Kubernetes has claimed to support 5,000 nodes in a single cluster since an earlier release, and there are no plans to increase the number of nodes supported by a single Kubernetes cluster in the near future. If you need to support more than 5,000 nodes in Kubernetes, Federation is the preferred method of cluster federation.
People frequently ask how far we are going to go in improving Kubernetes scalability. Currently we do not have plans to increase scalability beyond 5000-node clusters (within our SLOs) in the next few releases. If you need clusters larger than 5000 nodes, we recommend to use federation to aggregate multiple Kubernetes clusters.
Readers who are a little familiar with cloud services should know the concept of Available Zone (AZ). When we use the instances provided by AWS, Google Cloud and other services, we need to select the region where the instance is located and the available zone. Region is a geographical concept, for example, AWS has data centers in Beijing and Ningxia, and each data center has 3 availability zones.
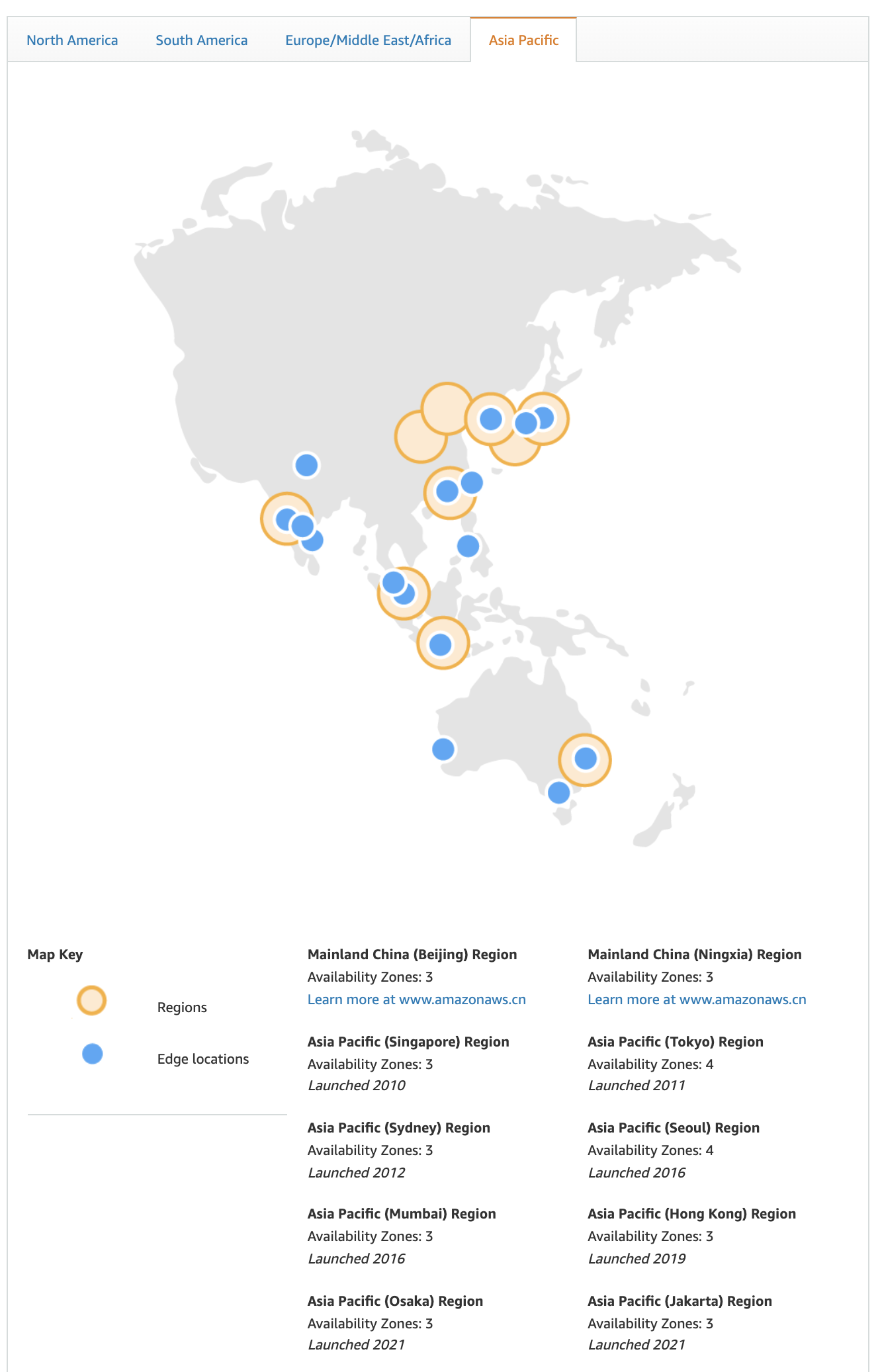
As AZs offered by cloud service vendors, each AZ may contain tens of thousands, or even hundreds of thousands of nodes, and trying to manage a number of nodes of that size using a single cluster is very difficult, so managing multiple clusters becomes a problem that must be faced at that scale.
Cluster federation sounds like a very high-end technology, but in reality we can understand it as a more flexible and easy-to-use multi-cluster. When we just refer to multiple clusters, they are more like independent islands without much connection to each other, but federated clusters ‘package’ these independent clusters into a whole, and the upper level users don’t need to care about the cluster level.
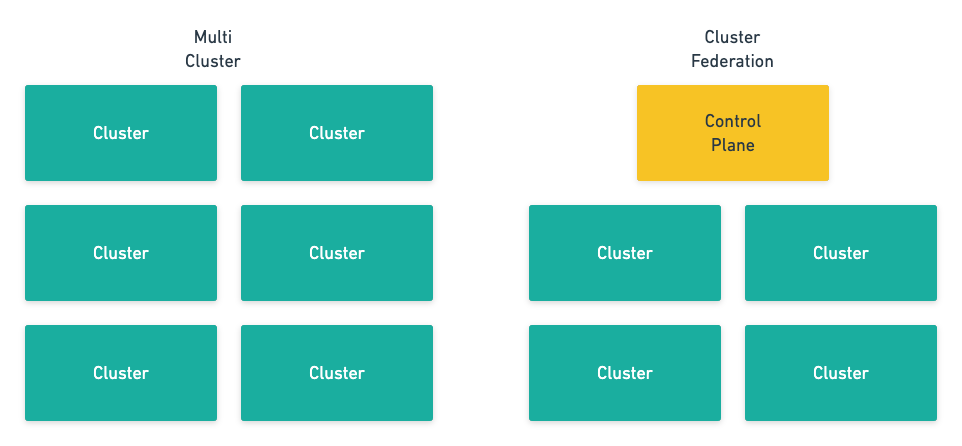
The new control panel introduced by Federated Cluster requires two more important functions: cross-cluster service discovery and cross-cluster scheduling. Among them, cross-cluster service discovery opens up the network of multiple clusters and allows requests to cross the boundaries of different clusters, while cross-cluster scheduling ensures the stability as well as availability of the service.
In this article, we will take two cluster federation projects, kubefed and karmada, as examples to introduce cluster federation The comparison of multiple projects will also give us a clear idea of the impact of different design choices.
kubefed
kubefed is a very old Kubernetes cluster federation project, which is currently hanging under the official repository, developed by the official multi-cluster interest group, and has been around for almost four years now. The Kubernetes cluster federation is a very old topic in terms of the age of the project, but there is no more perfect solution today.
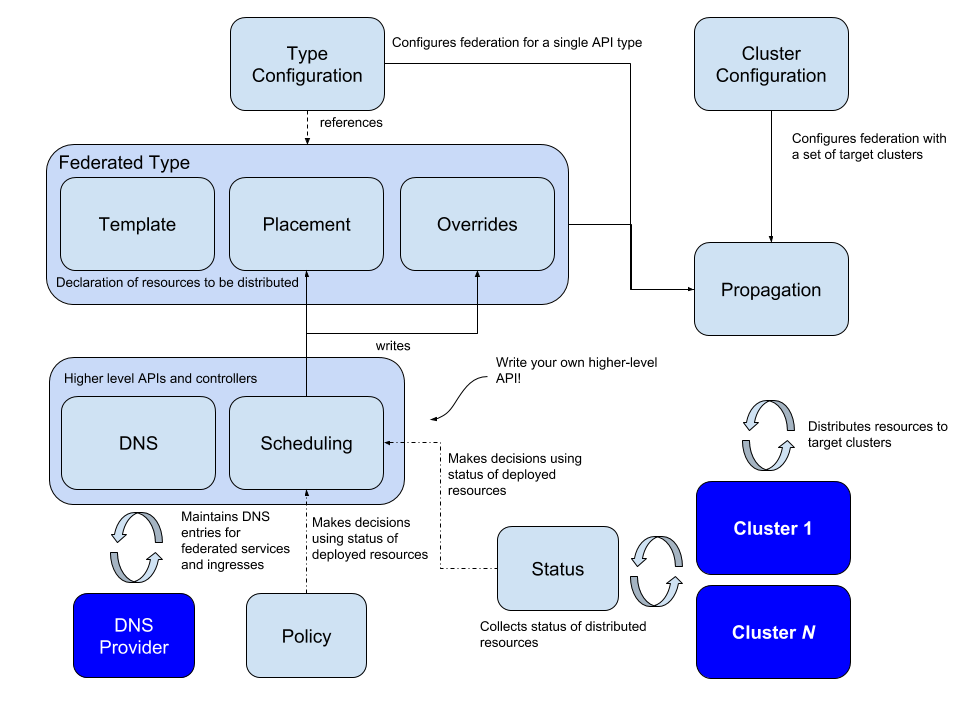
All cluster federation scenarios require us to synchronize resources from the management cluster to the federation cluster. Propagation is a term introduced by the project that will distribute resources from the host cluster to all federated clusters.This mechanism will require the introduction of the following three concepts: Templates, Placement and Overrides.
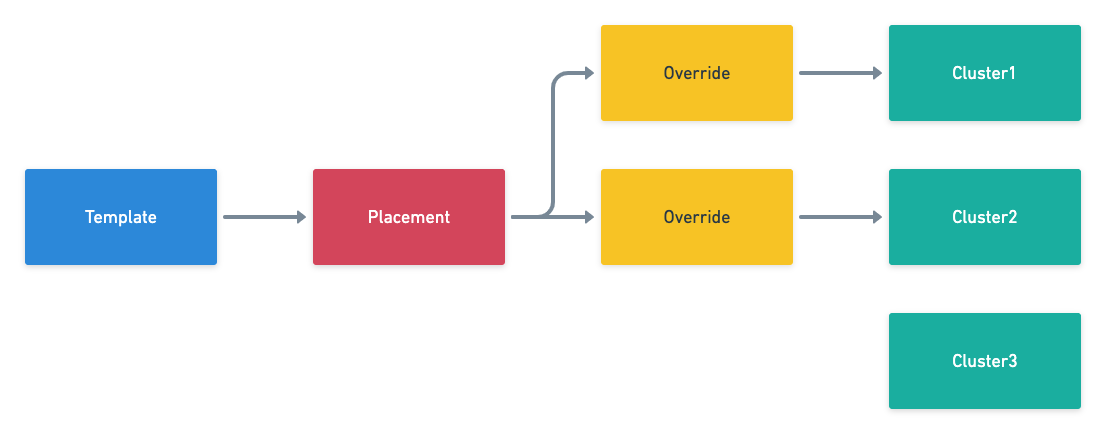
The Template defines some basic information of the resource, for example, Deployment, which may include the deployed container image, environment variables and the number of instances, etc.; Placement determines which clusters the resource needs to be deployed in, as shown above, the resource will be deployed in Cluster1 and Cluster2 clusters; the last Override overrides the resources in the original Template to meet some specific requirements of the current cluster, such as the number of instances, the secret key used for pulling mirrors, and other cluster-related properties.
In terms of implementation, kubefed chooses to generate corresponding federation resources for all resources in the cluster, such as Deployment and the corresponding FederatedDeployment. The spec field in the federation resource stores the template for the Deployment resource, while the overrides define the changes that need to be made when the resources are synchronized to different clusters.
|
|
The control plane of a federation cluster generates Deployments for different clusters based on the FederatedDeployment mentioned above and pushes them to the lower level managed federation clusters, which is the main problem solved by cluster federation kubefed.
Theoretically, all cluster federation components meet all requirements as long as they implement DefinitionTemplate and ReplicaSegment capabilities, but in practice, different solutions also provide some syntactic sugar-like features to help us better implement more complex resource distribution capabilities across clusters. kubefed provides kubefed provides ReplicaSchedulingPreference to achieve a more intelligent distribution strategy across different clusters.
|
|
The above scheduling strategy allows workloads to be weighted across clusters and instances to be migrated to other clusters when cluster resources are insufficient or even when problems occur, which improves the flexibility and availability of service deployment and allows infrastructure engineers to better balance the load across multiple clusters.
kubefed still includes cross-cluster service discovery in earlier versions, but in the latest branches, all the features related to service discovery have been removed, probably because cross-cluster service discovery is very complex and there are already many third-party tools in the community that can provide DNS-based federated Ingress resources without the need for kubefed support There are already many third-party tools in the community that provide DNS-based federated Ingress resources without the need for kubefed support.
karmada
Kubefed is an early cluster federation project in the Kubernetes community, and although it has been around for a long time, it has been in an experimental phase and is basically out of maintenance today. Karmada is a continuation of the Kubefed project, which inherits some of the concepts from kubefed and is currently under active development and maintenance, and is one of the more active and mature cluster federation projects in the community.
Notice: this project is developed in continuation of Kubernetes Federation v1 and v2. Some basic concepts are inherited from these two versions.
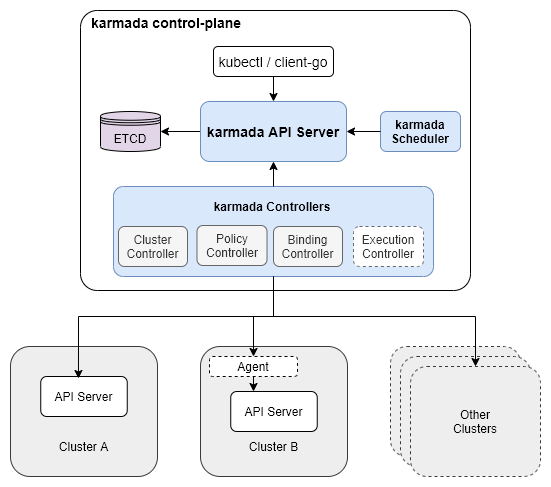
Karmada’s multi-level cluster management is all about natural tree structure. As shown above, the Karmada control panel on the root node contains three main components, API Server, Controller Manager and Scheduler. I believe readers who understand the Kubernetes control panel should be able to imagine the role of these three different components.
It should be noted that Karmada’s Controller Manager does not contain the controllers in Kubernetes Controller Manager. If we create Deployment resources in a Karmada cluster, Karmada’s control plane will not create Pods based on Deployment. It is only responsible for the synchronization and management of Karmada’s native CRD, including Cluster, PropagationPolicy, ResourceBinding and Work resources.
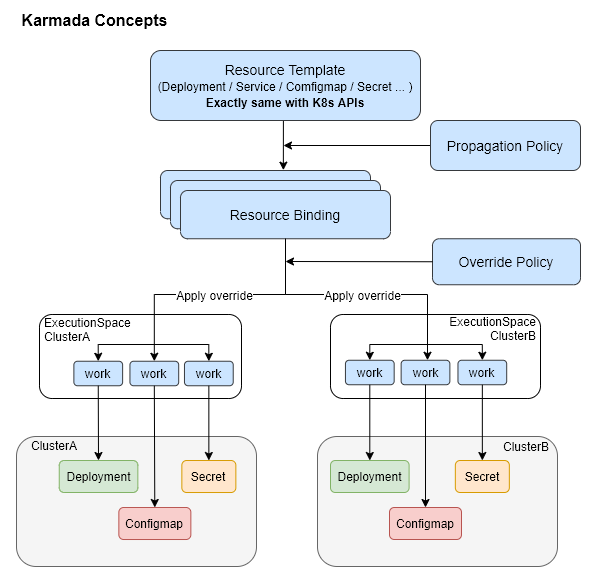
As we mentioned above, the concepts in Karmada are also inherited from Kubefed almost in its entirety. We can summarize from the above diagram that Karmada needs to go through the following steps to convert resource templates into resources of member clusters.
- Deployment, Service, ConfigMap and other resource templates are generated into a set of ResourceBinding by PropagationPolicy, and each ResourceBinding corresponds to a specific member cluster.
- the ResourceBinding changes some resources to fit different member clusters according to the OverridePolicy, e.g., cluster name and other parameters, and these resource definitions are stored in the Work object.
- The resource definitions stored in the Work object are submitted to the member clusters, and the control panel components such as Controller Manager in the member clusters are responsible for the processing of these resources, e.g., creating Pods based on Deployment, etc.
|
|
The concepts of Karmada and Kubefed are very similar in that they both need to address two issues in the API: which cluster the resource template should be deployed to, and what specific changes the resource template needs to implement in that cluster. These two issues are bound to be faced in the process of ’template instantiation’, and Kubefed and Karmada components have chosen different interfaces.
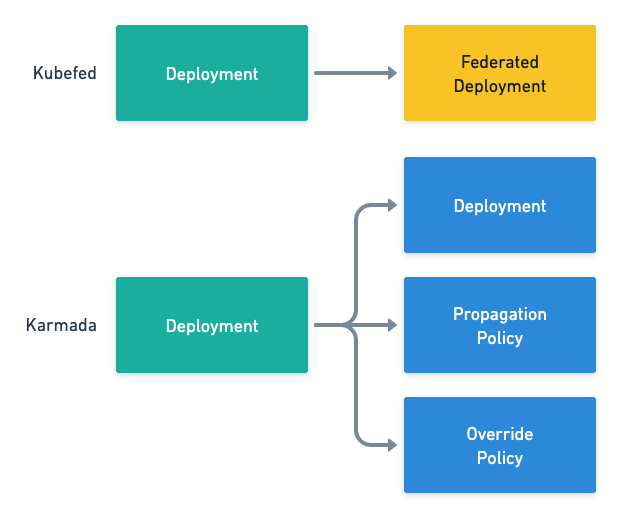
- Kubefed creates corresponding Federated resources for all Kubernetes native resources, such as Deployment and FederatedDeployment, and the definitions of Placement and Override are included in the new FederatedDeployment.
- Karmada retains all Kubernetes native resources while introducing new PropagationPolicy and OverridePolicy.
The two options above have their advantages and disadvantages. Creating a corresponding resource brings all the definitions together, but introduces additional work if a new Custom Resource is introduced in the cluster; creating separate PropagationPolicy and OverridePolicy simplifies the steps needed to introduce a new resource, but Creating separate PropagationPolicy and OverridePolicy simplifies the steps needed to introduce new resources, but may require an additional kanban board to see the final resource generated by the resource template.
In this scenario, the authors prefer Karmada’s approach because as the variety of resources in Kubernetes increases, using PropagationPolicy and OverridePolicy reduces the cost of maintaining the cluster, we do not need to create a federal type mapping for each new resource, and introducing an additional kanban board to show the final generated resources is not an unacceptable cost.
It is important to note that we will only distribute ‘advanced’ resources such as Deployment in Karmada control plane, and the Controller Manager in the management cluster will not create Pods based on Deployment, so as to reduce the pressure on the control plane and realize the management of multi-cluster federation.
In addition to the distribution of resources, Karmada also adds the replicaScheduling field in PropagationPolicy to manage the distribution of workload instances, which can provide the function of failover and distribution by weight.
|
|
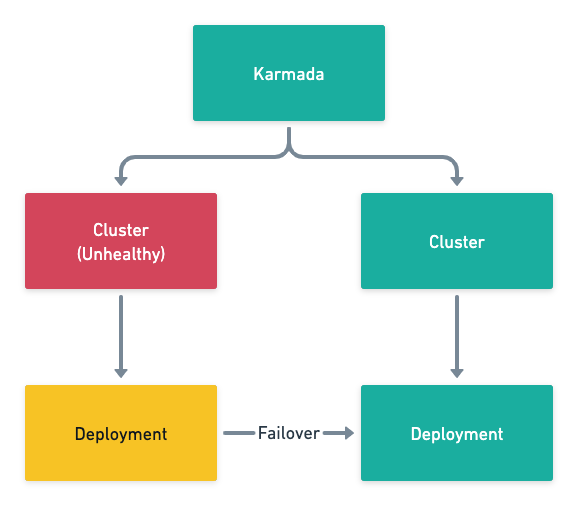
Karmada’s scheduler needs to solve the problem of where and how much to schedule workloads, which is a coarser-grained scheduler compared to the more fine-grained Kubernetes scheduler, which does not need or have the means to guarantee a globally optimal solution for scheduling because of the lack of context, while providing cross-cluster deployment and failover is enough to meet the common The provision of cross-cluster deployment and failover is sufficient to meet common needs.
Summary
The federation of clusters solves two main problems: the scalability of a single cluster, and cluster management across availability zones (geographies, clouds). In a system where a single cluster can be 100k nodes, we hardly ever hear about federation, and if the control surface of a Kubernetes cluster is strong enough to take on enough pressure, then the concept of multiple clusters and cluster federation is not particularly popular in the community. As the Kubernetes project matures, the Pipeline, federation, and cluster management segments will gradually improve and we will see mature federated cluster solutions in the community.