Python, as an interpreted language, is known for its clean and easy to understand code. We can assign values to names directly, without having to declare types. The Python interpreter determines name types and allocates and frees memory space at runtime, and this automatic memory management greatly reduces the burden on the programmer. For a high-level language like Python, developers can complete their work without concern for its internal garbage collection mechanism. Complementary to this, learning Python’s internal garbage collection mechanism and understanding its principles will enable developers to write better code and be more Pythonista.
Python memory management mechanisms
In Python, memory management involves a private heap (heap) that contains all Python objects and data structures. Management of this private heap is ensured by the internal Python memory manager, which has different components to handle various dynamic storage management aspects such as sharing, partitioning, preallocation, or caching.
At the lowest level, a raw memory allocator ensures that there is enough space in the private heap to store all Python-related data by interacting with the operating system’s memory manager. On top of the raw memory allocator, several object-specific allocators run on the same heap and implement different memory management policies based on the characteristics of each object type. For example, integer objects are managed differently within the heap than strings, tuples, or dictionaries because integers require different storage requirements and speed-versus-space tradeoffs. Thus, the Python memory manager assigns some work to object-specific allocators, but ensures that the latter operate within the confines of the private heap.
Python heap memory management is performed by the interpreter, and users have no control over it, even though they often manipulate object pointers to blocks of memory within the heap, and it is important to understand this.
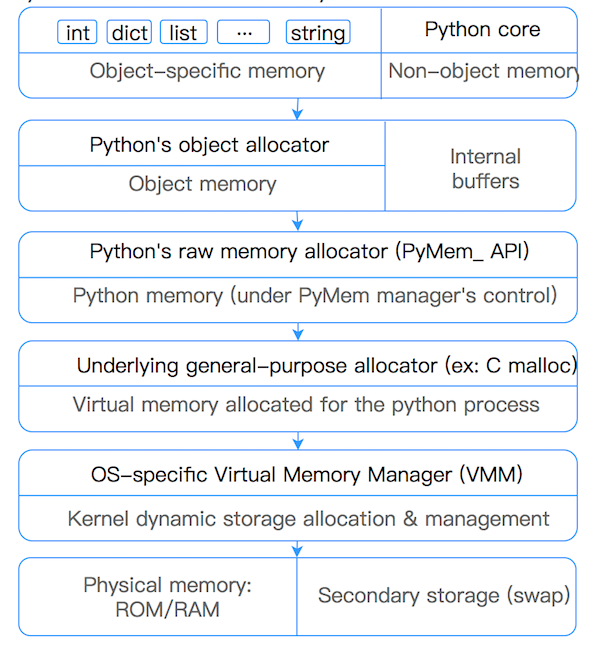
Python uses suballocation (memory pools) for small objects to avoid the performance drain of too many GCs for small objects (<=512bytes). For large objects, use the standard C allocator to allocate memory.
Python’s allocator for small objects is divided into three tiers from large to small: arena, pool, and block.
Block
Block is the smallest level, each block can only contain a fixed size Python Object. size from 8-512bytes, in steps of 8bytes, divided into 64 different types of blocks.
| Request in bytes | Size of allocated block | size class idx |
|---|---|---|
| 1-8 | 8 | 0 |
| 9-16 | 16 | 1 |
| 17-24 | 24 | 2 |
| 25-32 | 32 | 3 |
| 33-40 | 40 | 4 |
| 41-48 | 48 | 5 |
| … | … | … |
| 505-512 | 512 | 63 |
Pool
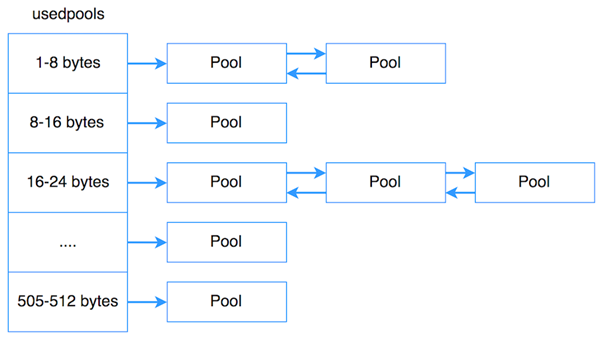
A Pool is a collection of blocks of the same size called a Pool, which is usually 4kb in size, consistent with the size of a virtual memory page. Restricting the size of blocks in a Pool to a fixed size has the following advantages: When an object is destroyed in a block in the current Pool, Pool memory management can put the newly generated object into that block.
|
|
Pools of the same size are linked by a bidirectional chain. sidx identifies the type of Block. arenaindex identifies the Arena to which the current Pool belongs. ref.conut identifies how many Blocks are used by the current Pool. freeblock: identifies a pointer to the blocks available in the current Pools. freeblock is actually a single-linked table implementation. When a block is empty, the block is inserted into the head of the freeblock chain.
Each Pool has three states.
- used: partially used, i.e. the Pool is not full and not empty
- full: full, i.e. all the blocks in the Pool have been allocated
- empty: empty, i.e. all blocks in the Pool are unallocated
usedpool In order to manage Pools very efficiently, Python uses an additional array, usedpool, to manage them. That is, as shown below, usedpool stores the header pointer to each Pool of a particular size in order, and Pools of the same size are linked in a bidirectional chain. When allocating new memory space to create a Pool of a particular size, simply use usedpools to find the header pointer and iterate through it. When no memory space is available, simply insert a new Pool at the head of the Pool’s bidirectional chain.
Arena
Pools and Blocks do not directly allocate memory (allocate), Pools and Blocks use the memory space already allocated from the arena side. arena: is a 256kb block of memory allocated on the heap, providing 64 Pools.
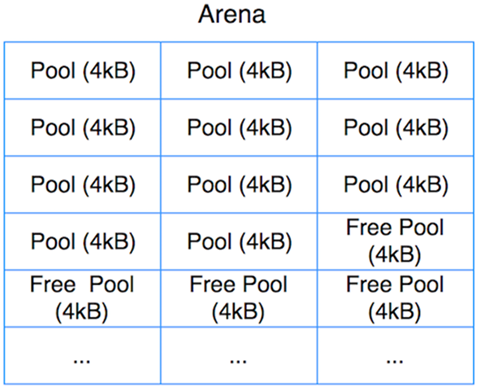
All arenas are also linked using a double-linked table (prevarena, nextarena fields). The nfreepools and ntotalpools store information about the currently available pools. freepools pointers point to the currently available pools. arena structure is simple, the responsibility is to allocate memory to pools on demand, and when an arena is empty, the memory of that arena is returned to the operating system.
Python’s garbage collection mechanism
Python uses a reference-counting mechanism as the primary strategy, supplemented by two mechanisms: mark-clear and generational collection.
reference counting
The default garbage collection mechanism used by the Python language is “Reference Counting”, an algorithm first proposed by George E. Collins in 1960 and still used by many programming languages today, 50 years later. The principle of reference counting is: each object maintains an ob_ref field, which is used to record the number of times the object is currently referenced, whenever a new reference points to the object, its reference count ob_ref plus 1, whenever the object’s reference fails count ob_ref minus 1, once the object’s reference count is 0, the object is immediately recycled, and the memory space occupied by the object will be released. Its disadvantage is that it requires extra space to maintain the reference count, which is a secondary problem, but the main problem is that it does not solve the object’s “circular reference”, so there are many languages such as Java that do not use this algorithm as a garbage collection mechanism.
Everything in Python is an object, which means that all the variables you use in Python are essentially class objects. In fact, the core of every object is a PyObject structure, which has an internal reference counter, ob_refcnt, that updates the value of ob_refcnt in real time as the program runs, to reflect the number of names that reference the current object. When the reference counter value of an object is 0, it means that the object has become garbage, then it will be recycled and the memory it uses will be freed immediately.
Cases that result in +1 reference count.
- object is created, e.g. a=23
- An object is referenced, e.g. b=a
- The object is passed as an argument to a function, e.g. func(a)
- The object is stored as an element in a container, e.g. list1=[a,a]
which results in a reference count of -1
- The object’s alias is destroyed explicitly, e.g. del a
- An object’s alias is given to a new object, e.g. a=24
- An object leaves its scope, e.g. a local variable in the func function when the f function finishes executing (global variables do not)
- The container in which the object is located is destroyed, or the object is removed from the container
We can get the current reference count of an object referenced by a name by using getrefcount() in the sys package. sys.getrefcount() itself will cause the reference count to be added by one.
Circular references
Another phenomenon of reference counting is circular references, equivalent to two objects a and b, where a references b, b references a, so that the reference count of a and b are 1 and will never be 0, which means that the two objects will never be recycled, which is a circular reference , a and b form a reference loop, the example is as follows :
In addition to the above two objects refer to each other, they can also refer to themselves:
Circular references cause variables to never count to 0, causing reference counting to fail to remove them.
The reference counting method has its obvious advantages, such as efficiency, simple implementation logic, real-time, once an object’s reference count goes to zero, the memory is released directly. There is no need to wait for a specific moment like other mechanisms. By randomly assigning garbage collection to the running phase, the time to deal with reclaiming memory is spread over the usual time, and the normal program runs more smoothly. Reference counting also has some disadvantages.
- Simple logic, but somewhat cumbersome to implement. Each object needs to be allocated a separate space to count the reference count, which in effect increases the space burden and requires maintenance of the reference count, which is prone to errors during maintenance.
- In some scenarios, it may be slower. Normally garbage collection runs smoothly, but when a large object needs to be freed, such as a dictionary, it needs to be called in a nested loop for all objects referenced, which may take longer.
- Circular references. This is the Achilles heel of reference counting, which is insurmountable and must be supplemented with other garbage collection algorithms.
That is, Python’s garbage collection mechanism is designed in large part to deal with the possibility of circular references, and is complementary to reference counting.
Mark and Sweep
Python uses the Mark and Sweep algorithm to solve the problem of circular references that can be generated by container objects. (Note that only container objects generate circular references, such as lists, dictionaries, objects of user-defined classes, tuples, and so on. Simple types like numbers, strings, and so on do not have circular references. (As an optimization strategy, tuples containing only simple types are also not considered for the token removal algorithm.)
As its name suggests, the algorithm is divided into two steps when performing garbage collection, which are
- Marking phase, which iterates through all objects and marks the object as reachable if it is reachable, i.e., if there are still objects that refer to it.
- Clear phase, which iterates through the objects again, and if an object is not marked as reachable, then it is recycled.
Objects are linked together by references (pointers) to form a directed graph, with objects forming the nodes and reference relationships forming the edges of the directed graph. From the root object, the objects are traversed along the directed edges, and the reachable objects are marked as active objects, while the unreachable objects are the inactive objects to be removed. The so-called root object is some global variables, call stacks, and registers, which cannot be deleted.
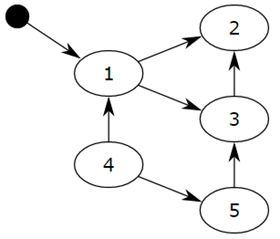
We consider the small black circle as the root object, from the small black circle, object 1 is reachable, then it will be marked, objects 2 and 3 are indirectly reachable will also be marked, while 4 and 5 are not reachable, then 1, 2 and 3 are active objects, 4 and 5 are inactive objects will be recycled by GC.
As shown in the figure below, in order to keep track of the container objects, each container object needs to maintain two additional pointers, which are used to form a double-ended chain table of container objects, with the pointers pointing to the front and back container objects for insertion and deletion operations. objects to be scanned, and another chain table that holds temporarily unreachable objects. In the diagram, these two tables are named “Object to Scan” and “Unreachable” respectively. The example in the figure is such a situation: link1,link2,link3 form a reference ring, while link1 is also referenced by a variable A (in fact, here is better called the name A). link4 self-reference, also forms a reference ring. We can also see from the figure, each node in addition to a record of the current reference count variable ref_count and a gc_ref variable, the gc_ref is a copy of ref_count, so the initial value of the size of ref_count.
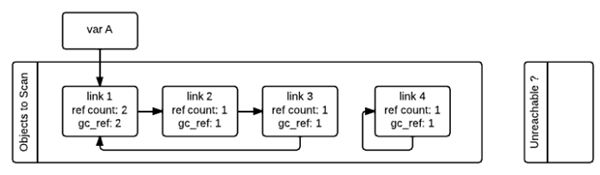
When gc starts, it will iterate through the “Object to Scan” chain of container objects one by one, and the gc_ref of all objects referenced by the current object will be subtracted by one. (When scanning to link1, as link1 references link2, so the gc_ref of link2 will be reduced by one, and then scanning link2, as link2 references link3, so the gc_ref of link3 will be reduced by one …..) After examining all the objects in the “Objects to Scan” chain like this, the ref_count and gc_ref of the objects in the two chains are shown below. This step is equivalent to remove the influence of circular references on the reference count.
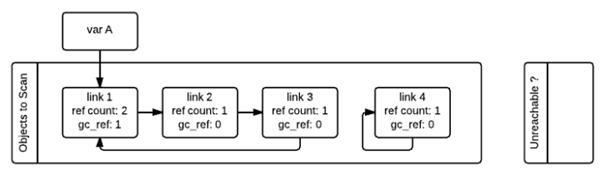
Then, gc will scan all the container objects again, if the object’s gc_ref value is 0, then the object is marked as GC_TENTATIVELY_UNREACHABLE and moved to the “Unreachable” chain. This is the case for link3 and link4 in the figure below.
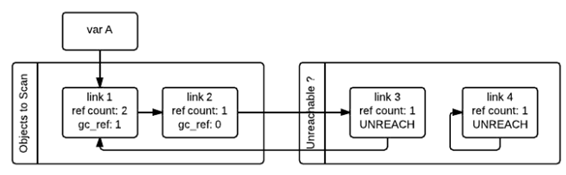
If the object’s gc_ref is not 0, then the object will be marked as GC_REACHABLE, and when gc finds a node that is reachable, then it will recursively mark all nodes reachable from that node as GC_REACHABLE, which is the case for link2 and link3 in the figure below.
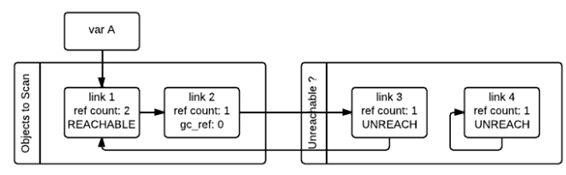
In addition to marking all reachable nodes as GC_REACHABLE, if the node is currently in the “Unreachable” chain, you need to move it back to the “Object to Scan” chain, the figure below shows the situation after link3 is moved back.
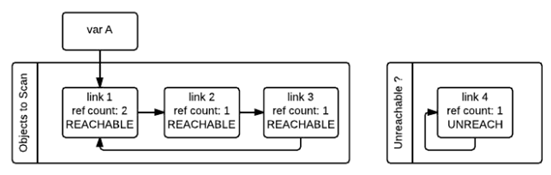
After all the objects in the second traversal are traversed, the objects in the “Unreachable” chain are the objects that really need to be released. As shown above, link4 is now in the Unreachable chain, and gc releases it immediately.
The garbage collection phase described above suspends the entire application and waits for marker removal to finish before resuming operation.
The advantage of marker removal is that it solves the circular reference problem and has no additional overhead during the execution of the algorithm. The disadvantage is that the normal program will be blocked when executing marker clearing. Another disadvantage is that the marker clearing algorithm generates some small memory fragments in the program’s heap space after many executions.
Generational garbage collector
The generational recycling technique is a garbage collection mechanism developed in the early 1980s and is the core algorithm of Java garbage collection. Generational recycling is based on the statistical fact that for programs, there exists a certain percentage of memory blocks that have a relatively short lifetime; while the remaining memory blocks will have a longer lifetime, even from the beginning of the program until the end of the program. The percentage of objects with a shorter lifetime is usually between 80% and 90%. Therefore, it is simply assumed that: the longer an object exists, the more likely it is not garbage and the less it should be collected. This effectively reduces the number of objects traversed when performing the mark-and-clean algorithm, thus increasing the speed of garbage collection, a space-for-time approach strategy.
- Python divides all objects into three generations of 0, 1, and 2.
- All new objects are generation 0 objects.
- When a generation of objects has undergone garbage collection and is still alive, it is classified as a next-generation object.
So, by what criteria are objects classified? Is it enough to randomly divide an object into a certain generation? The answer is no. In fact, there is a lot to learn about object generation, and a good classification standard can significantly improve the efficiency of garbage collection.
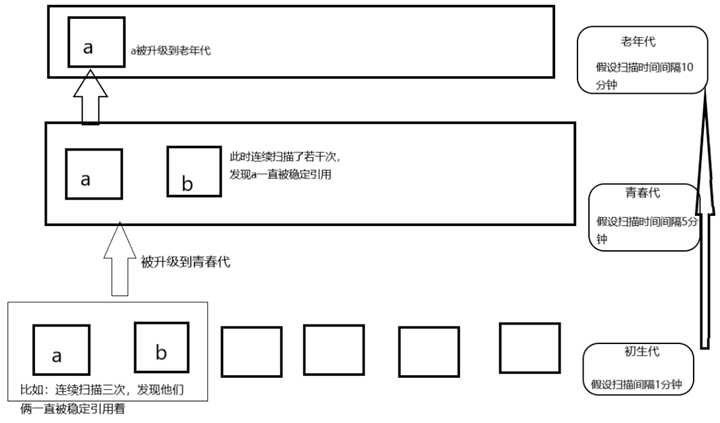
Python internally divides objects into 3 generations, each maintained by a gc_generation structure (defined in Include/internal/mem.h), based on how long the object has been alive.
where.
- head , the head of the collectible object chain table through which the objects in the generation are maintained
- threshold, the Python garbage collection operation will scan the generation only if count exceeds this threshold
- count, a counter that varies from generation to generation
The Python virtual machine runtime state is represented by the pyruntimestate structure in Include/internal/pystate.h, which has an internal _gc_runtime_state ( Include/internal/mem.h ) structure that holds GC state information, including three object generations These 3 generations are used in the GC module. These 3 generations are initialized in the _PyGC_Initialize function of the GC module ( Modules/gcmodule.c ).
For the sake of discussion, we will call these 3 generations: the first generation, the middle generation and the old generation. When these 3 generations are initialized, the corresponding gc_generation arrays will look like this
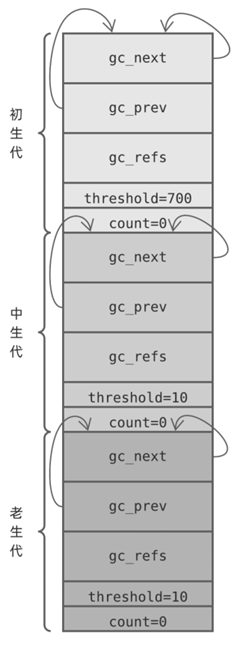
Each gc_generation structure points to itself at the head node of the chain, in other words each collectible object chain starts out empty, the counter field count is initialized to 0, and the threshold field has its own policy. How are these policies understood?
- When Python calls PyObject_GC_Alloc to allocate memory for an object to be tracked, the function adds 1 to the primitive count counter, and the object is then added to the primitive object chain, and when Python calls PyObject_GC_Del to free memory for garbage objects, the function adds 1 to the primitive count counter, PyObject_GC_Alloc will call collect_generations to perform a garbage collection (GC) if the threshold (700) is exceeded after self-incrementing the count.
- The collect_generations function starts from the oldest generation and iterates through each generation one by one to find the oldest generation that needs to perform a recycling operation (,count>threshold ). The collect_with_callback function is then called to start recycling that generation, and that function eventually calls the collect function.
- When the collect function processes a generation, it first resets the count of the generations younger than it to 0, then removes their object chains, stitches them together with its own, performs a GC algorithm, and finally adds 1 to the counter of the next generation.
Thus.
- Python performs a GC operation for every 701 new objects that need to be GC’d in the system
- The number of generations to be processed for each GC operation may be different, determined by both count and threshold
- If a generation needs to be GC’d (count>hreshold), all the young generations before it are GC’d at the same time
- For multiple generations, Python stitches their object chains together and processes them all at once
- After the GC is executed, count is cleared to zero, and the count of the next generation is added by 1
Here’s a simple example: the first generation triggers a GC operation, and Python executes the collect_generations function. It finds out that the oldest generation to reach the threshold is the middle generation, so it calls collection_with_callback(1), where 1 is the subscript of the middle generation in the array.
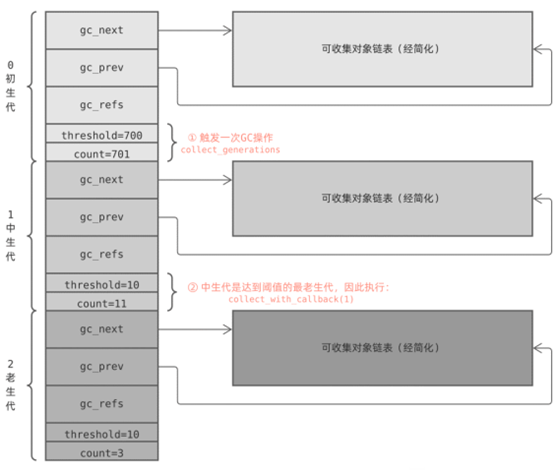
collection_with_callback(1) ends up calling collect(1), which first adds one to the counter of the next generation; then resets the counters of this generation and all previous young generations to zero; and finally calls gc_list_merge to merge the chain of recyclable objects together.
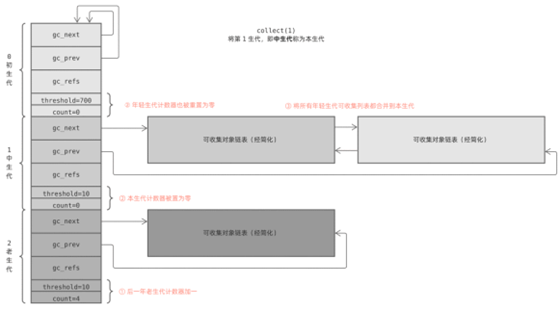
Finally, the collect function performs a marker removal algorithm to garbage collect the merged chain table.
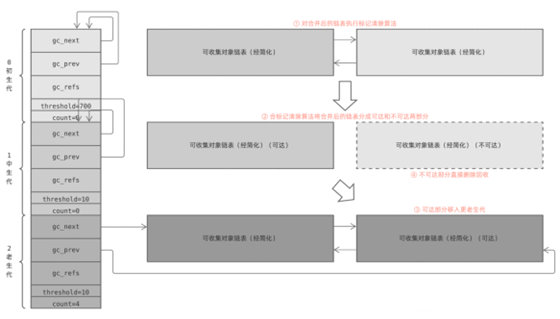
This is the whole secret of the generational recovery mechanism, which seems complicated, but with a little summary you can get a few straightforward strategies.
- Every 701 new objects that need GC, trigger a new generation GC
- Every 11 new-generation GCs, trigger a mid-generation GC
- Trigger an old-generation GC for every 11 mid-generation GCs (old-generation GCs are also affected by other policies and are less frequent)
- Before executing a generation GC, the young generation object chain is also moved to that generation and GC’d together
- After an object is created, it will be gradually moved to the old generation over time, and the recovery frequency is gradually reduced
The gc module in Python
The gc module is our interface for memory management in Python. Generally Python programmers don’t have to care about their program’s memory management, but there are times, such as when they find a memory leak in their program, that they may need to use the gc module’s interface to troubleshoot the problem.
Some Python systems will turn off automatic garbage collection, and the program will judge the timing of the collection itself. It is said that instagram’s system does this, and the overall running efficiency is increased by 10%.
Commonly used functions.
- set_debug(flags) : set gc’s debug log, usually set to gc.DEBUG_LEAK to see the memory leak objects.
- collect([generation]) : Perform garbage collection. It will collect those objects that have circular references. This function can pass parameters, 0 means only the garbage object of generation 0, 1 means collect the object of generation 0 and generation 1, 2 means collect the object of generation 0, 1 and 2. If no parameters are passed, then 2 is used as the default parameter.
- get_threshold() : Get the threshold value for the gc module to perform garbage collection. The return is a tuple, the 0th is the threshold for generation zero, the 1st is the threshold for generation 1, and the 2nd is the threshold for generation 2.
- set_threshold(threshold0[, threshold1[, threshold2]) : Set the threshold for performing garbage collection.
- get_count() : Get the current counter for automatically executing garbage collection. Returns a tuple. The 0th one is the number of garbage objects of generation zero, the 1st one is the number of times the chain table of generation zero is traversed, and the 2nd one is the number of times the chain table of generation 1 is traversed.