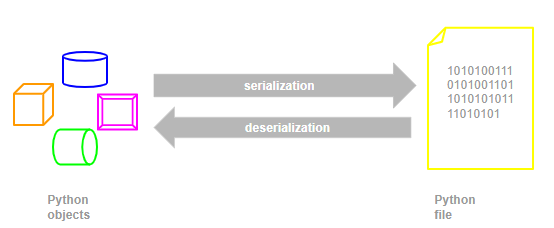
Python has a serialization process called pickle, which enables interconversion between arbitrary objects and text, and between arbitrary objects and binary. In other words, pickle enables the storage and recovery of Python objects.
- Serialization (picking): The process of turning a variable from memory into something that can be stored or transferred is called serialization, and after serialization, you can write the serialized object to disk or transfer it to another device
- deserialization (unpickling): accordingly, the process of re-reading the contents of a variable from a serialized object into memory is called deserialization
In machine learning, we often need to store the trained model so that the model can be read out directly when making decisions without retraining the model, which saves a lot of time. pickle module provided by Python solves this problem very well by serializing objects and saving them to disk and reading them out when needed, and any object can be executed Serialization operations.
There are two modules in Python 2 that can serialize objects, pickle and cPickle. cPickle is implemented in C, and pickle is implemented in pure Python, compared to cPickle, which is more efficient in reading and writing. When using, generally try to import cPickle first, if it fails, then import the pickle module.
Python 3 no longer needs to import like this.
A common pattern in Python 2.x is to have one version of a module implemented in pure Python, with an optional accelerated version implemented as a C extension; for example, pickle and cPickle. This places the burden of importing the accelerated version and falling back on the pure Python version on each user of these modules. In Python 3.0, the accelerated versions are considered implementation details of the pure Python versions. Users should always import the standard version, which attempts to import the accelerated version and falls back to the pure Python version. The pickle / cPickle pair received this treatment. The profile module is on the list for 3.1. The StringIO module has been turned into a class in the io module.
https://docs.python.org/3.1/whatsnew/3.0.html#library-changes
The pickle module provides the following four functions for our use.
- dumps(): serializes an object in Python into a binary object and returns
- loads(): reads the data of a given binary object and converts it to a Python object
- dump(): serializes an object in Python into a binary object and writes it to a file
- load(): reads the specified serialized data file and returns the object
The above four functions can be divided into two categories, with dumps and loads implementing memory-based Python object-to-binary interchange, and dump and load implementing file-based Python object-to-binary interchange.
The usage is similar to json serialization and deserialization, but there are some differences.
- JSON can only be stored in text form, Pickle can be stored as binary
- JSON is human readable, Pickle is not readable
- JSON is widely used in areas other than Python, Pickle is unique to Python
- JSON can only dump some python built-in objects, Pickle can store almost all objects
Instructions for using pickle
The pickle module provides two constants
| Constant | Description |
|---|---|
| pickle.HIGHEST_PROTOCOL | This is an integer value that indicates the highest protocol version available. It can be passed to the dump() and dumps() functions as an argument to the protocol version |
| DEFAULT_PROTOCOL | This is an integer value indicating the default protocol used for pickling, which may be less than the value of the highest protocol |
The pickle module provides the following methods.
- dump(obj, file, protocol=None, *, fix_imports=True, buffer_callback=None)
- dumps(obj, protocol=None, *, fix_imports=True, buffer_callback=None)
- load(file, *, fix_imports=True, encoding=“ASCII”, errors=“strict”, buffers=None)
- loads(data, /, *, fix_imports=True, encoding=“ASCII”, errors=“strict”, buffers=None)
Where protocol optional parameters.
- Protocol version 0 is the original “human-readable” protocol and is backwards compatible with earlier versions of Python.(Raw plain text storage)
- Protocol version 1 is an old binary format which is also compatible with earlier versions of Python.(Old Binary Storage)
- Protocol version 2 was introduced in Python 2.3. It provides much more efficient pickling of new-style classes. Refer to PEP 307 for information about improvements brought by protocol 2.(New version of binary storage, more efficient, new in Python 2.3)
- Protocol version 3 was added in Python 3.0. It has explicit support for bytes objects and cannot be unpickled by Python 2.x. This was the default protocol in Python 3.0–3.7.(Introduced in Python 3, default in Python 3.0-3.7)
- Protocol version 4 was added in Python 3.4. It adds support for very large objects, pickling more kinds of objects, and some data format optimizations. It is the default protocol starting with Python 3.8. Refer to PEP 3154 for information about improvements brought by protocol 4.(Support for very large objects)
- Protocol version 5 was added in Python 3.8. It adds support for out-of-band data and speedup for in-band data. Refer to PEP 574 for information about improvements brought by protocol 5.
If -1 is passed for this parameter, the highest version is used.
Example code.
|
|
Whether the file is opened in binary or not doesn’t seem to matter much, but it’s better to do what it says just to be safe.
pickleDB
Introduction says pickleDB is a lightweight and simple key-value store. It is based on Python’s simplejson module, inspired by redis. It is not clear how it is related to pickle?
Example of pickleDB.
Can pickleDB be used in conjunction with pickle? Test code.
|
|
The following error is reported.
|
|
It seems that pickledb does not support mixing with pickle. Or am I using it in the wrong way?
shelve
shelve is a simple data storage solution, similar to a key-value database, that can easily hold Python objects, and is internally serialized through the pickle protocol. shelve has only one open() function, which is used to open the specified file (a persistent dictionary) and then returns a shelf object. A shelf is a persistent, dictionary-like object. Its values can be any data that can be handled by any basic Python-object-pickle module. This includes most class instances, recursive data types, and objects containing many shared subobjects. keys is still a normal string.
open(filename, flag=‘c’, protocol=None, writeback=False)
- The flag parameter indicates the format of the open data store file.
- ‘r’ opens an existing datastore file in read-only mode
- ‘w’ opens an existing datastore file in read-write mode
- ‘c’ opens a datastore file in read-write mode, or creates it if it does not exist
- ’n’ always creates a new, empty datastore file and opens it in read-write mode
- the protocol parameter indicates the version of the protocol used to serialize the data, the default is pickle v3.
- The writeback parameter indicates whether writeback is enabled.
Usage examples.
|
|