Introduction
Version 1.13 timers
Go uses 64 minimal heaps until version 1.14. All timers created at runtime are added to the minimal heap, and timers created by each processor (P) are maintained by the corresponding minimal heap.
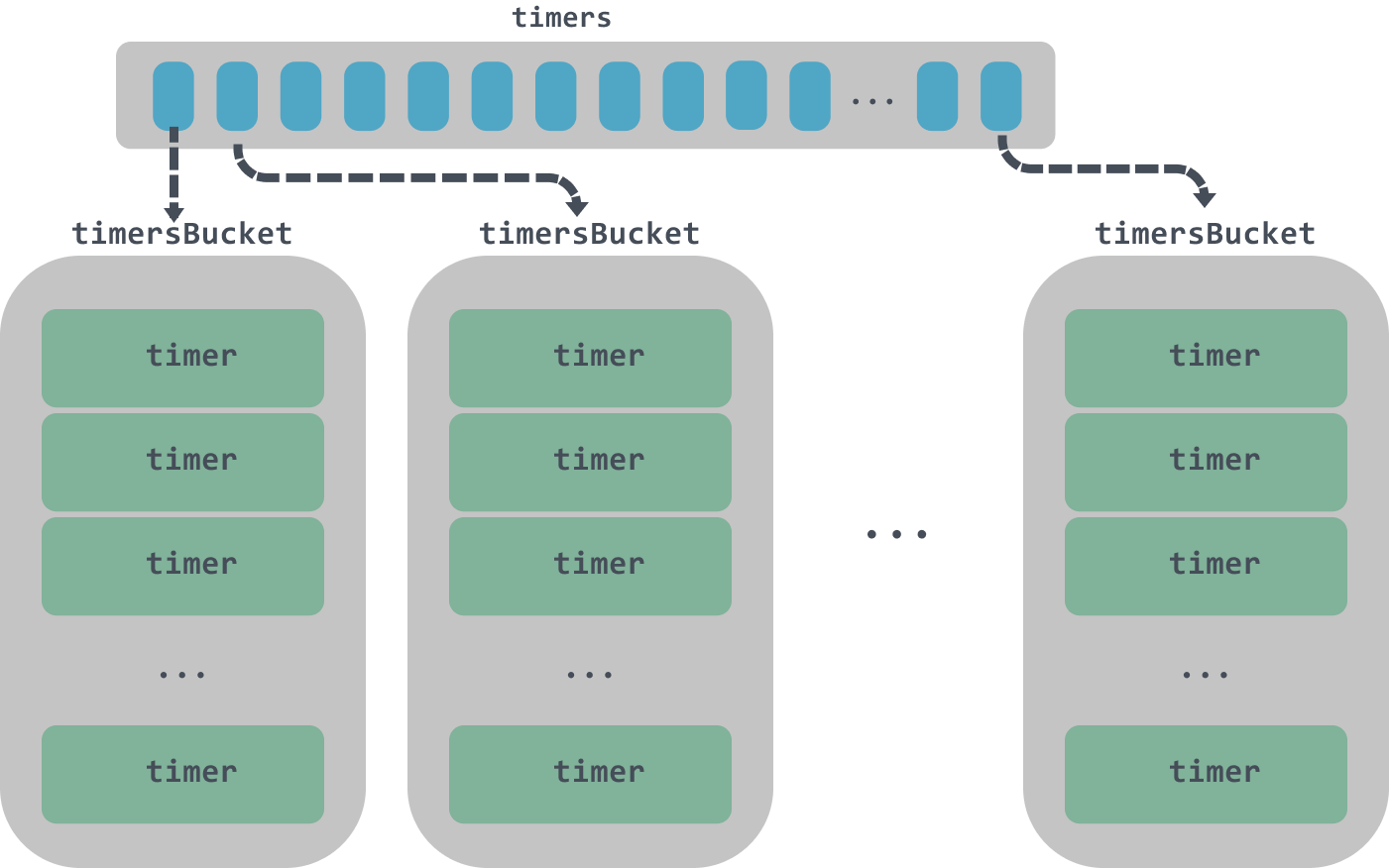
The following is the source code for version 1.13 of runtime.time.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
const timersLen = 64
var timers [timersLen]struct {
timersBucket
// padding, 防止false sharing
pad [sys.CacheLineSize - unsafe.Sizeof(timersBucket{})%sys.CacheLineSize]byte
}
// 获取 P 对应的 Bucket
func (t *timer) assignBucket() *timersBucket {
id := uint8(getg().m.p.ptr().id) % timersLen
t.tb = &timers[id].timersBucket
return t.tb
}
type timersBucket struct {
lock mutex
gp *g
created bool
sleeping bool
rescheduling bool
sleepUntil int64
waitnote note
// timer 列表
t []*timer
}
|
As you can see from the assignBucket method above, if the number of processors P on the current machine exceeds 64, timers on multiple processors may be stored in the same bucket timersBucket.
Each bucket is responsible for managing a bunch of these ordered timers, and each bucket has a corresponding timerproc asynchronous task that is responsible for constantly scheduling these timers.
The timerproc continuously fetches the top element from the timersBucket, executes if the timer at the top of the heap is due, sleep if no task is due, and calls gopark to hang until a new timer has been added to the bucket.
timerproc calls notetsleepg when it sleeps, which in turn raises an entersyscallblock call, which actively calls handoffp to unbind M and P. When the next timer time comes, M and P are bound again, and the frequent context switching between processor P and thread M is one of the timer’s The frequent context switches between processor P and thread M are also one of the main performance impact factors of the timer.
Changes to the timer since 1.14
In Go after version 1.14 the timersBucket has been removed and all timers are stored in P as a minimal quadruple heap.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
type p struct {
...
// 互斥锁
timersLock mutex
// 存储计时器的最小四叉堆
timers []*timer
// 计时器数量
numTimers uint32
// 处于 timerModifiedEarlier 状态的计时器数量
adjustTimers uint32
// 处于 timerDeleted 状态的计时器数量
deletedTimers uint32
...
}
|
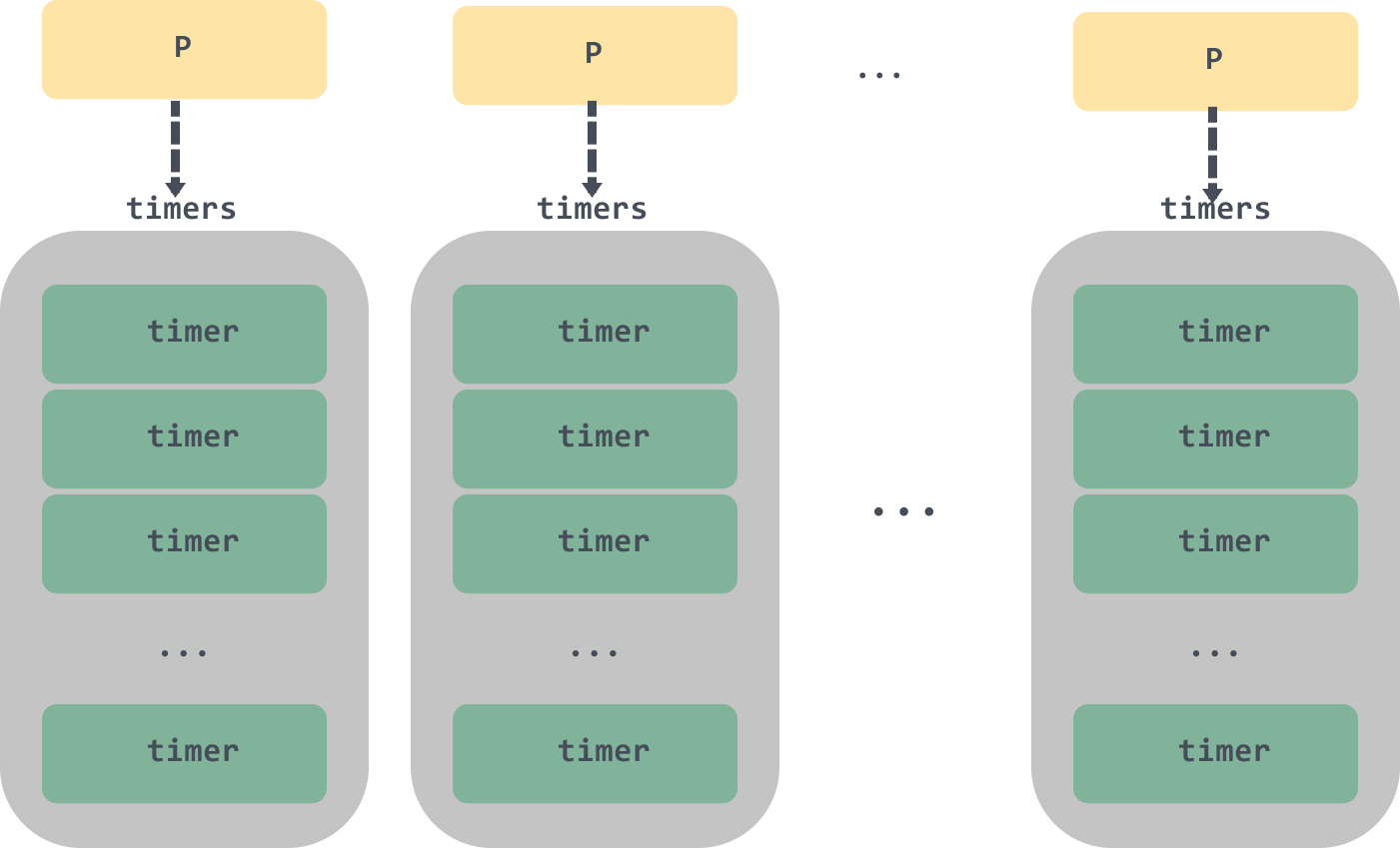
The timer is no longer scheduled using timerproc asynchronous tasks, but is instead triggered by a scheduling loop or system monitor scheduling, reducing the performance loss associated with context switching between threads and allowing the timer to be executed more promptly by using the netpoll blocking wakeup mechanism.
Use of timer
The time.Timer timer must be created using the time.NewTimer, time.AfterFunc or `time.
NewTimer as follows:
The timer field C allows us to know when the timer is due in time. C is a buffered channel of type chan time. Once the expiry time is hit, the timer will send an element of type time.
1
2
3
4
5
6
7
8
9
10
|
func main() {
//初始化定时器
t := time.NewTimer(2 * time.Second)
//当前时间
now := time.Now()
fmt.Printf("Now time : %v.\n", now)
expire := <- t.C
fmt.Printf("Expiration time: %v.\n", expire)
}
|
time.After is generally used in conjunction with select.
1
2
3
4
5
6
7
8
9
10
|
func main() {
ch1 := make(chan int, 1)
select {
case e1 := <-ch1:
//如果ch1通道成功读取数据,则执行该case处理语句
fmt.Printf("1th case is selected. e1=%v",e1)
case <- time.After(2 * time.Second):
fmt.Println("Timed out")
}
}
|
time.Afterfunc can execute a function after the set time has elapsed.
1
2
3
4
5
6
7
|
func main() {
f := func(){
fmt.Printf("Expiration time : %v.\n", time.Now())
}
time.AfterFunc(1*time.Second, f)
time.Sleep(2 * time.Second)
}
|
Analysis
Initialising the &Timer structure
Let’s start by looking at how the NewTimer method creates a Timer.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
type Timer struct {
C <-chan Time
r runtimeTimer
}
func NewTimer(d Duration) *Timer {
// 初始化一个channel,用于返回
c := make(chan Time, 1)
t := &Timer{
C: c,
r: runtimeTimer{
when: when(d),
f: sendTime,
arg: c,
},
}
// 调用runtime.time的startTimer方法
startTimer(&t.r)
return t
}
func startTimer(*runtimeTimer)
|
The NewTimer method essentially initializes a Timer, then calls the startTimer method and returns the Timer. the real logic of the startTimer method is not in the time package and we can use the assembly code to debug it using dlv as mentioned in the previous section.
1
|
sleep.go:94 0xd8ea09 e872c7faff call $time.startTimer
|
We know that startTimer actually calls the runtime.time.startTimer method. This means that time.Timer is just a layer of wrap on the timer in the runtime package, and the core functionality of this layer itself is to convert the underlying timeout callback to send a channel message.
Let’s look at runtime.startTimer.
1
2
3
4
|
func startTimer(t *timer) {
...
addtimer(t)
}
|
The startTimer method will turn the passed in runtimeTimer into a timer and then call the addtimer method.
In the NewTimer method a runtimeTimer structure is initialised, which is actually passed into the startTimer method as a timer structure in runtime.time, so here’s a look at timer.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
type timer struct {
// 对应处理器P的指针
pp puintptr
// 定时器被唤醒的时间
when int64
// 唤醒的间隔时间
period int64
// 唤醒时被调用的函数
f func(interface{}, uintptr)
// 被调用的函数的参数
arg interface{}
seq uintptr
// 处于timerModifiedXX状态时用于设置when字段
nextwhen int64
// 定时器的状态
status uint32
}
|
In addition to this, the timer has a number of flag bits to indicate status.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
const (
// 初始化状态
timerNoStatus = iota
// 等待被调用
// timer 已在 P 的列表中
timerWaiting
// 表示 timer 在运行中
timerRunning
// timer 已被删除
timerDeleted
// timer 正在被移除
timerRemoving
// timer 已被移除,并停止运行
timerRemoved
// timer 被修改了
timerModifying
// 被修改到了更早的时间
timerModifiedEarlier
// 被修改到了更晚的时间
timerModifiedLater
// 已经被修改,并且正在被移动
timerMoving
)
|
addtimer Add timer
runtime.addtimer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
func addtimer(t *timer) {
// 定时器被唤醒的时间的时间不能为负数
if t.when < 0 {
t.when = maxWhen
}
// 状态必须为初始化
if t.status != timerNoStatus {
throw("addtimer called with initialized timer")
}
// 设置为等待调度
t.status = timerWaiting
when := t.when
// 获取当前 P
pp := getg().m.p.ptr()
lock(&pp.timersLock)
// 清理 P 的 timer 列表头中的 timer
cleantimers(pp)
// 将 timer 加入到 P 的最小堆中
doaddtimer(pp, t)
unlock(&pp.timersLock)
// 唤醒 netpoller 中休眠的线程
wakeNetPoller(when)
}
|
- addtimer checks the time when the timer is woken up and that the status must be the newly initialized timer.
- cleantimers are then called to clean up the head node of the corresponding timer list in P after the lock has been added, and doaddtimer is called to add the timer to the smallest heap of P and release the lock.
- wakeNetPoller is called to wake up a dormant thread in the netpoller.
Here is a look at the implementation of each of the important functions in addtimer.
runtime.cleantimers
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
func cleantimers(pp *p) {
gp := getg()
for {
// 调度器列表为空,直接返回
if len(pp.timers) == 0 {
return
}
// 如果当前 G 被抢占了,直接返回
if gp.preemptStop {
return
}
// 获取第一个 timer
t := pp.timers[0]
if t.pp.ptr() != pp {
throw("cleantimers: bad p")
}
switch s := atomic.Load(&t.status); s {
case timerDeleted:
// 设置 timer 的状态
if !atomic.Cas(&t.status, s, timerRemoving) {
continue
}
// 删除第一个 timer
dodeltimer0(pp)
// 删除完毕后重置状态为 timerRemoved
if !atomic.Cas(&t.status, timerRemoving, timerRemoved) {
badTimer()
}
atomic.Xadd(&pp.deletedTimers, -1)
// timer 被修改到了更早或更晚的时间
case timerModifiedEarlier, timerModifiedLater:
// 将 timer 状态设置为 timerMoving
if !atomic.Cas(&t.status, s, timerMoving) {
continue
}
// 重新设置 when 字段
t.when = t.nextwhen
// 在列表中删除后重新加入
dodeltimer0(pp)
doaddtimer(pp, t)
if s == timerModifiedEarlier {
atomic.Xadd(&pp.adjustTimers, -1)
}
// 设置状态为 timerWaiting
if !atomic.Cas(&t.status, timerMoving, timerWaiting) {
badTimer()
}
default:
return
}
}
}
|
The cleantimers function uses an infinite loop to fetch the header node. If the status of the header node is timerDeleted, then it needs to be removed from the timer list; if the status of the header node is timerModifiedEarlier or timerModifiedLater, which means that the trigger time of the header node has been modified to an earlier or later time, then it will be removed from the timer queue before being re-added. Add.
runtime.doaddtimer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
func doaddtimer(pp *p, t *timer) {
// Timers 依赖于 netpoller
// 所以如果 netpoller 没有启动,需要启动一下
if netpollInited == 0 {
netpollGenericInit()
}
// 校验是否早已在 timer 列表中
if t.pp != 0 {
throw("doaddtimer: P already set in timer")
}
// 设置 timer 与 P 的关联
t.pp.set(pp)
i := len(pp.timers)
// 将 timer 加入到 P 的 timer 列表中
pp.timers = append(pp.timers, t)
// 维护 timer 在 最小堆中的位置
siftupTimer(pp.timers, i)
// 如果 timer 是列表中头节点,需要设置一下 timer0When
if t == pp.timers[0] {
atomic.Store64(&pp.timer0When, uint64(t.when))
}
atomic.Xadd(&pp.numTimers, 1)
}
|
The doaddtimer function is actually quite simple, it mainly sets the timer to be associated with P, adds the timer to P’s timer list, and maintains the order of the timer list’s minimum heap.
runtime.wakeNetPoller
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
func wakeNetPoller(when int64) {
if atomic.Load64(&sched.lastpoll) == 0 {
pollerPollUntil := int64(atomic.Load64(&sched.pollUntil))
// 如果计时器的触发时间小于netpoller的下一次轮询时间
if pollerPollUntil == 0 || pollerPollUntil > when {
// 向netpollBreakWr里面写入数据,立即中断netpoll
netpollBreak()
}
}
}
func netpollBreak() {
if atomic.Cas(&netpollWakeSig, 0, 1) {
for {
var b byte
// 向 netpollBreakWr 里面写入数据
n := write(netpollBreakWr, unsafe.Pointer(&b), 1)
if n == 1 {
break
}
if n == -_EINTR {
continue
}
if n == -_EAGAIN {
return
}
println("runtime: netpollBreak write failed with", -n)
throw("runtime: netpollBreak write failed")
}
}
}
|
If it is less than the next polling time of the netpoller, the netpollBreak is called to write data to netpollBreakWr, which immediately interrupts the netpoll.
stopTimer terminates the timer
The logic for stopping a timer is primarily a change in the timer’s state.
If the timer is in timerWaiting or timerModifiedLater or timerModifiedEarlier.
- timerModifying -> timerDeleted
If the timer is in another state:
- Pending state change or just return
So instead of deleting the timer during termination, it marks a state and waits to be deleted.
modTimer modifying timer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
func modtimer(t *timer, when, period int64, f func(interface{}, uintptr), arg interface{}, seq uintptr) bool {
if when < 0 {
when = maxWhen
}
status := uint32(timerNoStatus)
wasRemoved := false
var pending bool
var mp *m
loop:
for {
// 修改 timer 状态
switch status = atomic.Load(&t.status); status {
...
}
t.period = period
t.f = f
t.arg = arg
t.seq = seq
// 如果 timer 已被删除,那么需要重新添加到 timer 列表中
if wasRemoved {
t.when = when
pp := getg().m.p.ptr()
lock(&pp.timersLock)
doaddtimer(pp, t)
unlock(&pp.timersLock)
if !atomic.Cas(&t.status, timerModifying, timerWaiting) {
badTimer()
}
releasem(mp)
wakeNetPoller(when)
} else {
t.nextwhen = when
newStatus := uint32(timerModifiedLater)
// 如果修改后的时间小于修改前的时间,将状态设置为 timerModifiedEarlier
if when < t.when {
newStatus = timerModifiedEarlier
}
...
if !atomic.Cas(&t.status, timerModifying, newStatus) {
badTimer()
}
releasem(mp)
// 如果修改时间提前,那么触发 netpoll 中断
if newStatus == timerModifiedEarlier {
wakeNetPoller(when)
}
}
return pending
}
|
modtimer enters the for loop and does the state setting and necessary fields depending on the state; if the timer has been deleted, it needs to be re-added to the timer list; if the timer is modified for a time less than the time before the modification, set the state to timerModifiedEarlier, modify the time earlier and also trigger a netpoll interrupt.
Running a timer
After talking about how to add timers, let’s look at how timers are run. timers are run by the runtime.runtimer function, which checks the state of the timer at the top of the smallest heap on P and does different things depending on the state.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
func runtimer(pp *p, now int64) int64 {
for {
// 获取最小堆的第一个元素
t := pp.timers[0]
if t.pp.ptr() != pp {
throw("runtimer: bad p")
}
// 获取 timer 状态
switch s := atomic.Load(&t.status); s {
// timerWaiting
case timerWaiting:
// 还没到时间,返回下次执行时间
if t.when > now {
// Not ready to run.
return t.when
}
// 修改状态为 timerRunning
if !atomic.Cas(&t.status, s, timerRunning) {
continue
}
// 运行该 timer
runOneTimer(pp, t, now)
return 0
// timerDeleted
case timerDeleted:
if !atomic.Cas(&t.status, s, timerRemoving) {
continue
}
// 删除最小堆的第一个 timer
dodeltimer0(pp)
if !atomic.Cas(&t.status, timerRemoving, timerRemoved) {
badTimer()
}
atomic.Xadd(&pp.deletedTimers, -1)
if len(pp.timers) == 0 {
return -1
}
// 需要重新移动位置的 timer
case timerModifiedEarlier, timerModifiedLater:
if !atomic.Cas(&t.status, s, timerMoving) {
continue
}
t.when = t.nextwhen
// 删除最小堆的第一个 timer
dodeltimer0(pp)
// 将该 timer 重新添加到最小堆
doaddtimer(pp, t)
if s == timerModifiedEarlier {
atomic.Xadd(&pp.adjustTimers, -1)
}
if !atomic.Cas(&t.status, timerMoving, timerWaiting) {
badTimer()
}
case timerModifying:
osyield()
case timerNoStatus, timerRemoved:
badTimer()
case timerRunning, timerRemoving, timerMoving:
badTimer()
default:
badTimer()
}
}
}
|
Inside runtimer a for loop is started that keeps checking the status of the first element of P’s timer list.
- If the timer is in timerWaiting, then it is determined that the current time is greater than the time for the timer to execute, and runOneTimer is called.
- If the timer is timerDeleted, which means that the timer needs to be deleted, then call dodeltimer0 to delete the first timer in the smallest heap and change its state; * If the timer state is timerDeleted, which means that the timer needs to be deleted
- If the timer state is timerModifiedEarlier, timerModifiedLater, then the execution time of the timer has been modified and it needs to be repositioned in the minimal heap, so call dodeltimer0 to delete the timer first and then call doaddtimer to add the timer back to the minimal heap.
runtime.runOneTimer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
func runOneTimer(pp *p, t *timer, now int64) {
...
// 需要被执行的函数
f := t.f
// 被执行函数的参数
arg := t.arg
seq := t.seq
// 表示该 timer 为 ticker,需要再次触发
if t.period > 0 {
// 放入堆中并调整触发时间
delta := t.when - now
t.when += t.period * (1 + -delta/t.period)
siftdownTimer(pp.timers, 0)
if !atomic.Cas(&t.status, timerRunning, timerWaiting) {
badTimer()
}
updateTimer0When(pp)
// 一次性 timer
} else {
// 删除该 timer.
dodeltimer0(pp)
if !atomic.Cas(&t.status, timerRunning, timerNoStatus) {
badTimer()
}
}
unlock(&pp.timersLock)
// 运行该函数
f(arg, seq)
lock(&pp.timersLock)
...
}
|
runOneTimer determines whether the timer needs to be executed repeatedly based on whether the period is greater than 0. If so, it needs to be readjusted when the next execution time is and then the timer is readjusted in the heap. If a one-time timer is executed, dodeltimer0 is executed to delete the timer and the function in the timer is run last.
Timer triggering
Here’s what I find interesting, timers are triggered in two ways.
- triggered directly from the scheduling loop.
- The other is triggered at regular intervals by the Go language’s backend system monitor.
scheduling loop triggers
The entire scheduling loop has three places to check for an executable timer.
- when
runtime.schedule is called to execute the schedule.
- when
runtime.findrunnable is called to get an executable function.
- when
runtime.findrunnable is called to perform preemption.
runtime.schedule
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
func schedule() {
_g_ := getg()
...
top:
pp := _g_.m.p.ptr()
...
// 检查是否有可执行 timer 并执行
checkTimers(pp, 0)
var gp *g
...
if gp == nil {
gp, inheritTime = findrunnable() // blocks until work is available
}
...
execute(gp, inheritTime)
}
|
Here’s a look at what checkTimers does.
runtime.checkTimers
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
func checkTimers(pp *p, now int64) (rnow, pollUntil int64, ran bool) {
// 如果没有需要调整的 timer
if atomic.Load(&pp.adjustTimers) == 0 {
// 获取 timer0 的执行时间
next := int64(atomic.Load64(&pp.timer0When))
if next == 0 {
return now, 0, false
}
if now == 0 {
now = nanotime()
}
// 下次执行大于当前时间,
if now < next {
// 需要删除的 timer 个数小于 timer列表个数的4分之1,直接返回
if pp != getg().m.p.ptr() || int(atomic.Load(&pp.deletedTimers)) <= int(atomic.Load(&pp.numTimers)/4) {
return now, next, false
}
}
}
lock(&pp.timersLock)
// 进行调整 timer
adjusttimers(pp)
rnow = now
if len(pp.timers) > 0 {
if rnow == 0 {
rnow = nanotime()
}
for len(pp.timers) > 0 {
// 查找堆中是否存在需要执行的 timer
if tw := runtimer(pp, rnow); tw != 0 {
if tw > 0 {
pollUntil = tw
}
break
}
ran = true
}
}
// 如果需要删除的 timer 超过了 timer 列表数量的四分之一,那么清理需要删除的 timer
if pp == getg().m.p.ptr() && int(atomic.Load(&pp.deletedTimers)) > len(pp.timers)/4 {
clearDeletedTimers(pp)
}
unlock(&pp.timersLock)
return rnow, pollUntil, ran
}
|
The checkTimers do several things.
- checks to see if there are any timers that need to be adjusted, and returns directly if there are no timers to be executed, or if the next timer to be executed is not due and there are fewer timers to be deleted (a quarter).
- call adjusttimers to adjust the timer list, mainly to maintain the order of the minimum heap of timers in the timer list.
- calling
runtime.runtimer to find out if there is a timer in the heap that needs to be executed, runtime.runtimer has already been described above and will not be repeated here.
- if the current P of the Goroutine is the same as the incoming P and the timers to be deleted are more than a quarter of the number of timers in the timer list, then call clearDeletedTimers to clear the timers to be deleted.
runtime.findrunnable
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
|
func findrunnable() (gp *g, inheritTime bool) {
_g_ := getg()
top:
_p_ := _g_.m.p.ptr()
...
// 检查 P 中可执行的 timer
now, pollUntil, _ := checkTimers(_p_, 0)
...
// 如果 netpoll 已被初始化,并且 Waiters 大于零,并且 lastpoll 不为0
if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 {
// 尝试从netpoller获取Glist
if list := netpoll(0); !list.empty() { // 无阻塞
gp := list.pop()
//将其余队列放入 P 的可运行G队列
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
}
...
// 开始窃取
for i := 0; i < 4; i++ {
for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() {
if sched.gcwaiting != 0 {
goto top
}
// 如果 i>2 表示如果其他 P 运行队列中没有 G ,将要从其他队列的 runnext 中获取
stealRunNextG := i > 2 // first look for ready queues with more than 1 g
// 随机获取一个 P
p2 := allp[enum.position()]
if _p_ == p2 {
continue
}
// 从其他 P 的运行队列中获取一般的 G 到当前队列中
if gp := runqsteal(_p_, p2, stealRunNextG); gp != nil {
return gp, false
}
// 如果运行队列中没有 G,那么从 timers 中获取可执行的 timer
if i > 2 || (i > 1 && shouldStealTimers(p2)) {
// ran 为 true 表示有执行过 timer
tnow, w, ran := checkTimers(p2, now)
now = tnow
if w != 0 && (pollUntil == 0 || w < pollUntil) {
pollUntil = w
}
if ran {
// 因为已经运行过 timer 了,说不定已经有准备就绪的 G 了
// 再次检查本地队列尝试获取 G
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}
ranTimer = true
}
}
}
}
if ranTimer {
// 执行完一个 timer 后可能存在已经就绪的 G
goto top
}
stop:
...
delta := int64(-1)
if pollUntil != 0 {
// checkTimers ensures that polluntil > now.
delta = pollUntil - now
}
...
// poll network
// 休眠前再次检查 poll 网络
if netpollinited() && (atomic.Load(&netpollWaiters) > 0 || pollUntil != 0) && atomic.Xchg64(&sched.lastpoll, 0) != 0 {
...
list := netpoll(delta) // 阻塞调用
lock(&sched.lock)
_p_ = pidleget()
unlock(&sched.lock)
if _p_ == nil {
injectglist(&list)
} else {
acquirep(_p_)
if !list.empty() {
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
goto top
}
} else if pollUntil != 0 && netpollinited() {
pollerPollUntil := int64(atomic.Load64(&sched.pollUntil))
if pollerPollUntil == 0 || pollerPollUntil > pollUntil {
netpollBreak()
}
}
// 休眠当前 M
stopm()
goto top
}
|
- findrunnable will first call checkTimers to check for executable timers in P before stealing them.
- if there is a waiting waiter in netpoll, then netpoll is called to try to fetch the Glist from netpoller without blocking.
- if no executable G is fetched, then a steal is started. The steal calls checkTimers to fetch random timers from other P’s;
- If no executable timer is available after the steal, the netpoll network is checked again before hibernation, and the netpoll(delta) function is called to make a blocking call.
System Monitor Trigger
The system monitor is a Go language daemon that monitors the system in the background and responds when something unexpected happens. It checks the Go language runtime state at regular intervals to ensure that no exceptions have occurred. We won’t focus on system monitoring here, just the timer-related code.
runtime.sysmon
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
func sysmon() {
...
for {
...
now := nanotime()
// 返回下次需要调度 timer 到期时间
next, _ := timeSleepUntil()
...
// 如果超过 10ms 没有 poll,则 poll 一下网络
lastpoll := int64(atomic.Load64(&sched.lastpoll))
if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now {
atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now))
list := netpoll(0) // 非阻塞,返回 G 列表
// G 列表不为空
if !list.empty() {
incidlelocked(-1)
// 将获取到的 G 列表插入到空闲的 P 中或全局列表中
injectglist(&list)
incidlelocked(1)
}
}
// 如果有 timer 到期
if next < now {
// 启动新的 M 处理 timer
startm(nil, false)
}
...
}
}
|
- sysmon will iterate through the timer list of all P’s by timeSleepUntil to find the next timer to be executed.
- if there is no poll for more than 10ms, poll the network.
- if a timer has expired, start a new M processing timer directly at this time.
What netpoll does
When we call runtime.addtimer to add a timer from the beginning, it will runtime.wakeNetPoller to interrupt the netpoll, so how does it do that? Let’s start by looking at an official example.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
func TestNetpollBreak(t *testing.T) {
if runtime.GOMAXPROCS(0) == 1 {
t.Skip("skipping: GOMAXPROCS=1")
}
// 初始化 netpoll
runtime.NetpollGenericInit()
start := time.Now()
c := make(chan bool, 2)
go func() {
c <- true
// netpoll 等待时间
runtime.Netpoll(10 * time.Second.Nanoseconds())
c <- true
}()
<-c
loop:
for {
runtime.Usleep(100)
// 中断netpoll 等待
runtime.NetpollBreak()
runtime.NetpollBreak()
select {
case <-c:
break loop
default:
}
}
if dur := time.Since(start); dur > 5*time.Second {
t.Errorf("netpollBreak did not interrupt netpoll: slept for: %v", dur)
}
}
|
In the above example, runtime.Netpoll is first called to block and wait, and then runtime.NetpollBreak is cyclically dispatched to interrupt and block.
runtime.netpoll
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
func netpoll(delay int64) gList {
if epfd == -1 {
return gList{}
}
var waitms int32
// 因为传入delay单位是纳秒,下面将纳秒转换成毫秒
if delay < 0 {
waitms = -1
} else if delay == 0 {
waitms = 0
} else if delay < 1e6 {
waitms = 1
} else if delay < 1e15 {
waitms = int32(delay / 1e6)
} else {
waitms = 1e9
}
var events [128]epollevent
retry:
// 等待文件描述符转换成可读或者可写
n := epollwait(epfd, &events[0], int32(len(events)), waitms)
// 返回负值,那么重新调用epollwait进行等待
if n < 0 {
...
goto retry
}
var toRun gList
for i := int32(0); i < n; i++ {
ev := &events[i]
if ev.events == 0 {
continue
}
// 如果是 NetpollBreak 中断的,那么执行 continue 跳过
if *(**uintptr)(unsafe.Pointer(&ev.data)) == &netpollBreakRd {
if ev.events != _EPOLLIN {
println("runtime: netpoll: break fd ready for", ev.events)
throw("runtime: netpoll: break fd ready for something unexpected")
}
if delay != 0 {
var tmp [16]byte
read(int32(netpollBreakRd), noescape(unsafe.Pointer(&tmp[0])), int32(len(tmp)))
atomic.Store(&netpollWakeSig, 0)
}
continue
}
...
}
return toRun
}
|
When runtime.findrunnable is called to perform a preemption, a time is passed in at the end which blocks the call to netpoll, and if there is no event break, then the round-robin scheduling will wait until netpoll times out before proceeding further.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
func findrunnable() (gp *g, inheritTime bool) {
...
delta := int64(-1)
if pollUntil != 0 {
// checkTimers ensures that polluntil > now.
delta = pollUntil - now
}
...
// poll network
// 休眠前再次检查 poll 网络
if netpollinited() && (atomic.Load(&netpollWaiters) > 0 || pollUntil != 0) && atomic.Xchg64(&sched.lastpoll, 0) != 0 {
...
// 阻塞调用
list := netpoll(delta)
}
...
// 休眠当前 M
stopm()
goto top
}
|
So a netpoll interrupt when calling runtime.addtimer to add a timer will make it more responsive to time-sensitive tasks like timers.
Summary
Comparing timer version 1.13 with timer version 1.14, we can see that even a single timer has been optimized in the go language. Instead of maintaining 64 buckets and running asynchronous tasks in each bucket, the timer list is now hooked directly onto P. This not only reduces performance loss from context switching, but also reduces contention between locks, resulting in performance comparable to that of the timer wheel.