File system of Linux
Characteristics of the file system
- The file system has to be strictly organized so that files can be stored in blocks.
- The file system should also have indexed areas to make it easy to find out where the multiple blocks of a file are stored.
- the file system should have a cache layer if there are files that are hot files and have been read and written to frequently in the recent past.
- files should be organized in folders for easy management and querying.
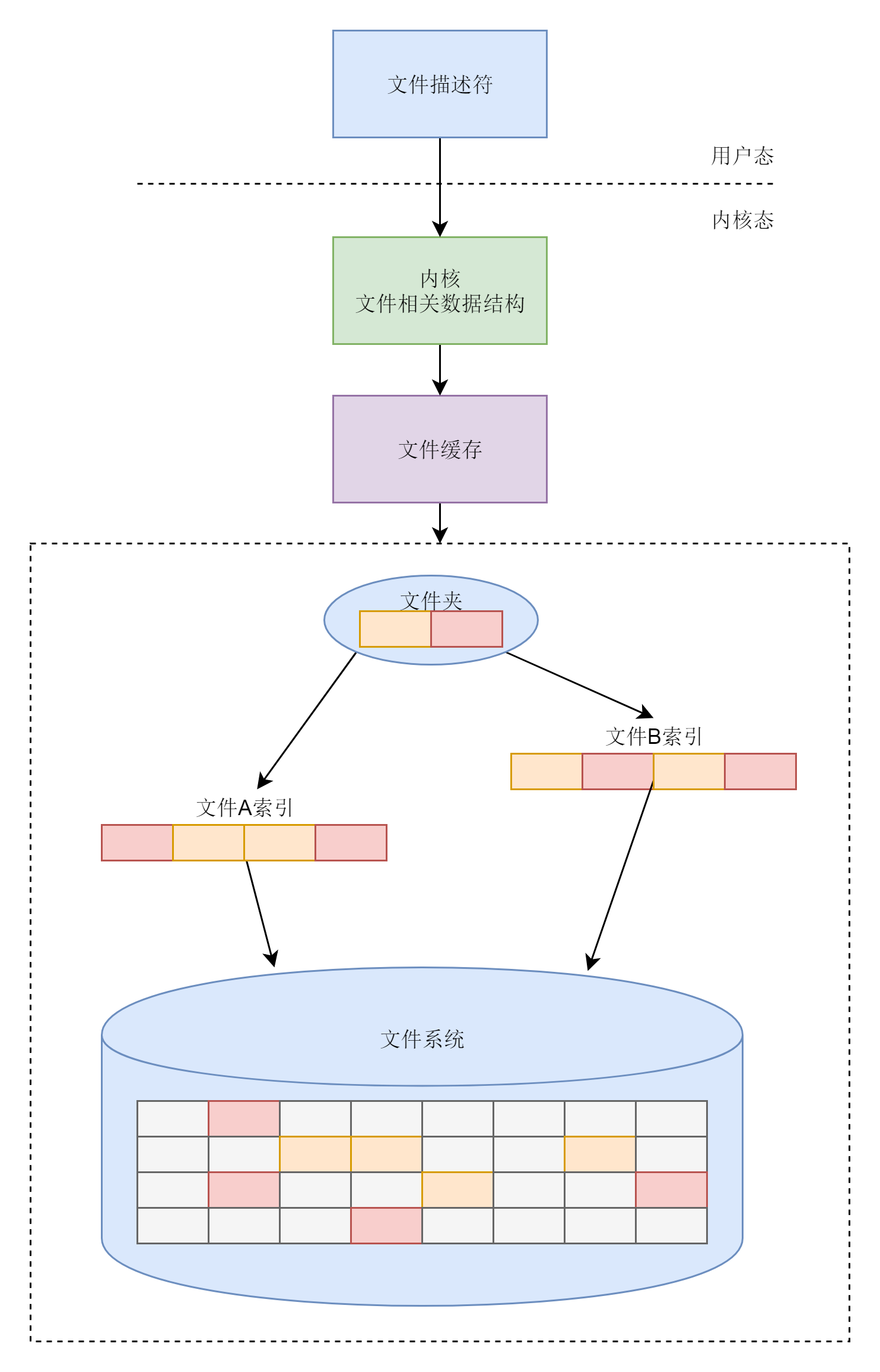
- The Linux kernel should maintain a set of data structures inside its own memory to keep track of which files are opened and used by which processes.
In general, the main functions of the file system are sorted out as follows.
The format of the ext family of file systems
inode and block storage
The hard drive is divided into equal-sized units, which we call Blocks. The size of a block is an integer multiple of the sector size, the default is 4K. this value can be set when formatting.
A large hard disk is divided into smaller blocks to hold the data part of the file. This way, if we store a file like this, we don’t have to allocate a contiguous block of space to it. We can spread it out into smaller chunks for storage. This is much more flexible and easier to add, delete and insert data.
The inode means file index, and each file corresponds to an inode; a folder is a file, which also corresponds to an inode.
The inode data structure is as follows.
|
|
inode contains the file read and write permissions i_mode, which user i_uid belongs to, which group i_gid, what size i_size_io is, how many blocks i_blocks_io occupies, i_atime is the access time, which is the last time the file was accessed; i_ctime is the change time, which is the last i_ctime is the change time, which is the last time the inode was changed; i_mtime is the modify time, which is the last time the file was changed, etc.
All the files are saved in i_block. The specific saving rules are determined by EXT4_N_BLOCKS, which has the following definition.
In ext2 and ext3, the first 12 of them directly save the location of the block, that is, we can get the block where the file content is saved directly by i_block[0-11].
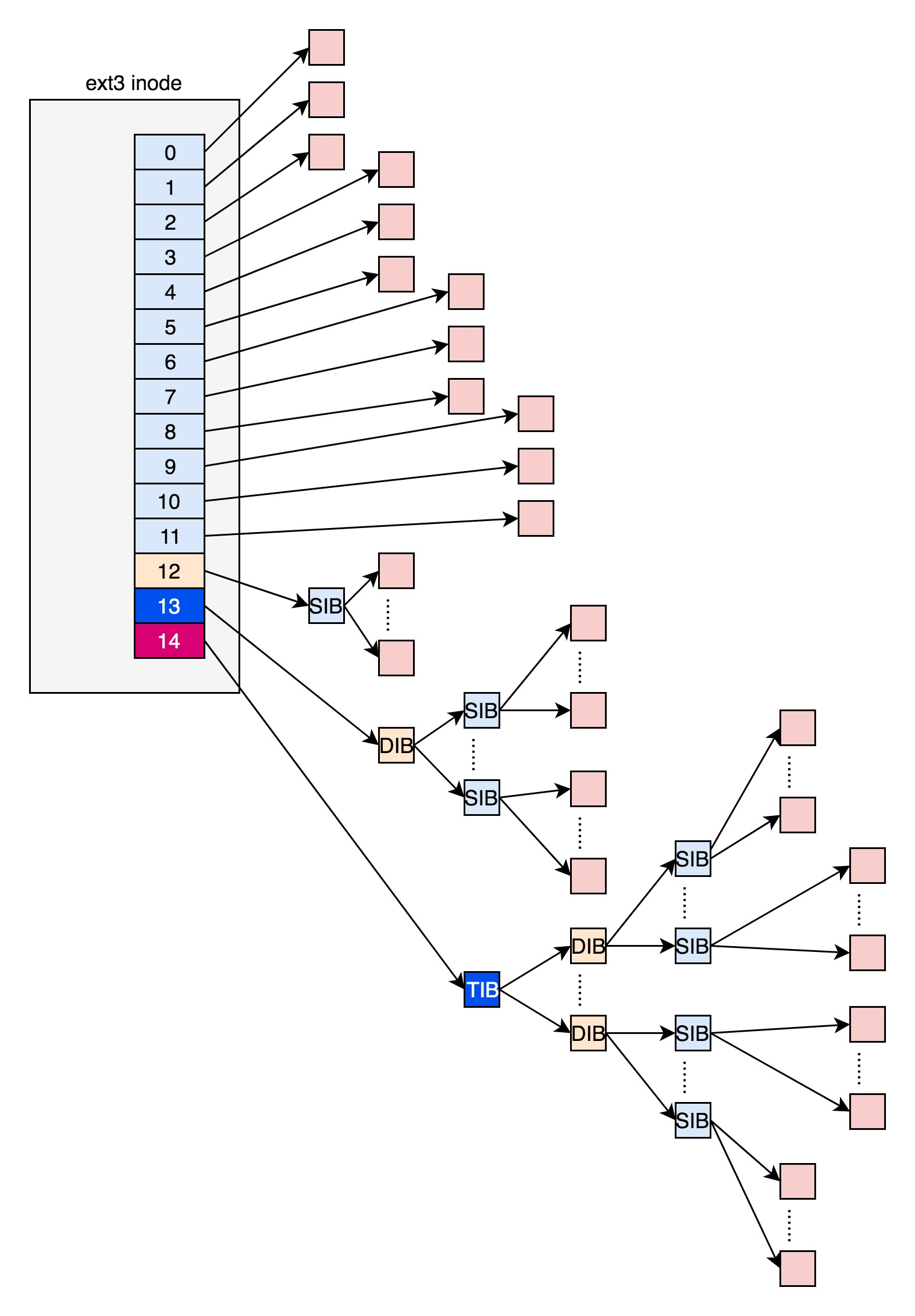
However, if a file is relatively large, 12 blocks won’t fit. When we use i_block[12], we can’t put the location of the data block directly, or the i_block will run out soon.
Then we can let i_block[12] point to a block which does not put data blocks inside, but the location of data blocks, and this block we call indirect block. If the file is even bigger, i_block[13] will point to a block, and we can use a secondary indirect block. The secondary indirect block holds the location of the indirect block inside, the indirect block holds the location of the data block inside, and the data block holds the real data inside. If the file is even bigger, then i_block[14] does the same thing.
There is a very significant problem here, for large files, we have to read the hard disk several times to find the corresponding block, so the access speed will be slow.
To solve this problem, ext4 has made some changes. It introduces a new concept called Extents. let’s say a file size of 128M, if we use 4k size blocks for storage, we need 32k blocks. If it is scattered as ext2 or ext3, the number is too large. But Extents can be used to store contiguous blocks, that is, we can put 128M inside one Extents. In this way, the performance of reading and writing to large files is improved and file fragmentation is reduced.
Exents is a tree-like structure.
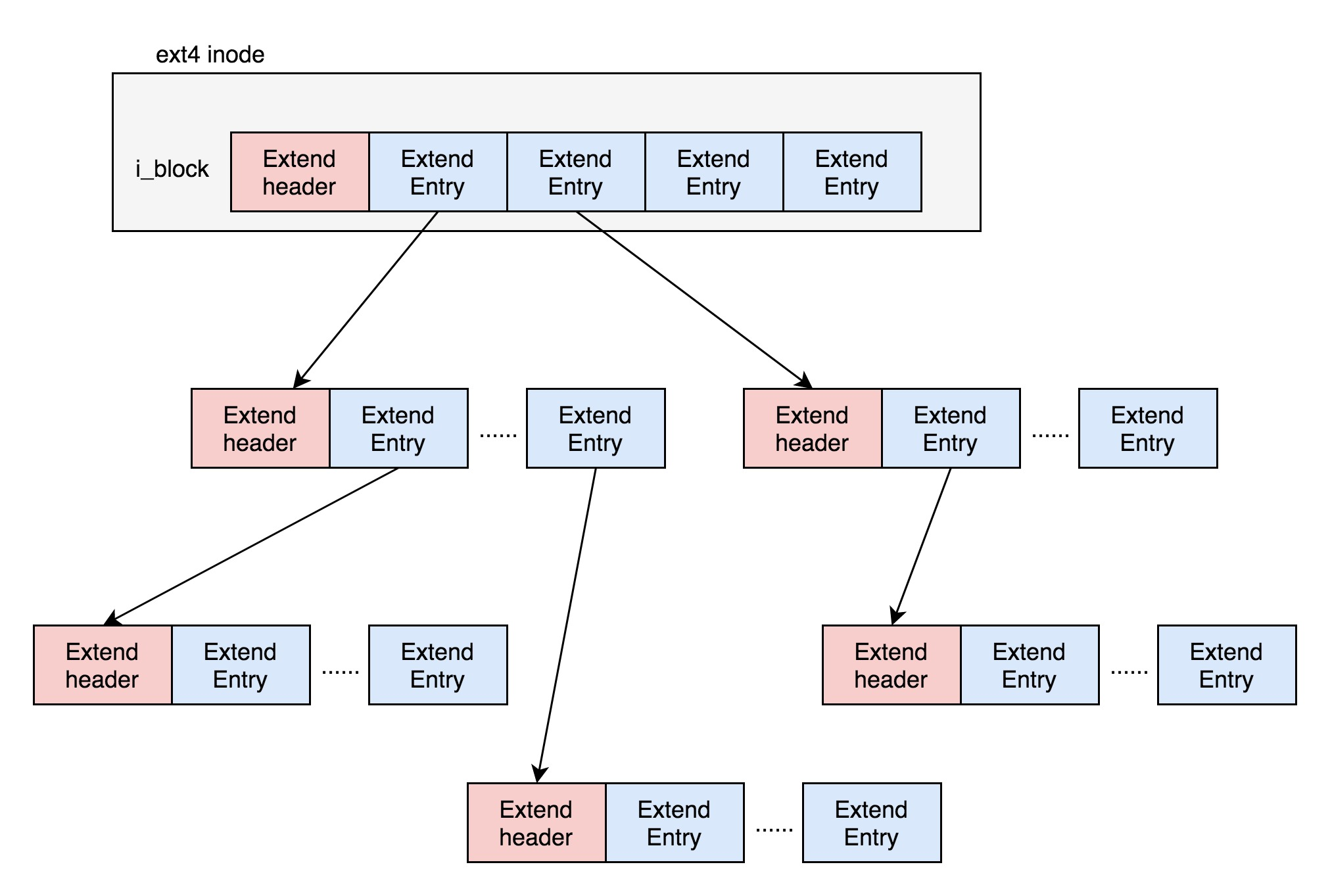
Each node has a header, ext4_extent_header can be used to describe a certain node.
|
|
eh_entries indicates how many items are inside this node. There are two types of items here: if it is a leaf node, this item will point directly to the address of a contiguous block on the hard disk, which we call the data node ext4_extent; if it is a branch node, this item will point to the next level of branch nodes or leaf nodes, which we call the index node ext4_extent_idx. The size of both types of items is 12 bytes.
|
|
If the file is not big, the i_block inside the inode can fit an ext4_extent_header and 4 ext4_extent. so at this time, eh_depth is 0, that is, the inode inside is the leaf node, and the tree height is 0.
If the file is larger and the 4 extents can’t fit, it has to split into a tree. The node with eh_depth>0 is the index node, where the root node has the greatest depth, in the inode. The bottom eh_depth=0 is the leaf node.
In addition to the root node, all other nodes are saved inside a block 4k, 4k minus 12 bytes of ext4_extent_header, the rest can put 340 items, each extent can represent a maximum of 128MB of data, 340 extents will make your representation of the file up to 42.5GB.
inode bitmaps and block bitmaps
The inode bitmap is 4k in size, each bit corresponds to an inode. if it is 1, the inode is already used, if it is 0, it is not used. the block bitmap is the same.
In Linux, if you want to create a new file, you call the open function with the parameter O_CREAT, which means that when the file is not found, we need to create one. Then the open function is called roughly as follows: to open a file, first find the folder according to the path. If the file is not found under the folder, and O_CREAT is set, then we need to create a file under the folder.
For the block bitmap, this process is also done when writing to the file.
Format of the file system
The bitmap of a data block is placed inside a block of 4k. each bit represents one data block and can represent a total of $4 1024 8 = 2^{15}$ data blocks. If each block is also 4K by default, the maximum representable space is $2^{15} 4 1024 = 2^{27}$ bytes, which is 128M, then obviously it is not enough.
This time we need to use block groups, the data structure is ext4_group_desc, which has corresponding member variables for inode bitmap bg_inode_bitmap_lo, block bitmap bg_block_bitmap_lo, and inode list bg_inode_table_lo in a block group.
In this way, one block group after another, basically constitutes the structure of our entire file system. Because there are multiple block groups, the block group descriptors likewise form a list, and we call these the block group descriptor tables.
We also need a data structure that describes the entire file system, which is the superblock ext4_super_block. s_inodes_count contains the total number of inodes in the entire file system, s_inodes_count, the total number of blocks, s_blocks_count_lo, the number of inodes per block group, s_inodes_per_group, and the number of blocks per block group. inodes_per_group, how many blocks per block group, s_blocks_per_group, etc. These are all such global information.
In the end, the whole file system format looks like the following.
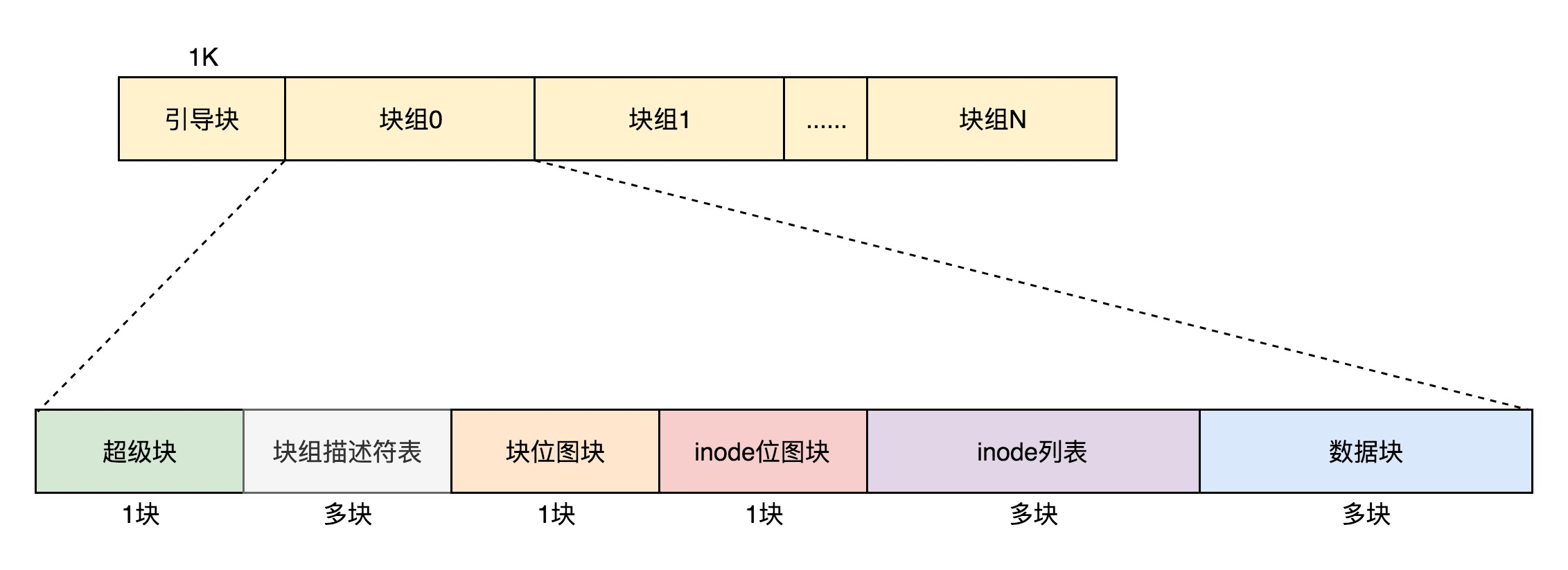
By default, copies of the superblock and block group descriptor tables are kept inside each block group. This prevents the entire file system from being opened if this data is lost.
Since it is a waste of space to keep a complete copy of the block group descriptor table inside each block group, on the one hand, and on the other hand, since the maximum size of a block group is 128M, and the number of items in the block group descriptor table limits the number of block groups, the total number of 128M * block groups is the size of the whole file system, which is limited.
Therefore Meta Block Groups feature is introduced.
First, the block group descriptor table does not hold the descriptors of all block groups anymore, but divides the block groups into multiple groups, which we call Meta Block Groups. Each Meta Block Group contains only its own block descriptor table, and a Meta Block Group contains 64 block groups, so that the maximum number of block descriptor table items in a Meta Block Group is 64.
Let’s assume there are 256 block groups in total, the original is a whole block group descriptor table, there are 256 items in it, to backup the whole backup, now divided into 4 meta block groups, each meta block group inside the block group descriptor table is only 64 items, this is much smaller, and the four meta block groups back up their own.
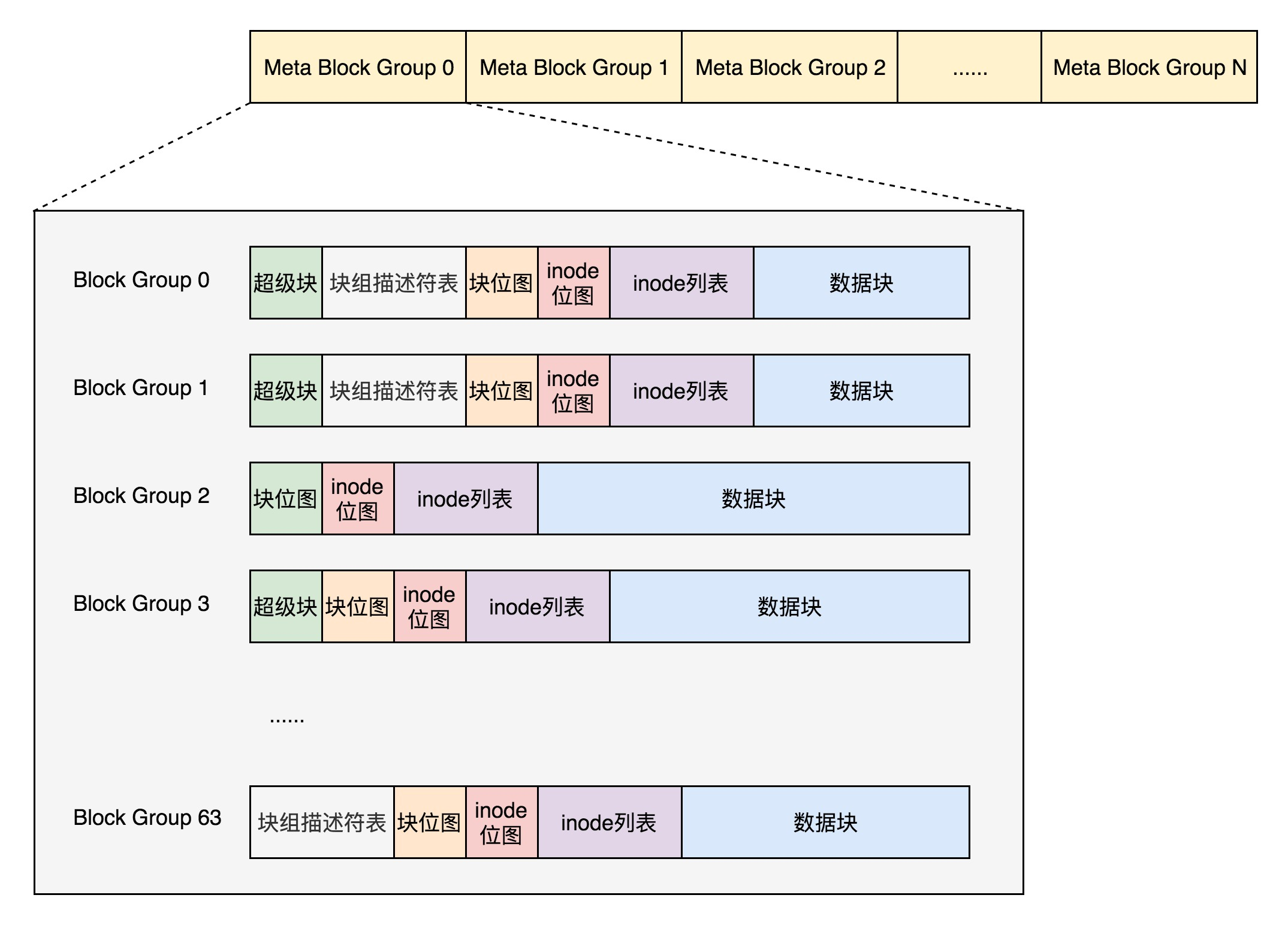
According to the figure, each meta-block group contains 64 block groups and the block group descriptor table is also 64 items, backed up in three copies, at the beginning of the first, second and last block groups of the meta-block group.
If the sparse_super feature is turned on, the copies of super blocks and block group descriptor tables are only saved in integer powers of block group indexes 0, 3, 5, and 7. So the super block in the above figure is only in integer powers with indexes 0, 3, 5, 7, etc.
The storage format of directories
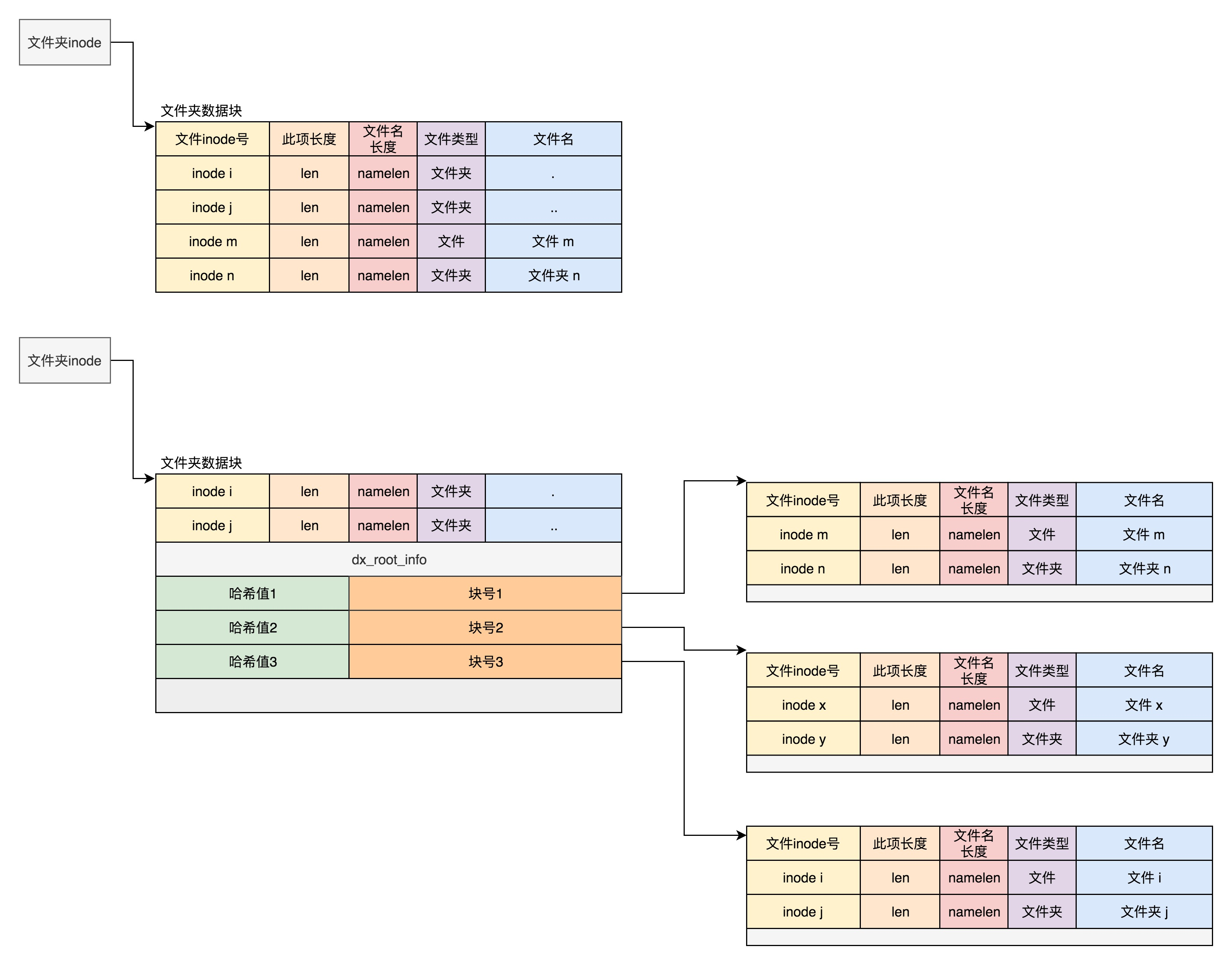
A directory is actually a file with an inode, which also points to blocks. Unlike normal files, which store file data in blocks, directory files store file-by-file information inside the directory. This information is called ext4_dir_entry.
In the block of directory files, the simplest format is a list, where each item holds the file name and corresponding inode of the next level of the directory, through which the real file can be found. The first item is “.” for the current directory, the second one is “…” for the previous directory, and the next one is the file name and inode.
If the EXT4_INDEX_FL flag is set in the inode, then it means that the file is found according to the index. The index entry maintains a mapping between the hash of a file name and a data block.
If we want to find a file name under a directory, we can take a hash by name. If the hash can match, it means that the information of this file is inside the corresponding block. Then we open the block, and if it is no longer an index, but a leaf node of the index tree, it is still a list of ext4_dir_entry, and we just have to look for the file name one by one. By using the index tree, we can spread more than one file in a directory into many blocks, so we can find them quickly.
File caching in Linux
ext4 file system layer
For the ext4 file system, the kernel defines an ext4_file_operations.
ext4_file_read_iter will call generic_file_read_iter and ext4_file_write_iter will call __generic_file_write_iter.
|
|
generic_file_read_iter and __generic_file_write_iter have similar logic to distinguish whether cache is used or not. Thus, depending on whether memory is used for caching or not, we can classify file I/O operations into two types.
The first type is cached I/O. The default I/O operation for most file systems is cached I/O. For read operations, the operating system first checks to see if the kernel has the data it needs in its buffers. If the data is already cached, it is returned directly from the cache; otherwise it is read from the disk and cached in the OS cache. For a write operation, the OS will first copy the data from user space to the kernel space cache . At this point, the write operation is complete for the user program. It is up to the operating system to decide when to write to disk again, unless the sync synchronization command is explicitly called.
The second type is direct IO, where the application accesses the disk data directly without going through the kernel buffer, thus reducing the need to copy data between the kernel cache and the user program.
If inside the write logic __generic_file_write_iter, it is found that IOCB_DIRECT is set, then generic_file_direct_write is called, which also calls the function of direct_IO of address_space to write the data directly to the hard disk.
Write operations with cache
Let’s first look at the generic_perform_write function with cached writes.
|
|
These are the main things that are done in the loop.
- for each page, first call write_begin on address_space to do some preparation.
- calling iov_iter_copy_from_user_atomic to copy the write from the user state to the kernel state page.
- call write_end of address_space to complete the write operation.
- call balance_dirty_pages_ratelimited to see if there are too many dirty pages that need to be written back to the hard disk. A dirty page is a page that is written to the cache but not yet written to the hard disk.
For the first step, which is called ext4_write_begin, there are two main things to do.
The first does logging-related work.
ext4 is a logging file system, which was introduced to prevent data loss in case of sudden power failure (Journal) mode. The journal file system has an additional Journal area than the non-journal file system. The file is stored in ext4 in two parts, one for the file metadata and the other for the data. Journal is also managed separately for metadata and data operations. You can select the Journal mode when mounting ext4. This mode has to wait until the logs of metadata and data have fallen off the disk before writing data to the file system to function. This is worse in performance, but the safest.
The other mode is Order mode. This mode does not log the data, only the metadata, but you must make sure that the data has fallen off the disk before writing the log of the metadata. This is a compromise and is the default mode.
Another mode is writeback, which does not log the data, only the metadata, and does not guarantee that the data is dropped before the metadata. This has the best performance, but is the least secure.
The second call to grab_cache_page_write_begin comes and gets the cache page that should be written.
|
|
In the kernel, the cache is placed in memory in pages. Each open file has a struct file structure, and each struct file structure has a struct address_space for associating the file with memory.
For the second step, call iov_iter_copy_from_user_atomic. first map the allocated page to a virtual address inside the kernel by calling kmap_atomic, then copy the user state data to the virtual address of the kernel state page, and call kunmap_atomic to remove the mapping inside the kernel.
|
|
In the third step, ext4_write_end is called to finish writing. This calls ext4_journal_stop to finish writing the journal, and block_write_end->__block_commit_write->mark_buffer_dirty to mark the modified cache as a dirty page. As you can see, the so-called finished write is not actually written to the hard disk, but simply written to the cache and marked as dirty pages .
The fourth step, calling balance_dirty_pages_ratelimited, is to write back the dirty pages.
|
|
Inside balance_dirty_pages_ratelimited, if the number of dirty pages is found to exceed the specified number, balance_dirty_pages->wb_start_background_writeback is called, starting a thread behind it to start writing back.
There are several other scenarios that trigger a writeback.
- user-initiated calls to sync, which flushes the cache to the hard disk and eventually calls wakeup_flusher_threads, which synchronizes dirty pages.
- when memory is so tight that pages cannot be allocated, free_more_memory is called, and eventually wakeup_flusher_threads is called, freeing the dirty pages.
- Dirty pages have been updated for a longer period of time than the set time and need to be written back in time to maintain data consistency in memory and on disk.
Read operations with cache
Look at read with cache, which corresponds to the function generic_file_buffered_read.
|
|
In the generic_file_buffered_read function, we need to find out if there is a cached page inside the page cache first. If not, we not only read the page, but also do a pre-read, which is done in the page_cache_sync_readahead function. After the pre-reading, try to find the cache page again.
If the cache page is found the first time, we still have to determine if we should continue the pre-reading; if needed, we call page_cache_async_readahead to initiate an asynchronous pre-reading.
Finally, copy_page_to_iter copies the contents from the kernel cache page into user memory space.