I was looking at some excellent open source libraries when I saw an interesting cache library fastcache, in its introduction mainly has the following characteristics:
- read and write data to be fast, even under concurrency.
- maintain good performance even in a cache of several gigabytes, as well as minimize the number of GCs.
- the design should be as simple as possible.
This article will examine how its kernel achieves such goals by writing a simple cache library that mimics it. I hope you will find it useful.
Design Thinking
In our projects, we often use Go cache libraries like the patrickmn/go-cache library. However, many cache libraries actually use a simple Map to store data, which is fine when the concurrency is low and the amount of data is small, but when the amount of data is high and the concurrency is high, it will prolong the GC time and increase the number of memory allocations.
For example, let’s use a simple example.
In this example, a map of size 1 billion (1e9) is preallocated, and then we output the GC situation via gctrace.
The environment for the experiment is Linux, and the machine configuration is 16C 8G
|
|
The above shows the last 5 GCs, let’s see what it means in detail.
|
|
You can see from the above output that each GC takes a very long time to process and consumes a lot of CPU resources. So what is the reason for this?
The underlying data structure of string actually consists of two parts, which include a pointer to a byte array and the size of the array.
Since the StringHeader contains pointers, each pointer is scanned every time it is GC’d, so there are a lot of pointers in the huge map, which causes a huge consumption of resources.
In the above example, the data in map a is stored roughly like this.
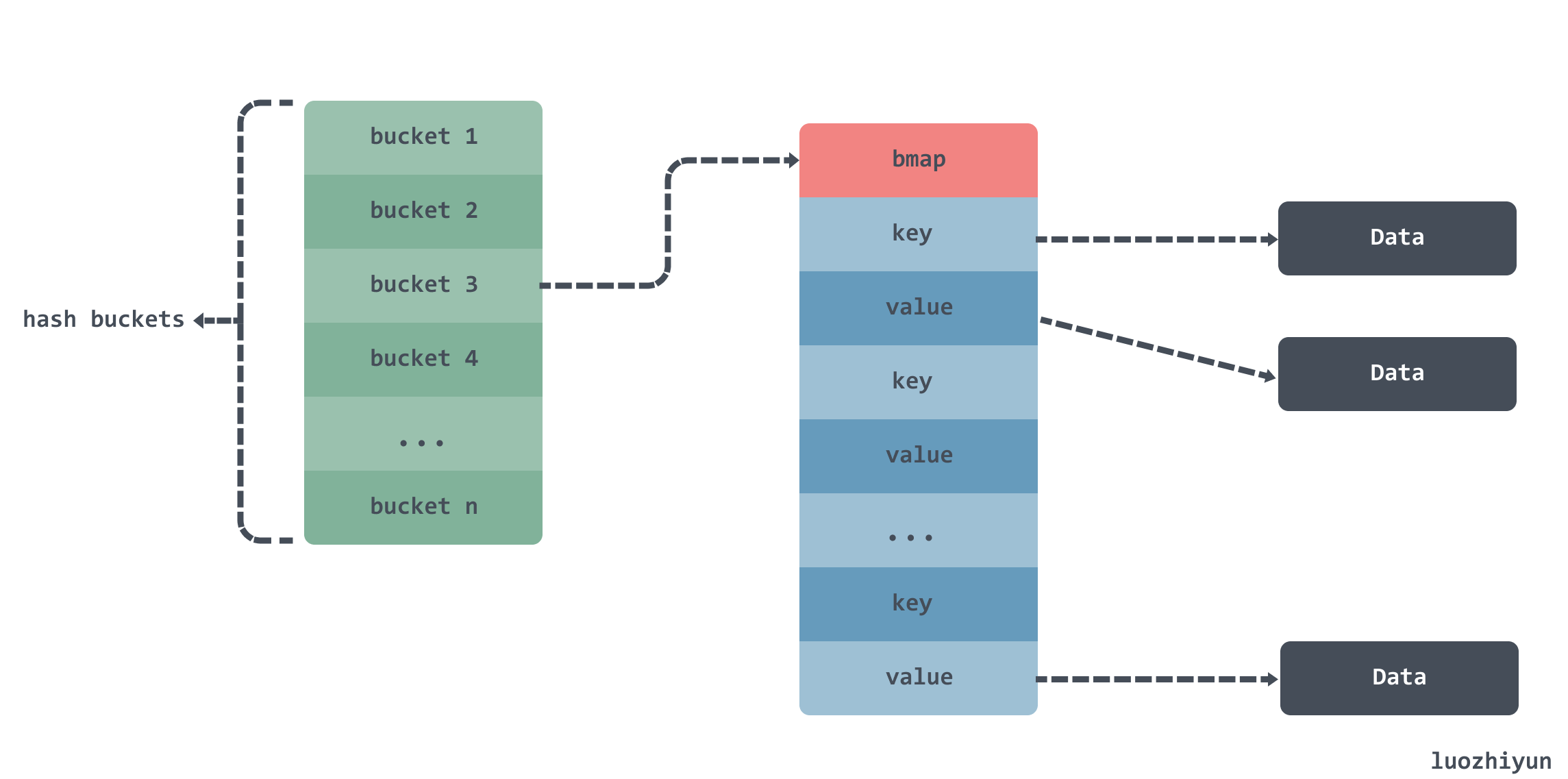
There are multiple buckets inside a map, and a bmap array inside the bucket to hold data, but since key and value are both of type string, you also need to scan the string data according to the Data pointer in the StringHeader at GC time.
For this case, if all the string bytes are in a single memory segment, we can track where a string starts and ends in that segment by offset. By tracking the offset, we don’t need to store the pointer in our large array, and GC won’t be bothered. As follows:
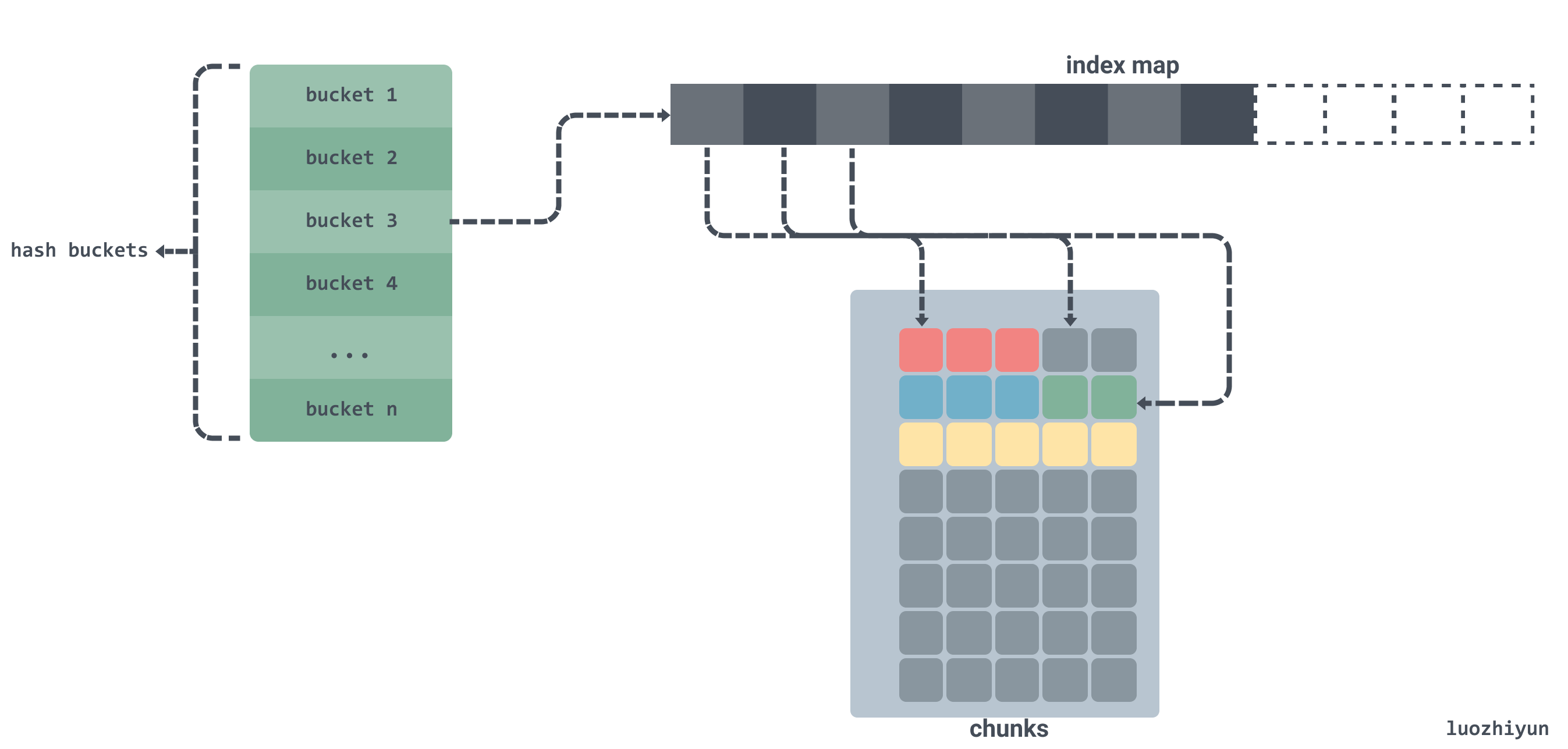
As shown above, if we copy the byte data in the string to a contiguous byte array chunks and allocate memory for this byte array in advance and store only the offset of the string in the array instead of the pointer.
Is there any other way to do this than the optimization described above?
Actually, we can also call mmap syscall directly from the system OS to allocate memory, so that the GC will never do memory management on this memory, and therefore will not scan it. As follows:
The system call requests 13bytes of memory directly from the OS, and then writes a string to the requested memory array.
So we can also improve performance by requesting a block of memory from the OS in advance, instead of requesting memory when it is needed, to reduce frequent memory allocations.
Source code implementation
API
Let’s define the API of this library before we develop it.
func New
|
|
Create a Cache structure and pass in the preset cache size in bytes.
func (*Cache) Get
|
|
Gets the value in the Cache, passed in as a byte array.
func (*Cache) Set
|
|
Set the key-value pair to the cache, k is the key, v is the value, and the parameters are byte arrays.
Structs
|
|
Through our analysis above, we can see that the real place to store data is the chunks two-dimensional array, which is implemented by m field to map the index paths and build a circular chain according to the chunks and gen fields, and the circular chain will add one for each turn of gen.
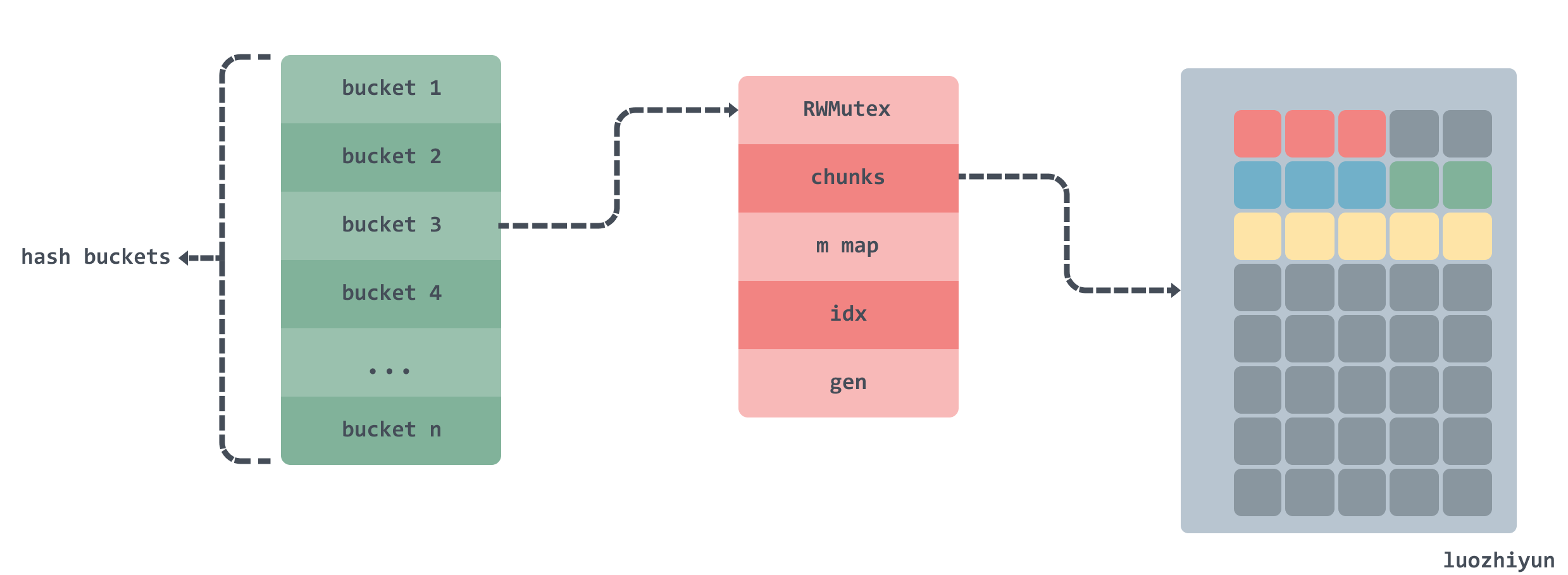
Initialization
|
|
We will set up a New function to initialize our Cache structure, where the size of the cached data will be distributed equally to each bucket, and then initialize each bucket.
|
|
Here the memory inside the bucket is allocated by chunk, each chunk occupies about 64 KB of memory. at the end the reset method of the bucket is called to initialize the bucket structure.
The Reset method is very simple, it mainly clears the chunks array, deletes all the data in the index dictionary and resets the index idx and gen values.
In the above method, there is a putChunk, which is actually a direct manipulation of the memory we requested from the OS in advance, and there is a getChunk method accordingly. Let’s look at the operation of Chunk in detail.
Chunk operation
getChunk
|
|
The initial call to the getChunk function uses a system call to allocate 64MB of memory, and then recursively chops the memory into 1024 copies of 64KB each into the freeChunks free list. Then it fetches the last element of the freeChunks free list each time and returns 64KB of memory. Note that getChunk will be used in the set method of the Cache, which will be described below, so it needs to take into account concurrency issues, so a lock is added here.
putChunk
The putChunk function is to return the memory data to the freeChunks free list and will be called in the reset method of the bucket.
Set
The Set method will do a hash based on the value of k, and then take the modal map to the buckets bucket, the hash library used here is cespare/xxhash.
The main thing is the Set method inside the buckets.
|
|
- at the beginning of this code I will actually limit the size of the key value to no more than 2bytes.
- then encapsulate the 2bytes length of the key value into a 4bytes kvLenBuf as the data header, the total length of the data header and the key value is not to exceed the length of a chunk, that is
64 * 1024. - then calculate the original index chunkIdx and the new index chunkIdxNew, to determine whether the added data plus the original data exceeds a chunk length.
- find the position in the corresponding chunks according to the new index, and then append the key value and kvLenBuf to the back of the chunk.
- set the new idx and the corresponding value in the m dictionary, where the gen and idx are stored by taking and placing.
In Set a key-value pair will have 4bytes of kvLenBuf as the data header, followed by key and value, in kvLenBuf, the first two bytes represent the low and high bits of the key length respectively; the last two bytes represent the low and high bits of the value length respectively, the data diagram is roughly as follows.
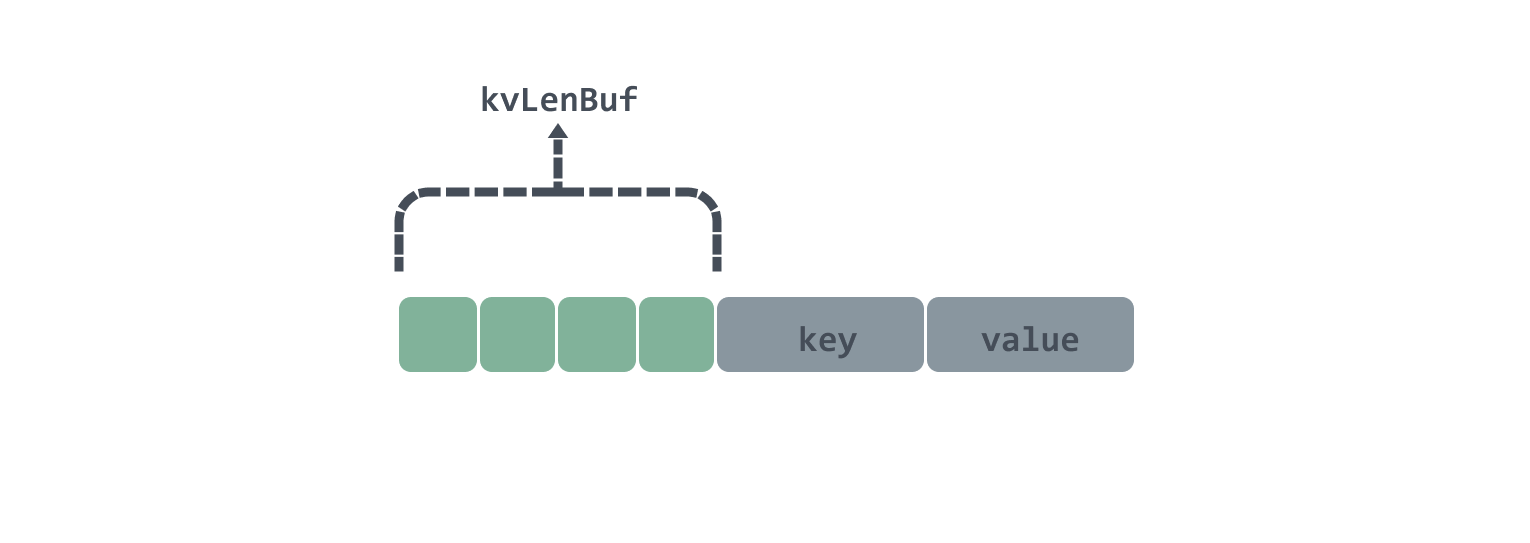
Here is an example to see how to use chunks as a two-dimensional array to implement a circular linkedlist.
In the Init method of the bucket, we set the length of the chunks according to the number of bytes passed into the maxBytes bucket, since each chunk size is 64 * 1024 bytes, then we set the bucket size of 3 * 64 * 1024 bytes, then the length of the chunks array is 3.
If the chunkIdx is currently calculated to be at position 1 of the chunks array, and there are 6bytes left unused in position chunks[1], then there are several cases as follows.
-
now assume that the length of the keys put in is 1byte, then the remaining 6bytes in the chunks[1] position is just enough to put down.
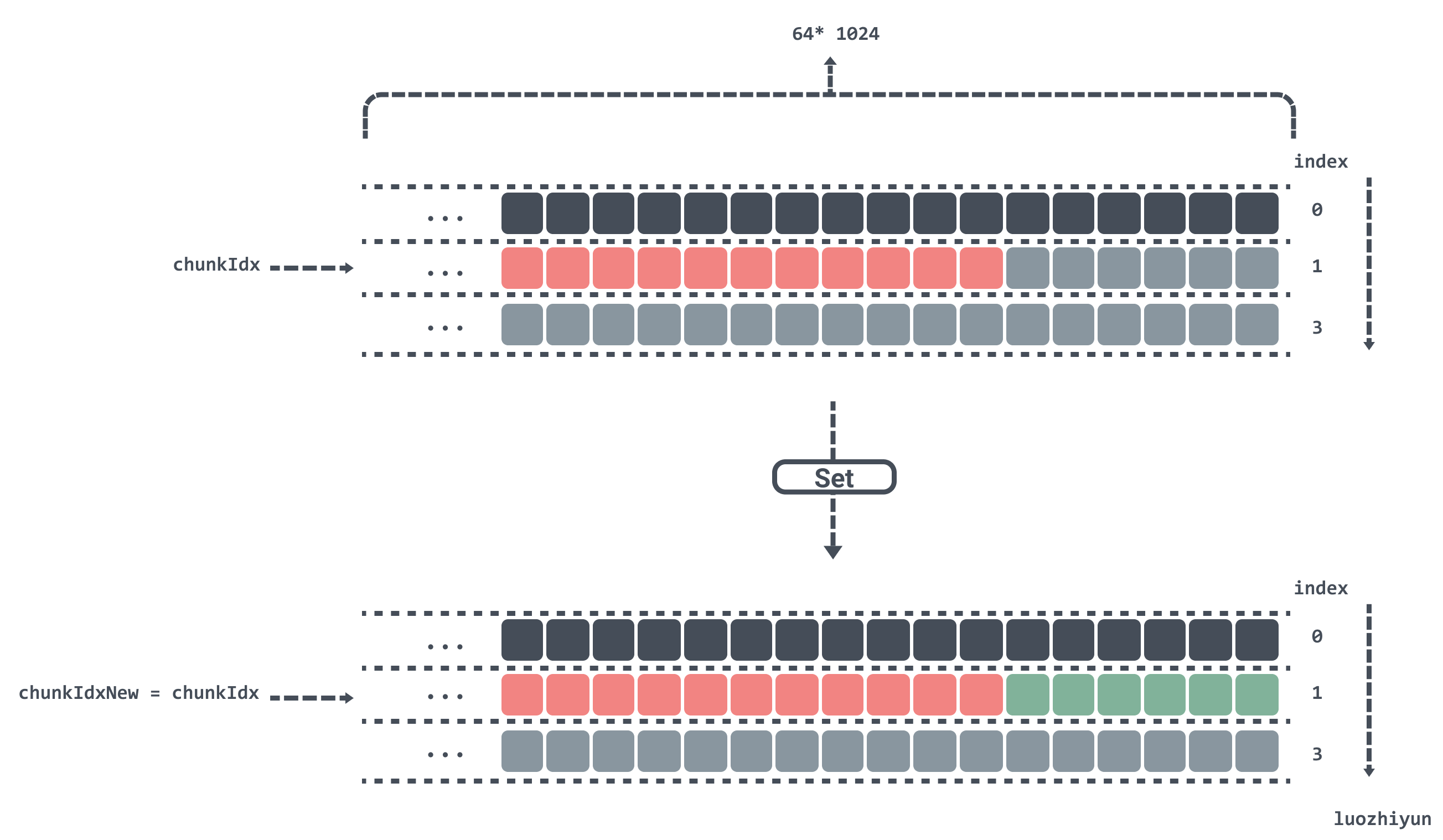
-
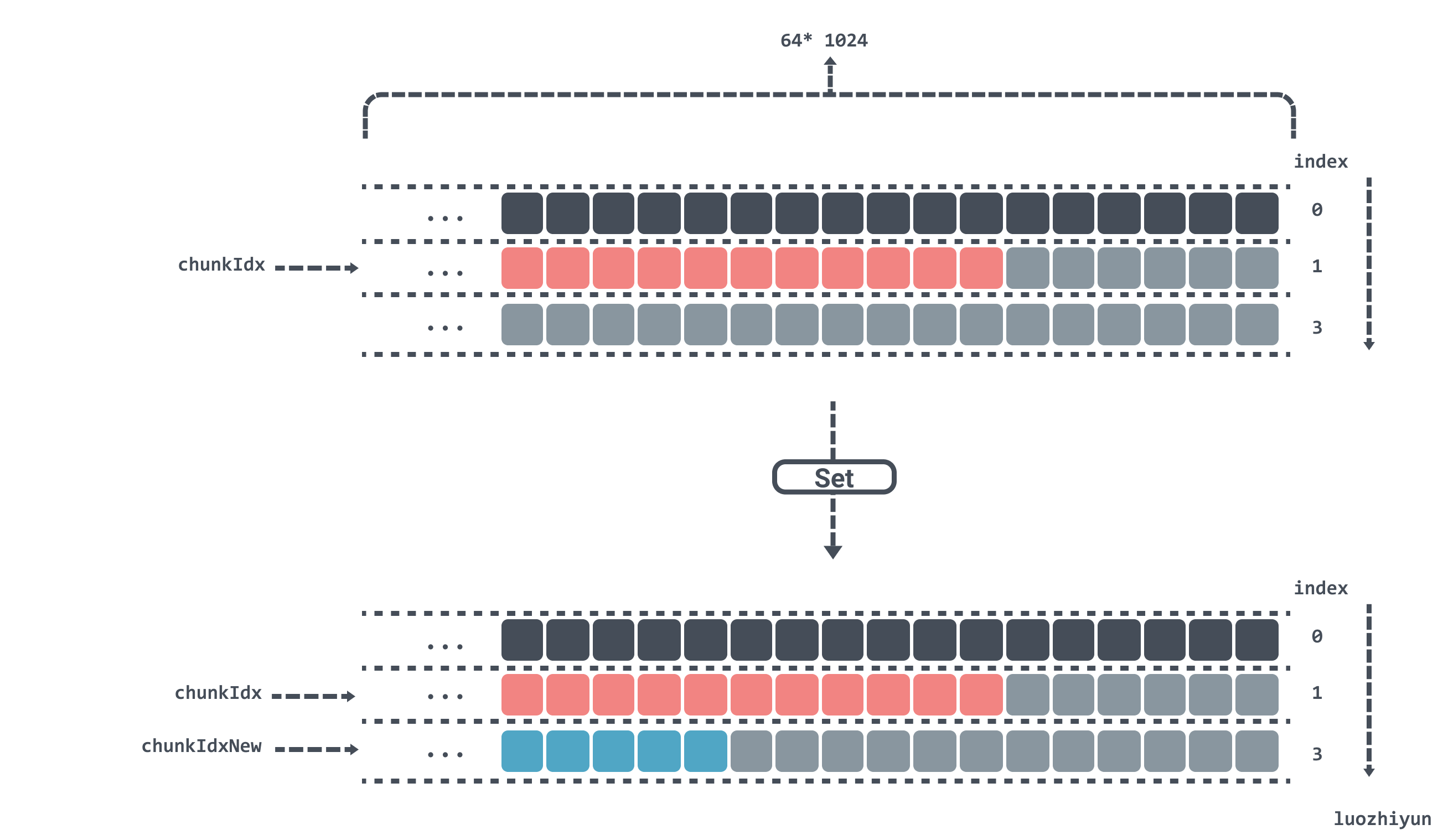
Now suppose the length of the key value is more than 1byte, then the remaining space in chunks[1] will not fit and will have to be placed in chunks[2].
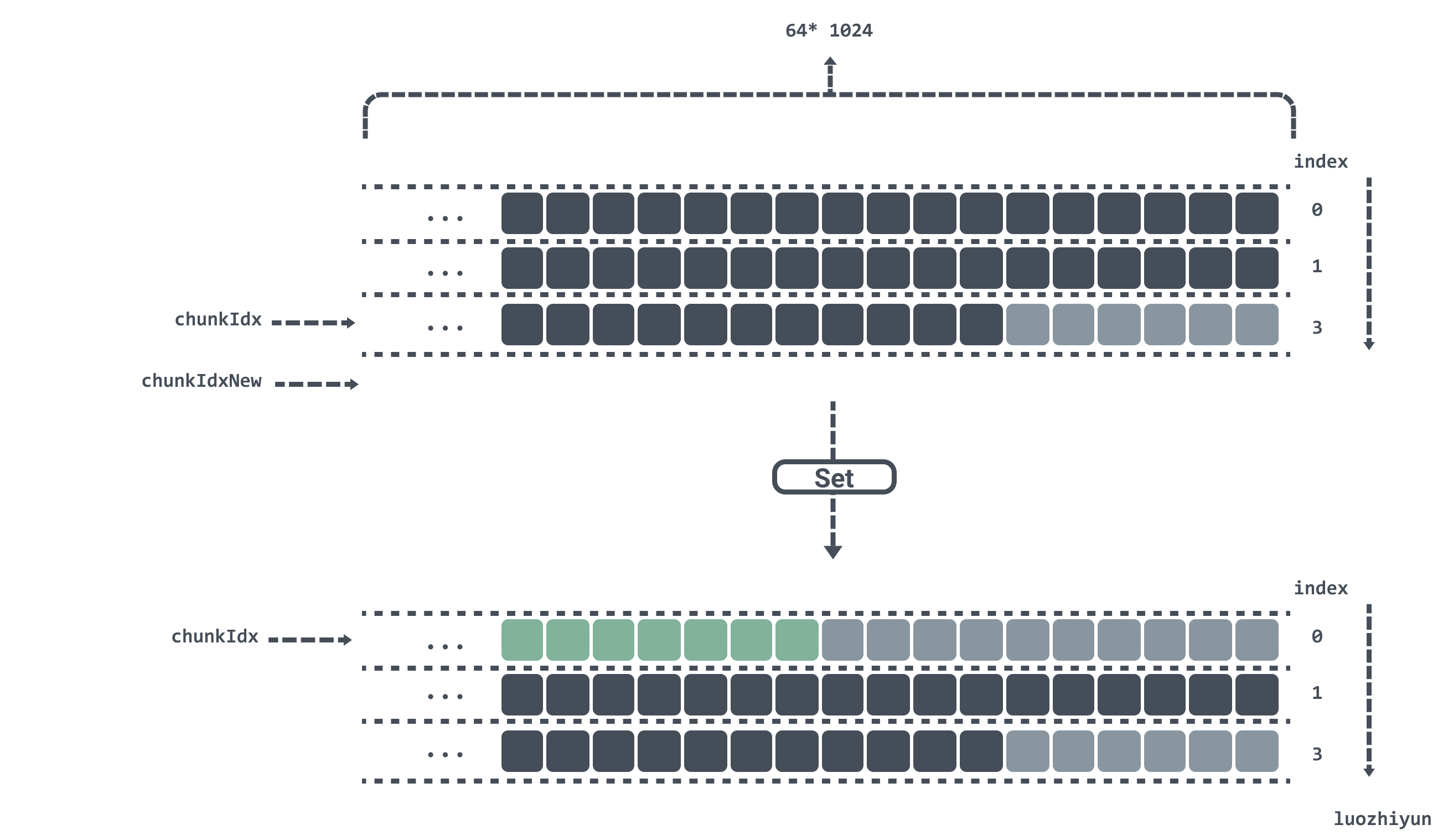
If chunkIdx is currently calculated to be at position 2 in the chunks array and now Set a key value, after calculating chunkIdxNew to be 3, which has exceeded the length of the chunks array, then the index will be reset, the data will be repositioned from chunks[0], and gen will be added by one, indicating that a run has been completed.
Get
Here it is the same as the Set method, which first finds the location of the corresponding bucket and then goes inside the bucket to get the data. Note that the dst here can be passed in a slice from outside to reduce duplicate allocation of return values.
|
|
The Get method mainly considers the boundary problem of the circular linkedlist. In the Set method, we store the gen and idx indexes of each key in the m dictionary, so we can get the gen and idx indexes by bit operation after getting the value of the m dictionary through hash.
After finding the gen and idx indexes, it is time to determine the boundary conditions, using an if condition to determine.
|
|
Here it is determined that if it is in the same loop of the circular linkedlist, then the index corresponding to the key should be less than the index of the current bucket.
|
|
Here it means that the current bucket has entered the next loop, so it is necessary to determine whether the index corresponding to the key is greater than the current index to indicate that the value corresponding to the current key has not been overwritten.
|
|
Because the gen and idx indexes are stuffed into fields of type uint64, the only maximum value left for gen is maxGen = 1<< 24 -1, and exceeding maxGen will make gen start from 1. So here if key corresponds to gen equal to maxGen, then the current bGen should be equal to 1, and the index corresponding to key should also be greater than the current idx, so that the key-value pair will not be overwritten.
After judging the boundary conditions, the corresponding chunk will be found, and then the data location will be found after taking the mode, and the value will be found and taken out by the offset.
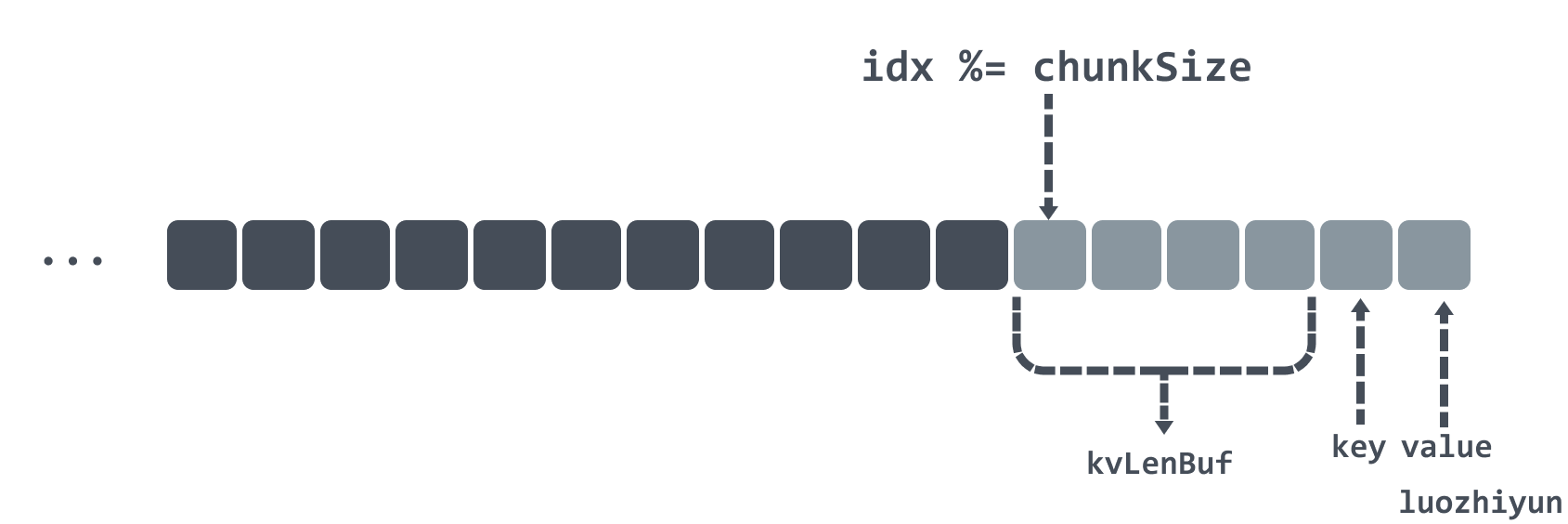
Benchmark
Here’s my post-Benchmark.
Code location: https://github.com/devYun/mycache/blob/main/cache_timing_test.go
|
|
The above tests are for GoCache, BigCache, Map, and sync.Map. The following tests are for the cache libraries developed in this article.
You can see that memory allocation is almost non-existent, and the speed of operation is one of the best in the above libraries.
Summary
In this article, we have analyzed the problem of using Map as a cache based on other cache libraries, and then we have given the reasons for this problem and proposed a solution; in our cache library, we first use indexes and memory blocks to store cached data, and then we use OS system calls to allocate memory so that our cached data blocks are out of GC control, thus reducing GC frequency and increasing concurrency.
In fact, not only the cache library, but also in our project when we need to use a large number of data structures with pointers and need to keep references for a long time, we also need to pay attention to the fact that this may cause GC problems and thus bring potential problems to the system.