In the past 2021, the Julia programming language community has continued to grow at a rapid pace. In addition, some of the world’s most prestigious universities, such as Peking University, MIT, Stanford and Berkeley, are already using Julia in their teaching.
Here are a few dimensions to see how active the Julia programming language community is today.
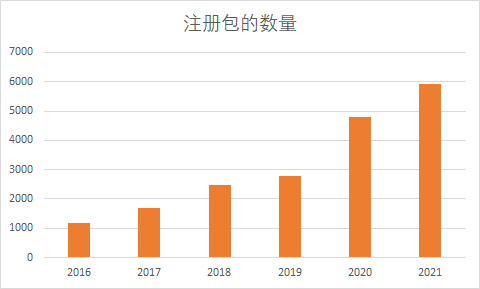
Over the past year, 1128 packages have been added to Julia’s default registry, bringing the total to 5397. Detailed information can be found at JuliaHub.com, and methods to obtain download information for each library are also available on the official forum.
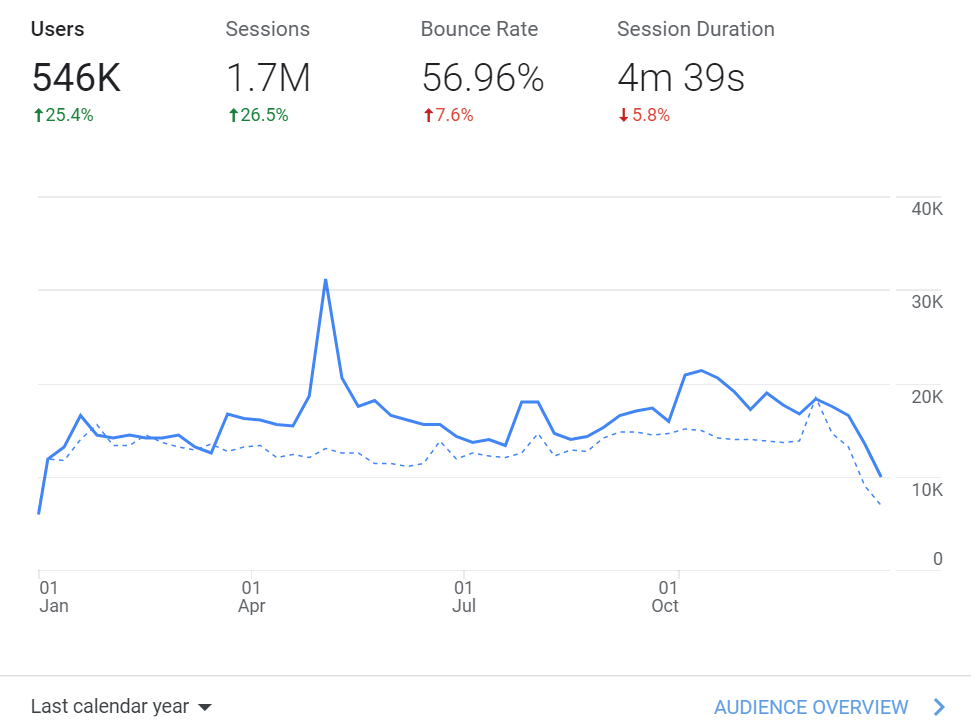
In terms of visits to Julia’s English-language documents, user traffic has increased by about 25 percent year-over-year in the past year.
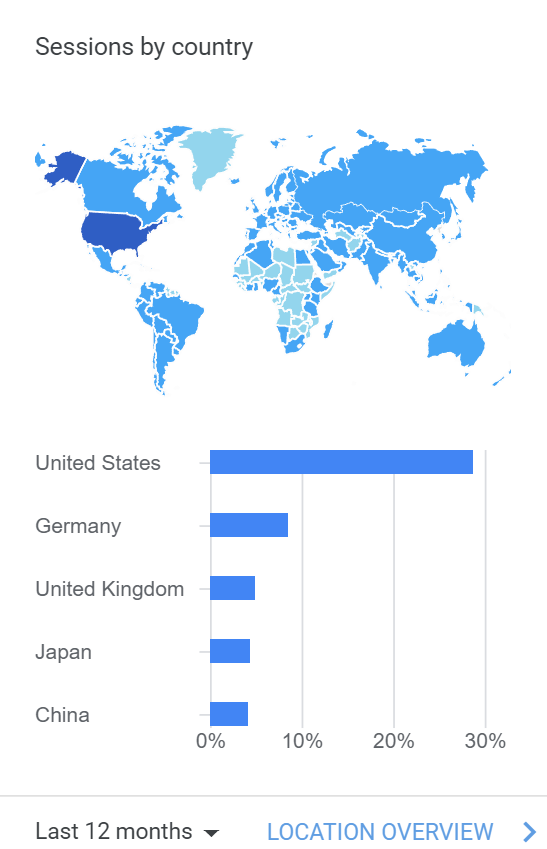
In terms of the distribution of users browsing the documentation, the current users of Julia language are still mainly from the US, followed by Germany and the UK, with Japan and China following closely behind.
However, since the quality of the current Julia Chinese documentation translation is very high, we can further look at the number of Chinese documentation visits.
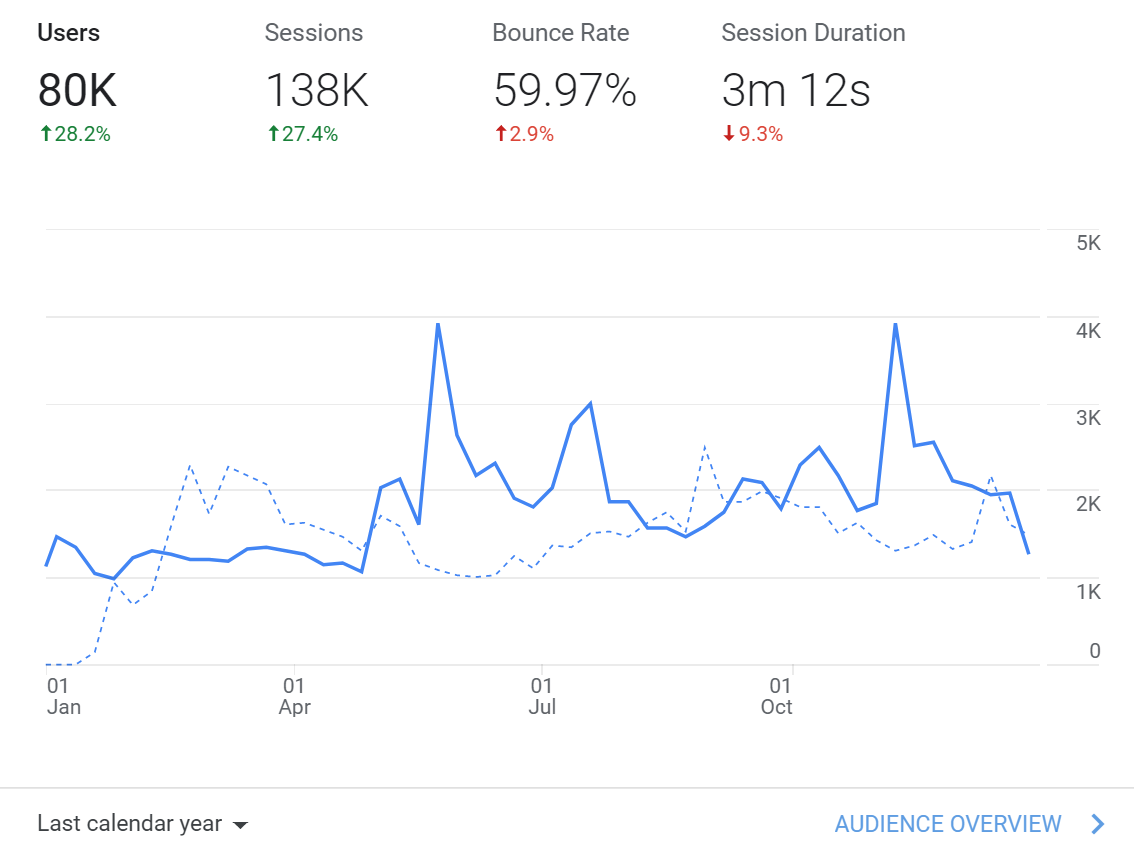
Compared to the previous year, Julia’s Chinese user base grew by about 28% and actually accounts for about 14.6% of the English user base, which should be second only to the US user base.
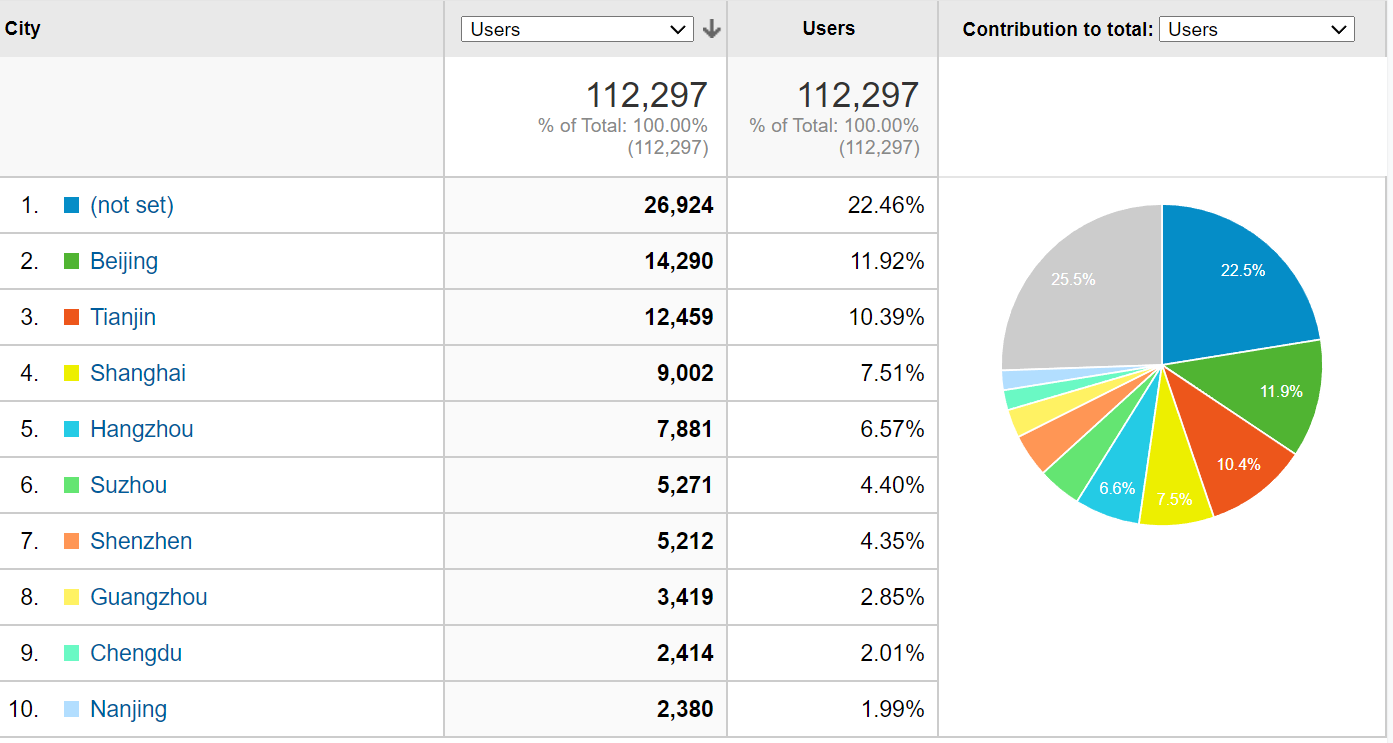
From the distribution of the domestic user volume, the users in Beijing are still the main ones.
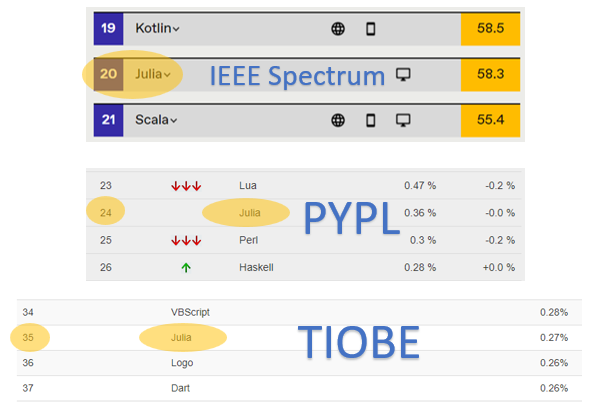
Julia’s overall ranking has risen steadily in the major programming rankings. According to IEEE Spectrum, Julia is new to the list this year, at #20. In the PYPL ranking, Julia is now at #24, little changed from the same time last year, but with a 0.36% share, up from 0.26% last year. In this month’s latest TIOBE ranking, Julia is at #35, little changed from last year.
Progress in the Julia Community
Over the past year, we have observed some important new developments in the Julia community that may have a positive impact on Julia’s future development.
Further increase in domestic mirrors
In the past, the biggest obstacle for domestic users trying to use Julia was that the download and installation often failed due to the network environment. Over the past year, domestic support for Julia mirroring services has increased further, and the following six domestic universities are now providing mirroring services to speed up the download and installation of Julia-related libraries for domestic users.
- Beijing Foreign Studies University (https://mirrors.bfsu.edu.cn/julia)
- Tsinghua University (https://mirrors.tuna.tsinghua.edu.cn/julia)
- Shanghai Jiao Tong University (https://mirrors.sjtug.sjtu.edu.cn/julia)
- University of Science and Technology of China (https://mirrors.ustc.edu.cn/julia)
- Southern University of Science and Technology (https://mirrors.sustech.edu.cn/julia)
- Nanjing University (https://mirrors.nju.edu.cn/julia)
You only need to configure the JULIA_PKG_SERVER environment variable to point to any of the above links before running the Julia program, for more information go to the relevant discussion post in the Chinese forum .
In addition, there are default servers deployed in Beijing, Shanghai and Guangzhou respectively, so even if the user does not configure a mirror station, the current domestic downloads and installations will enjoy accelerated results.
Flux 加入 NumFocus

The FluxML community officially announced its affiliation with NumFocus on December 1, and it couldn’t have come this far without the support of the entire Julia community and developers.
Flux has been committed to providing a simple, scalable and efficient machine learning solution that extends to all areas of scientific computing with differentiable programming. This partnership with NumFocus will further strengthen the community, attract new developers to the ecosystem, and help manage the funds raised for upcoming projects such as tools for compilers related to automatic differentiation, and more general low-precision operations on GPUs.
JuliaComputing Completes Series A Financing

Founded in 2015 by the founders of the Julia programming language, JuliaComputing provides enterprise-class computing solutions, primarily through JuliaHub.
Its recent focus has been on providing a modern set of modeling and simulation tools, such as the Pumas framework for drug simulation, JuliaSim for multiphysics simulation, and JuliaSPICE for circuit simulation, and its Series A funding round, which closed in July, has gone some way to dispelling long-held doubts about Julia’s commercialization prospects.
Julia lands more in commercial companies
Julia is also finding further use in commercial companies, for example, QuEra Computing Inc, the star quantum computing company of Cold Atom Solutions, uses Julia to build their simulators; RelationalAI uses Julia to build their web services and relational databases; and Tong Yuan Software has started using Julia to develop Pumas has used Julia to build their clinical drug research suite, and the mRNA-based Moderna New Crown vaccine uses Pumas’ services for clinical drug data analysis. Other companies using Julia without disclosing details of their products include well-known large companies (Google, AWS, Huawei, etc.) as well as emerging startups, and the ecosystem of Julia applications for commercial companies (e.g., private registry, private package management, private CI/CD, etc.) is getting better.
Evolution of Julia’s core functionality
In 2021, Julia released two major releases, Julia@v1.6 and Julia@v1.7. In addition, the community officially announced Julia@v1.6 as a new Long Term Support (LTS) release at the same time as Julia@v1.7.0 was released on November 30. Julia official blog details some of the new features of Julia@v1.7, and here we list a few that are of particular interest.
New multi-threading features
Multithreading-related updates have been a focus for the last few Julia releases.
The latest version of Julia@1.7 addresses many runtime race conditions, optimizes scheduling of tasks between multiple threads, makes the default random number generator more multi-thread friendly, and adds a new class of atomic operations as a fundamental language feature. With the @atomic macro, member variables within mutable structures can now be accessed and updated in a more efficient and atomic manner. At this year’s JuliaCon, Jameson Nash showed how to use this feature.
There is already a range of libraries in the community that provide thread-safe abstractions, and it is foreseeable that more and more libraries will use this feature in the future.
Updates to package management
In the previous version, if you used a package and it was not installed in the current environment, it would report an error.
In addition, the new Manifest.toml file has made one major change compared to the previous version: all package related information has been put under [deps], and a new julia_version entry has been added at the top level, which has been merged into the version after Julia@v1.6.2.
Another point of interest is that the new version of the package manager has significantly improved performance on Windows and distributed file systems (especially NFS), thanks to decompressing files in memory instead of decompressing them directly first.
Support for Apple Silicon
Julia@v1.7 is the first version to run on Apple Silicon. Note, however, that support for this platform is only at tier 3 (i.e. experimental, compilation/testing may fail), although the official download page provides the relevant binary installation files.
BLAS/LAPACK: Runtime backend switching
Prior to Julia 1.7, if you wanted to use MKL, you needed to compile a new Julia image before using it, which was somewhat inconvenient for users.
Julia 1.7 provides a libblastrampoline (LBT) flexible BLAS/LAPACK proxy module that allows users to dynamically select a specific calling backend at runtime. lBT makes it easier to use (e.g. MKL.jl can be used directly without compiling the image), but also provides On the other hand, it provides a flexible calling mechanism like “call the best one from multiple BLAS implementations”. Since it is not necessary to completely replace the entire functionality of the existing BLAS, this even opens up the possibility to provide pure Julia BLAS implementations (e.g. Octavian based on LoopVectorization) in the future. operational possibilities.
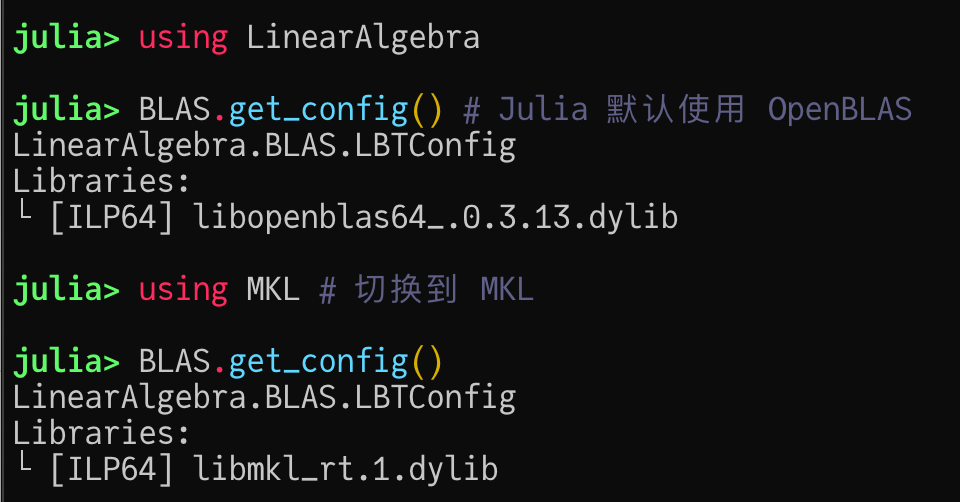
With Julia, you can imagine what it is like to write a BLAS library with comparable performance in a dynamic high-level language.
Compilation delay and runtime volume optimization
Due to the nature of Julia’s dynamic compilation, functions need to trigger a compilation operation when they are executed for the first time, so when using some of the larger toolkits (e.g. Plots, Makie), you will encounter a longer wait.
The graph below shows the time obtained with Julia 1.7 on an Intel 12900k, while using Plots in Julia 1.5 takes about 7s, or longer if you have a lower CPU.
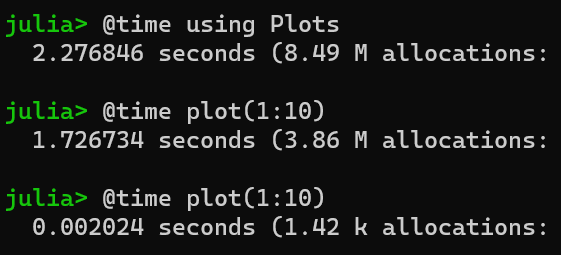
For server programs or large programs that take a long time to run, compile latency is not a big problem, but for drawing or command-line programs, compile latency will definitely make Julia a poor experience.
The two biggest changes in Julia 1.6 are the introduction of parallel precompilation to take advantage of the CPU’s multi-core performance (but still in single-threaded mode when loading packages), and support for manual tuning to reduce code that significantly affects method invalidation, thus improve the utilization of precompiled results. While these measures alleviate the compilation latency problem to some extent, further compilation latency optimization may require the introduction of a better interpreter in Julia or a mechanism similar to the JVM’s hotspot compilation and multi-level execution.
The packaging of LLVM into the Julia runtime brings another pain point of using Julia: the relatively large runtime size. For example, just opening Julia takes up about 200M of memory, and compiling the smallest hello world program generates over 250M of content.
To address the compilation latency and runtime size issues, Julia 1.8 is being developed with a number of optimizations to compiler performance by separating the LLVM from the Julia runtime so that Julia can run entirely in interpreter mode, resulting in smaller binaries.
In the near future, we can expect to have some of the performance-demanding code compiled statically earlier, while the rest of the code runs under the interpreter. This will significantly reduce compilation latency and make it easier to deploy Julia services.
Better Type Inference, Code Analysis and Checking
Julia 1.7 introduces a number of compiler-related type inference optimizations, mainly by Shuhei Kadowaki, including a new SORA (Scalar Replacement of Aggregates,) optimization, a number of compiler code type stability improvements, and more. This can bring nearly free performance acceleration to Julia code. Some previously known performance optimization techniques (such as using === instead of == when determining whether a singleton is equal) have been made redundant.
These type inference optimizations have, on the other hand, contributed to the improvement of the static code checking tool JET. Currently we can do some higher quality code type checking and performance optimization by calling JET manually, and it may be integrated into the IDE in the future.
Julia Ecology Evolution
As the Julia language has gradually stabilized, we have seen a very rich subset of the Julia ecosystem evolve over the past year. In general, in the field of scientific computing, more and more Julia niche projects are maturing and catching up or even surpassing their counterparts based on other languages. In this section, we will try to list some of the areas that we think are of interest to most Julia users: automatic differentiation, for loop optimization, heterogeneous programming, programming theory, editors, and drawing toolkits. We also list some areas that we know about: deep learning, dynamical systems.
However, due to the limited scope of knowledge, there are still some subdivisions of the Julia ecology that are difficult for us to give an overview review, e.g., the differential equation ecology with SciML at its core, the optimization domain represented by JuMP, and the probabilistic domain represented by Turing for probabilistic programming, and so on. We are aware that it is difficult to cover all the segments of the Julia ecosystem, so here we just want to give you an idea of the main trends in the Julia ecosystem and the areas where Julia is currently doing well.
Automatic differentiation: still very active
Julia’s exploration of the field of automatic differentiation has been relatively cutting-edge and active: from finite differences FiniteDiffs and forward-mode automatic differentiation [ForwardDiff](https:// github.com/JuliaDiff/ForwardDiff.jl), to the Julia IR-based source-to-source automatic differentiation framework Zygote, to the LLVM IR-based automatic differentiation framework supporting multiple languages Enzyme, and this year’s proposal Diffractor, which supports more efficient higher-order differential generation, as well as Dr. Jinguo Liu’s reversible programming based on reversible programming) NiLang, the existence of these different design-based but excellent automatic differentiation frameworks makes it easy for people to fall into a selection dilemma.
This is largely due to the fact that it does not take much effort to implement a relatively good performance code framework under Julia. In addition to these AD frameworks, ChainRules proposes a reusable and extensible automatic differentiation ruleset and testing framework that makes it easier and more reliable for the entire community to fully access automatic differentiation. In the future, we can expect more ecosystems to introduce autodifferentiation support and thus spark some new ideas.
LoopVectorization: Efficient for-loop optimization
LoopVectorization achieves very efficient code generation by performing an overhead analysis of Julia’s for-loop IR expressions to infer the optimal for-loop expansion pattern.
The following figure shows the optimized implementation of LoopVectorization for the matrix multiplication implementation, where @turbo shows that LoopVectorization achieves a performance close to that of MKL.

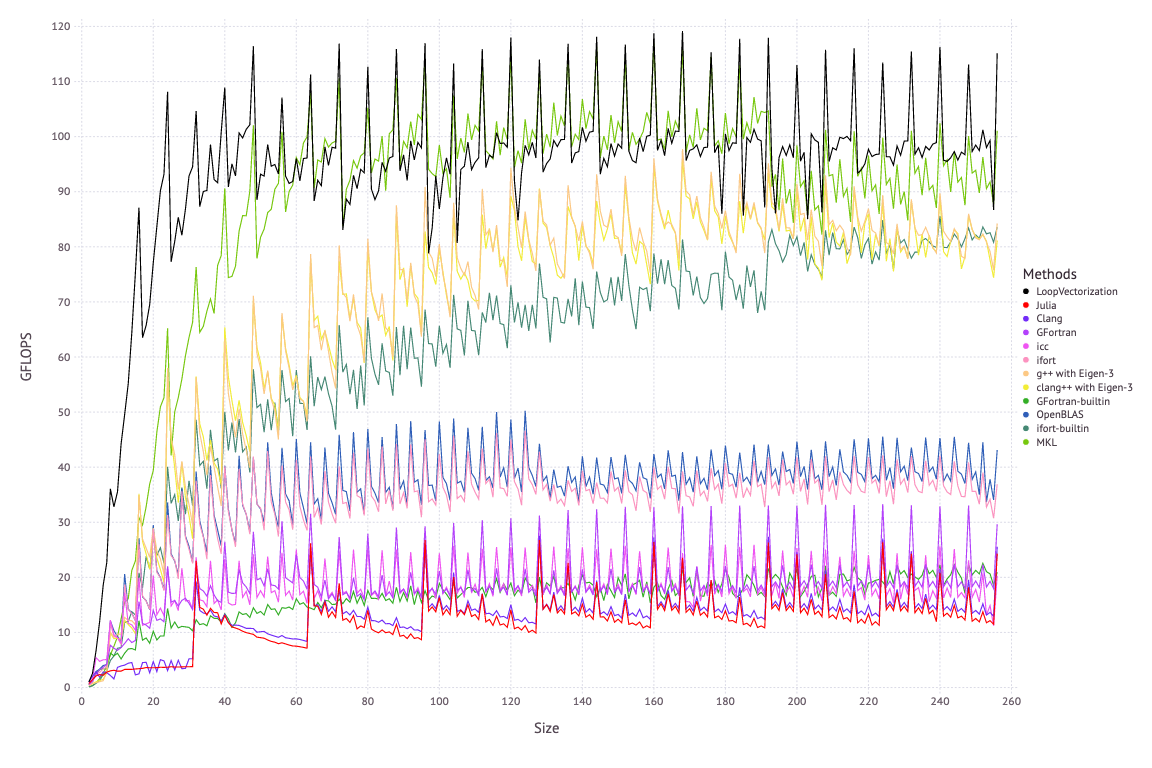
Since its release last year, LoopVectorization has received a lot of attention and praise from the community, and its author was named JuliaCon 2020 Community Contributor of the Year. The biggest addition to LoopVectorization this year is the introduction of multithreading support @tturbo. In the future we can expect more toolkits to leverage the performance of the CPU with LoopVectorization.
Heterogeneous Programming: CPU/GPU and Quantum Computing Devices
There are usually two ways to think about exploiting the computational power of GPUs: one is to write vectorized code to call existing GPU-enabled functions, and the other is to write CUDA kernel core functions directly (typically on C/C++). Since CUDA.jl allows to compile Julia code directly to CUDA devices, this allows us to write kernel functions directly on Julia. Remember the OpenAI triton that was all over your friends’ world this year? The work behind it is very similar to what CUDA.jl does.
After CUDA.jl provided the ability to compile kernel functions directly to CUDA devices, there were some advanced wrappers around that this year, such as KernelAbstractions and ParallelStencil. They provide the ability to compile hand-written kernel functions to heterogeneous devices such as CPUs, GPUs, etc. as needed, thus avoiding the need to write multiple kernel functions for different computing devices.
In addition to the classical CPU/GPU heterogeneous programming, in the field of quantum computing, Yao.jl also provides the ability to compile Julia code directly to quantum devices. A report on this can be found at the winter meeting organized by JuliaCN this year (bilibili link).
The development of CUDA.jl and Yao.jl has created some additional compiler plugin requirements for Julia, also resulting in JuliaCompilerPlugins group, and some related language features will be supported in Julia 1.8 (the development version). It can be expected that more compilation tools using Julia IR as an intermediate representation will appear in the future.
Formal research on programming theory related to the Julia language
Formal studies will help to better understand and verify Julia programs, and theoretical studies related to the Julia programming language are progressing steadily, following the study of the world age mechanism of Julia in October 2020 (arxiv:2010.07516) and the formalization (JULIETTE, a world age calculus). Researchers from Northeastern University and Cornell University formalized a type-stable subset of Julia and showed how type stability yields compiler optimizations and proves program correctness (arxiv:2109.01950). This paper does a good job of explaining why Julia is able to leverage type-stable code to achieve performance comparable to that of traditional static languages.
Editors: VSCODE, Jupyter, Pluto as the mainstream development platform
In the early days when VSCode was not yet mature, the recommended IDE for Julia was the combination of Atom + Juno, then as VSCode matured and Atom stopped being updated, in 2020 Sebastian Pfitzner announced that the Juno team joined the Julia for Visual Studio Code plug-in development.
With more Juno features (e.g. in-line display, variable workspace, debugger) being improved on the VSCode plugin, this year Juno has almost completed its historical mission and has been removed from the list of IDEs for Julia. In addition, a description of the Julia language has been added to VSCode’s documentation list.
Jupyter Notebook is a popular development and experimentation environment for programmers who have been exposed to data science: it provides a browser-based IDE and supports dozens of programming languages. Julia provides support for Julia through the IJulia.jl plugin, which is as stable as ever and is one of the most popular toolkits in the Julia community.
In contrast to the Jupyter project, the Pluto.jl project is a Jupyter replacement platform built entirely around Julia’s own features. It provides a programming experience that automatically executes code and updates the results, based on a dependency analysis of the execution order of code blocks. Because Pluto provides a more responsive programming experience than Jupyter, Pluto is excellent for teaching and demonstration scenarios, e.g., MIT’s Computational Thinking class uses Pluto to great effect.
Drawing toolboxes: Makie gets a new look, AlgebraOfGraphics gets a bright look
Among the more stable mainstream toolkits in Julia’s drawing ecosystem, GR.jl has been criticized in China for failing to build due to network reasons since it switched to the jll artifacts version that can be distributed with mirrors last year. The problem of build failures due to network reasons has been solved.
Julia’s mainstream drawing toolkits have always been packages of drawing toolkits in other languages, such as GR.jl based on GR in C and PyPlot based on Matplotlib in Python. Compared to these drawing toolkits, the pure Julia-based GPU drawing library Makie provides very strong support for interactive plotting, and this year merged the OpenGL, Cairo, and WebGL backend repositories in a relatively large documentation update that integrates flexible multi-image layout functionality. This has attracted a lot of contributions and interest from the community.
Julia’s compilation latency, which requires a few minutes of compilation time for the first drawing under Makie, has been a major pain point for Makie, so the experience is not yet ideal. Currently, if you need to use Makie on a daily basis, you can consider taking advantage of the pre-compiled image preload provided by PackageCompiler.jl. As more and more Julia developers start to address compilation delays, you can expect Makie to become easier to use in the future.
In contrast to the traditional drawing toolkit’s API documentation and example drawing model, the Makie-based AlgebraOfGraphics defines additive and multiplicative operations on basic graphical elements (data, axes, layers) and thus provides and multiplication operations on basic graphical elements (data, axes, layers), and thus provides an eye-catching graphical algebra-based drawing API.
Deep learning: focus on academic exploration, lack of industrialization
In the field of deep learning, there are three main lines of development for Julia: 1) directly calling the mature deep learning ecosystem under Python via PyCall; 2) using Julia to re-implement some of the underlying tools such as NNLib, Flux, Augmentor, DataLoaders, FastAI, Dagger+Flux github.com/FluxML/DaggerFlux.jl) and other basic deep learning modules; 3) development of new deep learning domains and working models, such as trainable differential equation solvers NeuralOperators, DiffEqFlux, a deep neural network based on differential equation solvers, and Geometric Deep Learning GeometircFlux.
While Julia’s deep learning will not be as easy to use and deploy in the short term as established deep learning frameworks like MindSpore, PyTorch, and TensorFlow, in terms of customizability and scalability, Julia will always be able to satisfy the desire of those at the forefront of research to explore without losing performance.
JuliaDynamics: Nonlinear Dynamical Systems and Chaos
Probably the most notable work in JuliaDynamics this year is the publication of Nonlinear Dynamics: A Concise Introduction Interlaced with Code, an introductory textbook on nonlinear dynamical systems in the Springer Nature series of undergraduate physics lecture notes.
The book contains a large number of code examples based on DynamicalSystems.jl. At the same time, this year DynamicalSystems has also released version 2.0, which includes new features and algorithms, such as a toolbox for entropy calculation and a new algorithm for estimating the domain of attraction ( https://arxiv.org/abs/2110.04358 ). More detailed information about the textbook and DynamicalSystems can be found in the summary on discourse.
In addition, Agents, another major toolbox of JuliaDynamics, provides an agent-based modeling approach. It was released earlier this year as version 4.0, and after a number of feature updates, it is now at version 4.7 and is also being prepared for version 5.0. According to its latest article ( https://arxiv.org/pdf/2101.10072.pdf ), Agents.jl has surpassed other similar toolkits (e.g. Mesa, NetLogo, MASON) in terms of performance, features and ease of use.
Summary
Quoting an introduction from the public course MIT 6.172 Performance Optimization of Software Systems: “Performance is the currency of computation” (performance is the currency of computation). On the one hand people will never be too rich, on the other hand people will say things like they are not interested in money when they are rich enough. Many times when we say that performance is not important, it is actually because we are enjoying the benefits of what has been done before us, yet once we need to explore new areas of computing (e.g., quantum computing, automatic differentiation, graph computing), we are thrown into an unexplored region. To go further in this unexplored region, we have to use all the resources around us more efficiently: to find the right direction to explore, and to explore more efficiently.
As a dynamically compiled language, Julia gives us the same development efficiency as Python on the one hand, and the same execution efficiency as C/C++ on the other, thus attracting a large number of researchers in optimization algorithms, differential equations, automatic differentiation, quantum computing, machine learning, and other computing fields. The Julia language is now maturing and stable, and we have reasons to believe that the advantages of Julia will be further exploited in the future as the Julia ecosystem further matures.
Finally, we quote the philosopher Wittgenstein’s famous quote from “The Philosophy of Logic”: “the limits of my language mean the limits of my world”. Many times we think that programming languages are just tools, and that what one programming language can do, another programming language can do, and we refuse to learn and use other programming languages. But in fact it is very similar to natural languages: you can only learn a language in depth to better understand the national culture and the ideas behind it, just like people who don’t know Chinese may never really understand the ideas behind Confucian culture. As a functional programming language, Julia adopts a completely different mindset from the mainstream languages like C/C++/Python, which will always bring you some extra experience and gains when you get to know and use it.
Now that Julia is steadily moving into the mainstream, what are you waiting for?