1. layering of monitoring
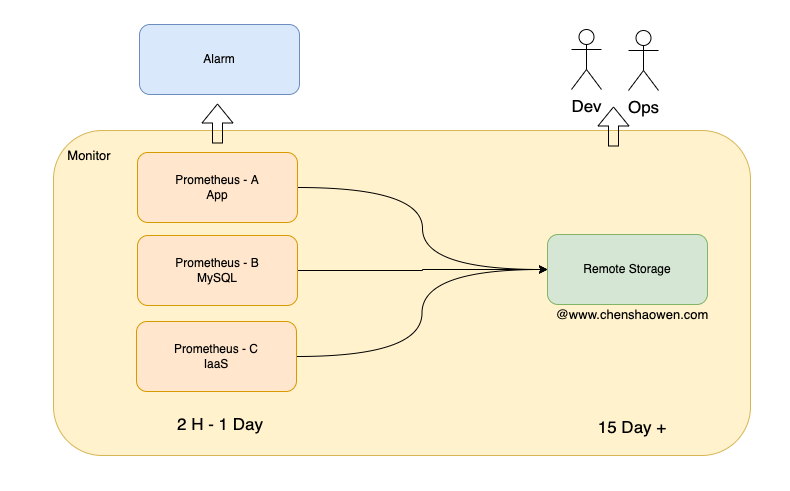
As shown above, two strategies are used when building a monitoring system:
- The advantage of separating IaaS, MySQL middleware, and App tier monitoring is that the systems are highly available and fault-tolerant to each other. When the App tier monitoring does not work, the IaaS tier monitoring will immediately show up.
- Separation of long and short term metrics. Short-term metrics are used to provide alerting systems with high frequency queries for recent data, and long-term metrics are used to provide people with queries for data sets that span a larger period of time.
This is collectively referred to here as a layering strategy for monitoring, except that one is layered in the infrastructure dimension and one is layered in the time dimension.
2. Current Situation and Selection
The current situation is that there is no long- and short-term stratification of monitoring, and a common set of Prometheus. When querying long-period metrics, the memory and CPU usage of the server where Prometheus is located rises sharply, even causing monitoring and alerting services to be unavailable.
The reason is twofold:
- Prometheus loads a lot of data into memory when querying long-period data.
- Prometheus is not loading downsampled data
The larger the range of queries, the more memory is needed. In another production scenario, we used VictoriaMetrics standalone as remote storage, deploying up to 128 GB of memory. Also, there was data loss in this approach.
The Prometheus Federation approach, on the other hand, only addresses the aggregation of multiple Prometheus, and does not provide the ability to sample and accelerate long-term metrics queries, which is not applicable to the current remote storage scenario.
Finally, seeing that the Thanos Compact component can compress and downsample metrics data, I decided to try using Thanos as the current remote storage for multiple Prometheus.
3. Several ways to deploy Thanos
3.1 Basic components
- Query, which implements the Prometheus API and provides a Prometheus-compliant query interface to the outside world
- Sidecar, which is used to connect to Prometheus, providing Query query interface, and can also report data
- Store Gateway, which accesses metric data placed in object stores
- Compactor, which compresses samples and cleans up data in the object store
- Receiver, receives data from Prometheus Remote Write
- Ruler, configures and manages alerting rules
3.2 Receive mode
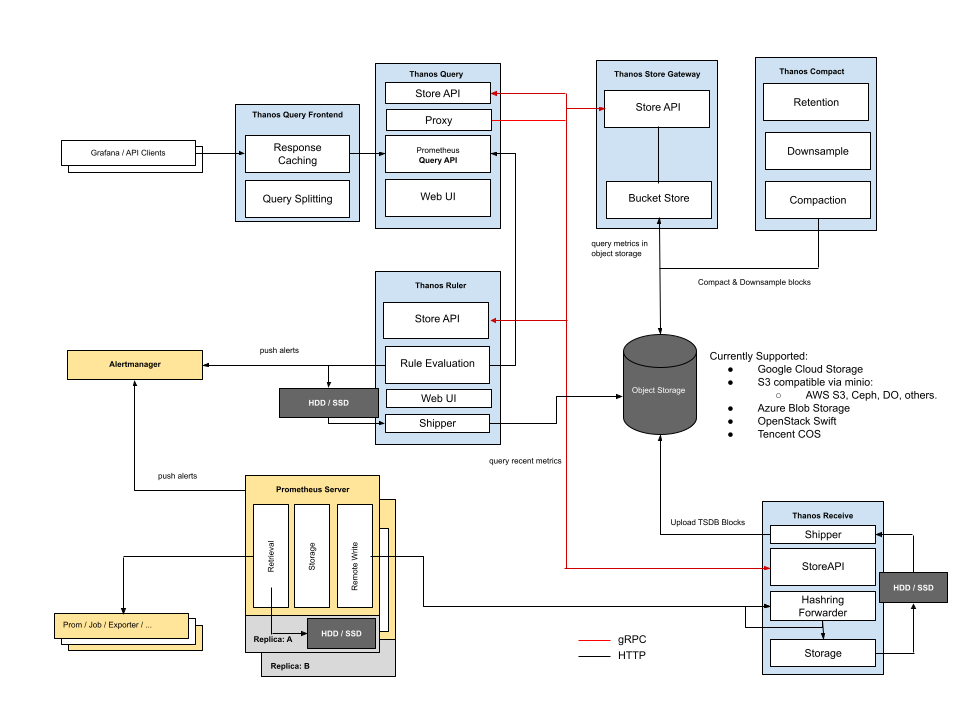
In Receive mode, you need to configure a remote write in each Prometheus instance to upload data to Thanos, where the real-time data is stored in the Thanos Receiver, so the Sidecar component is not needed to complete the query.
Benefits.
- Data centralization
- Prometheus is stateless
- Only the Receiver needs to be exposed for Prometheus to access
Disadvantages:
- Receiver is subject to a lot of remote write writes from Prometheus
3.3 Sidecar mode
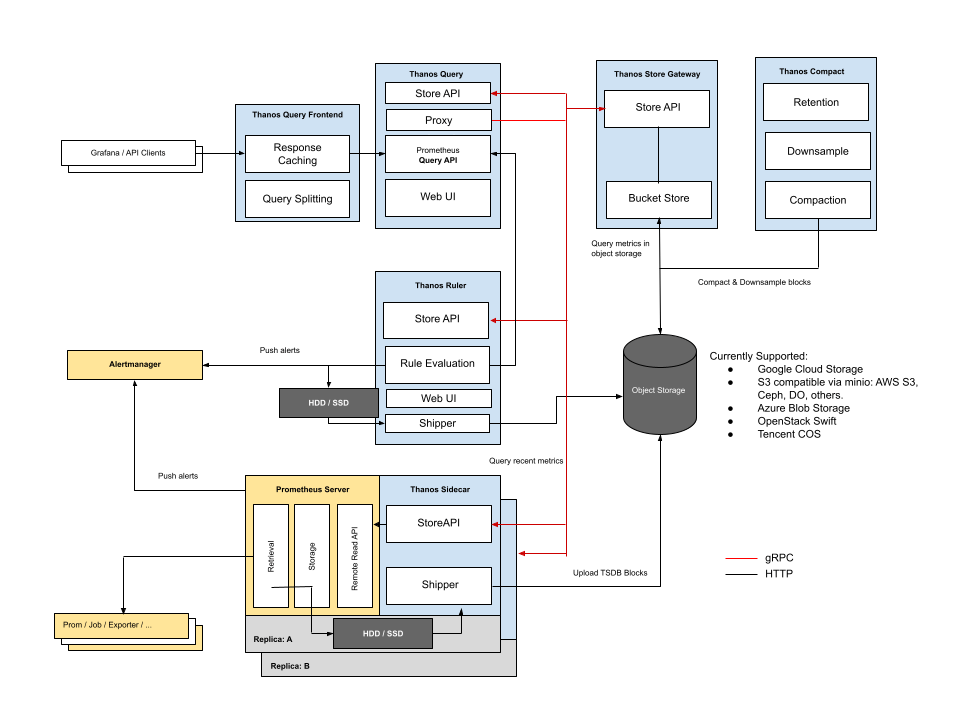
In Sidecar mode, a Thanos Sidecar component is added next to each Prometheus instance to enable management of Prometheus. There are two main functions.
- Accepting query requests from the Query component. When Thanos queries short-term data, the request will go to Sidecar.
- Uploading short-term metrics data for Prometheus. By default, every two hours, a block is created and uploaded to the object store.
Advantages:
- Easy integration, no need to modify the original configuration
Disadvantages:
- Recent data requires network requests between Query and Sidecar, which adds additional time.
- Requires Store Gateway to have access to each Prometheus instance
4. Deploying Thanos
4.1 Deploying a Minio
Please consult the official documentation.
Once the installation is complete, test the configuration according to the documentation to ensure that the Minio service works properly.
4.2 Create a Bucket named thanos on Minio
as follows.
4.3 Checking Prometheus version compliance with Thanos requirements
Currently Thanos requires that Prometheus version should preferably be no lower than v2.13.
4.4 Deploying Thanos
- Ensure that default storage is available on the Kubernetes cluster
- Create a new namespace thanos
|
|
- Deploying Thanos
|
|
Modify the Minio access address in the demo/objectstorage.yaml* View related loads file. Then create the Thanos-related load.
|
|
- View related loads
Deploying Thanos consumes few resources.
4.5 Accessing Thanos Query
- View the ports of Thanos related services
|
|
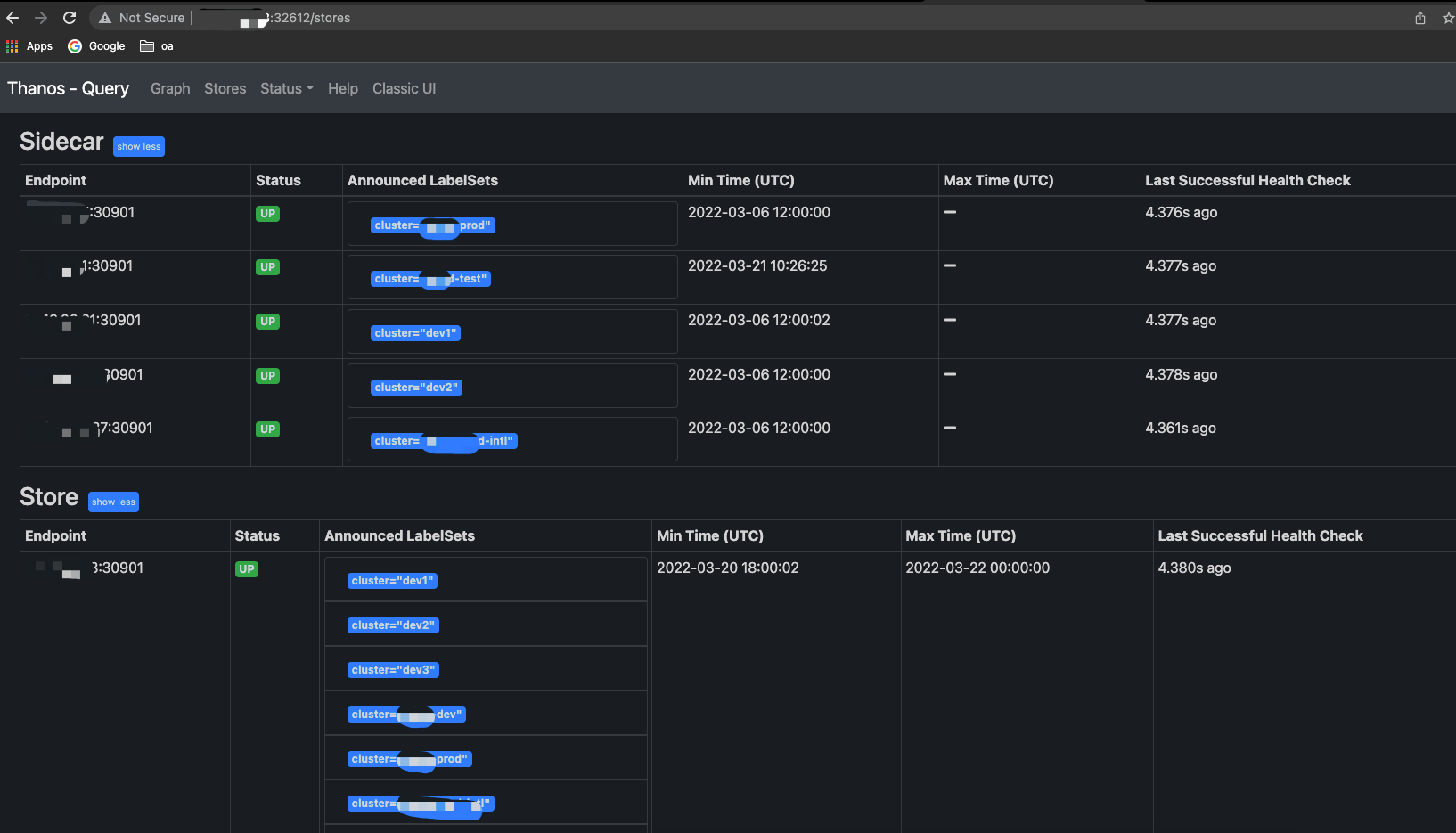
- Accessing the Thanos Query page
thanos-query provides an http access portal on port 9090, so here the pages provided by the Query component are accessed through the host IP:32612 port.
5. Add Thanos Sidecar to Prometheus
Sidecar mode requires less Thanos configuration, while Receiver mode needs to keep receiving Remote Write from many Prometheus, so Sidecar mode is chosen here for cost reasons.
5.1 Add S3 access credentials to the Prometheus namespace
|
|
The administrator account is used directly here. For production, a separate account should be created for Thanos’ use of Minio.
5.2 Adding additional Label tag instances to Prometheus
By adding external_labels to Prometheus you can add an additional label to each Prometheus instance globally to uniquely mark an instance.
- Edit the configuration file
|
|
- Add the following
A tag named cluster=dev has been added here. All metrics reported by this Prometheus instance will carry this tag for easy querying and filtering.
5.3 Modifying Prometheus startup parameters to turn off compression
- Edit the Prometheus deployment file
Some deployments are done with Deployment and some are done with StatefulSet, both need to modify the Prometheus startup parameters
|
|
- Modify tsdb to store blocks with equal maximum and minimum values
storage.tsdb.min-block-duration and storage.tsdb.max-block-duration are equal to guarantee that Prometheus has local compression turned off to avoid Thanos upload failures when compressing.
5.4 Adding Thanos Sidecar to Prometheus
- Edit the Prometheus deployment file
|
|
- Add the following containers
|
|
- New mount secret key
- Reboot Prometheus
Rolling upgrades will encounter the following error, caused by the previous Prometheus Pod not releasing the file directory.
|
|
So you need to set the number of copies to 0 first, then set it to 1 and restart Prometheus.
5.5 Adding a Grpc Remote Access Port to Prometheus Sidecar
- Edit the Prometheus Service configuration
|
|
- Add a Service port to expose the Grpc service to Thanos Store Gateway
5.6 Adding Store Grpc Addresses to Thanos Query
Finally, you need to add the Grpc address of the Prometheus Sidecar above to the Thanos Store Gateway.
- Edit Thanos Query
|
|
- Add
--store=0.0.0.0:30901to the startup parameters
|
|
Here 0.0.0.0:30901 needs to be replaced with the Grpc access portal exposed by Prometheus Sidecar above. This way, when Thanos Query provides query capabilities, short-term data will call Grpc queries instead of querying data in the object store.
At this point, the Thanos Query page mentioned above and the new 0.0.0.0:30901 Endpoint record can be seen, and the status should be Up.
5.7 Viewing synchronized data in Minio
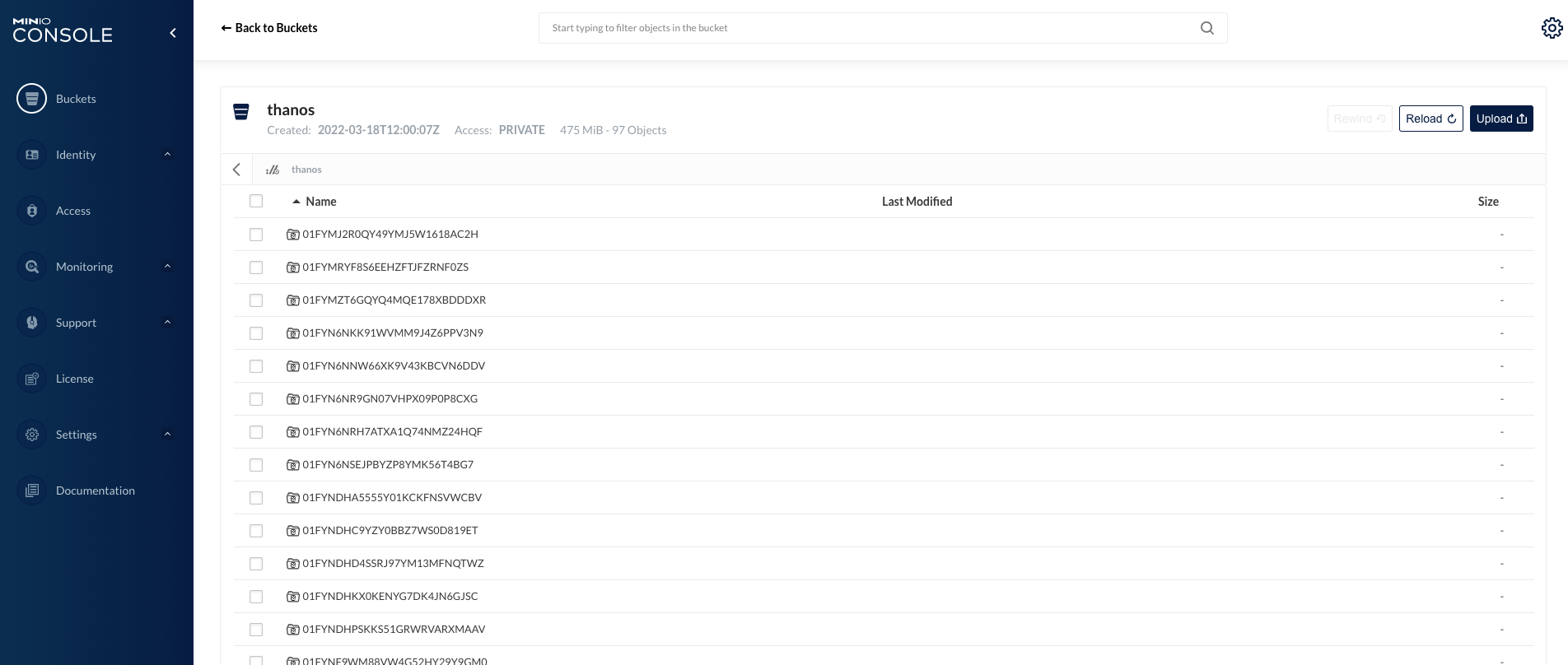
A total of 6 clusters were added, each with about 40 Pods, using about 2.1 GB of storage and 303 objects in half a day.
6. Grafana Configuration
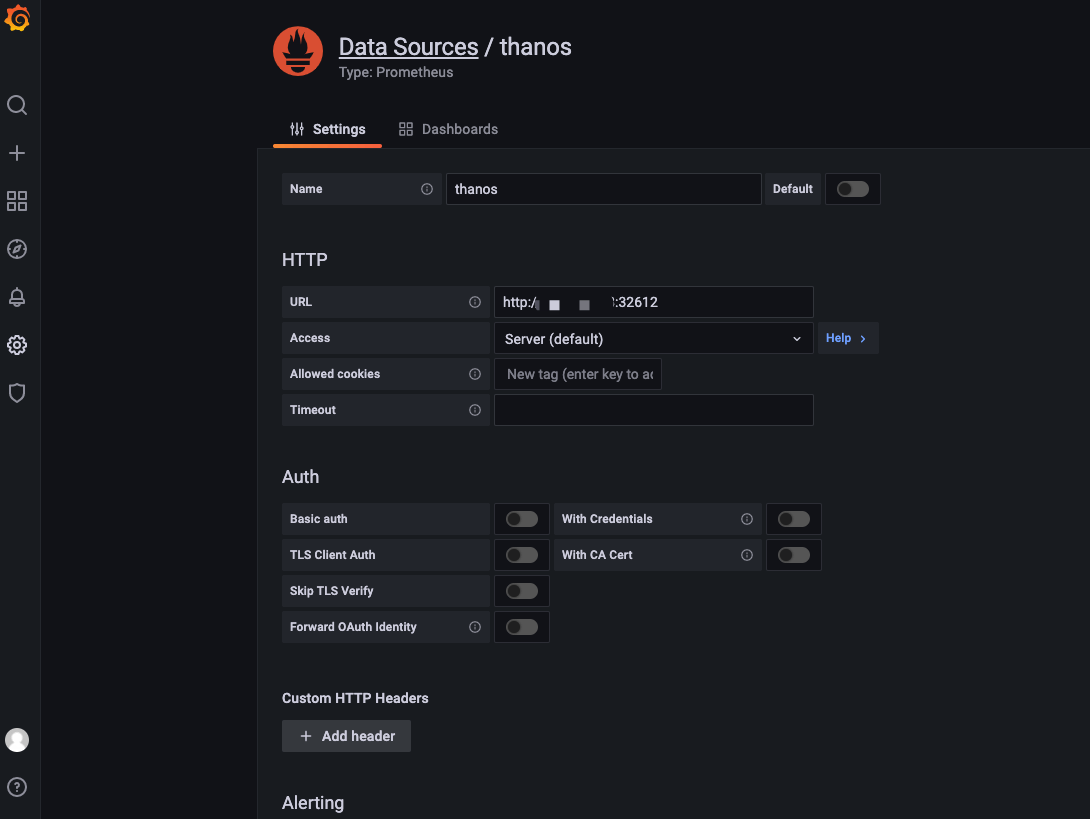
6.1 Adding a Data Source
Adding a Thanos Query data source to Grafana is done in the same way as adding Prometheus. As shown in the following figure.
6.2 Modifying the Grafana panel to accommodate cluster tag filtering
Here is a slight modification to the Kubernetes cluster-based view panel.
- Add variables for cluster filtering
Above, I added a global external_labels to each Prometheus to distinguish between clusters by the cluster field.

As shown above, add a Cluster variable to the panel and filter it using the cluster tag in the metrics.
- Edit the filtering query criteria for each view
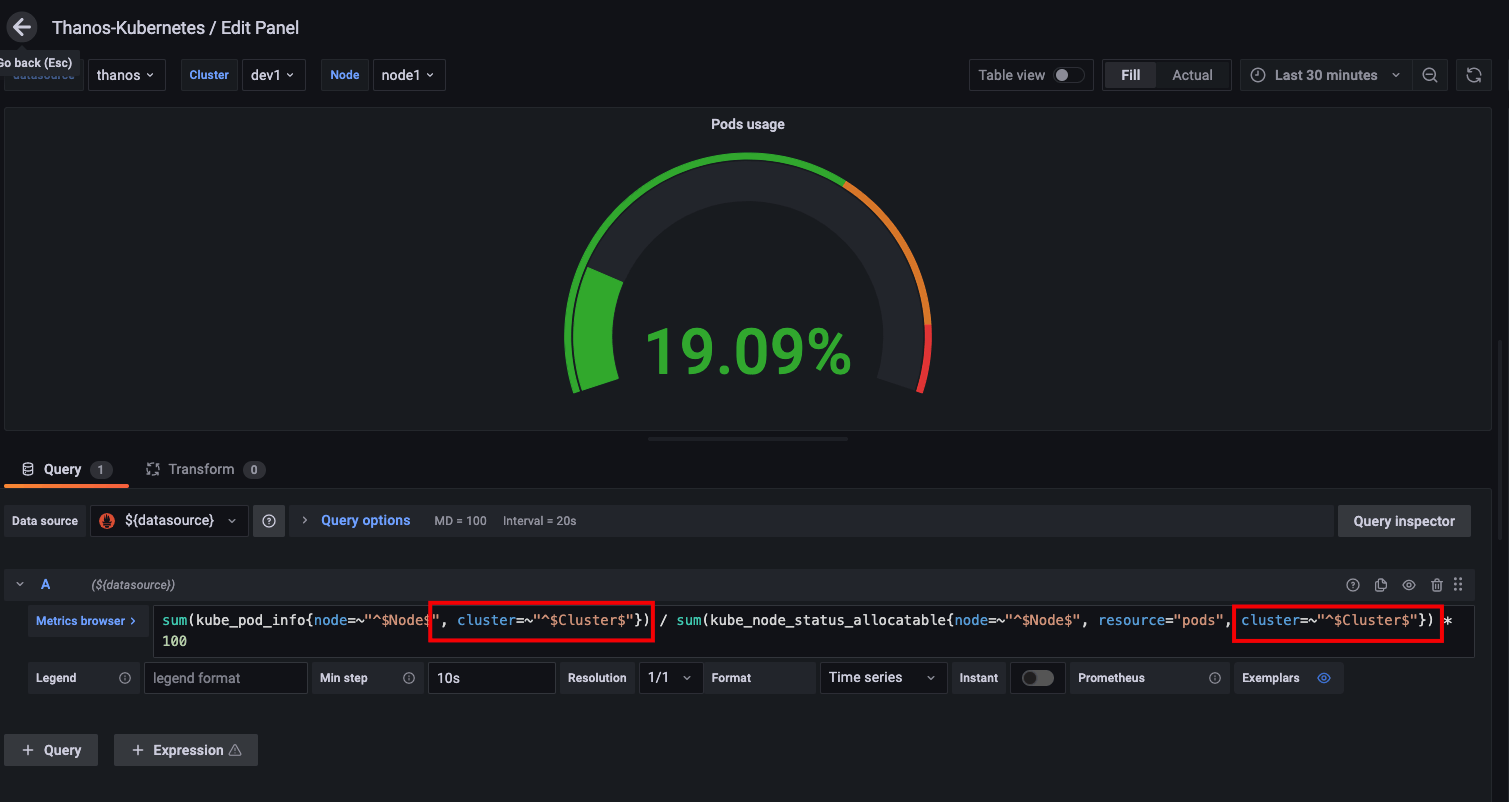
As shown above, you need to add an additional filter condition, cluster=~"^$Cluster$"}, to the expression of each view. Of course, you can also export the panel, make bulk changes in the editor, and then import it into Grafana.
6.3 Viewing Thanos and Prometheus Data Sources
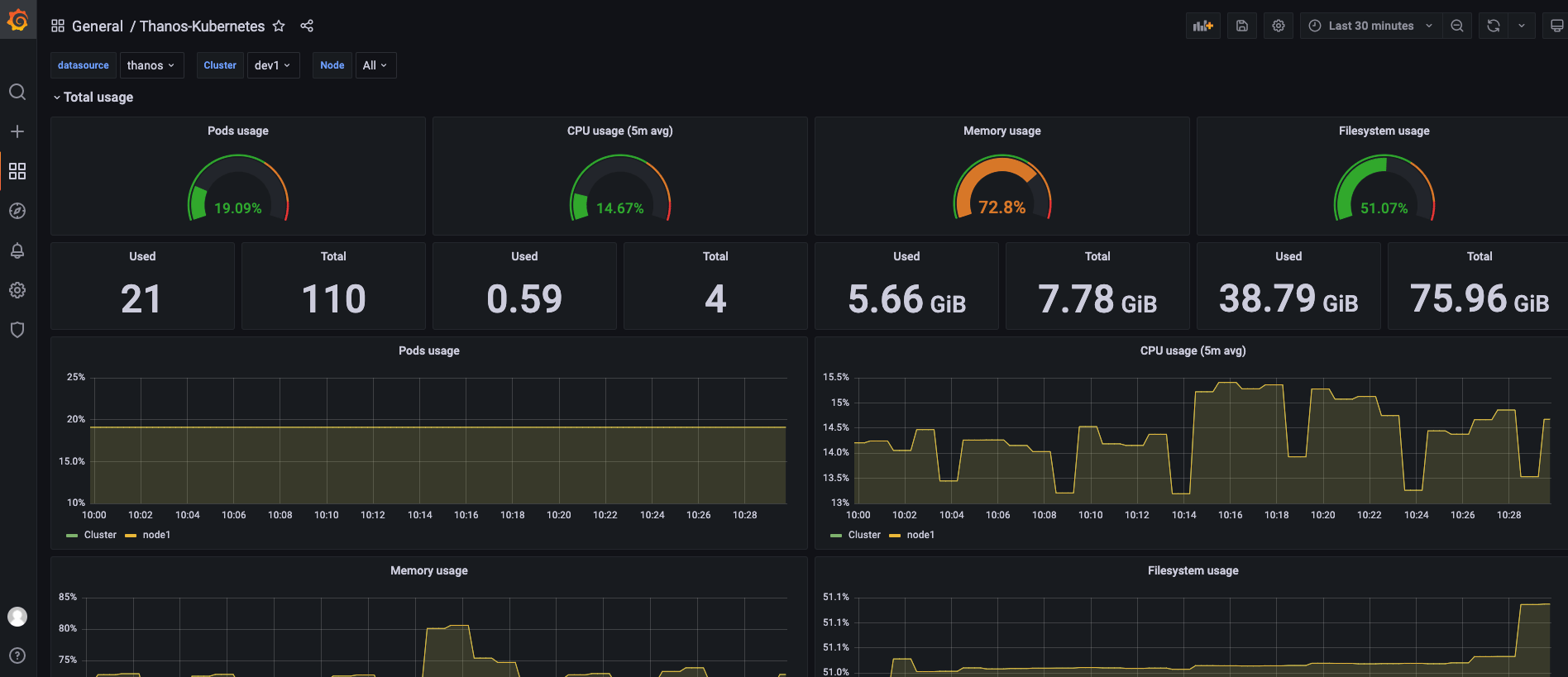
- Using the Thanos data source
- Using the Prometheus data source
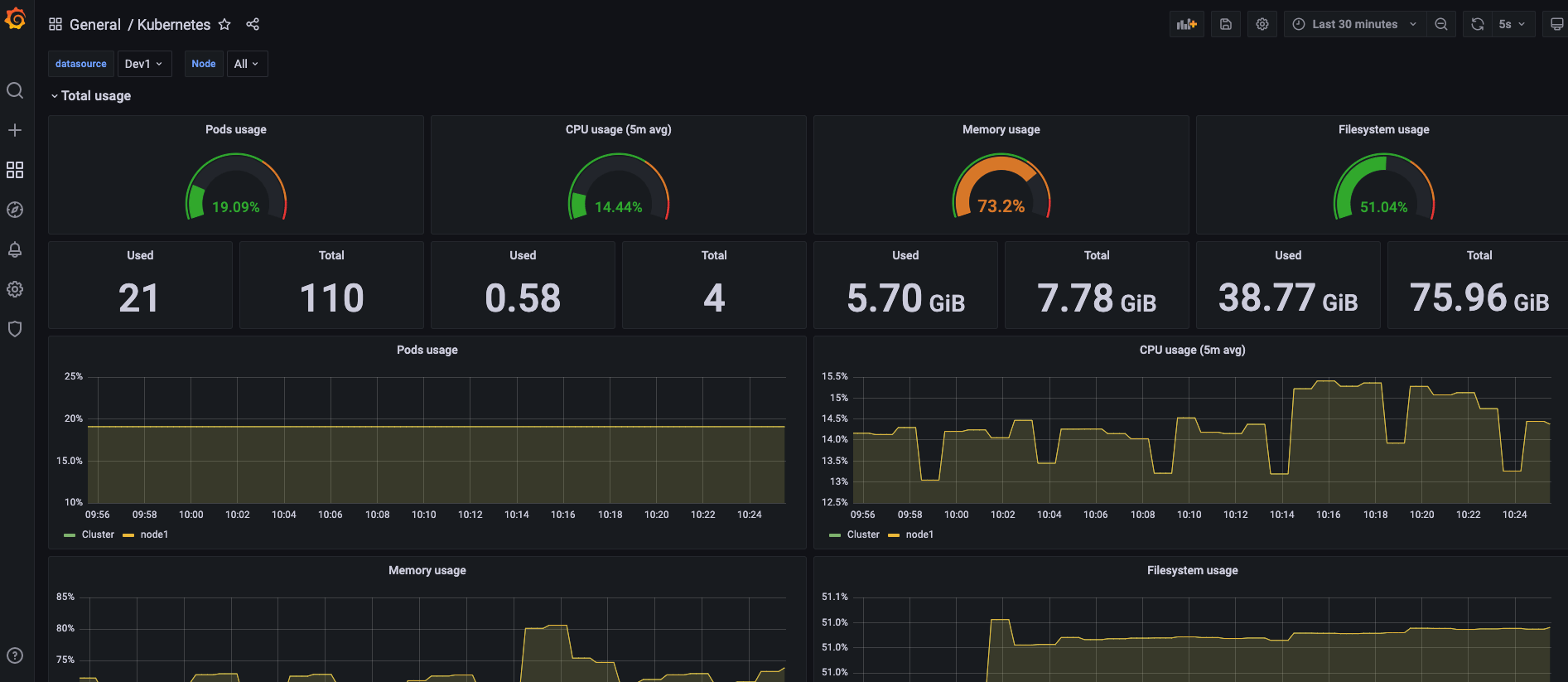
Comparing the data from both panels, we can see that they show the same metrics. Therefore, we can use one Thanos data source instead of a scenario where multiple Prometheus data sources are managed decentralized.
Here the time scale of the data does not reach the parameter settings of the Thanos Compact component, so the effect of downsampling is not reflected.
7. Summary
This article is mainly about some ideas for monitoring data layer management.
First of all, the data should be tiered, with short-term data stored directly in the nearest Prometheus and long-term data stored in Thanos’ object storage. Short-term data is provided to the alarm system for high-frequency queries, and long-term data is provided to people for analysis.
The main reason for choosing Thanos is its downsampling; the Thanos compact component provides 5-minute and 1-hour downsampling, and with Prometheus sampling every 15s, the compression will be 20x and 240x, which can greatly relieve the pressure of long-period queries. In Sidecar mode, short-term data is queried through Grpc using Prometheus’ API.
Finally, of course, all 6 local clusters are connected to Thanos, and only after trying it out, we can really appreciate some of the details and processing logic. I’ve read a lot of architecture diagrams, documents and blogs, but it’s not as good as trying it out myself.