RabbitMQ Model
RabbitMQ is a producer/consumer model, where the producer produces messages to a queue and the consumer takes messages from the queue to consume, without interacting directly with each other.
Let’s start by looking at the structure of the RabbitMQ model.
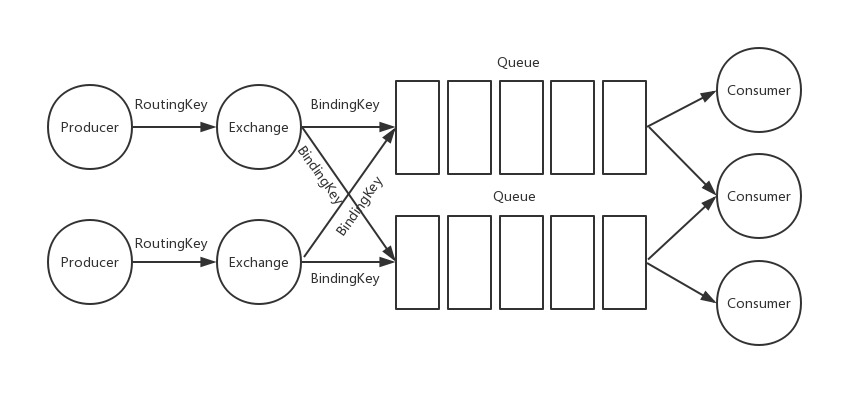
In the diagram, we can see that the entire structure consists of a Producer, an Exchange, a Queue, and a Consumer.
Among them, the Producer and the Consumer create TCP connections and channels when they connect to the MQ, and the Producer produces messages and decides which queue to send them to based on its specified RoutingKey, which is already the BindingKey of the Queue connected to the Exchange.
Let’s analyze the function of each part one by one.
Channel
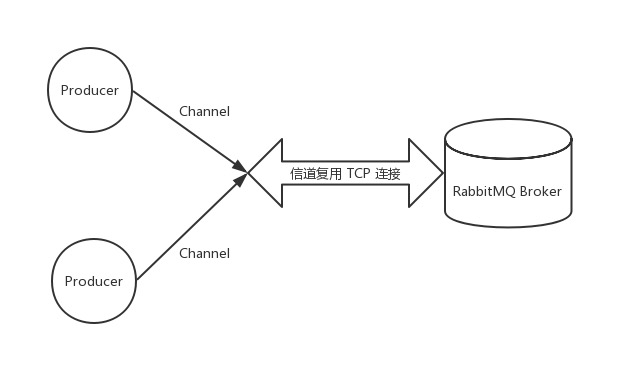
Once the Connection is established, the client creates an AMQP channel, or Channel, which is a virtual connection based on the Connection, with multiple channels reusing a single TCP connection, reducing performance overhead and making it easier to manage. This not only reduces performance overhead, but also makes it easier to manage.
TCP connections and channel creation are implemented using Python’s pika package.
|
|
Exchange
Producers typically send messages to a switch, which in turn routes them to a queue and either returns them to the queue or discards them if they fail to route.
Implement the switch in Python.
Switches are usually of four types.
- fanout: routes all messages sent to that switch to all queues bound to that switch.
- direct: routes messages to queues where the BindingKey matches the RoutingKey exactly.
- topic: routes messages to queues where the BindingKey matches the RoutingKey, with matching rules such as ‘.’ split by ‘.’ and ‘*’ and ‘#’ for fuzzy matching.
- headers: the switch of this type matches the message content according to the headers attribute of the message.
Queue
A queue is an object in RabbitMQ that stores messages. Multiple consumers can subscribe to the same queue, and the messages in the queue are split evenly among the consumers, rather than each consumer receiving all the messages.
RoutingKey & BindingKey
RoutingKey is the routing key, usually specified by the producer when sending the message, and BindingKey is the binding key, usually used to bind the switch to the queue.
The two are usually used in conjunction, for example, direct and topic type switches look for a match between these two keys when routing messages. In some cases, RoutingKey and BindingKey can be seen as the same thing.
Publish/Subscribe Mechanism
RabbitMQ messages are usually consumed in push mode and pull mode.
The push mode uses a subscription approach, using the basic_consume method, while the pull mode uses a queue fetching approach, using the basic_get method. Pull mode is usually used to get a single message, but push mode is more suitable for continuous message fetching or when high throughput is required.
Here is an example of push mode.
|
|
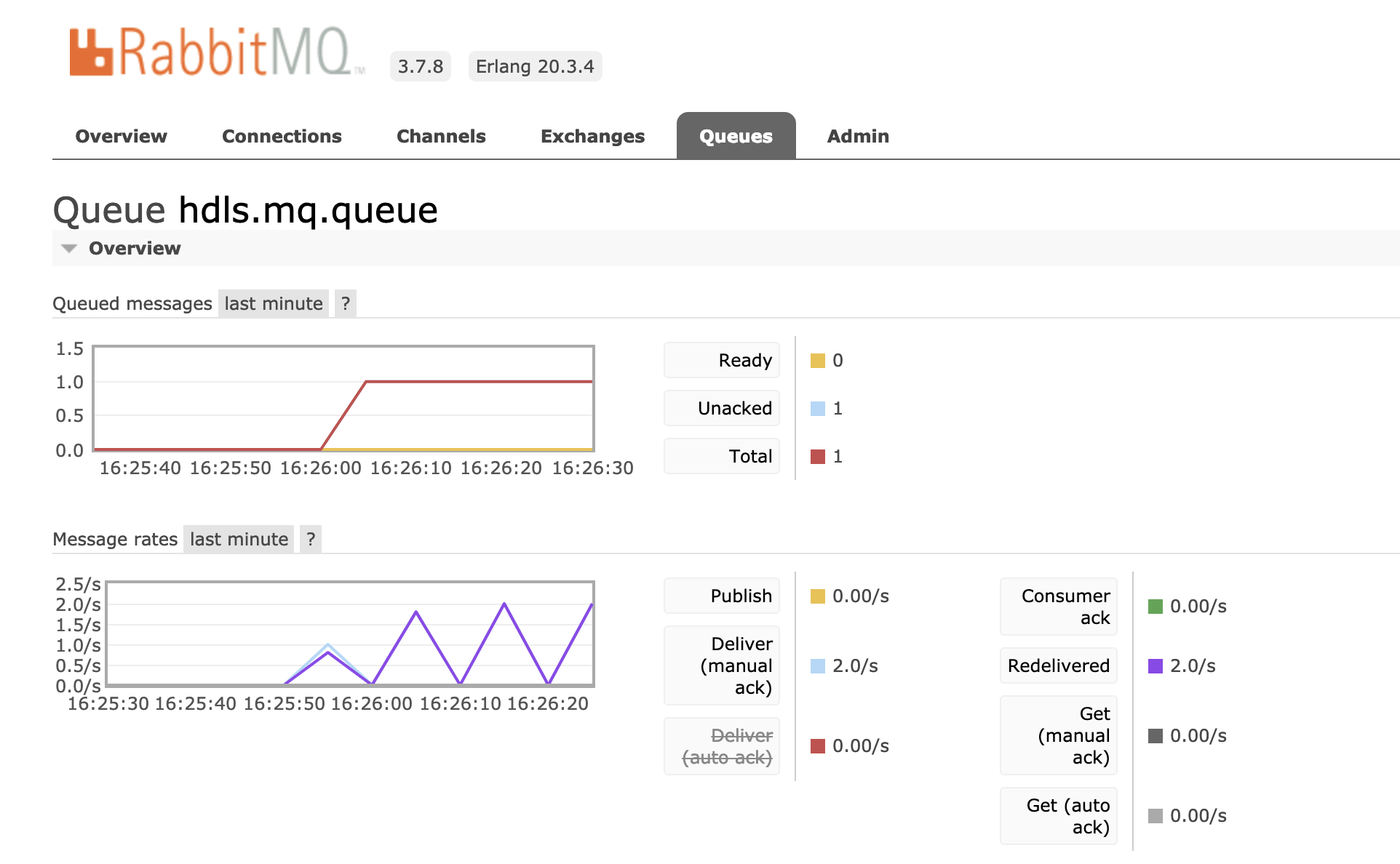
The consumer receives the message and performs an incoming ack to get the following result.
If, instead of consuming the message, the consumer rejects: basic_nack, and the rejection is accompanied by a parameter set to requeue=True, which knocks the message back to the queue, the result is as follows.
|
|
At this point the message will keep getting hit back into the queue and just keep blocking the queue.
Dead Messages
When a message is rejected and knocked back to the queue, and thereafter the message is not received by a consumer and becomes a dead message, it blocks the queue, and when there are more and more dead messages in the queue, the performance of the queue will be affected. For the handling of dead messages, setting up a dead message queue is a good choice.
There are usually several cases of dead messages.
- the message is rejected (by the basic.reject method or basic.nack method) and is also knocked back to the queue.
- the message itself has a TTL set or the queue has a TTL set and has reached its expiration time.
- the queue has reached the maximum number of messages it can hold.
Dead letter switch
When a message becomes dead in a queue, it can be sent to another switch, the dead letter switch. A dead letter switch is actually a normal switch, but bound to a dead letter queue, and is declared and used in the same way as a normal switch.
Dead letter queue
A dead letter queue is a queue used to receive dead letters, but it is essentially the same as a normal queue. Only when setting up a normal queue, you need to define which dead switch it is, and what routing_key to use to route messages to the dead queue when they become dead. This way all dead messages can be routed to the corresponding dead queue.
Note that the dead switch and the dead queue need to exist before declaring the dead settings for the normal queue.
Modify the above common queue according to the definition.
|
|
When declaring a queue, it is sufficient to declare two parameters: x-dead-letter-exchange and x-dead-letter-routing-key. Also declare the dead letter queue before declaring the normal queue.
If consumers of the dead letter queue are added at the same time, dead letters can be handled uniformly.
|
|
Everything is ready! But it actually reports an error after running.
|
|
This is because we have already declared the queue without the dead letter setting, and when declaring the queue, we tried to set an x-dead-letter-exchange parameter, but the current queue on the server has none of this parameter, so the server does not allow it, so it reports an error.
In this case, there are two solutions: one is to remove the previous queue from the server, add the dead-letter parameter, and declare the queue again; the other is to set the parameter via policy.
The policy can be set with rabbitmqctl set_policy or on the RabbitMQ front page.
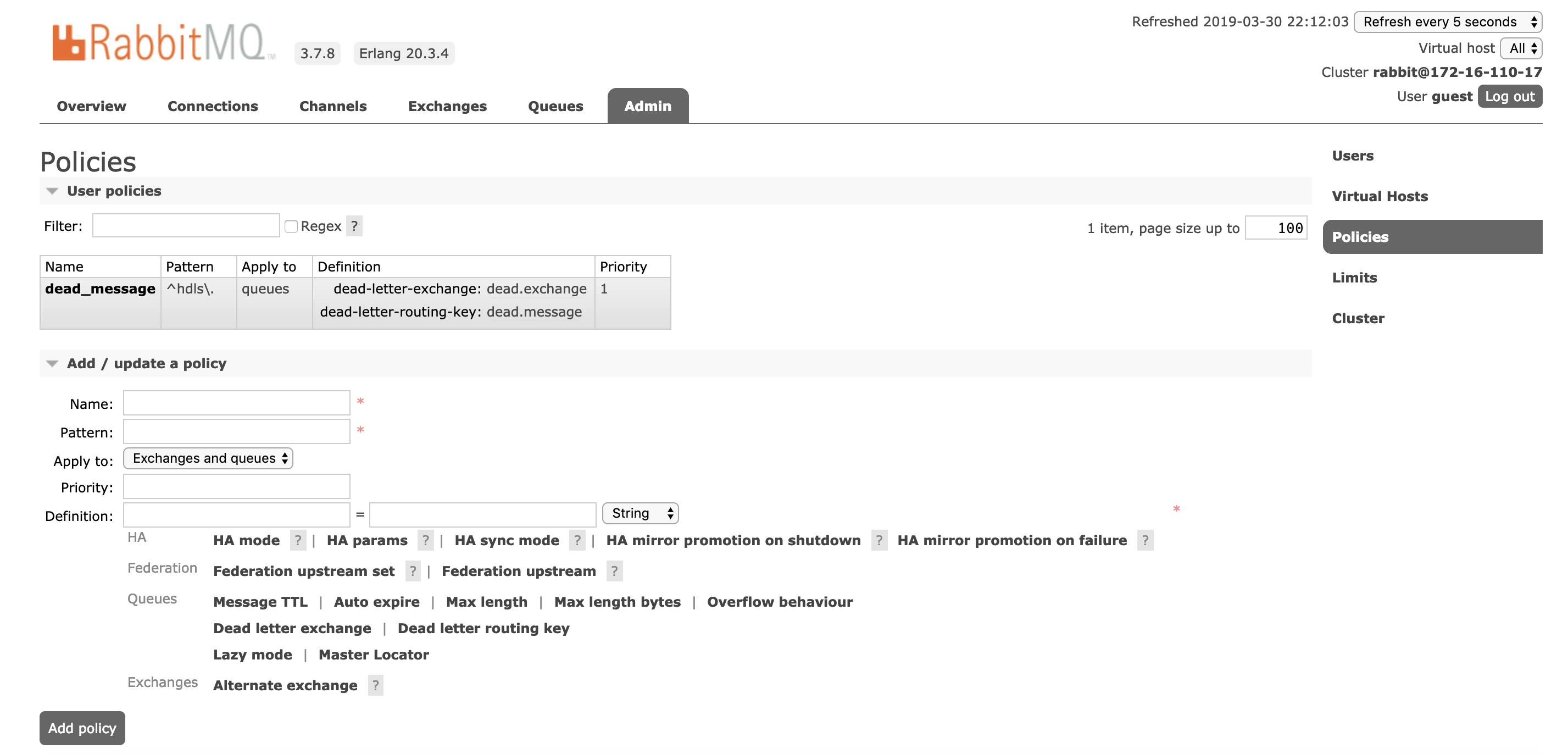
Note that the parameters are dead-letter-exchange dead-letter-routing-key when set by the policy method, while the dead letter parameters in the first method need to be prefixed with x-.
After adding the dead letter setting, enable consumer again.
|
|
As you can see, the message is routed to the dead letter queue after hitting back the queue.
Deferred queue
By deferred queue, we mean that after the message is sent, it does not want to be immediately available to the consumer, and we hope that the consumer will get the message after a specified time.
Delayed queues can be implemented with dead letter queues. Using the TTL characteristics of the queue or message, it can be done so that the message is routed to the dead letter queue after the specified timeout, and the dead letter queue can then be used as a delayed queue to do the message processing.
|
|
Add a x-message-ttl to the dead message setting of the normal queue to set the TTL of the message.
|
|