When we want to store data persistently, using relational databases is often the safest choice, not only because of the richness and stability of today’s relational databases, but also because the support for relational databases in different communities is very complete. In this article, we will analyze an important concept in relational databases - Foreign Key.
In a relational database, a foreign key, also known as a relational key, is a set of columns that provide a connection between relational tables in a relational database. In general, we use the primary key in the relational table as a foreign key in other tables so that we can satisfy the constraints on foreign keys in relational databases.
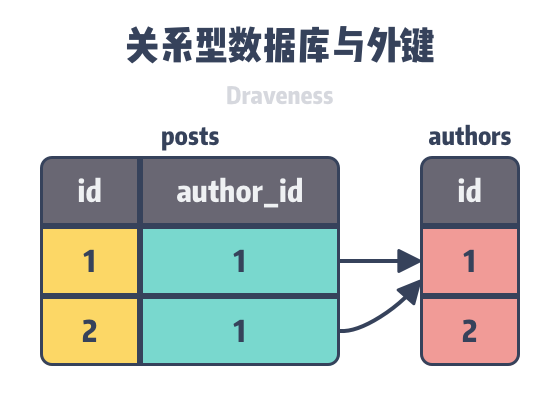
A foreign key is more than just an integer in a database table; it provides additional assurance of consistency. Because the database is often the Source of Truth for the entire system, it is important to ensure that the data is consistent and correct. Relational databases provide foreign keys, triggers, and other features to ensure consistency, but they are rarely used in today’s production environment.
Referential Integrity (Referential Integrity) is a property of the data, if the data has the property, then all references in the data are legitimate, in the context of relational databases, this means that the relational database reference to a value in another table must exist.
The above SQL statement can add a foreign key constraint to a relational table. The execution of this SQL statement presupposes the existence of the author_id field in the posts table. From the CONSTRAINT keyword in the SQL statement, we can also assume that the foreign key is not a data type, but a constraint between different relational tables.
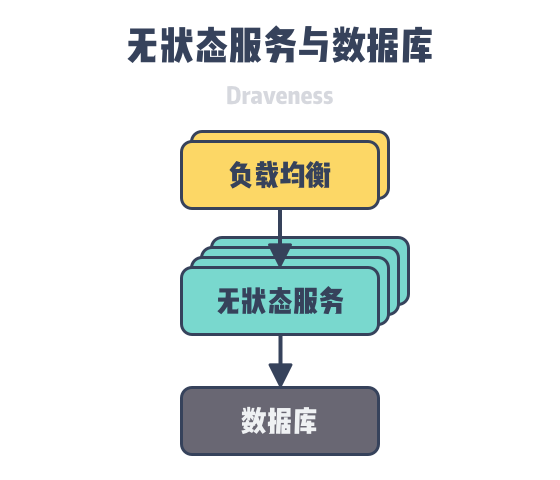
The reason for not using foreign keys is really simple. Relational databases such as MySQL and PostgreSQL are difficult to scale horizontally, but stateless services can often be scaled easily. Since features such as foreign keys require the database to perform additional work, and these operations take up computational resources of the database, we can migrate most of the requirements to stateless services to reduce the workload of the database.
Depending on the behavior when updating and deleting, we can classify foreign keys into RESTRICT, CASCADE and SET NULL, when we add foreign keys to When we add a foreign key constraint to a field in a relational table, we need to specify the type of the foreign key, the most common ones are RESTRICT and CASCADE, where RESTRICT is the default type of foreign key.
- Using
RESTRICTwill perform a consistency check on the existence of the record corresponding to the foreign key when it is updated or deleted. - Using
CASCADEwill trigger a cascade update or delete operation when a record is updated or deleted.
Note:
NO ACTIONandRESTRICTin MySQL have the same semantics.
Next we will detail how relational databases handle the two different types of foreign keys mentioned above, and how we should emulate these functions in our applications.
Consistency check
When we use the default foreign key type RESTRICT, the legitimacy of the reference is checked when a record is created, modified or deleted. To trigger the foreign key consistency check in a database like MySQL, suppose our database contains two tables posts(id, author_id, content) and authors(id, name), both of which trigger the database foreign key check when performing the following actions.
- Checking whether
author_idexists in theauthorstable when inserting data into thepoststable. - When modifying data in the
poststable, check ifauthor_idexists in theauthorstable. - When deleting data in the
authorstable, check if a foreign key referencing the current record exists inposts.
As a system dedicated to managing data, the database is able to guarantee integrity better than application services, and all of the above operations are extra work that comes with introducing foreign keys, but it is a necessary price for the database to guarantee data integrity. These analyses are theoretical and qualitative, but we can simply quantify the impact of introducing foreign keys on performance.
Here we create authors, posts and foreign_key_posts tables in the database as follows, where the columns in posts and foreign_key_posts are identical, except that the foreign_key_posts table adds a foreign key constraint of type RESTRICT to the author_id field.
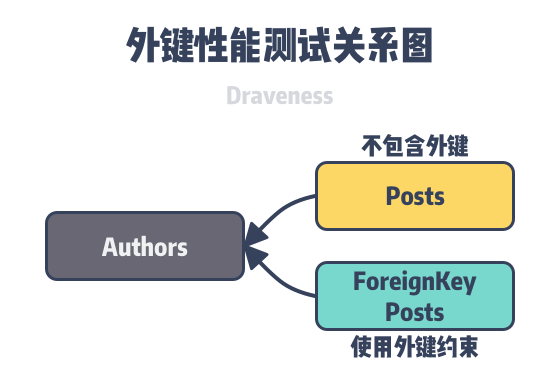
We start by inserting a record in the authors table, and then inserting multiple new data columns referencing that record in posts and foreign_key_posts respectively, the former without checking the legitimacy of the foreign key, and the latter with additional checks. You can find the Go language code used by the author to test the extra overhead of foreign keys at here, and after several benchmarks, we can get the results shown below.
|
|
The authors performed four benchmark tests with foreign keys, and although the results of the four tests were not particularly stable, the use case with foreign keys was significantly weaker than the use case without foreign keys in each test, with the additional overhead from foreign keys being ~2.47%, ~0.02%, ~10.41%, and ~11.52%, respectively. The benchmark here is a relatively simple quantitative analysis, but we can see the general trend from the results - integrity checking of foreign keys does introduce additional performance overhead that needs to be carefully considered in highly concurrent services.
To emulate the functionality of database foreign keys in an application is actually relatively easy, we just need to follow a few guidelines.
- Whenever inserting data into a table or modifying data in a table, an additional
SELECTstatement should be executed to ensure that the data it references exists in the database. - An additional
SELECTstatement needs to be executed before deleting data to check if the reference to the current record exists.
Note that in order to ensure consistency, we need to execute the above query and modify statements in a transaction in order to fully simulate the function of foreign keys; when we insert or modify data into the posts table, the processing required is relatively simple, we only need to execute a limited number of SELECT statements and perform the corresponding operations according to the pattern shown below.
But if we want to delete the data in the authors table, we need to query all the tables that reference the authors data; if there are 10 tables that all have foreign keys pointing to the authors table, we need to query the 10 tables for the existence of corresponding records, which is a relatively cumbersome process, but it is a necessary price to pay to achieve integrity, but this simulated foreign key method is actually far more resource-intensive than using foreign keys; it requires not only querying the associated data, but also sending more packets over the network.
Cascading operations
When we create a foreign key constraint in a relational database, a cascade operation is triggered when the client updates or deletes data if the CASCADE behavior is specified for updating or deleting records using the SQL statement shown below.
- When a client updates the primary key of a record in the
authorstable, the database updates all foreign keys in thepoststable that reference that record at the same time. - When a client deletes a record in the
authorstable, the database deletes all records associated with theauthorstable.
However, whether performing update or delete operations, the database can guarantee the consistency and legitimacy of references across relational tables without referencing to non-existent records. As with the RESTRICT behavior, all foreign key updates and deletes can be performed by performing additional checks and operations to ensure data consistency.
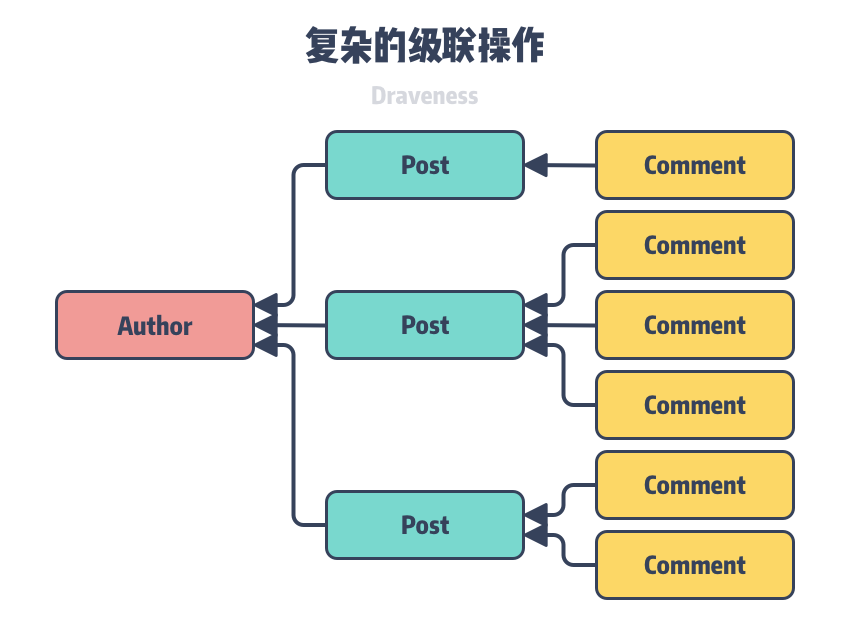
Although the starting point of cascade deletion is also to ensure data integrity, we also need to pay attention to the problem of mass data deletion caused by cascade deletion when designing different relationships between relational tables. As shown in the figure above, when a client wants to delete data in the authos table in the database, if we specify the cascade deletion behavior in both authors and posts, then the database will delete all the associated posts records and the comments data associated with the posts table at the same time.
This cascading deletion behavior involving multiple levels does not cause problems in databases with smaller data volumes, but deleting critical data in databases with larger data volumes can cause an avalanche where the deletion of a single record can be scaled up to tens or even hundreds of times, and these random reads and writes to disk can cause significant overhead, a situation we want to avoid as much as possible. If we can design the relationships between tables better and use the CASCADE behavior carefully, it is very important to ensure the legitimacy of the data in the database. Using this feature can avoid expired and illegal data in the database, but it is also important to reasonably anticipate the worst-case scenario that may result when using it.
It is feasible to manually implement cascade delete operations for databases. If we delete all the data in a transaction in order, we can indeed ensure data consistency, but this is not much different from the cascade delete feature for foreign keys, but will have worse performance. If we can accept data inconsistency within a time window, we can split a large deletion task into multiple subtasks to be executed in batches, reducing the peak impact on the database.
This approach imposes a greater additional overhead than CASCADE for database foreign keys, except that we can reduce the transient impact on database performance.
Summary
The several different behaviors provided by foreign keys on updates and deletions can all help us ensure consistency and reference legality of data in the database, but the use of foreign keys also requires the database to bear additional overhead, and in today’s world where most services can scale horizontally, the use of foreign keys in high concurrency scenarios can really affect the throughput ceiling of the service. It is possible to implement foreign keys manually outside of the database, but it will incur a lot of maintenance costs or require us to make some compromises on data consistency. We can analyze the differences between using foreign keys, simulating foreign keys, and not using foreign keys in terms of availability and consistency.
- Not using foreign keys sacrifices consistency of data in the database, but reduces the load on the database.
- Simulating foreign keys moves some of the work outside the database, and we may need to give up some of the consistency to get higher availability, but for that part of the availability we pay more development and maintenance costs and increase the number of network communications with the database.
- the use of foreign keys guarantees the consistency of data in the database and also gives all the computational tasks to the database.
In most systems that do not require high concurrency or have strong requirements for consistency, we can directly use the foreign keys provided by the database to help us verify the data, but in scenarios that do not require high consistency, complex scenarios or large-scale teams, not using foreign keys does take the burden off the database, and large teams have more time and energy to design other solutions, e.g., distributed relational databases.
When we consider whether we should use foreign keys in the database, we need to focus on the core of our database to take on this part of the computing task will not affect the availability of the system, in the use of also ** should not be a blanket decision ** with or without foreign keys, should be based on specific scenarios to make decisions, we introduce here two problems that may be encountered when using foreign keys.
RESTRICTforeign keys check the legality of foreign key constraints when updating and deleting data in relational tables, ensuring that foreign keys do not refer to records that do not exist.CASCADEforeign keys will trigger updates and deletions of associated records when updating and deleting data in relational tables, which may have an order-of-magnitude amplification effect in databases with large data volumes.
We don’t really have a choice in many cases whether to use foreign keys or not; most company DBAs have more explicit rules about the use of database systems, but we need to be clear about the reasons for making the choice between using foreign keys and not using them. At the end of the day, let’s look at some more open-ended related questions, and the interested reader can think carefully about the following.
- What other features of the database would we not use in a production environment? Why?
- What are the differences between a distributed relational database and a traditional database such as MySQL?