Generally, large websites store their images on dedicated servers, which can be a good way to improve the performance of the website. A simpler way is to use the services provided by cloud vendors. Today we are going to introduce an open source implementation of the solution zing.
zimg Introduction
zimg is a set of Chinese open source programs designed and developed for image processing servers, aiming to solve the following three problems in image services.
- Large traffic: For some small and medium-sized websites, the traffic problem is the cost problem, pictures increase the traffic by an order of magnitude compared to text, and every byte saved is a white silver. So any Internet application that involves pictures should be planned in an integrated manner to reduce traffic and save money.
- High concurrency: The problem of high concurrency hardly occurs when the user volume is low, but once the user climbs, or encounters a hot event, such as a website being uploaded with an explosive news picture, a large number of browsing requests will flood in a short time, and if the architecture is poorly designed and there is no emergency response plan, it is likely to lead to a dead-end cycle of lots of waiting, more page refreshes and more requests. Overall, it’s all about making the performance of the image service good enough.
- Massive storage: Facebook users upload hundreds of millions of pictures, with a total capacity of over nPB. Such an order of magnitude is beyond the reach of general enterprises. Although it is difficult to make an application that can match Facebook, but from the perspective of architecture design, a good expansion plan is still necessary. Need to design in advance the most appropriate massive image data storage solutions and easy to operate the topology program to cope with the growing business needs in the future.
The above three issues, in fact, are also mutually constrained and clamped, for example, to reduce the flow of traffic, it requires a large number of calculations, resulting in longer request processing time, the system processing capacity per unit of time decreases; and then for example, in order to store more pictures, it is inevitable to consume resources on the lookup, the same will also reduce the processing capacity. Therefore, although the picture service seems to be a simple business, it is not a trivial matter to actually do it.
Positioning of zimg.
- zimg is an image storage and processing server. You can get compressed and scaled images from zimg using URL parameters.
- zimg’s concurrent I/O, distributed storage and just-in-time processing capabilities are excellent. You no longer need to use nginx in your image server. zimg can handle over 3000 image download jobs per second and over 90,000 HTTP display requests per second at high concurrency levels in benchmark tests. Performance is higher than PHP or other image processing servers.
- For small and medium-sized image bed services
The following features are supported by zimg.
- All images are returned as compressed images of 75% quality by default, in JPEG format, so that they are not recognizable to the naked eye, but are reduced in size
- Get the image with width x, scaled equally
- Get the rotated image
- Get a fixed size image of a specified area
- Get the image of a specific size, which is scaled differently from the original image to show the most content as possible, and the excess part needs to be cropped after scaling
- Get an image of a specific size to show all the contents of the image, so the image will be stretched to a new scale and deformed.
- Get an image of a specific size, but without scaling, just show the core content of the image
- Get the image scaled by the specified percentage
- Get the image with the specified compression ratio
- Get the image with the color removed
- Get the image in the specified format
- Get image information
- Delete the specified image
- These above functions are provided with just one url + specific parameters by get.
zimg design ideas
To have the best performance in the matter of presenting images, you first need to separate the image serving part from the overall business. Using a separate domain name and setting up a separate image server has many benefits, such as
- CDN triage. If you have noticed, popular websites have special domain names for their image addresses, such as sinaimg.cn for Weibo, fmn.xnpic.com for Renren, etc. Different domain names can achieve very obvious optimization effects at the CDN resolution level.
- The number of concurrent browser connections is limited. Generally speaking, browsers will create many connections when loading HTML resources and download them in parallel. Different browsers have different limits on the number of concurrent connections to the same host. If the image server is independent, it will not take up the quota of the number of connections to the main site, which improves the performance of the site to some extent.
- Browser caching. Nowadays, all browsers have caching function, but due to the existence of cookies, most browsers do not cache requests with cookies, resulting in a large number of image requests that cannot be hit and have to be downloaded again. A domain-independent image server can alleviate this problem to a large extent.
The mainstream solution is to use Nginx for the front-end, PHP or self-developed modules for the middle, and physical storage for the back-end; for the more unusual ones, such as Facebook, they combine image request processing and storage into one, called haystack, which has the advantage that haystack only handles The advantage is that haystack only handles requests related to images, stripping away the cumbersome functions of an ordinary http server, making it lighter and more efficient, and also making deployment and operation and maintenance less difficult. zimg adopts a similar strategy to Facebook, taking the power of image processing into its own hands, handling most things by itself, and minimizing the introduction of third-party modules unless particularly necessary.
zimg’s architecture design
For the ultimate performance, zimg is developed entirely in C. It is generally divided into three layers, the front-end http processing layer, the middle image processing layer and the back-end storage layer. The following diagram shows the zimg architecture design.
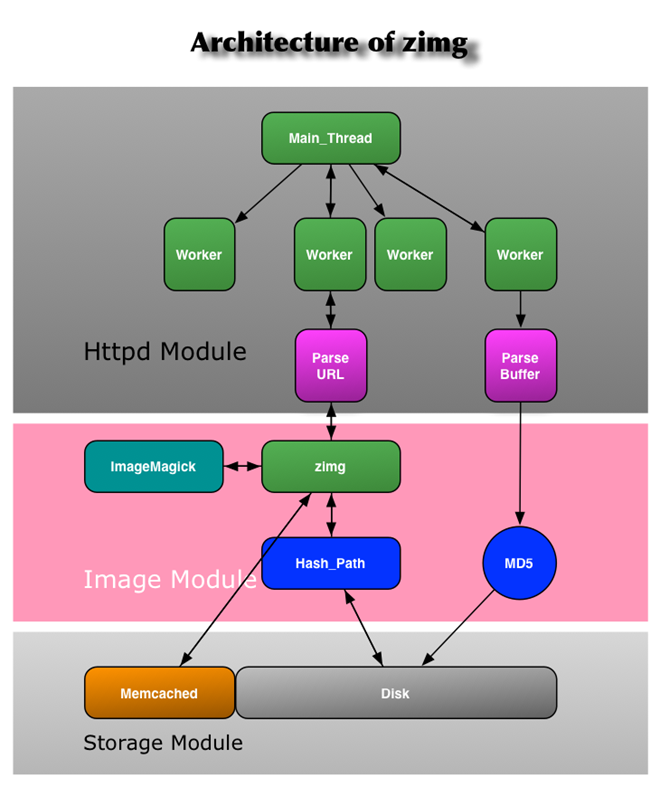
- http processing layer introduces the libevhtp library based on libevent, which specializes in handling basic http requests .
- Image processing layer uses imagemagick library.
- storage layer using memcached cache plus direct read and write hard disk solution, later may introduce TFS4 and so on.
In order to avoid performance bottlenecks caused by databases, zimg does not introduce structured databases, and all image lookups are solved using hashing. In fact, the design of the image server is a game between I/O and CPU computing, and the best strategy is of course to continue to split: the CPU-sensitive http and image processing layers are deployed on machines with more computing power, the memory-sensitive cache layer is deployed on machines with more memory, and the I/O-sensitive physical storage layer is placed on machines equipped with SSDs, but not everyone can afford such an extravagant configuration. zimg compromises between cost and business requirements and currently only needs to be deployed on one server. The idea that zimg has chosen is to minimize I/O and put the pressure on the CPU, which has proven to be true, even on machines with poor hard drive performance; even if SSDs become fully popular in the future, the CPU’s computing power will increase accordingly, and overall zimg’s solution is not too unbalanced.
Code implementation of zimg
Although zimg is not sub-modular on the binary entity, for the reasons mentioned above, and at this stage is geared towards small to medium sized services that can be deployed on a single machine, the code is separated.
main.c
main.c is the entry point of the program, the main function is to handle the startup parameters, some of which function as follows.
- -p [port] Listening port number, default 4869
- -t [thread_num] number of threads, default 4, please adjust to the number of CPU cores of the specific server
- -k [max_keepalive_num] Maximum number of keepalive connections, default 1, no long connections are enabled, 0 is enabled
- -l [keepalive_num] Enable logging, it will bring big performance loss, use your own discretion whether to enable it or not
- -M [memcached_ip] The IP of the cache-enabled connection
- -m [memcached_port] Cache-enabled connection port
- -b [backlog_num] Maximum number of connections per thread, default 1024, set at your discretion
zhttpd.c
zhttpd.c is the part that parses http requests and is divided into two main parts: GET requests look for images based on the request URL parameters and forward them to the image processing layer for processing, and finally return the results to the user; POST receives upload requests and then deposits the images in the calculated path. To achieve the overall design vision of zimg, zhttpd takes on a large part of the work and has some key points, which are highlighted below.
- The unique Key value of an image in zimg is the MD5 of that image, which hides the path and reduces the storage pressure on the front end (meaning the front part of zimg, probably your application server) and zimg itself, and is the key to avoid introducing structured storage parts, so all GET requests are stitched together based on MD5. If you need to show an image somewhere on your website, the original size of this image is 10001000, but the place you want to show is only 300300, how would you do it? Usually you still rely on CSS to control it, but that would result in a lot of wasted traffic. For this reason, zimg provides an image crop function, all you need to do is to add w=300&h=300 (width and height) after the image URL.
- In the image upload section, if we use Nginx for the front-end of our image server, the upload function is implemented in PHP, which requires very little code to be written, but the performance is very poor. First of all, after PHP receives the request from Nginx, it will separate the binary file according to the http protocol (RFC1867), store it in a temporary directory, and then we will use $_FILES[“upfile”][tmp_name] in the PHP code to get the file After calculating the MD5 and then stored in the specified directory, in this process there is a read file and a write file is redundant, in fact, the best case is that we get the binary file in the http request (preferably in memory), directly calculate the MD5 and then stored. So I went to read the source code of PHP and implemented the parsing of POST files by myself, so that the http layer is directly connected to the storage layer, improving the performance of uploading images. In addition to the POST request example, there are many places in the zimg code that reflect this idea of “reduce disk I/O, try to read and write in memory” and “avoid memory replication”, a little accumulation will eventually bring excellent performance.
zimg.c
zimg.c is the part that calls imagemagick to process images. At this stage zimg serves standalone image servers with terabytes of storage, so the storage path uses a 2-level subdirectory scheme. Since the number of subdirectories in the same directory in Linux should preferably not exceed 2000, plus the MD5 value itself is a 32-bit hexadecimal number, zimg takes a very tricky way: according to the first six bits of MD5 for hashing, 1-3 bits are converted to hexadecimal number and divided by 4, the range falls exactly within 1024, with this number as the first level subdirectory; 4-6 bits are similarly The second level subdirectory is a folder named after MD5, and each MD5 folder stores the original image and other versions of the image as needed. Assuming that a picture takes up an average space of 200KB, the total capacity supported by a zimg server can be calculated: 1024 * 1024 * 1024 * 200KB = 200TB
In addition to path planning, another great feature of zimg is image compression. From the user’s point of view, the image returned by zimg only needs to look similar to the original image, and if the original image is really needed, it can be obtained by setting all parameters to null. Based on this condition, zimg.c compresses all converted images, which are almost indistinguishable to the naked eye, but the size is reduced by 67.05%. The specific processing is.
- image cropping with the LanczosFilter filter.
- Compressing at a compression rate of 75%.
- Removing the Exif information from the image.
- Converting to JPEG format.
After such processing the traffic can be reduced to a great extent to achieve the design goals.
zcache.c
zcache.c is the section that introduces the memcached cache, and it is important to introduce the cache, especially after the volume of images rises. Caching is used as a very important feature in zimg, and almost all the lookup sections in zimg.c will first check if the cache exists. For example, if I want a (representing a certain MD5) image cropped to 100100 and then grayed out, the process is to first find if the cache of a&w=100&h=100&g=1 exists, and if not, to find if the file exists (the file name corresponding to this request is a/100100pg), and if it doesn’t exist, to find the color image cache of this resolution If it still does not exist, we will find out if the color image file exists (the corresponding file name is a/100*100p), if not, then we will query the original image cache, and if the original image cache is still not hit, we can only open the original image file, and then start cropping and graying, and then return it to the user and store it in the cache.
As you can see, if the cache is hit at some point in the above process, the number of I/O or image processing operations will be reduced accordingly. It is well known that the difference between memory and hard disk read/write speed is huge, so such a design will be very important for hotspot image resistance.
In addition to the above core code is some supporting code, such as log part, md5 calculation part, util part, etc.
zimg deployment and installation (centos 7)
Install the dependency libraries:
Installation dependencies.
|
|
Optional plug-ins.
|
|
Build zimg
After successful installation.
Open http://localhost:4869 to see if the installation is successful.
If it’s too much trouble to install manually, just use the docker image
You can package your own image service based on zimg.
Reference links.