "age", Type: arrow.PrimitiveTypes.Int32},
}
structType := arrow.StructOf(fields...)
sb := array.NewStructBuilder(memory.DefaultAllocator, structType)
defer sb.Release()
names := []string{"Alice", "Bob", "Charlie"}
ages := []int32{25, 30, 35}
valid := []bool{true, true, true}
nameBuilder := sb.FieldBuilder(0).(*array.StringBuilder)
ageBuilder := sb.FieldBuilder(1).(*array.Int32Builder)
sb.Reserve(len(names))
nameBuilder.Resize(len(names))
ageBuilder.Resize(len(names))
sb.AppendValues(valid)
nameBuilder.AppendValues(names, valid)
ageBuilder.AppendValues(ages, valid)
arr := sb.NewArray().(*array.Struct)
defer arr.Release()
bitmaps := arr.NullBitmapBytes()
fmt.Println(hex.Dump(bitmaps))
bufs := arr.Data().Buffers()
for _, buf := range bufs {
fmt.Println(hex.Dump(buf.Buf()))
}
nameArr := arr.Field(0).(*array.String)
bufs = nameArr.Data().Buffers()
for _, buf := range bufs {
fmt.Println(hex.Dump(buf.Buf()))
}
ageArr := arr.Field(1).(*array.Int32)
bufs = ageArr.Data().Buffers()
for _, buf := range bufs {
fmt.Println(hex.Dump(buf.Buf()))
}
fmt.Println(arr)
}
|
Executing the above code, we will get the following output.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
$go run struct_array_type.go
00000000 07 00 00 00 |....|
00000000 07 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 07 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 00 00 00 00 05 00 00 00 08 00 00 00 0f 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 41 6c 69 63 65 42 6f 62 43 68 61 72 6c 69 65 00 |AliceBobCharlie.|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 07 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 19 00 00 00 1e 00 00 00 23 00 00 00 00 00 00 00 |........#.......|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
{["Alice" "Bob" "Charlie"] [25 30 35]}
|
The first big chunk of data is the bitmap buffer of the struct, the next three big chunks of data are the bitmap, offset and data buffer of the name field, and the last two big chunks of data are the bitmap and data buffer of the age field.
Here is a diagram of a struct type layout from that book to help you understand the structure.
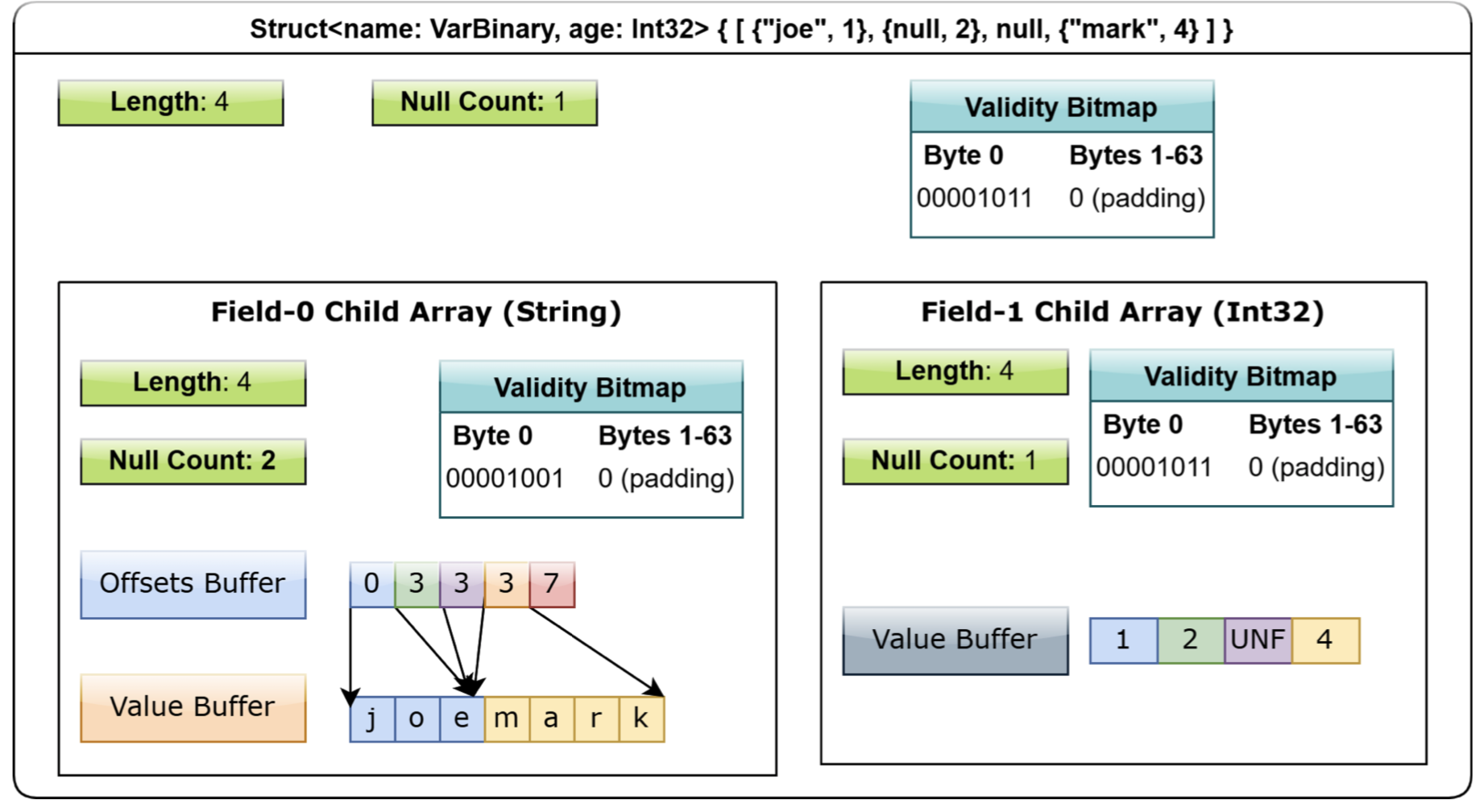
3.8 Union type
Anyone who has studied C knows about union, which is simply a bunch of types sharing a block of memory.
Arrow’s union array type is a sequence of union types placed in each slot, and there are two other types of union array type, a dense union type and a sparse union type; we can see the difference between them by the following two examples The union array type is a little more difficult to understand than the primitive type and the nested types like list and struct.
Let’s start by looking at the dense union array type.
3.8.1 dense union array type
Let’s look at a union array like this: [{i32=5} {f32=1.2} {f32=<nil>} {f32=3.4} {i32=6}]. We see that this instance of the union array has two union types: float32 and int32. float32 has three values: 1.2, null and 3.4, and int32 has two values: 5 and 6. We write go code to build this union array.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
// dense_union_array_type.go
var (
F32 arrow.UnionTypeCode = 7
I32 arrow.UnionTypeCode = 13
)
func main() {
childFloat32Bldr := array.NewFloat32Builder(memory.DefaultAllocator)
childInt32Bldr := array.NewInt32Builder(memory.DefaultAllocator)
defer func() {
childFloat32Bldr.Release()
childInt32Bldr.Release()
}()
ub := array.NewDenseUnionBuilderWithBuilders(memory.DefaultAllocator,
arrow.DenseUnionOf([]arrow.Field{
{Name: "f32", Type: arrow.PrimitiveTypes.Float32, Nullable: true},
{Name: "i32", Type: arrow.PrimitiveTypes.Int32, Nullable: true},
}, []arrow.UnionTypeCode{F32, I32}),
[]array.Builder{childFloat32Bldr, childInt32Bldr})
defer ub.Release()
ub.Append(I32)
childInt32Bldr.Append(5)
ub.Append(F32)
childFloat32Bldr.Append(1.2)
ub.AppendNull()
ub.Append(F32)
childFloat32Bldr.Append(3.4)
ub.Append(I32)
childInt32Bldr.Append(6)
arr := ub.NewDenseUnionArray()
defer arr.Release()
// print type buffer
buf := arr.TypeCodes().Buf()
fmt.Println(hex.Dump(buf))
// print offsets
offsets := arr.RawValueOffsets()
fmt.Println(offsets)
fmt.Println()
// print buffer of child array
bufs := arr.Field(0).Data().Buffers()
for _, buf := range bufs {
fmt.Println(hex.Dump(buf.Buf()))
}
bufs = arr.Field(1).Data().Buffers()
for _, buf := range bufs {
fmt.Println(hex.Dump(buf.Buf()))
}
fmt.Println(arr)
}
|
We see that the construction of the union array is also very complex. As per the previous table, the layout of the dense union array type has two buffers for the metadata, the first being the typeIds and the second being the offset. there is no data buffer, the real data is stored in the layout of the child array. Let’s run the above example and see for ourselves.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
$go run dense_union_array_type.go
00000000 0d 07 07 07 0d 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
[0 0 1 2 1]
00000000 05 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 9a 99 99 3f 00 00 00 00 9a 99 59 40 00 00 00 00 |...?......Y@....|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 05 00 00 00 06 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
[{i32=5} {f32=1.2} {f32=<nil>} {f32=3.4} {i32=6}]
|
The first piece of data is the union typeid buffer, here our union array type has a total of two subtypes, which I have divided into the typeid given to them as float32(0×07) and int32(0x0d). union array type has a total of 5 slots (3 float32, 2 int32), the typeids buffer here uses one byte to represent the type of a slot, so there are 3 07s and 2 0d.
The following output [0 0 1 2 1] is an offset buffer, representing the offset of a value buffer of the same type (an offset value is a 4-byte int32). Take the int32 slot as an example, we have two int32 slots, the first and the fifth of the total union array type. But the int32 slots are stored together as int32 primitive array type, so the first slot of the union array type is the first slot of the int32 primitive array type, i.e. its offset in the int32 type is 0, and the The 5th slot of the union array type is the 2nd slot of the int32 primitive array type, i.e. its offset has an offset of 1 in the int32 type, which is why the first value of [0 0 1 2 1] is 0 and the last value is 1. By analogy, you can work out why the middle three values are 0 1 2.
The next four blocks of data are the buffer of the float32 array type and the buffer layout of the int32 array type. we can see the layout of the union array type more visually in the following diagram.
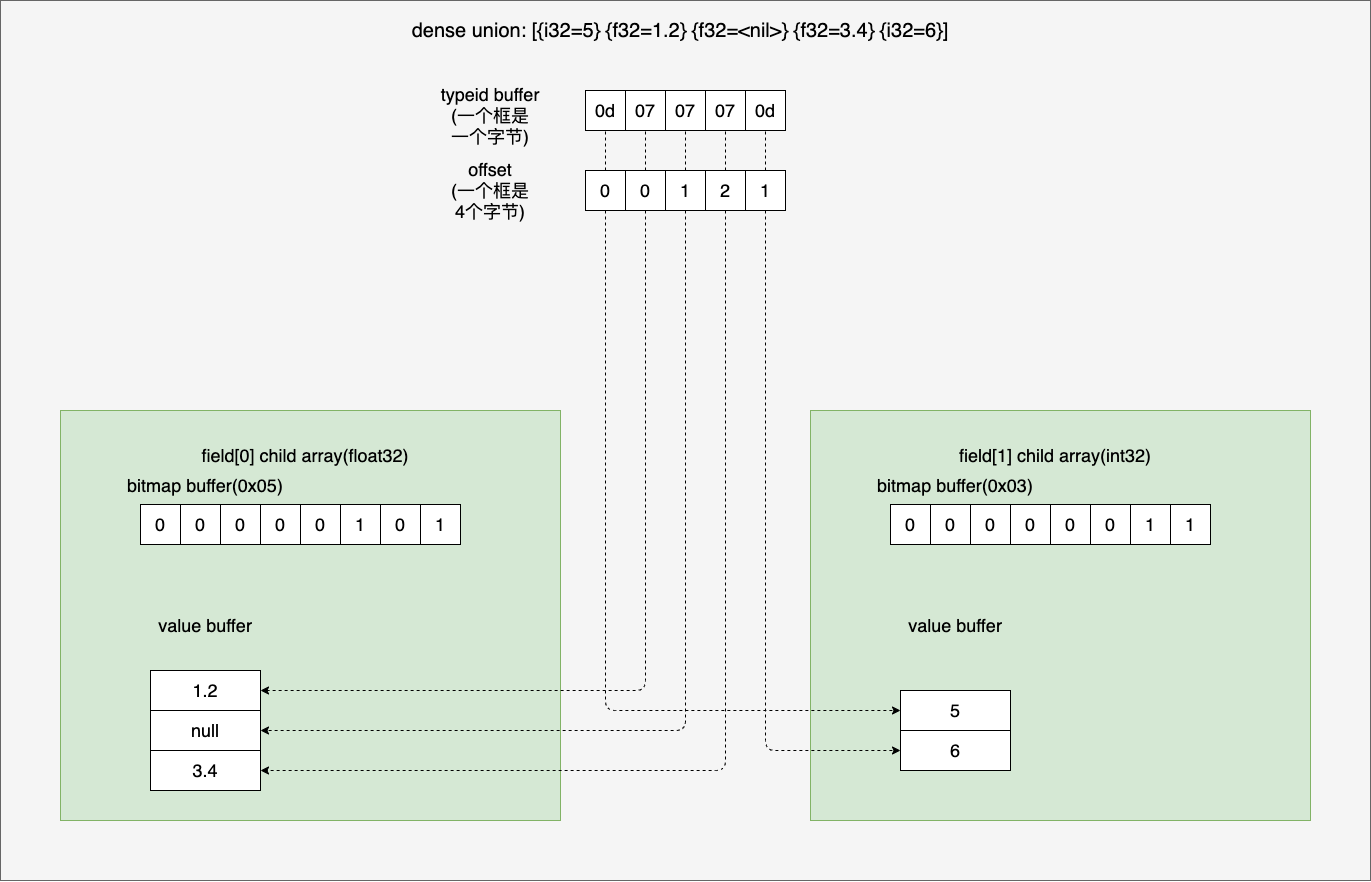
3.8.2 sparse union array type
Next, let’s take a look at the sparse union array type, using the union array: [{i32=5} {f32=1.2} {f32=<nil>} {f32=3.4} {i32=6}] as an example, and see what it looks like using the sparse union array type to represent its layout looks like. We start by constructing this union array type using go.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
// sparse_union_array_type.go
var (
F32 arrow.UnionTypeCode = 7
I32 arrow.UnionTypeCode = 13
)
func main() {
childFloat32Bldr := array.NewFloat32Builder(memory.DefaultAllocator)
childInt32Bldr := array.NewInt32Builder(memory.DefaultAllocator)
defer func() {
childFloat32Bldr.Release()
childInt32Bldr.Release()
}()
ub := array.NewSparseUnionBuilderWithBuilders(memory.DefaultAllocator,
arrow.SparseUnionOf([]arrow.Field{
{Name: "f32", Type: arrow.PrimitiveTypes.Float32, Nullable: true},
{Name: "i32", Type: arrow.PrimitiveTypes.Int32, Nullable: true},
}, []arrow.UnionTypeCode{F32, I32}),
[]array.Builder{childFloat32Bldr, childInt32Bldr})
defer ub.Release()
ub.Append(I32)
childInt32Bldr.Append(5)
childFloat32Bldr.AppendEmptyValue()
ub.Append(F32)
childFloat32Bldr.Append(1.2)
childInt32Bldr.AppendEmptyValue()
ub.AppendNull()
ub.Append(F32)
childFloat32Bldr.Append(3.4)
childInt32Bldr.AppendEmptyValue()
ub.Append(I32)
childInt32Bldr.Append(6)
childFloat32Bldr.AppendEmptyValue()
arr := ub.NewSparseUnionArray()
defer arr.Release()
// print type buffer
buf := arr.TypeCodes().Buf()
fmt.Println(hex.Dump(buf))
// print child
bufs := arr.Field(0).Data().Buffers()
for _, buf := range bufs {
fmt.Println(hex.Dump(buf.Buf()))
}
bufs = arr.Field(1).Data().Buffers()
for _, buf := range bufs {
fmt.Println(hex.Dump(buf.Buf()))
}
fmt.Println(arr)
}
|
In contrast to the dense union type, the sparse union type requires all child types to have the same length as the union type. This is why the above code appends an emtpy int32 after appending a float32. Here is the result of the above program.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
$go run sparse_union_array_type.go
00000000 0d 07 07 07 0d 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 1b 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 00 00 00 00 9a 99 99 3f 00 00 00 00 9a 99 59 40 |.......?......Y@|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 1f 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 05 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 06 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
[{i32=5} {f32=1.2} {f32=<nil>} {f32=3.4} {i32=6}]
|
Again, we can visualise the above results with a diagram:
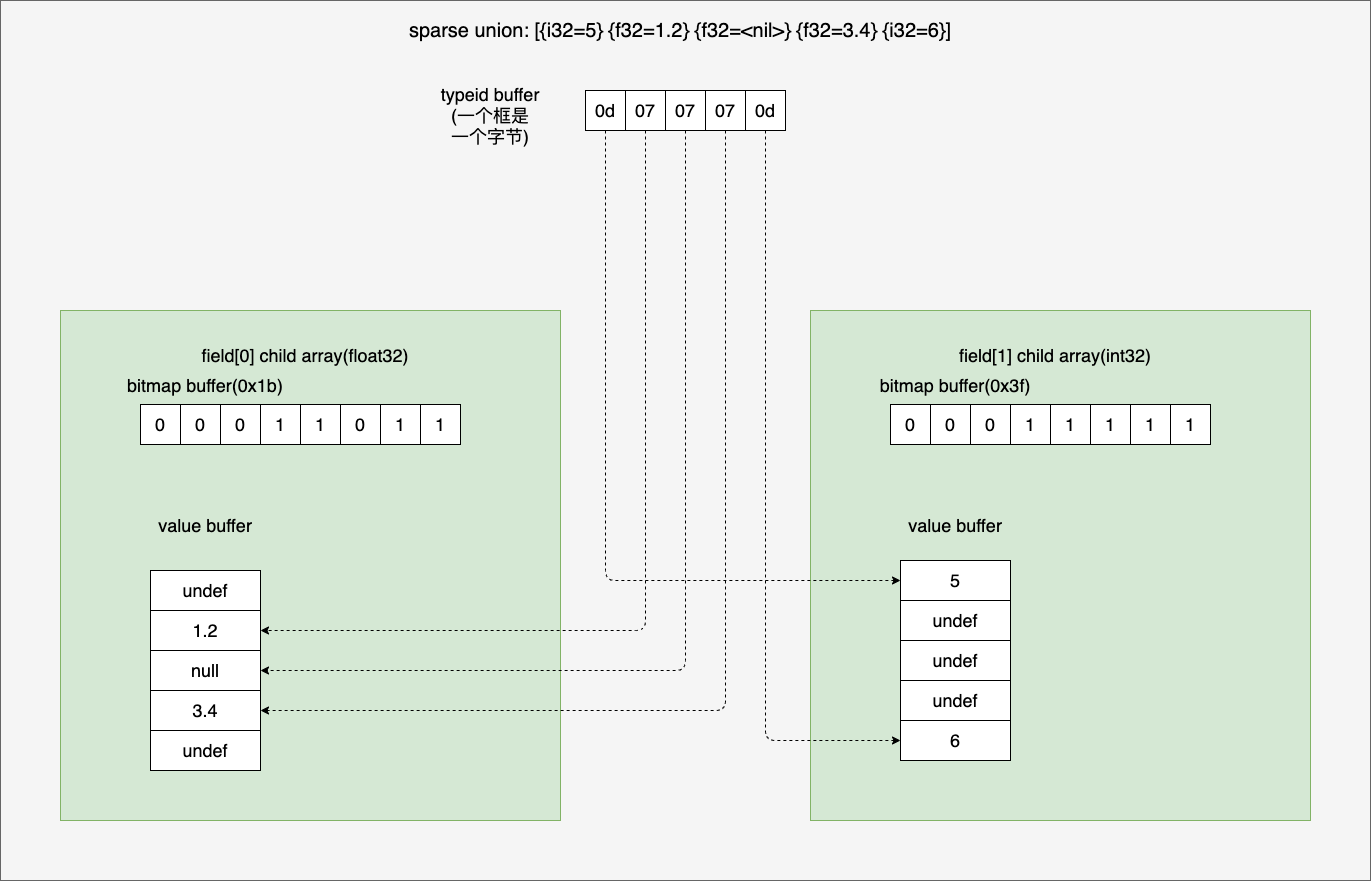
At this point we can briefly compare the dense and sparse unions. Obviously sparse actually takes up more memory space due to its special requirements.
So what kind of scenario is sparse union type used in? According to the book “In Memory Analytics With Apache Arrow”, sparse union is more likely to be used with vectorized expression evaluation.
3.9 Dictionary-encoded type
A final word about dictionary-encoded types. If we were to store a set of strings with duplicate values, e.g. [“foo”, “bar”, “foo”, “bar”, null, “baz”], using the variable-size binary type mentioned earlier, the same strings would not be stored in a single copy, but in separate strings.
To address this problem, Arrow provides an array type that uses dictionary-encode, in which duplicate strings are stored in one copy only. Let’s look at an example.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
// dictionary_encoded_array_type.go
func main() {
dictType := &arrow.DictionaryType{IndexType: &arrow.Int8Type{}, ValueType: &arrow.StringType{}}
bldr := array.NewDictionaryBuilder(memory.DefaultAllocator, dictType)
defer bldr.Release()
bldr.AppendValueFromString("foo")
bldr.AppendValueFromString("bar")
bldr.AppendValueFromString("foo")
bldr.AppendValueFromString("bar")
bldr.AppendNull()
bldr.AppendValueFromString("baz")
arr := bldr.NewDictionaryArray()
defer arr.Release()
bufs := arr.Data().Buffers()
for _, buf := range bufs {
fmt.Println(hex.Dump(buf.Buf()))
}
dict := arr.Dictionary()
// print value string in dict
bufs = dict.Data().Buffers()
for _, buf := range bufs {
if buf == nil {
continue
}
fmt.Println(hex.Dump(buf.Buf()))
}
fmt.Println(arr)
}
|
The results of the execution of the above procedure are as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
$go run dictionary_encoded_array_type.go
00000000 2f 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |/...............|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 00 01 00 01 00 02 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 00 00 00 00 03 00 00 00 06 00 00 00 09 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000000 66 6f 6f 62 61 72 62 61 7a 00 00 00 00 00 00 00 |foobarbaz.......|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
{ dictionary: ["foo" "bar" "baz"]
indices: [0 1 0 1 (null) 2] }
|
This large output can be better understood by comparing it with the diagram below.
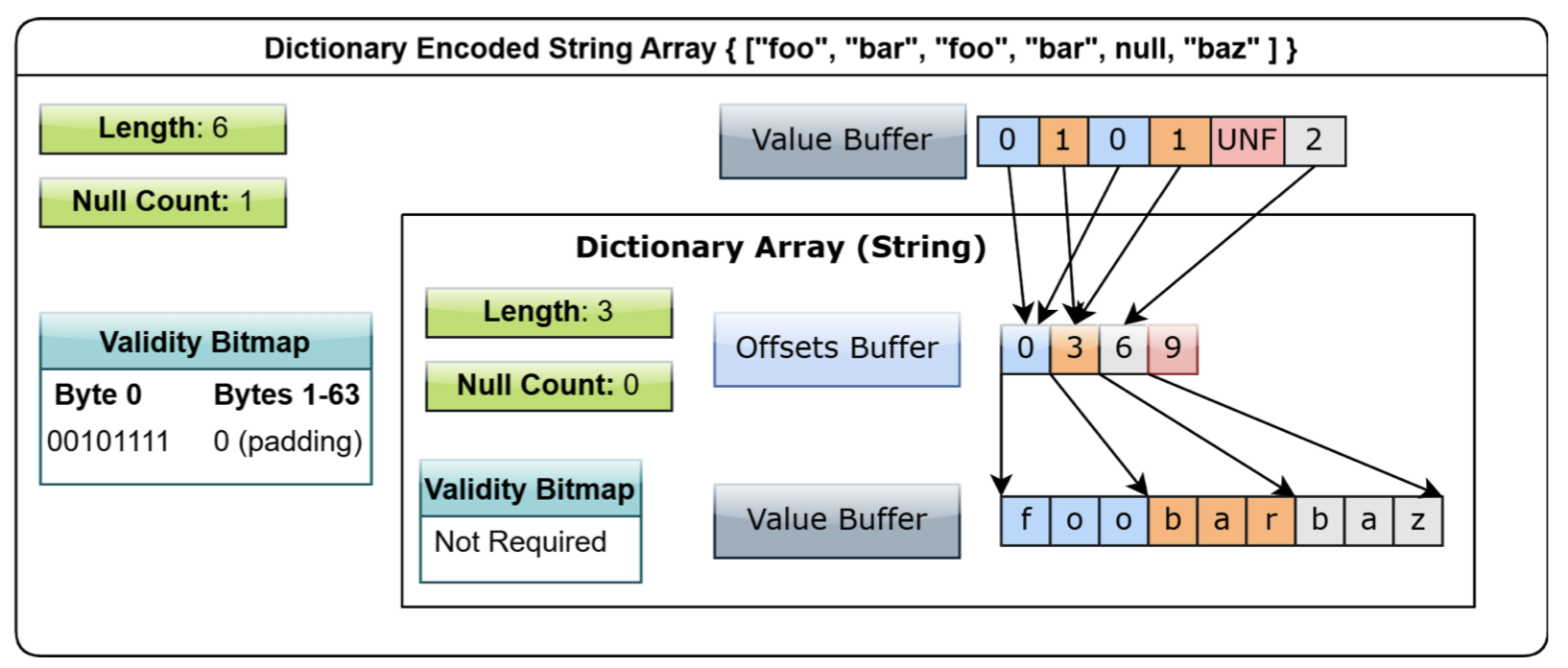
We can see that the dictionary array type is actually a dictionary encoded through a mapping of indices to the underlying array’s offset, which can greatly save memory space.
There are other types, such as Time32/Time64, Date32/Date64, etc., whose storage structure is similar to the above types, so you can read the specification and do your own coding practice to understand them.
The Arrow format specification has been committed to the semver specification since 1.0, i.e. the major.minor.fix versioning format. Incompatible changes will only be introduced when the version of major changes. The current version of format is 1.3, so we can treat it as backwards compatible.
5. Summary
This article introduces the Apache top-level project Arrow, a project that aims to create a unified format specification for each type in memory. Based on Arrow, big data systems can operate directly on Arrow data without the need for serialisation/deserialisation; Arrow also uses a columnar model, which is inherently suitable for data processing and analysis.
In this article, we have analysed the layout of the common array type of Arrow. Although they are both called types, the array type defined by arrow describes a “column”, such as the int32 type in primitive types. The length of the elements in the column is fixed: sizeof(int32), and the length of the column (array length) is also fixed. Only by understanding this level can we better understand arrow.
The code and layouts in this article apply to Arrow Columnar Format Version: 1.3.
The source code covered in this article is available for download here.
6. Ref
https://tonybai.com/2023/06/25/a-guide-of-using-apache-arrow-for-gopher-part1/