KinD is a very lightweight Kubernetes installation tool that treats Docker containers as Kubernetes nodes, making it very easy to use. Since you can run a Kubernetes cluster in a Docker container, it’s natural to wonder if you can run it in a Pod. What are the problems with running in a Pod?
Installing Docker Daemon in a Pod
KinD is now dependent on Docker, so first we need to create an image that allows us to run Docker Deamon in the Pod, so that we can execute commands like docker run inside the Pod, but this is not the same as the DIND mode of mounting docker.sock on the host as we mentioned before This is different from the DIND mode of mounting the host docker.sock. There are still a lot of problems with running Docker Deamon in a Pod.
The PID 1 problem
For example, we need to run Docker Daemon and some Kubernetes cluster tests in a container, and these tests depend on KinD and Docker Damon, and we may use systemd to run multiple services in a container, but there are some problems with using systemd.
For example, we need to keep the exit status of the test, and the container used in Kubernetes can watch the exit status of the first process (PID 1) in the container when it is running. If we use systemd, then the exit status of our test process will not be forwarded to Kubernetes. 2. It is also important to get the logs of the tests. In Kubernetes, the container logs written to stdout and stderr are automatically fetched, but if we use systemd, it is more difficult to get the application logs.
To solve the above problem, we can use the following startup script in the container image.
However, it is important to note that we cannot use the above script as an entrypoint for the container; the entrypoint defined in the image will run in the container as PID 1 in a separate pid namespace; PID 1 is a special process in the kernel that behaves differently from other processes.
Essentially, the process that receives the signal is PID 1: it will be handled specially by the kernel; if it does not register a processor for the signal, the kernel will not fall back to the default behavior (i.e., kill the process). Since the kernel kills the process by default when the SIGTERM signal is received, some processes may not register a signal handler for the SIGTERM signal. If this happens, when Kubernetes tries to terminate the Pod, SIGTERM will be swallowed and you will notice that the Pod will be stuck in the Terminating state.
This is not really a new problem, but not many people are aware of it and keep building containers with this problem. We can solve this problem using the application tini as the entry point for the image, as follows.
|
|
This program will properly register the signal handler and forward the signal. It will also perform some other PID 1 things, such as reclaiming zombie processes in the container.
Mount cgroups
Since Docker Daemon needs to control cgroups, it needs to mount the cgroup filesystem to the container. But since cgroups are shared with the host, we need to make sure that the cgroups controlled by Docker Daemon do not affect other cgroups used by other containers or host processes, and that the cgroups created by Docker Daemon in the container are not leaked after the container exits.
There is a -cgroup-parent parameter in Docker Daemon to tell Daemon to nest all container cgroups under the specified cgroup. When a container is running under a Kubernetes cluster, we set the -cgroup-parent parameter in Docker Daemon in the container so that all of its cgroups are nested under the cgroup created by Kubernetes for the container.
In the past, to make the cgroup file system available in the container, some users would mount /sys/fs/cgroup from the host to this location in the container. If we use it this way, we need to set -cgroup-parent to the following in the container startup script so that the cgroups created by Docker Daemon will be nested correctly.
|
|
Note:
/proc/self/cgroupshows the cgorup path of the calling process.
But we should know that mounting the host’s /sys/fs/cgroup file is a very dangerous thing to do, because it exposes the entire host’s cgroup hierarchy to the container. To solve this problem, Docker used a trick to hide unrelated cgroups from the containers. docker mounts the root of each cgroup system’s cgroup hierarchy from the container’s cgroups.
|
|
From the above, we can see that cgroups control the files at the root of the cgroup hierarchy in the container by mapping the /sys/fs/cgroup/memory/memory.limit_in_bytes file on the host cgroup file system to the /sys/fs/cgroup/memory/docker/<CONTAINER_ID>/ memory.limit_in_bytes to control the file at the root of the cgroup hierarchy within the container, which prevents container processes from accidentally modifying the host’s cgroup.
However, this approach can sometimes be confusing for applications like cadvisor and kubelet, because binding mounts do not change the contents of /proc/<PID>/cgroup.
|
|
cadvisor will look at /proc/<PID>/cgroup to get the cgroup of a given process and try to get CPU or memory statistics from the corresponding cgroup. To solve this problem, we did another mount inside the container, from /sys/fs/cgroup/memory to /sys/fs/cgroup/memory/ docker/<CONTAINER_ID>/ (for all cgroup subsystems), which works well for this problem.
The new workaround is now to use cgroup namespace if you are running under a Linux system with kernel version 4.6+, and both runc and docker both add support for cgroup namespaces. However, Kubernetes does not currently support the cgroup namespace, but will soon do so as cgroups v2 support cgroups-v2.md).
IPtables
While using it we found that when running a Kubernetes cluster online, sometimes the nested containers started by the Docker Daemon inside the container could not access the extranet, but worked fine on the local development computer, which most developers should encounter often.
Finally, it was found that when this problem occurred, the packets from the nested Docker container did not hit the POSTROUTING chain of iptables, so it was not masqueraded.
This problem is because the image containing the Docker Daemon is based on Debian buster, which by default uses nftables as the default backend for iptables. .debian.org/nftables) as the default backend for iptables, but Docker itself does not support nftables yet. To solve this problem, just switch to the iptables command in the container image.
The full Dockerfile file and startup script are available on GitHub (https://github.com/jieyu/docker-images/tree/master/dind), or you can use the jieyu/dind-buster:v0.1.8 image directly to test.
|
|
Simply deploy under a Kubernetes cluster using the Pod resource list shown below.
|
|
Running KinD in a Pod
We have successfully configured Docker-in-Docker (DinD) above, so let’s start a Kubernetes cluster in that container using KinD.
|
|
For some reason you may not be able to download kind with the above command, we can find a way to download it to the host in advance, and then directly mount it to the container can also be, I will kind and kubectl commands here are mounted to the container, use the following command to start the container can be.
|
|

You can see that KinD works well in containers to create Kubernetes clusters. Next, let’s test this directly in Kubernetes.
|
|
We can see that using KinD in Pod to create a cluster fails because the kubelet running in the KinD nested container randomly kills the processes in the top-level container, which is actually still related to the cgroups mount discussed above.
However, when I was using KinD in v0.8.1, I was able to create clusters in the above Pods normally, so I don’t know if there is any special treatment for KinD-built clusters.
If you are experiencing the same problem as above, then you can continue to see the solution below.
When the top-level container (DIND) is running in a Kubernetes Pod, for each cgroup subsystem (e.g. memory), its cgroup path from the host’s perspective is /kubepods/burstable/<POD_ID>/<DIND_CID>.
When KinD starts a kubelet within a nested node container within a DIND container, the kubelet will operate the cgroup under /kubepods/burstable/ relative to the root cgroup of the nested KIND node container for its Pods. from the host’s perspective, the cgroup path is / kubepods/burstable/<POD_ID>/<DIND_CID>/docker/<KIND_CID>/kubepods/burstable/.
These are correct, but in the nested KinD node container, there is another cgroup that exists under /kubepods/burstable/<POD_ID>/<DIND_CID>/docker/<DIND_CID>, as opposed to the root cgroup of the nested KinD node container, which existed before the kubelet existed before it was started, as a result of the cgroups mount we discussed above, set via the KinD entrypoint script. And if you do a cat /kubepods/burstable/<POD_ID>/docker/<DIND_CID>/tasks inside the KinD node container, you will see the processes of the DinD container.
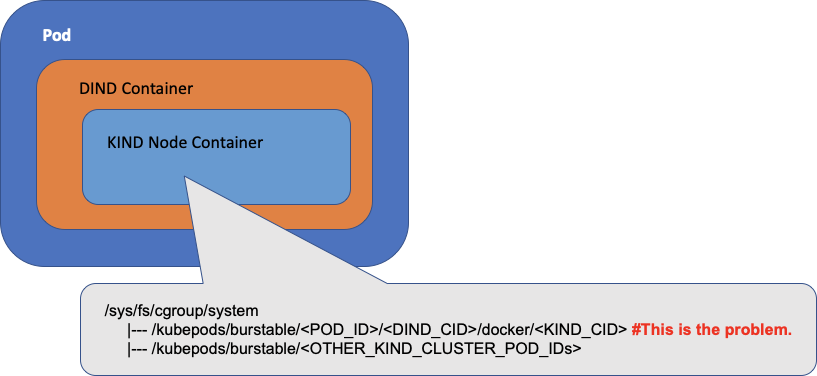
This is the root cause: the kubelet inside the KinD node container sees the cgroup and thinks it should manage it, but cannot find a Pod associated with the cgroup, so it tries to delete the cgroup by killing the processes belonging to the cgroup, which results in random processes being killed. The solution to this problem is to set the -cgroup-root parameter of the kubelet to instruct the kubelet in the KinD node container to use a root path (e.g. /kubelet) for its Pods that does not have a cgroup. This allows you to start a KinD cluster in a Kubernetes cluster, which we can fix with the YAML resource manifest file below.
|
|
Once created using the resource list file above, we can go into the Pod and verify it in a moment.
It is also possible to use the Docker CLI directly to test.
|
|
The above image corresponds to the Dockerfile and startup script address: https://github.com/jieyu/docker-images/tree/master/kind-cluster
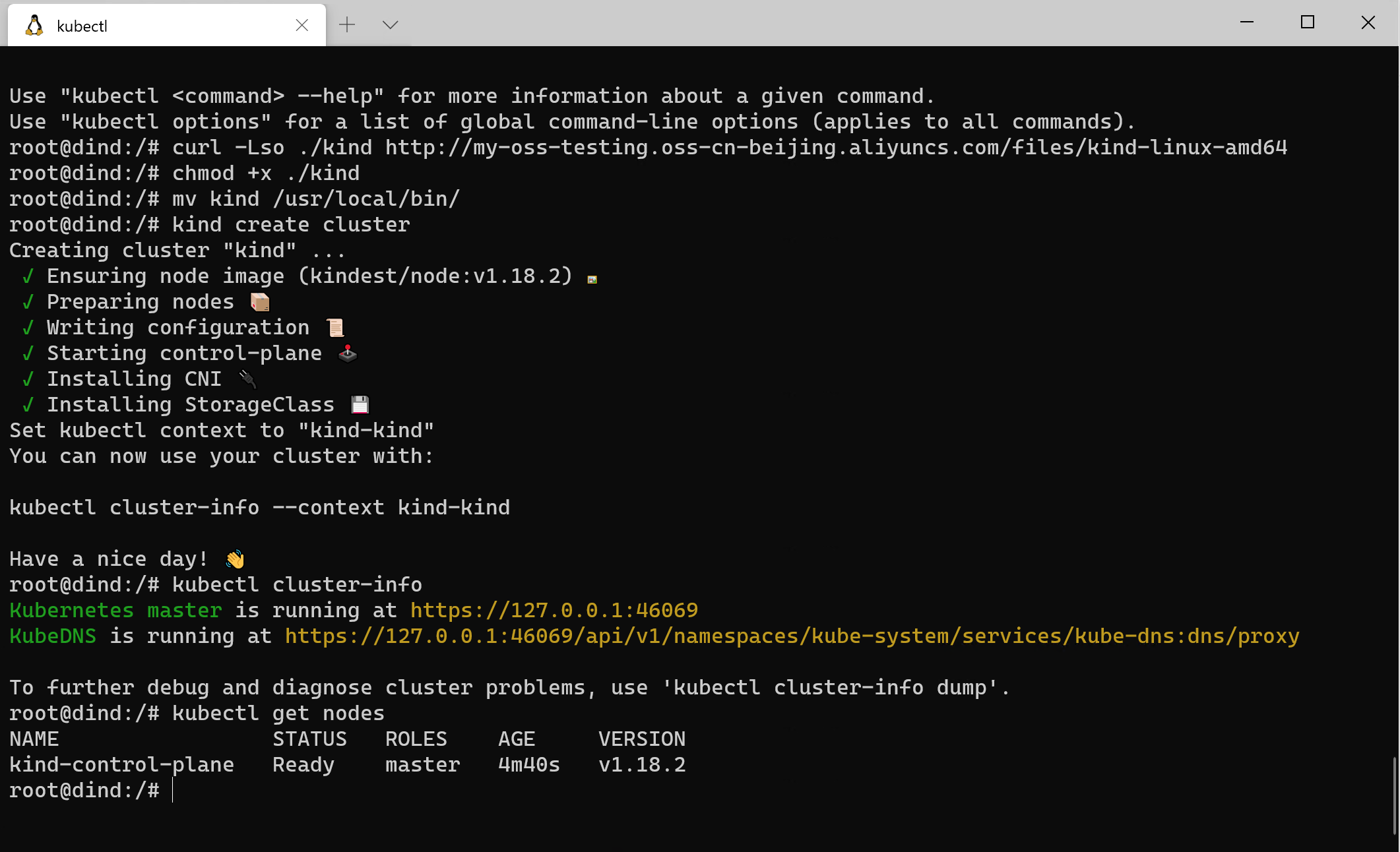
The following image shows the final result of a Pod I created in a Kubernetes cluster built by KinD, and then a standalone Kubernetes cluster created in the Pod.

Summary
When implementing the above features, we encountered a lot of obstacles in the process, most of which are caused by the fact that Docker containers don’t provide complete isolation from the host, and some kernel resources like cgroups are shared in the kernel, which may also cause potential conflicts if many containers operate them at the same time. But once these problems are solved, we can easily run a standalone Kubernetes cluster in a Kubernetes cluster Pod, which should be considered a real Kubernetes IN Kubernetes, right?