The previous article, Kubelet Pod Creation Workflow, explained how kubelet creates pods and how the components collaborate with each other. Based on the previous article, this article will explain how kubelet performs quality of service management for pods.
Pod QoS
Kubernetes has a QoS type for each Pod, which is used to manage the quality of service for the Pod. There are three types, in decreasing order of priority.
- Guaranteed: Each container in a Pod must have a request and a limit, and the values must be the same.
- Burstable: At least one container in the Pod has a request value set for cpu or memory; * BestEffort: The Pod has a request value set for cpu or memory.
- BestEffort: all containers in the Pod do not specify cpu and memory requests and limits.
When machine resources are insufficient, kubelet will treat the Pod unfairly based on its QoS level. For seizable resources, such as CPU, when resources are tight, time slices are allocated in proportion to requests, and CPUs are slowed down if they reach the CPU resource limit limit of a Pod; while for non-seizable resources, such as memory and disk, when resources are tight, pods are evicted or OOMKill according to QoS levels.
Cgroups
Cgroups stands for Control Groups, a mechanism provided by the Linux kernel to limit, record, and isolate the physical resources (such as cpu, memory, i/o, etc.) used by process groups.
The cgroups structure is used to represent the resource limits of a control group to one or more cgroups subsystems. Each cgroups structure is called a cgroups hierarchy. cgroups hierarchies can attach one or more cgroups subsystems, and the current hierarchy can restrict resources to the cgroups subsystems it attaches to; each cgroups subsystem can only be attached to one cpu hierarchy. can only be attached to one cpu hierarchy.
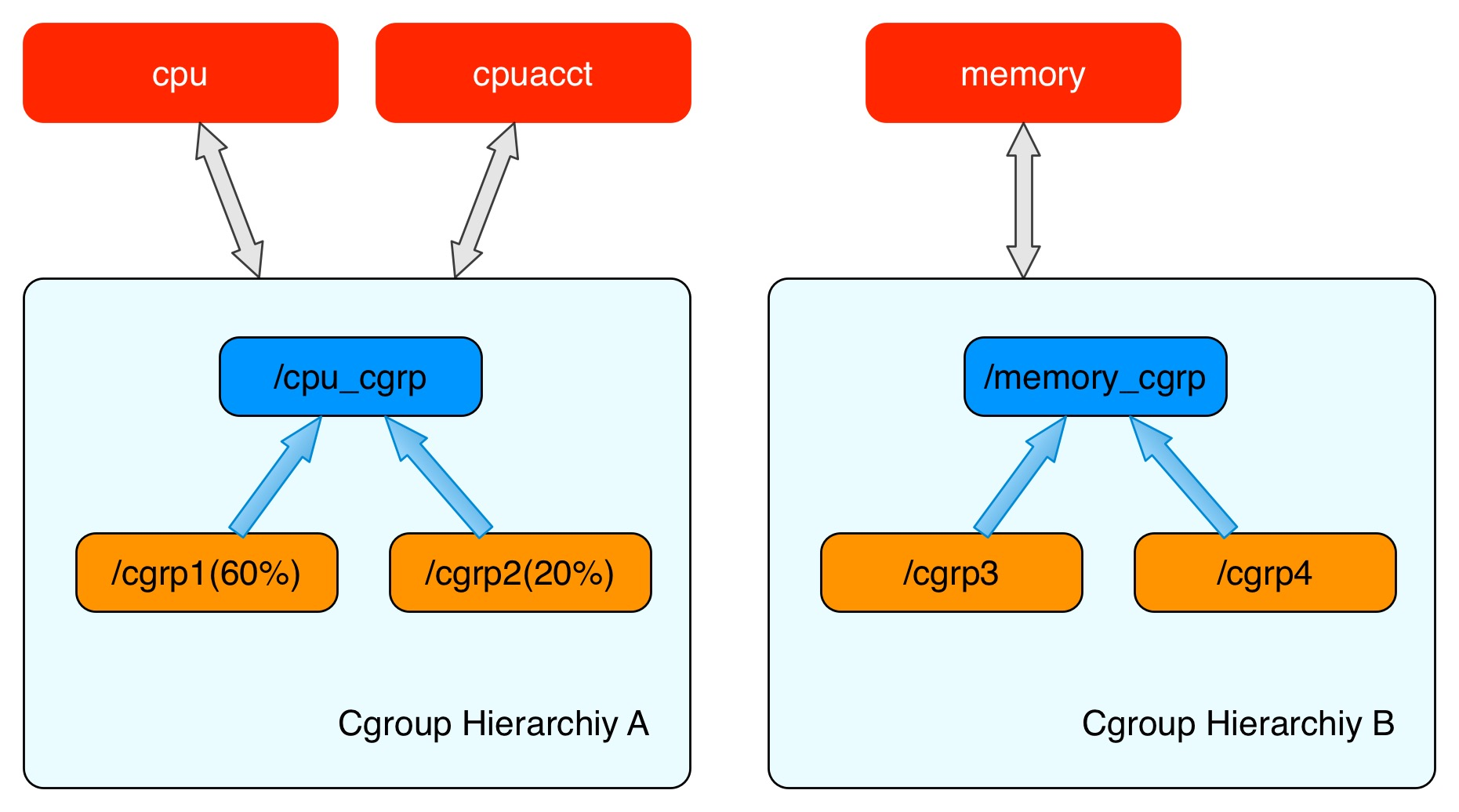
Where the cpu subsystem restricts process access to the CPU, each parameter exists independently in a pseudo-file in the cgroups virtual file system, and the parameters are explained as follows.
| key |
desc |
| cpu.shares |
cgroup’s allocation of time. For example, if cgroup A is set to 100 and cgroup B is set to 200, then the tasks in B will take twice as long to get cpu as the tasks in A. |
| cpu.cfs_period_us |
The period of the fully fair scheduler’s adjusted time quota. |
| cpu.cfs_quota_us |
The amount of time the full fair scheduler can occupy in its cycle. |
| cpu.stat |
cpu running statistics |
Cgroups in K8s
In kubernetes, in order to limit the use of container resources and prevent containers from competing for resources or affecting their hosts, the kubelet component needs to limit the use of container resources using cgroups. cgroups currently support limiting multiple resources for a process, while kubelet only supports limiting cpu, memory, pids, and hugetlb resources.
When kubelet starts, it resolves the root cgroups on the node and creates a sub-cgroups called kubepods under it. three levels of cgroups file tree are created under kubepods.
- QoS level: Two QoS level cgroups, named Burstable and BestEffort, exist as the parent cgroups of all pods at their respective QoS levels
- pod level: When creating a pod, you need to create pod level cgroups under the QoS cgroups corresponding to the pod. for Guaranteed Qos corresponding pods, the pod cgroups are created directly in the kubepods cgroups of the same level.
- container level: when creating a specific container within a pod, pod level cgroups continue to create the corresponding container level cgroups.
Resolving Root Cgroups
Let’s start by looking at how kubelet resolves root group cgroups.
The kubelet manages pod QoS levels through the component qosContainerManager, which is a member of the component containerManager, and constructs the qosContainerManager when constructing the containerManager, look at the following code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
func NewContainerManager(mountUtil mount.Interface, cadvisorInterface cadvisor.Interface, nodeConfig NodeConfig, failSwapOn bool, devicePluginEnabled bool, recorder record.EventRecorder) (ContainerManager, error) {
...
cgroupRoot := ParseCgroupfsToCgroupName(nodeConfig.CgroupRoot)
cgroupManager := NewCgroupManager(subsystems, nodeConfig.CgroupDriver)
if nodeConfig.CgroupsPerQOS {
if nodeConfig.CgroupRoot == "" {
return nil, fmt.Errorf("invalid configuration: cgroups-per-qos was specified and cgroup-root was not specified. To enable the QoS cgroup hierarchy you need to specify a valid cgroup-root")
}
if !cgroupManager.Exists(cgroupRoot) {
return nil, fmt.Errorf("invalid configuration: cgroup-root %q doesn't exist", cgroupRoot)
}
klog.Infof("container manager verified user specified cgroup-root exists: %v", cgroupRoot)
cgroupRoot = NewCgroupName(cgroupRoot, defaultNodeAllocatableCgroupName)
}
klog.Infof("Creating Container Manager object based on Node Config: %+v", nodeConfig)
qosContainerManager, err := NewQOSContainerManager(subsystems, cgroupRoot, nodeConfig, cgroupManager)
if err != nil {
return nil, err
}
...
}
|
Before constructing the qosContainerManager, the root of the pod cgroup managed by the kubelet is assembled and passed into the constructor, <rootCgroup>/kubepods.
Once constructed, when the containerManager is started, it initializes and starts all the subcomponents, including the qosContainerManager, which is started by calling the setupNode function.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
func (cm *containerManagerImpl) Start(node *v1.Node,
activePods ActivePodsFunc,
sourcesReady config.SourcesReady,
podStatusProvider status.PodStatusProvider,
runtimeService internalapi.RuntimeService) error {
...
// cache the node Info including resource capacity and
// allocatable of the node
cm.nodeInfo = node
if utilfeature.DefaultFeatureGate.Enabled(kubefeatures.LocalStorageCapacityIsolation) {
rootfs, err := cm.cadvisorInterface.RootFsInfo()
if err != nil {
return fmt.Errorf("failed to get rootfs info: %v", err)
}
for rName, rCap := range cadvisor.EphemeralStorageCapacityFromFsInfo(rootfs) {
cm.capacity[rName] = rCap
}
}
// Ensure that node allocatable configuration is valid.
if err := cm.validateNodeAllocatable(); err != nil {
return err
}
// Setup the node
if err := cm.setupNode(activePods); err != nil {
return err
}
...
return nil
}
|
In the setupNode function, the createNodeAllocatableCgroups function is called to resolve the node’s root cgroups and then start the qosContainerManager.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func (cm *containerManagerImpl) setupNode(activePods ActivePodsFunc) error {
...
// Setup top level qos containers only if CgroupsPerQOS flag is specified as true
if cm.NodeConfig.CgroupsPerQOS {
if err := cm.createNodeAllocatableCgroups(); err != nil {
return err
}
err = cm.qosContainerManager.Start(cm.getNodeAllocatableAbsolute, activePods)
if err != nil {
return fmt.Errorf("failed to initialize top level QOS containers: %v", err)
}
}
...
}
|
Finally, let’s take a closer look at the createNodeAllocatableCgroups function and explore how kubelet resolves the root cgroups of nodes.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
func (cm *containerManagerImpl) createNodeAllocatableCgroups() error {
nodeAllocatable := cm.internalCapacity
// Use Node Allocatable limits instead of capacity if the user requested enforcing node allocatable.
nc := cm.NodeConfig.NodeAllocatableConfig
if cm.CgroupsPerQOS && nc.EnforceNodeAllocatable.Has(kubetypes.NodeAllocatableEnforcementKey) {
nodeAllocatable = cm.getNodeAllocatableInternalAbsolute()
}
cgroupConfig := &CgroupConfig{
Name: cm.cgroupRoot,
// The default limits for cpu shares can be very low which can lead to CPU starvation for pods.
ResourceParameters: getCgroupConfig(nodeAllocatable),
}
if cm.cgroupManager.Exists(cgroupConfig.Name) {
return nil
}
if err := cm.cgroupManager.Create(cgroupConfig); err != nil {
klog.Errorf("Failed to create %q cgroup", cm.cgroupRoot)
return err
}
return nil
}
func getCgroupConfig(rl v1.ResourceList) *ResourceConfig {
// TODO(vishh): Set CPU Quota if necessary.
if rl == nil {
return nil
}
var rc ResourceConfig
if q, exists := rl[v1.ResourceMemory]; exists {
// Memory is defined in bytes.
val := q.Value()
rc.Memory = &val
}
if q, exists := rl[v1.ResourceCPU]; exists {
// CPU is defined in milli-cores.
val := MilliCPUToShares(q.MilliValue())
rc.CpuShares = &val
}
if q, exists := rl[pidlimit.PIDs]; exists {
val := q.Value()
rc.PidsLimit = &val
}
rc.HugePageLimit = HugePageLimits(rl)
return &rc
}
|
As you can see, the createNodeAllocatableCgroups function essentially sets the root group Cgroup based on the available cpu, memory, Pid, HugePageLimits, etc. of the node obtained from cm.internalCapacity, which sets the memory limit, cpu share, Pid limit, and hugePageLimit. cpu share, Pid limit and hugePageLimit. The name of the root group cgroup is the kubepods directory passed in before building the qosContainerManager.
The cm.internalCapacity is obtained from the CAdvisor when the containerManager is initialized; when the user uses the Node Allocatable feature, the node’s reserved resources are set according to the parameters filled in by the user.
Qos-level cgroups
After the root group cgroups are set, let’s take a look at the qosContainerManager startup function.
As shown in the figure below, the root group cgroups (path /kubepods) are first fetched, which is the result of the previous parsing step.
Then the QoS-level cgroups are created, where the Guaranteed cgroup path is the root group, the Burstable cgroup path is /kubepods/burstable, and the BestEffort cgroup path is /kubepods/besteffort, and the cpushare of the latter two types starts at 0.
Finally, a concurrent program is started to execute the UpdateCgroups function at regular intervals to synchronize the corresponding cgroups according to the pods of each QoS type.
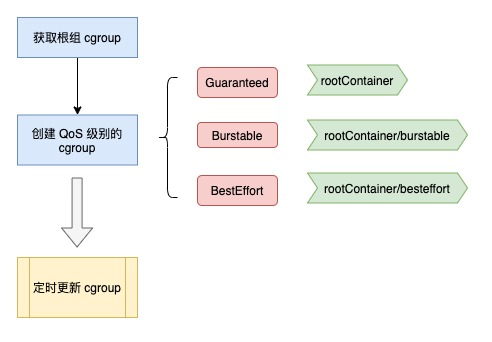
The source code is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
func (m *qosContainerManagerImpl) Start(getNodeAllocatable func() v1.ResourceList, activePods ActivePodsFunc) error {
cm := m.cgroupManager
rootContainer := m.cgroupRoot
if !cm.Exists(rootContainer) {
return fmt.Errorf("root container %v doesn't exist", rootContainer)
}
// Top level for Qos containers are created only for Burstable
// and Best Effort classes
qosClasses := map[v1.PodQOSClass]CgroupName{
v1.PodQOSBurstable: NewCgroupName(rootContainer, strings.ToLower(string(v1.PodQOSBurstable))),
v1.PodQOSBestEffort: NewCgroupName(rootContainer, strings.ToLower(string(v1.PodQOSBestEffort))),
}
// Create containers for both qos classes
for qosClass, containerName := range qosClasses {
resourceParameters := &ResourceConfig{}
// the BestEffort QoS class has a statically configured minShares value
if qosClass == v1.PodQOSBestEffort {
minShares := uint64(MinShares)
resourceParameters.CpuShares = &minShares
}
// containerConfig object stores the cgroup specifications
containerConfig := &CgroupConfig{
Name: containerName,
ResourceParameters: resourceParameters,
}
// for each enumerated huge page size, the qos tiers are unbounded
m.setHugePagesUnbounded(containerConfig)
// check if it exists
if !cm.Exists(containerName) {
if err := cm.Create(containerConfig); err != nil {
return fmt.Errorf("failed to create top level %v QOS cgroup : %v", qosClass, err)
}
} else {
// to ensure we actually have the right state, we update the config on startup
if err := cm.Update(containerConfig); err != nil {
return fmt.Errorf("failed to update top level %v QOS cgroup : %v", qosClass, err)
}
}
}
// Store the top level qos container names
m.qosContainersInfo = QOSContainersInfo{
Guaranteed: rootContainer,
Burstable: qosClasses[v1.PodQOSBurstable],
BestEffort: qosClasses[v1.PodQOSBestEffort],
}
m.getNodeAllocatable = getNodeAllocatable
m.activePods = activePods
// update qos cgroup tiers on startup and in periodic intervals
// to ensure desired state is in sync with actual state.
go wait.Until(func() {
err := m.UpdateCgroups()
if err != nil {
klog.Warningf("[ContainerManager] Failed to reserve QoS requests: %v", err)
}
}, periodicQOSCgroupUpdateInterval, wait.NeverStop)
return nil
}
|
Look at the UpdateCgroups again.
First, the cpushare value is recalculated for both BestEffort and Burstable qos. The rule is that the cpushare of the BestEffort type is set to 2; the cpushare of the Burstable type is the sum of the cpushare of all the pods under it.
Second, if memory huge page is enabled, set the huge page related cgroup.
Then, if qos reserve is enabled, the memory limit is calculated for both Burstable and BestEffort QoS types, and the rule is that the memory limit for Burstable is the total number of nodes minus the sum of the memory limits of Guaranteed pods. The memory limit of BestEffort is the memory limit of Burstable minus the sum of the memory limits of Burstable pods. The calculation formula is as follows.
1
2
|
burstableLimit := allocatable - (qosMemoryRequests[v1.PodQOSGuaranteed] * percentReserve / 100)
bestEffortLimit := burstableLimit - (qosMemoryRequests[v1.PodQOSBurstable] * percentReserve / 100)
|
In particular, the qos-reserved parameter is used in some scenarios where we want to ensure that the resources of a high-level pod like Guaranteed pod, especially the non-preemptible resources (such as memory), are not preempted by a low-level pod. The So Burstable’s cgroup needs to reserve memory resources for Guaranteed pods that are higher than it, while BestEffort needs to reserve memory resources for both Burstable and Guaranteed.
Finally, the new data is updated to the QoS level cgroup data. The overall code is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
func (m *qosContainerManagerImpl) UpdateCgroups() error {
m.Lock()
defer m.Unlock()
qosConfigs := map[v1.PodQOSClass]*CgroupConfig{
v1.PodQOSBurstable: {
Name: m.qosContainersInfo.Burstable,
ResourceParameters: &ResourceConfig{},
},
v1.PodQOSBestEffort: {
Name: m.qosContainersInfo.BestEffort,
ResourceParameters: &ResourceConfig{},
},
}
// update the qos level cgroup settings for cpu shares
if err := m.setCPUCgroupConfig(qosConfigs); err != nil {
return err
}
// update the qos level cgroup settings for huge pages (ensure they remain unbounded)
if err := m.setHugePagesConfig(qosConfigs); err != nil {
return err
}
if utilfeature.DefaultFeatureGate.Enabled(kubefeatures.QOSReserved) {
for resource, percentReserve := range m.qosReserved {
switch resource {
case v1.ResourceMemory:
m.setMemoryReserve(qosConfigs, percentReserve)
}
}
updateSuccess := true
for _, config := range qosConfigs {
err := m.cgroupManager.Update(config)
if err != nil {
updateSuccess = false
}
}
...
}
for _, config := range qosConfigs {
err := m.cgroupManager.Update(config)
if err != nil {
klog.Errorf("[ContainerManager]: Failed to update QoS cgroup configuration")
return err
}
}
...
return nil
}
|
In cgroupManager.Update(), runc is called to write cgroups based on all the cgroups calculated above, and the supported cgroupfs include MemoryGroup, CpuGroup, PidsGroup, all in package "github.com/ opencontainers/runc/libcontainer/cgroups/fs", and the source code is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
func setSupportedSubsystemsV1(cgroupConfig *libcontainerconfigs.Cgroup) error {
for sys, required := range getSupportedSubsystems() {
if _, ok := cgroupConfig.Paths[sys.Name()]; !ok {
if required {
return fmt.Errorf("failed to find subsystem mount for required subsystem: %v", sys.Name())
}
...
continue
}
if err := sys.Set(cgroupConfig.Paths[sys.Name()], cgroupConfig); err != nil {
return fmt.Errorf("failed to set config for supported subsystems : %v", err)
}
}
return nil
}
func getSupportedSubsystems() map[subsystem]bool {
supportedSubsystems := map[subsystem]bool{
&cgroupfs.MemoryGroup{}: true,
&cgroupfs.CpuGroup{}: true,
&cgroupfs.PidsGroup{}: false,
}
// not all hosts support hugetlb cgroup, and in the absent of hugetlb, we will fail silently by reporting no capacity.
supportedSubsystems[&cgroupfs.HugetlbGroup{}] = false
if utilfeature.DefaultFeatureGate.Enabled(kubefeatures.SupportPodPidsLimit) || utilfeature.DefaultFeatureGate.Enabled(kubefeatures.SupportNodePidsLimit) {
supportedSubsystems[&cgroupfs.PidsGroup{}] = true
}
return supportedSubsystems
}
|
Take cpuGroup as an example, it is essentially writing to cpu.shares, cpu.cfs_period_us, cpu.cfs_quota_us files. The source code is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func (s *CpuGroup) Set(path string, cgroup *configs.Cgroup) error {
if cgroup.Resources.CpuShares != 0 {
shares := cgroup.Resources.CpuShares
if err := fscommon.WriteFile(path, "cpu.shares", strconv.FormatUint(shares, 10)); err != nil {
return err
}
...
}
if cgroup.Resources.CpuPeriod != 0 {
if err := fscommon.WriteFile(path, "cpu.cfs_period_us", strconv.FormatUint(cgroup.Resources.CpuPeriod, 10)); err != nil {
return err
}
}
if cgroup.Resources.CpuQuota != 0 {
if err := fscommon.WriteFile(path, "cpu.cfs_quota_us", strconv.FormatInt(cgroup.Resources.CpuQuota, 10)); err != nil {
return err
}
}
return s.SetRtSched(path, cgroup)
}
|
pod-level cgroups
Here’s a look at the process of creating a pod-level cgroup.
When creating a pod, the syncPod function will call the EnsureExists method inside the podContainerManagerImpl structure, which will check whether the pod already exists, and if not, it will call the ResourceConfigForPod function to calculate the resource of the pod and then create its corresponding cgroup. The source code is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
func (m *podContainerManagerImpl) EnsureExists(pod *v1.Pod) error {
podContainerName, _ := m.GetPodContainerName(pod)
// check if container already exist
alreadyExists := m.Exists(pod)
if !alreadyExists {
// Create the pod container
containerConfig := &CgroupConfig{
Name: podContainerName,
ResourceParameters: ResourceConfigForPod(pod, m.enforceCPULimits, m.cpuCFSQuotaPeriod),
}
if utilfeature.DefaultFeatureGate.Enabled(kubefeatures.SupportPodPidsLimit) && m.podPidsLimit > 0 {
containerConfig.ResourceParameters.PidsLimit = &m.podPidsLimit
}
if err := m.cgroupManager.Create(containerConfig); err != nil {
return fmt.Errorf("failed to create container for %v : %v", podContainerName, err)
}
}
if err := m.applyLimits(pod); err != nil {
return fmt.Errorf("failed to apply resource limits on container for %v : %v", podContainerName, err)
}
return nil
}
|
Let’s look at how kubelet calculates the resource of a pod.
First, the cpu request/limits and memory limit of all containers of the pod are counted, cpu request/limits are converted into cpuShares and cpuQuota; the large page limit is calculated; then, according to the resource declaration of each container, the QoS is determined; finally, the cgroup of the pod is counted:
- if enforceCPULimits is not enabled, cpuQuota is -1; 2. if the pod is of Guaranteed type, cpuQuota is -1.
- if the pod is Guaranteed, CpuShares, CpuQuota, CpuPeriod, Memory are all calculated earlier.
- if the pod is of type Burstable, CpuQuota and CpuPeriod are configured only if cpuLimitsDeclared is on, and Memory is configured only if memoryLimitsDeclared is on.
- If the pod is of type BestEffort, CpuShares is 2, and nothing else is set.
The source code is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
func ResourceConfigForPod(pod *v1.Pod, enforceCPULimits bool, cpuPeriod uint64) *ResourceConfig {
// sum requests and limits.
reqs, limits := resource.PodRequestsAndLimits(pod)
cpuRequests := int64(0)
cpuLimits := int64(0)
memoryLimits := int64(0)
if request, found := reqs[v1.ResourceCPU]; found {
cpuRequests = request.MilliValue()
}
if limit, found := limits[v1.ResourceCPU]; found {
cpuLimits = limit.MilliValue()
}
if limit, found := limits[v1.ResourceMemory]; found {
memoryLimits = limit.Value()
}
// convert to CFS values
cpuShares := MilliCPUToShares(cpuRequests)
cpuQuota := MilliCPUToQuota(cpuLimits, int64(cpuPeriod))
// track if limits were applied for each resource.
memoryLimitsDeclared := true
cpuLimitsDeclared := true
// map hugepage pagesize (bytes) to limits (bytes)
hugePageLimits := map[int64]int64{}
for _, container := range pod.Spec.Containers {
if container.Resources.Limits.Cpu().IsZero() {
cpuLimitsDeclared = false
}
if container.Resources.Limits.Memory().IsZero() {
memoryLimitsDeclared = false
}
containerHugePageLimits := HugePageLimits(container.Resources.Requests)
for k, v := range containerHugePageLimits {
if value, exists := hugePageLimits[k]; exists {
hugePageLimits[k] = value + v
} else {
hugePageLimits[k] = v
}
}
}
// quota is not capped when cfs quota is disabled
if !enforceCPULimits {
cpuQuota = int64(-1)
}
// determine the qos class
qosClass := v1qos.GetPodQOS(pod)
// build the result
result := &ResourceConfig{}
if qosClass == v1.PodQOSGuaranteed {
result.CpuShares = &cpuShares
result.CpuQuota = &cpuQuota
result.CpuPeriod = &cpuPeriod
result.Memory = &memoryLimits
} else if qosClass == v1.PodQOSBurstable {
result.CpuShares = &cpuShares
if cpuLimitsDeclared {
result.CpuQuota = &cpuQuota
result.CpuPeriod = &cpuPeriod
}
if memoryLimitsDeclared {
result.Memory = &memoryLimits
}
} else {
shares := uint64(MinShares)
result.CpuShares = &shares
}
result.HugePageLimit = hugePageLimits
return result
}
|
container-level cgroups
Finally, let’s take a look at the container-level cgroups.
When a container is created, it will first get its parent cgroup, i.e. pod-level cgroups, which will be stored in podSandboxConfig, and then generateContainerConfig will be called to generate container-level cgroup information. The source code is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
func (m *kubeGenericRuntimeManager) startContainer(podSandboxID string, podSandboxConfig *runtimeapi.PodSandboxConfig, spec *startSpec, pod *v1.Pod, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, podIP string, podIPs []string) (string, error) {
container := spec.container
...
containerConfig, cleanupAction, err := m.generateContainerConfig(container, pod, restartCount, podIP, imageRef, podIPs, target)
if cleanupAction != nil {
defer cleanupAction()
}
...
containerID, err := m.runtimeService.CreateContainer(podSandboxID, containerConfig, podSandboxConfig)
if err != nil {
s, _ := grpcstatus.FromError(err)
m.recordContainerEvent(pod, container, containerID, v1.EventTypeWarning, events.FailedToCreateContainer, "Error: %v", s.Message())
return s.Message(), ErrCreateContainer
}
...
return "", nil
}
|
Then look at the code to generate the containerConfig, in fact, this part is very simple, is generated from the container resources in the container of all the cgroup information, the source code is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
func (m *kubeGenericRuntimeManager) generateContainerConfig(container *v1.Container, pod *v1.Pod, restartCount int, podIP, imageRef string, podIPs []string, nsTarget *kubecontainer.ContainerID) (*runtimeapi.ContainerConfig, func(), error) {
opts, cleanupAction, err := m.runtimeHelper.GenerateRunContainerOptions(pod, container, podIP, podIPs)
...
config := &runtimeapi.ContainerConfig{
Metadata: &runtimeapi.ContainerMetadata{
Name: container.Name,
Attempt: restartCountUint32,
},
Image: &runtimeapi.ImageSpec{Image: imageRef},
Command: command,
Args: args,
WorkingDir: container.WorkingDir,
Labels: newContainerLabels(container, pod),
Annotations: newContainerAnnotations(container, pod, restartCount, opts),
Devices: makeDevices(opts),
Mounts: m.makeMounts(opts, container),
LogPath: containerLogsPath,
Stdin: container.Stdin,
StdinOnce: container.StdinOnce,
Tty: container.TTY,
}
// set platform specific configurations.
if err := m.applyPlatformSpecificContainerConfig(config, container, pod, uid, username, nsTarget); err != nil {
return nil, cleanupAction, err
}
...
return config, cleanupAction, nil
}
func (m *kubeGenericRuntimeManager) applyPlatformSpecificContainerConfig(config *runtimeapi.ContainerConfig, container *v1.Container, pod *v1.Pod, uid *int64, username string, nsTarget *kubecontainer.ContainerID) error {
config.Linux = m.generateLinuxContainerConfig(container, pod, uid, username, nsTarget)
return nil
}
func (m *kubeGenericRuntimeManager) generateLinuxContainerConfig(container *v1.Container, pod *v1.Pod, uid *int64, username string, nsTarget *kubecontainer.ContainerID) *runtimeapi.LinuxContainerConfig {
lc := &runtimeapi.LinuxContainerConfig{
Resources: &runtimeapi.LinuxContainerResources{},
SecurityContext: m.determineEffectiveSecurityContext(pod, container, uid, username),
}
...
// set linux container resources
var cpuShares int64
cpuRequest := container.Resources.Requests.Cpu()
cpuLimit := container.Resources.Limits.Cpu()
memoryLimit := container.Resources.Limits.Memory().Value()
oomScoreAdj := int64(qos.GetContainerOOMScoreAdjust(pod, container, int64(m.machineInfo.MemoryCapacity)))
if cpuRequest.IsZero() && !cpuLimit.IsZero() {
cpuShares = milliCPUToShares(cpuLimit.MilliValue())
} else {
// if cpuRequest.Amount is nil, then milliCPUToShares will return the minimal number
// of CPU shares.
cpuShares = milliCPUToShares(cpuRequest.MilliValue())
}
lc.Resources.CpuShares = cpuShares
if memoryLimit != 0 {
lc.Resources.MemoryLimitInBytes = memoryLimit
}
lc.Resources.OomScoreAdj = oomScoreAdj
if m.cpuCFSQuota {
cpuPeriod := int64(quotaPeriod)
if utilfeature.DefaultFeatureGate.Enabled(kubefeatures.CPUCFSQuotaPeriod) {
cpuPeriod = int64(m.cpuCFSQuotaPeriod.Duration / time.Microsecond)
}
cpuQuota := milliCPUToQuota(cpuLimit.MilliValue(), cpuPeriod)
lc.Resources.CpuQuota = cpuQuota
lc.Resources.CpuPeriod = cpuPeriod
}
lc.Resources.HugepageLimits = GetHugepageLimitsFromResources(container.Resources)
return lc
}
|
After the containerConfig is generated, the CRI interface is called to create the container, which includes the creation of container-level cgroups.
OOM scoring
As we all know, when a node runs out of memory, it will trigger the system’s OOM Killer, and the kubelet must ensure that pods of different QoS types are killed in a different order. Let’s take a look at how the kubelet guarantees the order in which pods are killed.
Linux OOM
Linux has an OOM KILLER mechanism that enables its own algorithm to selectively kill some processes when the system runs out of memory. Some files related to system OOM are
/proc/<pid>/oom_score_adj: When calculating the final badness score, oom_score_adj is added to the result, so that the user can use this value to protect a process from being killed or to kill a process every time, from -1000 to 1000. If the value is set to -1000, the process will never be killed, because the badness score will always return 0.
/proc/<pid>/oom_adj: This parameter is there for compatibility with older versions of the kernel. It is set in the range -17 to 15.
/proc/<pid>/oom_score : This value is calculated by combining the memory consumption, CPU time (utime + stime), survival time (uptime - start time) and oom_adj of the process.
The OOM killer mechanism decides which process to kill based on oom_score and oom_score_adj.
kubelet’s OOM scoring system
With the foundation of OOM Killer in place, let’s look at how kubelet sets up oom_score_adj for different kinds of processes. collected from the code as follows.
1
2
3
4
5
6
|
dockerOOMScoreAdj = -999
KubeletOOMScoreAdj int = -999
KubeProxyOOMScoreAdj int = -999
defaultSandboxOOMAdj int = -998
guaranteedOOMScoreAdj int = -998
besteffortOOMScoreAdj int = 1000
|
The dockershim process (dockerOOMScoreAdj), the kubelet process (KubeletOOMScoreAdj), and the kubeproxy process (KubeProxyOOMScoreAdj) have oom_score_adj set to -999, indicating that it is very important, but not to -1000.
The pod pause container (defaultSandboxOOMAdj) and the Guaranteed type pod (guaranteedOOMScoreAdj) have oom_score_adj set to -998, indicating that they are also important, but can still be killed relative to the components above.
The BestEffort type pod (besteffortOOMScoreAdj), oom_score_adj is set to 1000, which means that the BestEffort type pod is the most likely to be killed.
Finally, let’s look at the Burstable type of pod, which is calculated as.
1
|
min{max[1000 - (1000 * memoryRequest) / memoryCapacity, 1000 + guaranteedOOMScoreAdj], 999}
|
It can be seen that a pod of Burstable type must score larger than Guaranteed and smaller than BestEffort, and the larger the request value of memory, the less likely it is to be killed.
The source code is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
func GetContainerOOMScoreAdjust(pod *v1.Pod, container *v1.Container, memoryCapacity int64) int {
if types.IsCriticalPod(pod) {
// Critical pods should be the last to get killed.
return guaranteedOOMScoreAdj
}
switch v1qos.GetPodQOS(pod) {
case v1.PodQOSGuaranteed:
// Guaranteed containers should be the last to get killed.
return guaranteedOOMScoreAdj
case v1.PodQOSBestEffort:
return besteffortOOMScoreAdj
}
memoryRequest := container.Resources.Requests.Memory().Value()
oomScoreAdjust := 1000 - (1000*memoryRequest)/memoryCapacity
// A guaranteed pod using 100% of memory can have an OOM score of 10. Ensure
// that burstable pods have a higher OOM score adjustment.
if int(oomScoreAdjust) < (1000 + guaranteedOOMScoreAdj) {
return (1000 + guaranteedOOMScoreAdj)
}
// Give burstable pods a higher chance of survival over besteffort pods.
if int(oomScoreAdjust) == besteffortOOMScoreAdj {
return int(oomScoreAdjust - 1)
}
return int(oomScoreAdjust)
}
|
Summary
In summary, k8s provides three types of QoS, namely Guaranteed, Burstable and BestEffort. kubelet creates different cgroups for different types of pods to ensure that different types of pods get different resources and try to ensure high priority quality of service and improve system stability.