
1. Background
After writing the classic “hello, world” program, Go beginners may be eager to experience Go’s powerful standard library, for example, writing a fully functional web server like the following example in a few lines of code.
|
|
The go net/http package is a more balanced generic implementation that meets the needs of most gopher 90%+ scenarios and has the following advantages.
- standard library packages, without the need to introduce any third-party dependencies.
- Better satisfaction with the http specification.
- relatively high performance without having to do any optimization.
- Support for HTTP proxies.
- Support for HTTPS.
- Seamless support for HTTP/2.
However, because of the “balanced” generic implementation of the http package, net/http may not be able to perform well in some performance-critical areas, and there is not much room for tuning. This is when we turn our attention to other third-party http server framework implementations.
And in the third-party http server framework, a framework called fasthttp is mentioned and adopted more. fasthttp official website claims that its performance is ten times that of net/http (based on the results of the go test benchmark).
fasthttp uses many best practices on performance optimization, especially on memory object reuse, using sync.Pool extensively to reduce the pressure on Go GC.
So in a real environment, how much faster can fasthttp be than net/http? It so happens that there are two servers available with decent performance, and in this article we will look at their actual performance in this real world environment.
2. performance tests
We implement two almost “zero business” programs under test using net/http and fasthttp respectively.
- nethttp:
|
|
- fasthttp:
|
|
The client side of the stress test for the target under test is based on hey, an http stress test tool. To facilitate the adjustment of the stress level, we “wrap” hey in the following shell script (only It is suitable for running on linux only).
|
|
An example execution of the script is as follows.
|
|
From the incoming parameters, the script starts 8 tasks in parallel (one task starts one hey), each task establishes 200 concurrent connections to http://10.10.195.134:8080 and sends 100w http GET requests.
We use two servers to host the target application under test and the stress tool script.
- Server where the target application is located: 10.10.195.181 (physical machine, Intel x86-64 CPU, 40 cores, 128G RAM, CentOs 7.6)
|
|
- Server where the stress tool is located: 10.10.195.133 (physical machine, Kunpeng arm64 cpu, 96 cores, 80G RAM, CentOs 7.9)
|
|
I use dstat to monitor the resource usage of the host where the target under test is located (dstat -tcdngym), especially the cpu load; monitor memstats through expvarmon, as there is no business, the memory usage is very little; check the ranking of the consumption of various resources in the target program through go tool pprof.
Here is a table of data created after several tests.
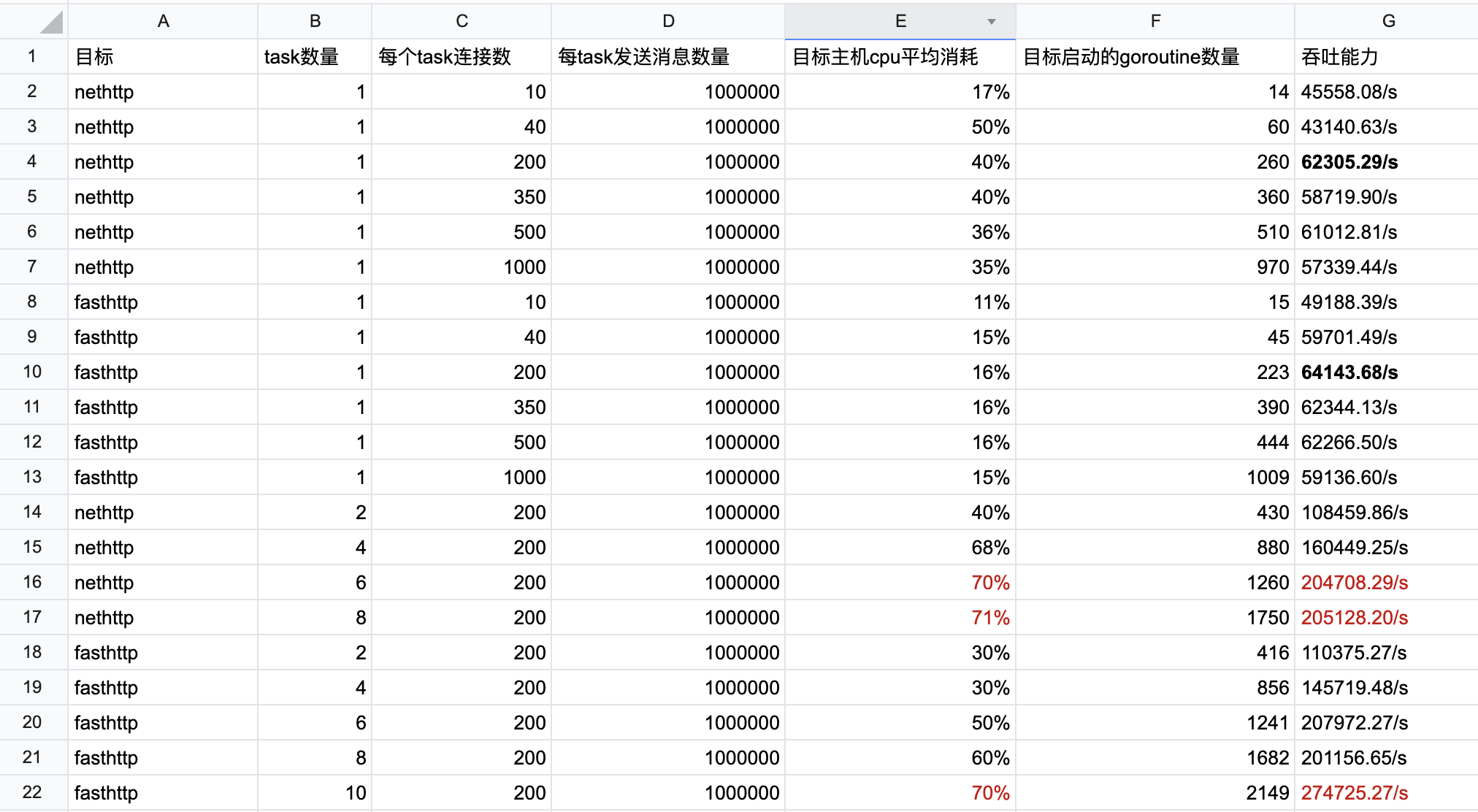
3. Brief analysis of the results
The above test results are limited by the specific scenario, the accuracy of the test tool and script, and the stress test environment, but they truly reflect the performance trend of the target under test. We see that fasthttp does not outperform net http by a factor of 10 when given the same pressure, and even in such a specific scenario, twice the performance of net/http is not achieved: we see that in several use cases where the target host cpu resource consumption is close to 70%, fasthttp’s performance is only 30% to 70% higher than that of net/http. ~70% or so.
So why did fasthttp’s performance fall short of expectations? To answer this question, it is necessary to look at the respective implementation principles of net/http and fasthttp! Let’s take a look at the working principle of net/http schematic.
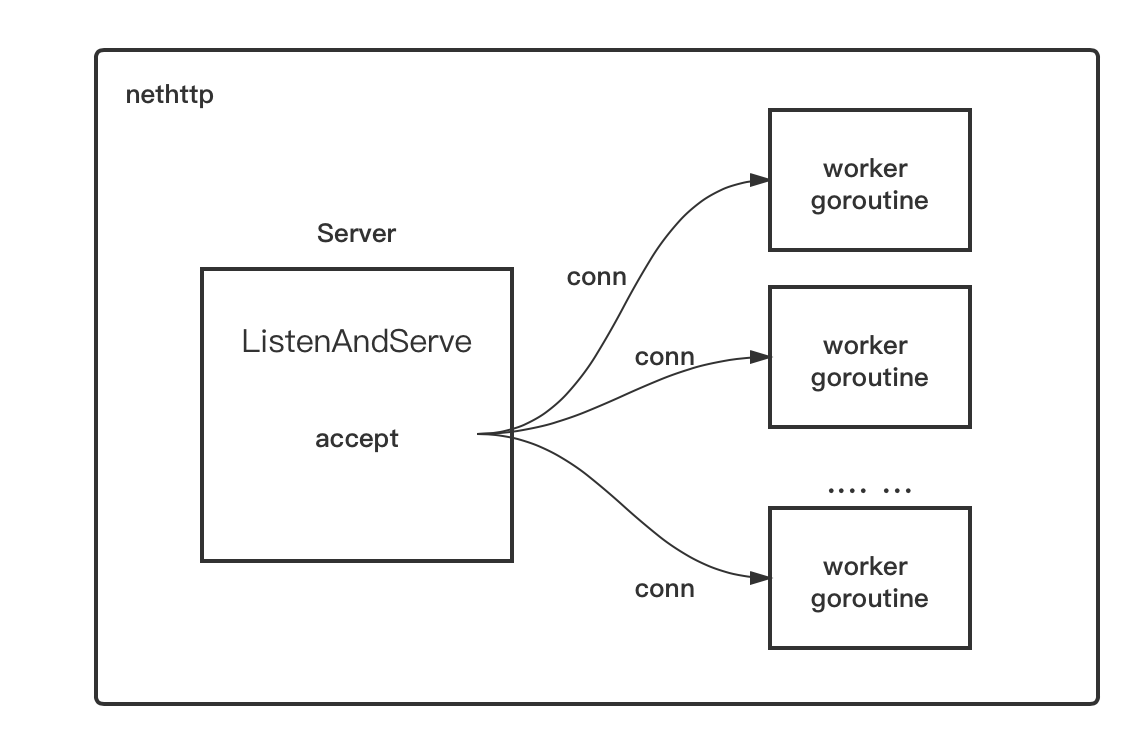
The principle of http package as a server side is very simple, that is, after accepting a connection (conn), the conn will be assigned to a worker goroutine to handle, the latter continues to exist until the end of the conn’s life cycle: that is, the connection is closed.
Here is a diagram of how fasthttp works.
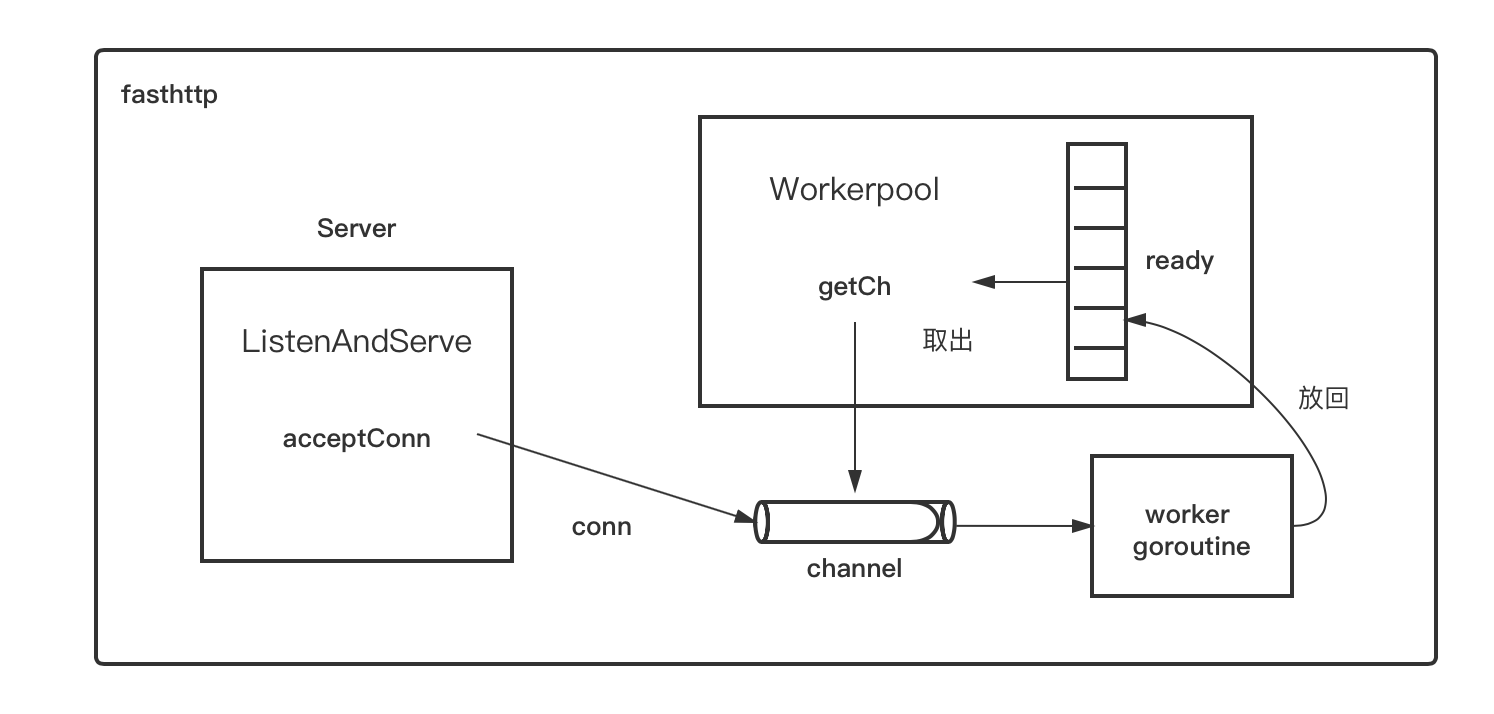
fasthttp has designed a mechanism to reuse goroutines as much as possible instead of creating a new one each time. fasthttp’s Server accepts a conn and tries to take a channel from the ready slices in the workerpool, which corresponds to the The channel corresponds to a worker goroutine. Once the channel is removed, the accepted conn is written to the channel, and the worker goroutine at the other end of the channel handles the reading and writing of the data on the conn. After processing the conn, the worker goroutine will not exit, but will put its corresponding channel back into the ready slice in the workerpool and wait for it to be taken out next time.
fasthttp’s goroutine reuse strategy is initially very good, but in the test scenario here the effect is not obvious, as can be seen from the test results, in the same client concurrency and pressure, the number of goroutines used by net/http and fasthttp is not much different. This is caused by the test model: in our test, each task in the hey will launch a fixed number of long connections (keep-alive) to the target under test, and then launch a “saturation” request on each connection. This fasthttp workerpool goroutine once received a certain conn can only be put back after the end of the communication on the conn, and the conn will not be closed until the end of the test, so such a scenario is equivalent to let fasthttp “degraded Therefore, such a scenario is equivalent to making fasthttp “degenerate” into a net/http model, and also tainted with the “defects” of net/http: once the number of goroutines is more, the consumption brought by the go runtime itself scheduling is not negligible and even exceeds the proportion of resources consumed by business processing. Here are the results of fasthttp’s cpu profile for 200 long connections, 8000 long connections and 16000 long connections respectively.
|
|
By comparing the above profiles, we find that when the number of long connections increases (i.e., when the number of goroutines in the workerpool increases), the percentage of go runtime scheduling gradually increases, and at 16000 connections, the various functions of runtime scheduling already rank in the top 4.
4. Optimization method
From the above test results, we can see that fasthttp’s model is less suitable for this kind of connection and continuous “saturation” request scenario, and more suitable for short or long connections but no continuous saturation request, in the latter scenario, its goroutine reuse model can be better played.
But even if “degraded” to the net/http model, fasthttp’s performance is still slightly better than net/http, which is why? These performance improvements are mainly the result of fasthttp in the memory allocation level optimization trick, such as the extensive use of sync.
So, in the scenario of continuous “saturation” requests, how to make the number of goroutines in the fasthttp workerpool does not grow linearly due to the increase in conn? fasthttp official answer is not given, but a path to consider is the use of os multiplexing ( The implementation on linux is epoll), i.e. the mechanism used by go runtime netpoll. With the multiplexing mechanism, this allows each goroutine in the workerpool to handle multiple connections at the same time, so that we can choose the size of the workerpool pool based on the size of the business, instead of growing the number of goroutines almost arbitrarily, as is currently the case. Of course, the introduction of epoll at the user level may also bring about problems such as an increase in the percentage of system calls and an increase in response latency. As for whether the path is feasible, it still depends on the specific implementation and test results.
Note: The Concurrency in fasthttp.Server can be used to limit the number of concurrent goroutines in the workerpool, but since each goroutine only handles one connection, when the Concurrency is set too small, subsequent connections may be denied service by fasthttp. Therefore, the default Concurrency of fasthttp is as follows.
|
|
The source code covered in this article can be found here for download.