mmap Basic Concepts
mmap is a memory mapping method that maps a file to a process address space, mapping a file’s disk address to a process virtual address. Once such a mapping relationship is implemented, the process can read and write to this section of memory using pointers, and the system will automatically write back dirty pages to the corresponding file disk, i.e., it is done with the file without having to call read, write, and other system calls. On the contrary, changes to this area in kernel space are directly reflected in user space, thus allowing file sharing between processes.
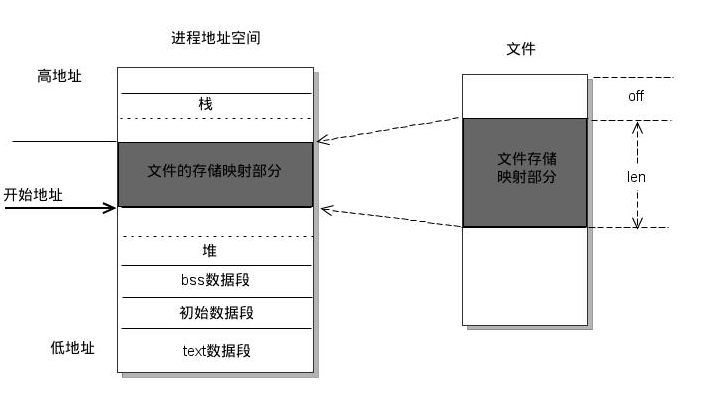
The operating system provides this set of mmap companion functions
mmap in Java
Native read and write methods in Java can be roughly divided into three types: normal IO, FileChannel, and mmap. For example, FileWriter and FileReader exist in the java.io package, and they belong to normal IO; FileChannel exists in the java.nio package, and is the most common file manipulation class in Java; and today’s main character, mmap, is a special way of reading and writing files derived from the map method called by FileChannel. The main character, mmap, is a special way of reading and writing files derived from the map method called by FileChannel, which is called memory mapping.
The way mmap is used.
MappedByteBuffer is the mmap operation class in Java.
|
|
mmap is not a silver bullet
A big motivation for writing this article came from a lot of misconceptions about mmap in the web. When I first learned about mmap, many articles mentioned that mmap was suitable for handling large files, but in retrospect, this is a ridiculous view, and I hope that this article will clarify what mmap is supposed to be.
The coexistence of FileChannel and mmap probably means that both have their appropriate use cases, and they do. When you look at them, you can think of them as two tools for implementing file IO, and there is no good or bad tool per se.
mmap vs FileChannel
This section details the similarities and differences between FileChannel and mmap for file IO.
pageCache
Both FileChannel and mmap reads and writes go through the pageCache, or more precisely the cache part of memory observed by vmstat, rather than the user space memory.
I have not researched whether this part of memory mapped by mmap can be called pageCache, but in the OS view, there is not much difference between them, as this part of the cache is controlled by the kernel. Later in this article, we will also call the memory from mmap a pageCache.
Missing page interrupts
Readers with a basic understanding of Linux file IO may not be too familiar with the concept of page-out interrupts. mmap and FileChannel both read and write to files in a page-out interrupt fashion.
Take the example of mmap reading a 1G file, fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, _GB); The mapping is a minimal consumption operation, but it does not mean that the 1G file is read into the pageCache. pageCache.
MappedByteBuffer#load method, the load method is also triggered by a per-page access break
The following is the gradual growth of the pageCache, which has grown by about 1.034G in total, indicating that the contents of the file are fully loaded at this point.
|
|
Two details.
- the mmap mapping process can be interpreted as a lazy load, only get() will trigger a page out interrupt
- the pre-reading size is determined by the OS algorithm and can be treated as 4kb by default, i.e. if you want lazy loading to become real-time loading, you need to iterate through it once according to step=4kb
The same principle of FileChannel out-of-page interrupt, both need to use PageCache as a springboard to finish reading and writing files.
Number of memory copies
Many argue that mmap makes one less copy than FileChannel, but I personally think we need to differentiate between scenarios.
For example, if the requirement is to read an int from the first address of a file, the two links are actually the same: SSD -> pageCache -> application memory, and mmap does not make one less copy.
But if the requirement is to maintain a 100M multiplexed buffer, and it involves file IO, mmap can be used directly as a 100M buffer, instead of maintaining another 100M buffer in the process memory (user space).
User state vs. kernel state
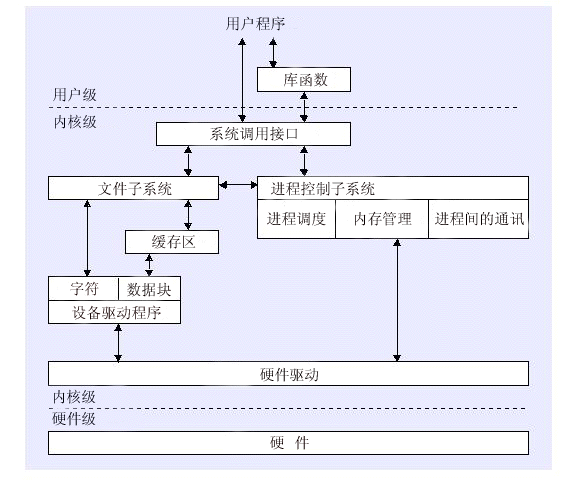
For security reasons, the operating system encapsulates some of the underlying capabilities and provides system calls for users to use. Here is the problem of switching between “user state” and “kernel state”, and I think this is where many people’s concepts are blurred, so I’ll sort out my personal knowledge here.
Let’s look at FileChannel first, the following two pieces of code, who do you think is faster?
|
|
Using method 1: 4kb buffering to swipe the disk (regular operation), it only took 1.2s to finish writing 1G on my test machine, while method 2, which does not use any buffering, was almost straightforwardly stuck, the file grew very slowly, and after waiting for 5 minutes before it was finished, the test was interrupted.
Using a write buffer is a very classic optimization trick. Users only need to set a write buffer of 4kb integer multiples to aggregate small data writes, so that the data is swiped from the pageCache in as many integer multiples of 4kb as possible to avoid write amplification problems. But this is not the focus of this section, have you ever thought, pageCache is actually a layer of buffer itself, the actual write 1byte is not synchronized with the disk, the equivalent of writing the memory, pageCache disk by the operating system’s own decision. Then why is method two so slow? **The main reason is that the underlying read/write associated system calls of the filechannel need to switch between kernel and user states. Method 2 switches 4096 times more than method 1, and the state switching becomes the bottleneck, resulting in a serious time consumption.
To summarize the key points at this stage, the act of setting user write buffers in DRAM has two implications: 1.
- convenient to do 4kb alignment, ssd swipe disk friendly
- reduce the number of user state and kernel state switch, cpu friendly
However, unlike mmap, the underlying mapping capability does not involve switching between kernel and user states, note that there is still nothing to do with memory copying here, and the root cause of the state not switching is the system call itself associated with mmap. It is also very easy to verify this, as we use the mmap implementation of method 2 to see how fast.
On my test machine, it took 3s, which is slower than a FileChannel + 4kb buffered write, but far faster than a FileChannel writing a single byte.
mmap details added
copy on write mode
We notice that the first parameter of public abstract MappedByteBuffer map(MapMode mode, long position, long size), MapMode, actually has three values, and when surfing the web, we hardly find any articles explaining MapMode. MapMode has three enumerated values READ_WRITE, READ_ONLY, PRIVATE, most of the time the one used is probably READ_WRITE, while READ_ONLY is just a restriction of WRITE, which is easy to understand, but this PRIVATE seems to have a mysterious veil on it. But this PRIVATE seems to have a veil of mystery.
In fact, the PRIVATE mode is the copy on write mode of mmap, and when using MapMode.
- any other modifications to the file will be directly reflected in the current mmap map. 2.
- private mmap’s own put behavior afterwards will trigger a copy, forming its own copy, and any changes will not be swiped to the file and will no longer sense changes to that page of the file.
Commonly known as: copy on write.
What is the point of this? The point is that any changes will not be swiped back to the file. For one thing, you get a copy of the file, and if you happen to need it, you can use PRIVATE mode to map it directly, and for another, it’s a little exciting because you get a real PageCache and don’t have to worry about it being overhead by the OS swiping the disk. The remaining 1G can only be used by the kernel state, and if you want to use it for user state programs, you can use the copy on write mode of mmap, which will not take up your in-heap or out-of-heap memory.
Reclaiming mmap memory
To correct an error in a previous blog post about mmap memory recycling, recycling mmap is simple
|
|
The life of an mmap can be simply divided into: map (mapping), get/load (missing page interrupt), and clean (recycling). A useful trick is to dynamically allocate memory map areas that can be reclaimed asynchronously after they have been read.
mmap usage scenarios
Using mmap to handle frequent reads and writes of small data
If IO is very frequent but data is very small, it is recommended to use mmap to avoid tangent problems caused by FileChannel. For example, appending writes to index files.
mmap caching
When using FileChannel for file reads and writes, a piece of write cache is often needed for aggregation purposes, most often using in-heap/out-of-heap memory, but they both have the problem that when the process hangs, the in-heap/out-of-heap memory is immediately lost, and this part of the data that did not fall on the disk is lost. Using mmap as a cache, on the other hand, stores directly in the pageCache and does not result in data loss, although this only circumvents the process being killed, not the power loss.
Reading and writing small files
Contrary to many statements on the web, mmap is particularly suitable for sequential reading and writing due to its non-tangent state, but due to the size limitation in sun.nio.ch.FileChannelImpl#map(MapMode mode, long position, long size), only an int value can be passed, so If 2G is used as the threshold for large or small files, it is generally advantageous to use mmap to read and write files smaller than 2G. This is also exploited in RocketMQ, where the commitLog size is sliced by 1G to make it easier to use mmap. By the way, I forgot to mention that RocketMQ and other message queues use mmap all the time.
Reads and Writes in a cpu crunch
In most scenarios, the combination of a FileChannel and a read/write buffer has an advantage over mmap, or a tie, but in cpu-critical reads and writes, using mmap for reads and writes is often optimized, based on the fact that mmap does not overwhelm the cpu with user-state and kernel-state switching (but then takes on the overhead of dynamic mapping and asynchronous memory reclamation).
Special hardware and software factors
For example, persistent memory Pmem, different generations of SSDs, different CPUs, different cores, different file systems, different file system mounts, etc. all affect the speed of mmap and filechannel read/write, because they correspond to different system calls. Only after benchmarking will we know how fast or slow they are.