Overview
When we think of “scheduling”, the first thing that comes to mind is the scheduling of processes and threads by the operating system. The operating system scheduler schedules multiple threads on the system to run on the physical CPU according to a certain algorithm. Although threads are relatively lightweight, they do have a large additional overhead when scheduling. Each thread takes up more than 1M of memory space, and the system needs to be asked for resources to switch between threads and restore the contents of registers.
The Go language’s Goroutine can be seen as a layer of abstraction over threads, which is much more lightweight and reduces the extra overhead of context switching, and the Goroutine takes up fewer resources. For example, the stack memory consumption for creating a Goroutine is 2 KB, whereas a thread takes up more than 1M. Goroutine switching costs are also much smaller than threads.
G M P model
Go’s scheduler uses three structures to implement the scheduling of Goroutines: G M P.
G : represents a Goroutine, each of which has its own separate stack for the current running memory and state. When a Goroutine is dispatched away from the CPU, the scheduler code is responsible for saving the values of the CPU registers in the member variables of the G object, and when the Goroutine is dispatched to run, the scheduler code is responsible for restoring the values of the registers saved in the member variables of the G object to the CPU registers.
M: represents a kernel thread, which is itself bound to a kernel thread, and each worker thread has a unique instance object of the M structure to which it corresponds. The pointer maintains a binding relationship with the instance object of the P structure.
P : represents a virtual Processor that maintains a local Goroutine runnable G queue, with worker threads giving priority to their own local run queue and accessing the global run queue only when necessary, which greatly reduces lock conflicts and improves concurrency for worker threads. For each G to actually run, it first needs to be assigned a P.
In addition to the three structures above, there is a container for all Runnable runnable Goroutines, schedt. There is only one instance object of the schedt structure in each Go program, and it is a shared global variable in the code that each worker thread can access, along with the Goroutine run queue that it owns.
The following is the relationship between G, P, M and the global queue in schedt.
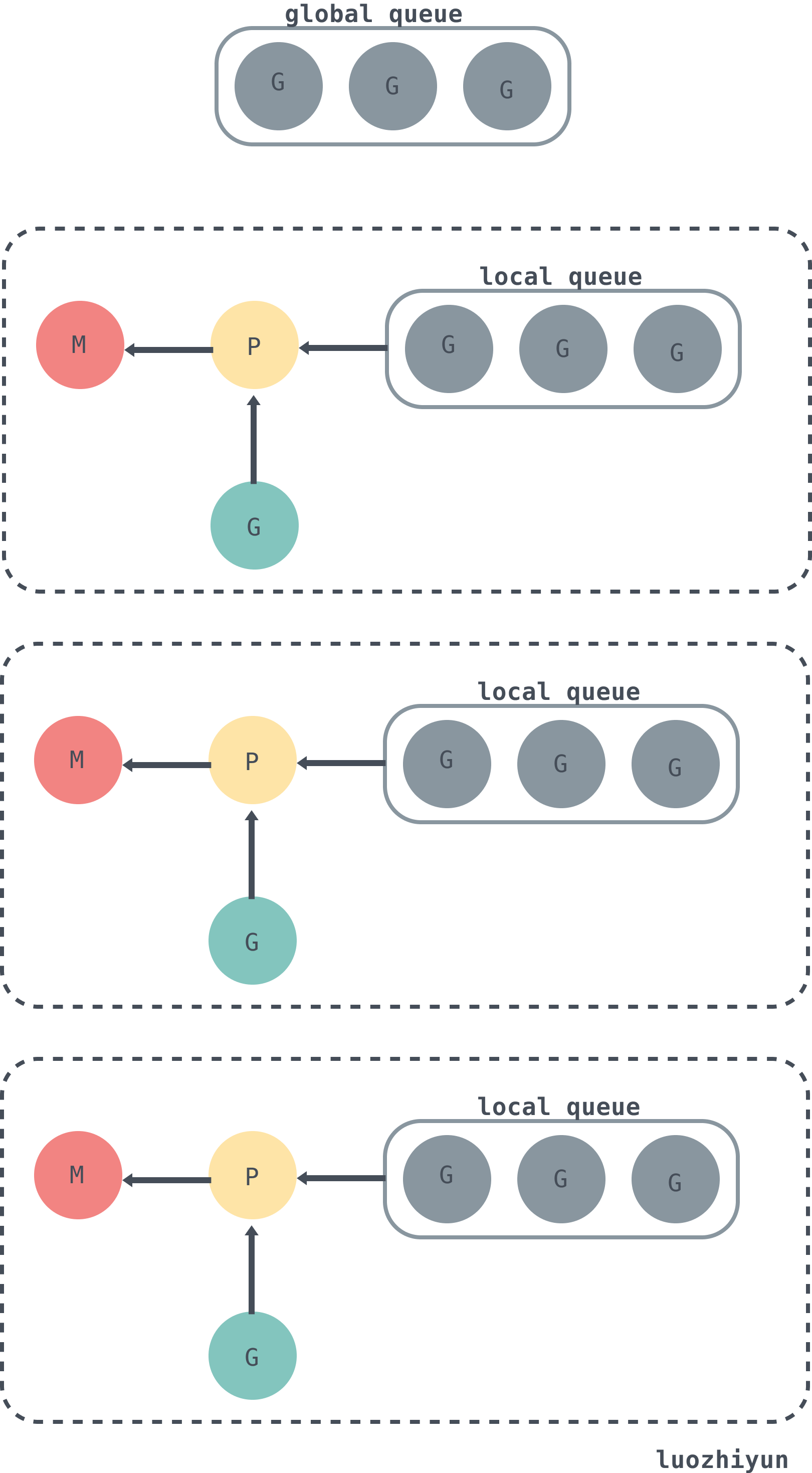
As can be seen from the diagram above, each m is bound to a P. Each P has a private local Goroutine queue, and the thread corresponding to the m gets the Goroutine from the local and global Goroutine queues and runs it, with the green G representing the running G.
By default, the runtime sets GOMAXPROCS to the number of cores on the current machine, assuming a quad-core machine creates four active OS threads, each corresponding to an M in the runtime.
Explanation
Structs
G M P structs defined in src/runtime/runtime2.go
G
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
type g struct {
// 当前 Goroutine 的栈内存范围 [stack.lo, stack.hi)
stack stack
// 用于调度器抢占式调度
stackguard0 uintptr
_panic *_panic
_defer *_defer
// 当前 Goroutine 占用的线程
m *m
// 存储 Goroutine 的调度相关的数据
sched gobuf
// Goroutine 的状态
atomicstatus uint32
// 抢占信号
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
// 抢占时将状态修改成 `_Gpreempted`
preemptStop bool // transition to _Gpreempted on preemption; otherwise, just deschedule
// 在同步安全点收缩栈
preemptShrink bool // shrink stack at synchronous safe point
...
}
|
Here’s a look at the gobuf structure, which is mainly used when the scheduler saves or restores contexts.
1
2
3
4
5
6
7
8
9
10
11
|
type gobuf struct {
// 栈指针
sp uintptr
// 程序计数器
pc uintptr
// gobuf对应的Goroutine
g guintptr
// 系统调用的返回值
ret sys.Uintreg
...
}
|
During execution, G may be in one of the following states.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
const (
// 刚刚被分配并且还没有被初始化
_Gidle = iota // 0
// 没有执行代码,没有栈的所有权,存储在运行队列中
_Grunnable // 1
// 可以执行代码,拥有栈的所有权,被赋予了内核线程 M 和处理器 P
_Grunning // 2
// 正在执行系统调用,拥有栈的所有权,没有执行用户代码,
// 被赋予了内核线程 M 但是不在运行队列上
_Gsyscall // 3
// 由于运行时而被阻塞,没有执行用户代码并且不在运行队列上,
// 但是可能存在于 Channel 的等待队列上
_Gwaiting // 4
// 表示当前goroutine没有被使用,没有执行代码,可能有分配的栈
_Gdead // 6
// 栈正在被拷贝,没有执行代码,不在运行队列上
_Gcopystack // 8
// 由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒
_Gpreempted // 9
// GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在
_Gscan = 0x1000
...
)
|
The above states look like a lot, but in reality it is only necessary to focus on the following.
- Waiting: _Gwaiting, _Gsyscall and _Gpreempted, which indicate that G is not executing.
- Runnable: _Grunnable, which means G is ready to run in thread;
- running: _Grunning, which indicates that G is running.
M
M in the Go language concurrency model is the operating system thread, and there will be at most GOMAXPROCS active threads that can run properly.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
type m struct {
// 持有调度栈的 Goroutine
g0 *g
// 处理 signal 的 G
gsignal *g
// 线程本地存储 thread-local
tls [6]uintptr // thread-local storage (for x86 extern register)
// 当前运行的G
curg *g // current running goroutine
caughtsig guintptr // goroutine running during fatal signal
// 正在运行代码的P
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
// 之前使用的P
oldp puintptr
...
}
|
P
The processor P in the scheduler is the intermediate layer between threads M and G, and is used to schedule the execution of G on M.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
type p struct {
id int32
// p 的状态
status uint32
// 调度器调用会+1
schedtick uint32 // incremented on every scheduler call
// 系统调用会+1
syscalltick uint32 // incremented on every system call
// 对应关联的 M
m muintptr
mcache *mcache
pcache pageCache
// defer 结构池
deferpool [5][]*_defer
deferpoolbuf [5][32]*_defer
// 可运行的 Goroutine 队列,可无锁访问
runqhead uint32
runqtail uint32
runq [256]guintptr
// 缓存可立即执行的 G
runnext guintptr
// 可用的 G 列表,G 状态等于 Gdead
gFree struct {
gList
n int32
}
...
}
|
Here’s a look at a few of the states of P.
1
2
3
4
5
6
7
8
9
10
11
12
|
const (
// 表示P没有运行用户代码或者调度器
_Pidle = iota
// 被线程 M 持有,并且正在执行用户代码或者调度器
_Prunning
// 没有执行用户代码,当前线程陷入系统调用
_Psyscall
// 被线程 M 持有,当前处理器由于垃圾回收 STW 被停止
_Pgcstop
// 当前处理器已经不被使用
_Pdead
)
|
sched
sched, as we mentioned above, holds the global resources held by the scheduler, such as the free P-chain table, G’s global queue, etc.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
type schedt struct {
...
lock mutex
// 空闲的 M 列表
midle muintptr
// 空闲的 M 列表数量
nmidle int32
// 下一个被创建的 M 的 id
mnext int64
// 能拥有的最大数量的 M
maxmcount int32
// 空闲 p 链表
pidle puintptr // idle p's
// 空闲 p 数量
npidle uint32
// 处于 spinning 状态的 M 的数量
nmspinning uint32
// 全局 runnable G 队列
runq gQueue
runqsize int32
// 有效 dead G 的全局缓存.
gFree struct {
lock mutex
stack gList // Gs with stacks
noStack gList // Gs without stacks
n int32
}
// sudog 结构的集中缓存
sudoglock mutex
sudogcache *sudog
// defer 结构的池
deferlock mutex
deferpool [5]*_defer
...
}
|
Starting from Go program start
Here again, debugging is done with the help of dlv. Note that the following examples are in Linux.
First we write a very simple example.
1
2
3
4
5
6
7
|
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
|
Then build it.
1
2
|
go build main.go
dlv exec ./main
|
After running the program, enter the following command as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
(dlv) r
Process restarted with PID 33191
(dlv) list
> _rt0_amd64_linux() /usr/local/go/src/runtime/rt0_linux_amd64.s:8 (PC: 0x4648c0)
Warning: debugging optimized function
Warning: listing may not match stale executable
3: // license that can be found in the LICENSE file.
4:
5: #include "textflag.h"
6:
7: TEXT _rt0_amd64_linux(SB),NOSPLIT,$-8
=> 8: JMP _rt0_amd64(SB)
9:
10: TEXT _rt0_amd64_linux_lib(SB),NOSPLIT,$0
11: JMP _rt0_amd64_lib(SB)
(dlv) si
> _rt0_amd64() /usr/local/go/src/runtime/asm_amd64.s:15 (PC: 0x4613e0)
Warning: debugging optimized function
Warning: listing may not match stale executable
10: // _rt0_amd64 is common startup code for most amd64 systems when using
11: // internal linking. This is the entry point for the program from the
12: // kernel for an ordinary -buildmode=exe program. The stack holds the
13: // number of arguments and the C-style argv.
14: TEXT _rt0_amd64(SB),NOSPLIT,$-8
=> 15: MOVQ 0(SP), DI // argc
16: LEAQ 8(SP), SI // argv
17: JMP runtime·rt0_go(SB)
18:
19: // main is common startup code for most amd64 systems when using
20: // external linking. The C startup code will call the symbol "main"
(dlv)
|
The above breakpoints show that the startup function for the linux amd64 system is in the runtime-rt0_go function in asm_amd64.s. Of course, different platforms have different program entry points, so you can find out for yourself if you are interested.
Let’s look at runtime-rt0_go.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
TEXT runtime·rt0_go(SB),NOSPLIT,$0
...
// 初始化执行文件的绝对路径
CALL runtime·args(SB)
// 初始化 CPU 个数和内存页大小
CALL runtime·osinit(SB)
// 调度器初始化
CALL runtime·schedinit(SB)
// 创建一个新的 goroutine 来启动程序
MOVQ $runtime·mainPC(SB), AX // entry
// 新建一个 goroutine,该 goroutine 绑定 runtime.main
CALL runtime·newproc(SB)
// 启动M,开始调度goroutine
CALL runtime·mstart(SB)
...
|
Of the CALL methods above.
schedinit performs the initialization of the various runtime components, which includes the initialization of our scheduler with memory allocators and recyclers.
newproc is responsible for creating execution units that can be scheduled by the runtime based on the main G entry address.
mstart starts the scheduler’s scheduling loop.
scheduling initialisation runtime.schedinit
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
func schedinit() {
...
_g_ := getg()
...
// 最大线程数10000
sched.maxmcount = 10000
// M0 初始化
mcommoninit(_g_.m, -1)
...
// 垃圾回收器初始化
gcinit()
sched.lastpoll = uint64(nanotime())
// 通过 CPU 核心数和 GOMAXPROCS 环境变量确定 P 的数量
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
// P 初始化
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
...
}
|
The schedinit function will set maxmcount to 10000, which is the maximum number of threads a Go program can create. M0 is then initialized by calling mcommoninit, and P is initialized by calling the procresize function after the number of CPU cores and the GOMAXPROCS environment variable have been determined.
M0 initialisation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
func mcommoninit(mp *m, id int64) {
_g_ := getg()
...
lock(&sched.lock)
// 如果传入id小于0,那么id则从mReserveID获取,初次从mReserveID获取id为0
if id >= 0 {
mp.id = id
} else {
mp.id = mReserveID()
}
//random初始化,用于窃取 G
mp.fastrand[0] = uint32(int64Hash(uint64(mp.id), fastrandseed))
mp.fastrand[1] = uint32(int64Hash(uint64(cputicks()), ^fastrandseed))
if mp.fastrand[0]|mp.fastrand[1] == 0 {
mp.fastrand[1] = 1
}
// 创建用于信号处理的gsignal,只是简单的从堆上分配一个g结构体对象,然后把栈设置好就返回了
mpreinit(mp)
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + _StackGuard
}
// 把 M 挂入全局链表allm之中
mp.alllink = allm
...
}
|
P Initialization
runtime.procresize
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
|
var allp []*p
func procresize(nprocs int32) *p {
// 获取先前的 P 个数
old := gomaxprocs
// 更新统计信息
now := nanotime()
if sched.procresizetime != 0 {
sched.totaltime += int64(old) * (now - sched.procresizetime)
}
sched.procresizetime = now
// 根据 runtime.MAXGOPROCS 调整 p 的数量,因为 runtime.MAXGOPROCS 用户可以自行设定
if nprocs > int32(len(allp)) {
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
allp = allp[:nprocs]
} else {
nallp := make([]*p, nprocs)
copy(nallp, allp[:cap(allp)])
allp = nallp
}
unlock(&allpLock)
}
// 初始化新的 P
for i := old; i < nprocs; i++ {
pp := allp[i]
// 为空,则申请新的 P 对象
if pp == nil {
pp = new(p)
}
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}
_g_ := getg()
// P 不为空,并且 id 小于 nprocs ,那么可以继续使用当前 P
if _g_.m.p != 0 && _g_.m.p.ptr().id < nprocs {
// continue to use the current P
_g_.m.p.ptr().status = _Prunning
_g_.m.p.ptr().mcache.prepareForSweep()
} else {
// 释放当前 P,因为已失效
if _g_.m.p != 0 {
_g_.m.p.ptr().m = 0
}
_g_.m.p = 0
p := allp[0]
p.m = 0
p.status = _Pidle
// P0 绑定到当前的 M0
acquirep(p)
}
// 从未使用的 P 释放资源
for i := nprocs; i < old; i++ {
p := allp[i]
p.destroy()
// 不能释放 p 本身,因为他可能在 m 进入系统调用时被引用
}
// 释放完 P 之后重置allp的长度
if int32(len(allp)) != nprocs {
lock(&allpLock)
allp = allp[:nprocs]
unlock(&allpLock)
}
var runnablePs *p
// 将没有本地任务的 P 放到空闲链表中
for i := nprocs - 1; i >= 0; i-- {
p := allp[i]
// 当前正在使用的 P 略过
if _g_.m.p.ptr() == p {
continue
}
// 设置状态为 _Pidle
p.status = _Pidle
// P 的任务列表是否为空
if runqempty(p) {
// 放入到空闲列表中
pidleput(p)
} else {
// 获取空闲 M 绑定到 P 上
p.m.set(mget())
//
p.link.set(runnablePs)
runnablePs = p
}
}
stealOrder.reset(uint32(nprocs))
var int32p *int32 = &gomaxprocs // make compiler check that gomaxprocs is an int32
atomic.Store((*uint32)(unsafe.Pointer(int32p)), uint32(nprocs))
return runnablePs
}
|
The procresize method is executed as follows.
- allp is a pool of resources for the global variable P. If the number of processors in the slice of allp is less than the desired number, the slice will be expanded.
- the procresize method requests a new P using new and initializes it using init, noting that the id of the initialized P is the value of i passed in, with the status _Pgcstop.
- then get M0 via
_g_.m.p and if M0 is already bound to a valid P, change the state of the bound P to _Prunning. otherwise get allp[0] as P0 and call runtime.acquirep to bind to M0.
- P with more than the number of processors releases resources via
p.destroy, which releases the resources associated with P and sets the P state to _Pdead.
- change the length of the global variable allp by truncating to ensure that it is equal to the expected number of processors.
- iterate over allp to check if P is free and put it in the free list if it is.
P.init
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
func (pp *p) init(id int32) {
// 设置id
pp.id = id
// 设置状态为 _Pgcstop
pp.status = _Pgcstop
// 与 sudog 相关
pp.sudogcache = pp.sudogbuf[:0]
for i := range pp.deferpool {
pp.deferpool[i] = pp.deferpoolbuf[i][:0]
}
pp.wbBuf.reset()
// mcache 初始化
if pp.mcache == nil {
if id == 0 {
if mcache0 == nil {
throw("missing mcache?")
}
pp.mcache = mcache0
} else {
pp.mcache = allocmcache()
}
}
...
lockInit(&pp.timersLock, lockRankTimers)
}
|
Here some P field values are initialised, such as set id, status, sudogcache, mcache, lock related.
The initialised sudogcache field stores the set of sudogs associated with the Channel.
The corresponding mcache is stored in each P, allowing for quick allocation of micro-objects and small objects.
Here’s how runtime.acquirep binds P to M.
runtime.acquirep
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func acquirep(_p_ *p) {
wirep(_p_)
...
}
func wirep(_p_ *p) {
_g_ := getg()
...
// 将 P 与 M 相互绑定
_g_.m.p.set(_p_)
_p_.m.set(_g_.m)
// 设置 P 状态为 _Prunning
_p_.status = _Prunning
}
|
This is a very simple method, so I won’t explain it. Here’s another look at runtime.pidleput putting P into the free list.
1
2
3
4
5
6
7
8
9
10
|
func pidleput(_p_ *p) {
// 如果 P 运行队列不为空,那么不能放入空闲列表
if !runqempty(_p_) {
throw("pidleput: P has non-empty run queue")
}
// 将 P 与 pidle 列表关联
_p_.link = sched.pidle
sched.pidle.set(_p_)
atomic.Xadd(&sched.npidle, 1) // TODO: fast atomic
}
|
G initialization
You can tell from the assembly that runtime-schedinit is executed after the execution of runtime.newproc which is the entry point for creating G.
runtime.newproc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
func newproc(siz int32, fn *funcval) {
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
// 获取当前的 G
gp := getg()
// 获取调用者的程序计数器 PC
pc := getcallerpc()
systemstack(func() {
// 获取新的 G 结构体
newg := newproc1(fn, argp, siz, gp, pc)
_p_ := getg().m.p.ptr()
// 将 G 加入到 P 的运行队列
runqput(_p_, newg, true)
// mainStarted 为 True 表示主M已经启动
if mainStarted {
// 唤醒新的 P 执行 G
wakep()
}
})
}
|
runtime.newproc gets the current G and the caller’s program counter, then calls newproc1 to get the new G structure; it then puts the G into the runnext field of P.
runtime.newproc1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) *g {
_g_ := getg()
if fn == nil {
_g_.m.throwing = -1 // do not dump full stacks
throw("go of nil func value")
}
// 加锁,禁止 G 的 M 被抢占
acquirem() // disable preemption because it can be holding p in a local var
siz := narg
siz = (siz + 7) &^ 7
_p_ := _g_.m.p.ptr()
// 从 P 的空闲列表 gFree 查找空闲 G
newg := gfget(_p_)
if newg == nil {
// 创建一个栈大小为 2K 大小的 G
newg = malg(_StackMin)
// CAS 改变 G 状态为 _Gdead
casgstatus(newg, _Gidle, _Gdead)
// 将 G 加入到全局 allgs 列表中
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
...
// 计算运行空间大小
totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frame
totalSize += -totalSize & (sys.SpAlign - 1) // align to spAlign
sp := newg.stack.hi - totalSize
spArg := sp
...
if narg > 0 {
// 从 argp 参数开始的位置,复制 narg 个字节到 spArg(参数拷贝)
memmove(unsafe.Pointer(spArg), argp, uintptr(narg))
...
}
// 清理、创建并初始化的 G
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
if _g_.m.curg != nil {
newg.labels = _g_.m.curg.labels
}
if isSystemGoroutine(newg, false) {
atomic.Xadd(&sched.ngsys, +1)
}
// 将 G 状态CAS为 _Grunnable 状态
casgstatus(newg, _Gdead, _Grunnable)
newg.goid = int64(_p_.goidcache)
_p_.goidcache++
...
// 释放锁,对应上面 acquirem
releasem(_g_.m)
return newg
}
|
The newproc1 function is rather long, so here is a summary of the main things it does.
- find a free G from P’s free list gFree.
- if G is not found, then call malg to create a new G. Note that _StackMin is 2048, meaning that the G created has a memory footprint of 2K on the stack. then CAS changes the G state to _Gdead and adds it to the global allgs list.
- initialise the SP of the execution stack and the entry location of the arguments according to the entry address and arguments of the function to be executed, and call memmove to make a copy of the arguments.
- clean up, create and initialize G, CAS the G state to _Grunnable and return.
Here’s how runtime.gfget looks up G.
runtime.gfget
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
func gfget(_p_ *p) *g {
retry:
// 如果 P 的空闲列表 gFree 为空,sched 的的空闲列表 gFree 不为空
if _p_.gFree.empty() && (!sched.gFree.stack.empty() || !sched.gFree.noStack.empty()) {
lock(&sched.gFree.lock)
// 从sched 的 gFree 列表中移动 32 个到 P 的 gFree 中
for _p_.gFree.n < 32 {
gp := sched.gFree.stack.pop()
if gp == nil {
gp = sched.gFree.noStack.pop()
if gp == nil {
break
}
}
sched.gFree.n--
_p_.gFree.push(gp)
_p_.gFree.n++
}
unlock(&sched.gFree.lock)
goto retry
}
// 此时如果 gFree 列表还是为空,返回空
gp := _p_.gFree.pop()
if gp == nil {
return nil
}
...
return gp
}
|
- transfer 32 Gs from the free list gFree held by sched to the current free list of P when P’s free list gFree is empty.
- a G is then returned from the head of P’s gFree list.
When newproc has finished running newproc1 it calls runtime.runqput to put G into the run list.
runtime.runqput
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
func runqput(_p_ *p, gp *g, next bool) {
if randomizeScheduler && next && fastrand()%2 == 0 {
next = false
}
if next {
retryNext:
// 将 G 放入到 runnext 中作为下一个处理器执行的任务
oldnext := _p_.runnext
if !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
goto retryNext
}
if oldnext == 0 {
return
}
// 将原来 runnext 的 G 放入到运行队列中
gp = oldnext.ptr()
}
retry:
h := atomic.LoadAcq(&_p_.runqhead)
t := _p_.runqtail
// 放入到 P 本地运行队列中
if t-h < uint32(len(_p_.runq)) {
_p_.runq[t%uint32(len(_p_.runq))].set(gp)
atomic.StoreRel(&_p_.runqtail, t+1)
return
}
// P 本地队列放不下了,放入到全局的运行队列中
if runqputslow(_p_, gp, h, t) {
return
}
goto retry
}
|
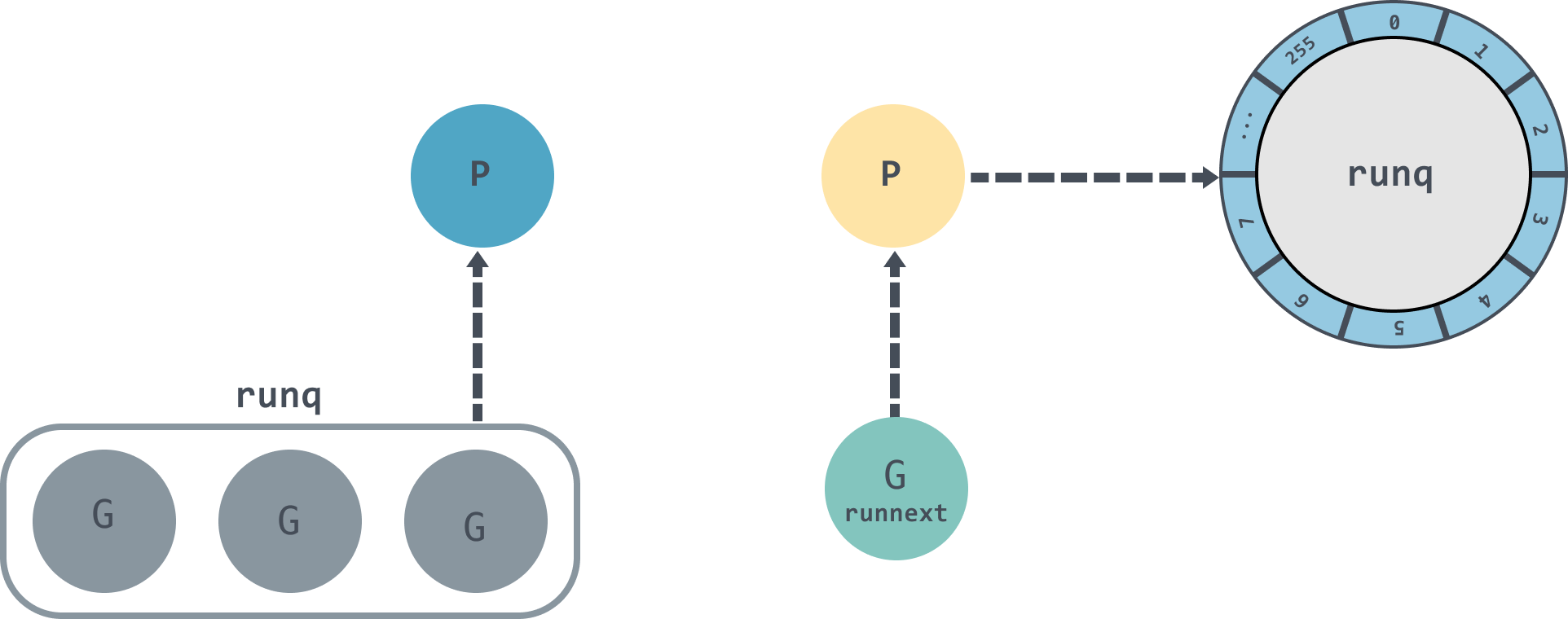
runtime.runqput will determine whether to put G into runnext based on next.- if next is false, it will try to put the incoming G into the local queue, which is a circular chain of size 256, and call
runqputslow to put G into the global queue of runq if it doesn’t fit.
Scheduling loop
We continue back in runtime-rt0_go, where runtime-mstart is called to start scheduling G after the initialization work is done.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
TEXT runtime·rt0_go(SB),NOSPLIT,$0
...
// 初始化执行文件的绝对路径
CALL runtime·args(SB)
// 初始化 CPU 个数和内存页大小
CALL runtime·osinit(SB)
// 调度器初始化
CALL runtime·schedinit(SB)
// 创建一个新的 goroutine 来启动程序
MOVQ $runtime·mainPC(SB), AX // entry
// 新建一个 goroutine,该 goroutine 绑定 runtime.main
CALL runtime·newproc(SB)
// 启动M,开始调度goroutine
CALL runtime·mstart(SB)
...
|
runtime-mstart will be called to runtime-mstart1 which will initialize M0 and call runtime.schedule to enter the scheduling loop.

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
func mstart1() {
_g_ := getg()
if _g_ != _g_.m.g0 {
throw("bad runtime·mstart")
}
// 一旦调用 schedule 就不会返回,所以需要保存一下栈帧
save(getcallerpc(), getcallersp())
asminit()
minit()
// 设置信号 handler
if _g_.m == &m0 {
mstartm0()
}
// 执行启动函数
if fn := _g_.m.mstartfn; fn != nil {
fn()
}
// 如果当前 m 并非 m0,则要求绑定 p
if _g_.m != &m0 {
acquirep(_g_.m.nextp.ptr())
_g_.m.nextp = 0
}
// 开始调度
schedule()
}
|
After mstart1 saves the scheduling information, it calls schedule to enter the scheduling loop, looking for an executable G and executing it. Here’s a look at the schedule execution function.
schedule
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
func schedule() {
_g_ := getg()
if _g_.m.locks != 0 {
throw("schedule: holding locks")
}
...
top:
pp := _g_.m.p.ptr()
pp.preempt = false
// GC 等待
if sched.gcwaiting != 0 {
gcstopm()
goto top
}
// 不等于0,说明在安全点
if pp.runSafePointFn != 0 {
runSafePointFn()
}
// 如果在 spinning ,那么运行队列应该为空,
if _g_.m.spinning && (pp.runnext != 0 || pp.runqhead != pp.runqtail) {
throw("schedule: spinning with local work")
}
// 运行 P 上准备就绪的 Timer
checkTimers(pp, 0)
var gp *g
var inheritTime bool
...
if gp == nil {
// 为了公平,每调用 schedule 函数 61 次就要从全局可运行 G 队列中获取
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
// 从全局队列获取1个 G
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
// 从 P 本地获取 G 任务
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
}
// 运行到这里表示从本地运行队列和全局运行队列都没有找到需要运行的 G
if gp == nil {
// 阻塞地查找可用 G
gp, inheritTime = findrunnable() // blocks until work is available
}
...
// 执行 G 任务函数
execute(gp, inheritTime)
}
|
In this function, we are only concerned with the scheduling-related code. From the above code we can see that the main directions to find available G are as follows.
- to ensure fairness, by modulo 61 for schedtick when there is a pending G in the global run queue, meaning that every 61 times the scheduler will try to get a pending G from the global queue to run.
- calling runqget to find the G to be executed from P’s local run queue.
- if no G is found in the first two methods, the findrunnable function is used to “steal” some G from other P’s to execute, and if it does not, it blocks until a runnable G is available.
Global queue for G
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
func globrunqget(_p_ *p, max int32) *g {
// 如果全局队列中没有 G 直接返回
if sched.runqsize == 0 {
return nil
}
// 计算 n 的个数
n := sched.runqsize/gomaxprocs + 1
if n > sched.runqsize {
n = sched.runqsize
}
// n 的最大个数
if max > 0 && n > max {
n = max
}
if n > int32(len(_p_.runq))/2 {
n = int32(len(_p_.runq)) / 2
}
sched.runqsize -= n
// 拿到全局队列队头 G
gp := sched.runq.pop()
n--
// 将其余 n-1 个 G 从全局队列放入本地队列
for ; n > 0; n-- {
gp1 := sched.runq.pop()
runqput(_p_, gp1, false)
}
return gp
}
|
globrunqget will fetch n Gs from the global runq queue, with the first G used for execution and n-1 Gs from the global queue into the local queue.
local queue fetch G
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
func runqget(_p_ *p) (gp *g, inheritTime bool) {
// 如果 runnext 不为空,直接获取返回
for {
next := _p_.runnext
if next == 0 {
break
}
if _p_.runnext.cas(next, 0) {
return next.ptr(), true
}
}
// 从本地队列头指针遍历本地队列
for {
h := atomic.LoadAcq(&_p_.runqhead)
t := _p_.runqtail
// 表示本地队列为空
if t == h {
return nil, false
}
gp := _p_.runq[h%uint32(len(_p_.runq))].ptr()
if atomic.CasRel(&_p_.runqhead, h, h+1) { // cas-release, commits consume
return gp, false
}
}
}
|
The local queue is fetched from the runnext field of P first, and returned directly if it is not empty. If runnext is empty, then the local queue is traversed from the local queue head pointer, which is a circular queue for ease of reuse.
taskstealing G
The task stealing method findrunnable is very complex, 300 lines long, so let’s take our time and analyse it.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
|
func findrunnable() (gp *g, inheritTime bool) {
_g_ := getg()
top:
_p_ := _g_.m.p.ptr()
// 如果在 GC,则休眠当前 M,直到复始后回到 top
if sched.gcwaiting != 0 {
gcstopm()
goto top
}
// 运行到安全点
if _p_.runSafePointFn != 0 {
runSafePointFn()
}
now, pollUntil, _ := checkTimers(_p_, 0)
...
// 从本地 P 的可运行队列获取 G
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}
// 从全局的可运行队列获取 G
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false
}
}
// 从I/O轮询器获取 G
if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 {
// 尝试从netpoller获取Glist
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
//将其余队列放入 P 的可运行G队列
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
}
...
if !_g_.m.spinning {
// 设置 spinning ,表示正在窃取 G
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
// 开始窃取
for i := 0; i < 4; i++ {
for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() {
if sched.gcwaiting != 0 {
goto top
}
// 如果 i>2 表示如果其他 P 运行队列中没有 G ,将要从其他队列的 runnext 中获取
stealRunNextG := i > 2 // first look for ready queues with more than 1 g
// 随机获取一个 P
p2 := allp[enum.position()]
if _p_ == p2 {
continue
}
// 从其他 P 的运行队列中获取一般的 G 到当前队列中
if gp := runqsteal(_p_, p2, stealRunNextG); gp != nil {
return gp, false
}
// 如果运行队列中没有 G,那么从 timers 中获取可执行的定时器
if i > 2 || (i > 1 && shouldStealTimers(p2)) {
tnow, w, ran := checkTimers(p2, now)
now = tnow
if w != 0 && (pollUntil == 0 || w < pollUntil) {
pollUntil = w
}
if ran {
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}
ranTimer = true
}
}
}
}
if ranTimer {
goto top
}
stop:
// 处于 GC 阶段的话,获取执行GC标记任务的G
if gcBlackenEnabled != 0 && _p_.gcBgMarkWorker != 0 && gcMarkWorkAvailable(_p_) {
_p_.gcMarkWorkerMode = gcMarkWorkerIdleMode
gp := _p_.gcBgMarkWorker.ptr()
//将本地 P 的 GC 标记专用 G 职位 Grunnable
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
...
// 放弃当前的 P 之前,对 allp 做一个快照
allpSnapshot := allp
// return P and block
lock(&sched.lock)
// 进入了 gc,回到顶部并阻塞
if sched.gcwaiting != 0 || _p_.runSafePointFn != 0 {
unlock(&sched.lock)
goto top
}
// 全局队列中又发现了任务
if sched.runqsize != 0 {
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
return gp, false
}
if releasep() != _p_ {
throw("findrunnable: wrong p")
}
// 将 p 放入 idle 空闲链表
pidleput(_p_)
unlock(&sched.lock)
wasSpinning := _g_.m.spinning
if _g_.m.spinning {
// M 即将睡眠,状态不再是 spinning
_g_.m.spinning = false
if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {
throw("findrunnable: negative nmspinning")
}
}
// 休眠之前再次检查全局 P 列表
//遍历全局 P 列表的 P,并检查他们的可运行G队列
for _, _p_ := range allpSnapshot {
// 如果这时本地队列不空
if !runqempty(_p_) {
lock(&sched.lock)
// 重新获取 P
_p_ = pidleget()
unlock(&sched.lock)
if _p_ != nil {
// M 绑定 P
acquirep(_p_)
if wasSpinning {
// spinning 重新切换为 true
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
// 这时候是有 work 的,回到顶部寻找 G
goto top
}
break
}
}
// 休眠前再次检查 GC work
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(nil) {
lock(&sched.lock)
_p_ = pidleget()
if _p_ != nil && _p_.gcBgMarkWorker == 0 {
pidleput(_p_)
_p_ = nil
}
unlock(&sched.lock)
if _p_ != nil {
acquirep(_p_)
if wasSpinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
// Go back to idle GC check.
goto stop
}
}
// poll network
// 休眠前再次检查 poll 网络
if netpollinited() && (atomic.Load(&netpollWaiters) > 0 || pollUntil != 0) && atomic.Xchg64(&sched.lastpoll, 0) != 0 {
...
lock(&sched.lock)
_p_ = pidleget()
unlock(&sched.lock)
if _p_ == nil {
injectglist(&list)
} else {
acquirep(_p_)
if !list.empty() {
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
if wasSpinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
goto top
}
} else if pollUntil != 0 && netpollinited() {
pollerPollUntil := int64(atomic.Load64(&sched.pollUntil))
if pollerPollUntil == 0 || pollerPollUntil > pollUntil {
netpollBreak()
}
}
// 休眠当前 M
stopm()
goto top
}
|
This function requires some attention to the spin state (spinning) of the worker thread M. The state of a worker thread when it is stealing G from the local run queue of other worker threads is called the spin state.
Here we look at what findrunnable does.
- first check to see if a GC is in progress, and if so, suspend the current M and block to hibernate.
- look for G in the local run queue, the global run queue
- find if there is a G waiting to run from the network poller.
- Setting spinning to true indicates the start of stealing G. The stealing process uses two nested for loops; the inner loop iterates through allp to see if there is a G in its run queue, and if so, takes half of it to the current worker’s run queue and returns it from findrunnable, and if not, continues to iterate through the next P. Note that the traversal of allp starts with a P at a random position, preventing the elements in allp from being accessed in the same order each time it is traversed.
- all possibilities have been tried and an additional check is made before preparing to hibernate M .
- first check if it is the GC mark phase at this point and, if so, return directly to G in the mark phase.
- checking the global P list again before hibernating, iterating through the P’s of the global P list and checking their runnable G queues.
- check again for the presence of a GC mark G. If so, fetch the P and return to the first step and re-execute the steal.
- check again for the presence of a G in the poll network, and if so, return directly.
- if nothing is found, then hibernate the current M
Task execution
schedule has run to this point to indicate that it has finally found a G that it can run.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func execute(gp *g, inheritTime bool) {
_g_ := getg()
// 将 G 绑定到当前 M 上
_g_.m.curg = gp
gp.m = _g_.m
// 将 g 正式切换为 _Grunning 状态
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
// 抢占信号
gp.preempt = false
gp.stackguard0 = gp.stack.lo + _StackGuard
if !inheritTime {
// 调度器调度次数增加 1
_g_.m.p.ptr().schedtick++
}
...
// gogo 完成从 g0 到 gp 真正的切换
gogo(&gp.sched)
}
|
When execution of execute begins, G is switched to the _Grunning state and M is bound to G. Eventually, runtime.gogo is called to start execution.
The program counter of runtime.goexit and the program counter of the function to be executed are retrieved from runtime.gobuf in runtime.gogo, then jumped to runtime.goexit and executed.
1
2
3
4
5
6
7
|
TEXT runtime·goexit(SB),NOSPLIT,$0-0
CALL runtime·goexit1(SB)
func goexit1() {
// 调用goexit0函数
mcall(goexit0)
}
|
goexit1 completes the call to goexit0 via mcall.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
func goexit0(gp *g) {
_g_ := getg()
// 设置当前 G 状态为 _Gdead
casgstatus(gp, _Grunning, _Gdead)
// 清理 G
gp.m = nil
...
gp.writebuf = nil
gp.waitreason = 0
gp.param = nil
gp.labels = nil
gp.timer = nil
// 解绑 M 和 G
dropg()
...
// 将 G 扔进 gfree 链表中等待复用
gfput(_g_.m.p.ptr(), gp)
// 再次进行调度
schedule()
}
|
goexit0 resets G, unties M from G, and puts it in the gfree table to wait for other go statements to create a new g. At the end, goexit0 re-calls schedule to trigger a new round of scheduling.

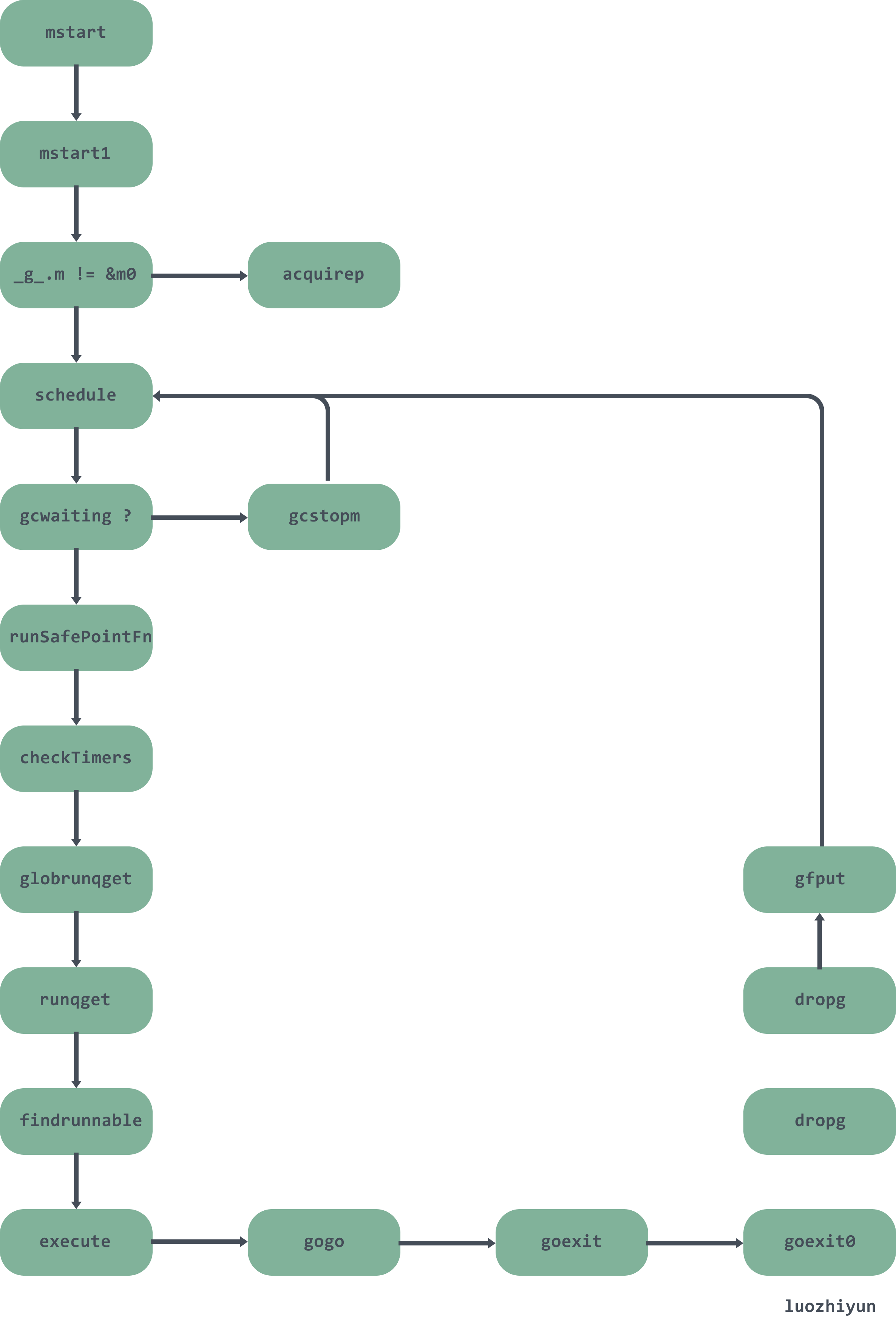
Summary
The following is a diagram that roughly summarizes the scheduling process.