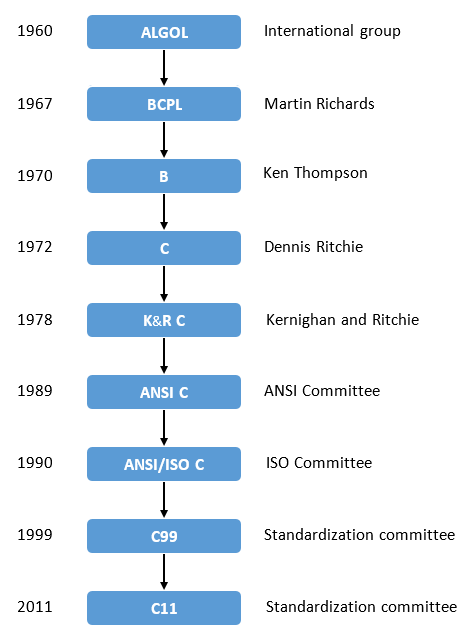
Even if we count from K&R C in 1978, C will be 44 years old in 2022.
I don’t know what C looks like in the reader’s mind, but I have the impression that C has poor expressiveness, only two high-level data structures, arrays and pointers, a small standard library and many historical problems, and no package management mechanism. The most fatal thing is that memory needs to be managed manually. It is difficult for modern young programmers to be interested in C. There are too many high-level languages to choose from, such as Java, the rising star Go/Rust, so why choose C.
Background introduction
In order to experience the development experience of C, I first read the book 21st Century C. This book is relatively short, so I can finish it quickly, but the book is also relatively shallow, so if you don’t understand the tool chain of C before, reading this book will help, but it is limited to help write C code, so I revisited C Programming Language (2nd Edition - New Edition). I have to say, even after all these years, this book is still the best textbook for learning C. The content is concise and concise, with typical cases and not a word of nonsense in the whole book. The book is also relatively short, so you can read it in a week without doing exercises. If there is a drawback to this book, it is that the variable names do not need to be defined at the beginning of the function, now the C compiler is much more advanced than before.
With the bottom of K&R C, you can directly start the real world. I recently developed a 2K line project with C: jiacai2050/oh-my-github, not too trivial, mainly to experience the following content from this project.
- C development process, familiar with the relevant tool chain
- C99/C11 language features
- C coding style essentials, how to design APIs to avoid users stepping on potholes
The following section summarizes what we have learned in the past few months, focusing on these three points. Due to the limited contact time, there are inevitably shortcomings in the text, and readers are welcome to criticize and correct them.
Toolchain
Let’s talk about the toolchain first. Before developing a formal project, there are some rather tedious things to do, such as configuring the development and debugging environment, installing dependencies, etc.. The language server I use is clangd, which supports variable definitions, references, auto-completion, etc. clangd uses compile_commands.json file for configuration, some build tools can generate it directly, for simple personal projects, you can also directly use compile_flags.txt for configuration, sample usage:
For veteran C programmers, they may be more familiar with universal-ctags/ctags and try it when they encounter a situation where LSP is not up to the task.
Package management
After the development tools are configured, it is often necessary to install dependencies before formally writing code, which brings us to an important topic: package management.
The most important point of package management is to ensure that the dependencies are fixed for each project, i.e. reprodubile build, which is not a simple matter of choosing the right version when directly or indirectly depending on multiple versions of a library, npm2 that downloading each library dependency separately is one solution, and Go’s Minimal version selection is also a solution.
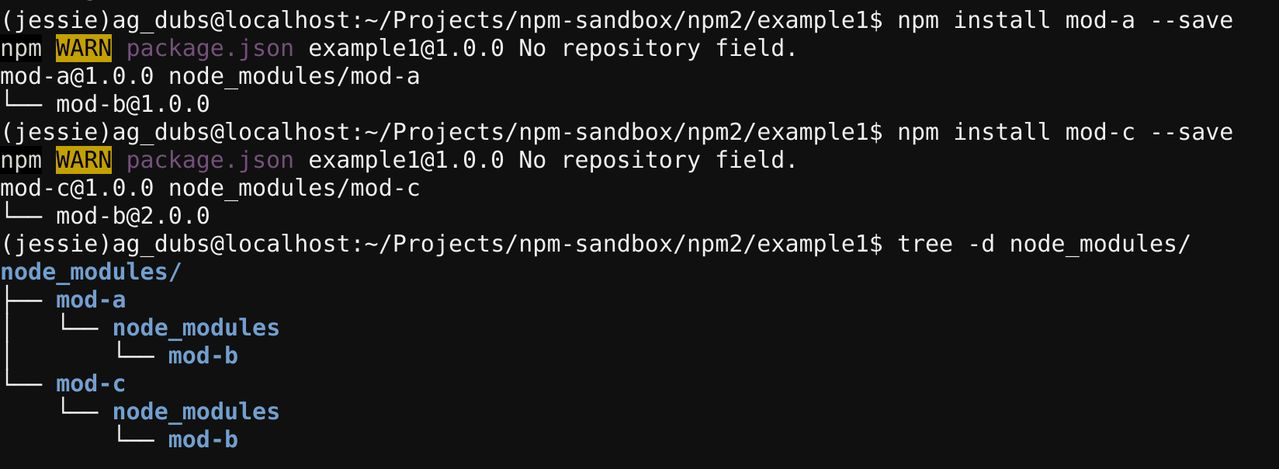
In NPM, there may be multiple versions of the same library.
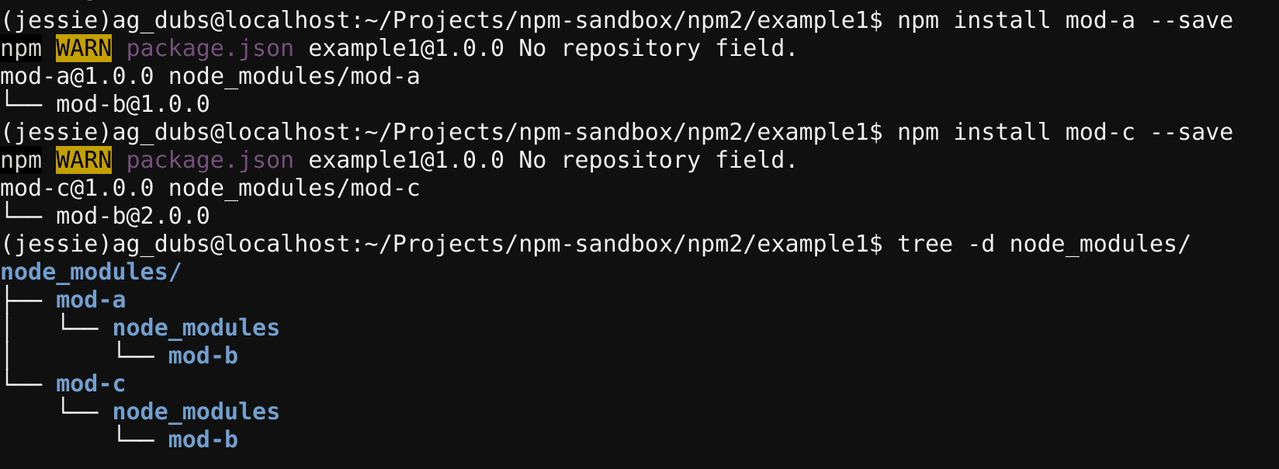
This is the structure that NPM relies on on disk.
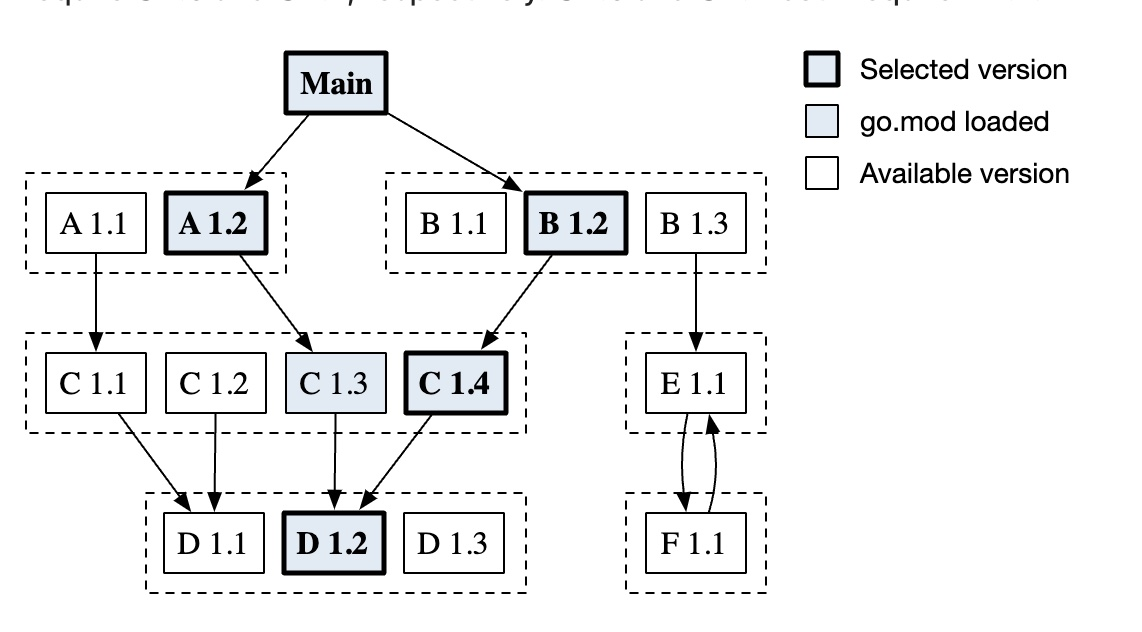
In Go, under the same major version, the largest minor version that meets the requirements is selected.
Before describing how C does package management, let’s review how C code is organized. A C project has two main types of files.
.hheader files, which are mainly used for declarations, including function signatures, types, etc..csource files, which are mainly used to provide implementation of the declarations in the header files
These two types of files are used at different stages of the build, and can be found in the following image (source).

As you can see, the header files will only be used in the second phase (i.e. preprocessing), the source files will only be used in the third phase (i.e. compilation), and the fourth and fifth phases will link the user’s own code together with the code of third-party dependencies to form the final executable.
When a project is used as a class library, the source code is generally not provided directly. Instead, a .so shared library or .a static library (created using the archive command) is provided corresponding to the source code file
This is to protect the source code from leaks on the one hand and to speed up the build process on the other. Users only need to compile their own code, and three-party dependencies do not need to be compiled repeatedly.
For C, there is no strict package organization, as long as the corresponding file can be found during compilation and linking. There are package managers in the community, such as vcpkg, conan-io/conan, CMake, etc. For personal projects, you can also choose the following approach: install the dependencies through the tools provided by the operating system (brew or apt, etc.) and then write the Makefile by hand to configure the compilation and linking parameters.
This approach may seem rudimentary, but it solves the problem more effectively, and with the addition of container technology, it also does a better job of version isolation. The only drawback is that it is not possible to specify the exact dependency version.
Makefile
The following is an introduction to the basic use of Makefile, a fully functional example can be found at: Makefile.
This is a relatively basic Makefile template. Makefile has default rules for converting .c files to .o files, with the following general commands.
Therefore, compile-time parameters can be defined via CFLAGS. There are several common variables in the Makefile.
$@for target name$*for target name without suffix$<for target dependencies, i.e., what comes after the colon
You can use pkg-config to simplify the manual configuration of CFLAGS, for example, if you have installed the dependency libcurl, you can use the following way to find Its compilation parameters and link parameters.
-Iis used to set the search directory for header files-lto specify the library to be linked by the linker
Generally C libraries are distributed with the corresponding header files and compiled shared or static libraries. On Debian systems, you can find the files installed by libcurl4-openssl-dev with the following command.
As for whether the linker chooses static or shared libraries, each linker does it differently, so refer to the documentation for the corresponding platform.
GNU ld does it by specifying static libraries by means of -l:, for example: -l:libXYZ.a will only go for libXYZ.a, while -lXYZ will expand to libXYZ.so or libXYZ.a. Reference.
Language features
Interpreting pointer declarations
Pointers, as the most important type of C, often cause a lot of trouble for beginners, not only in terms of usage, but also in terms of deciphering pointer definitions. For example.
ptr is better understood as a pointer to an int type, but what about ptr2? Is it a pointer to an array, or an array whose elements are pointers?
Actually, there is a nod to this question in the K&R C book, namely
The syntax of the declaration for a variable mimics the syntax of expressions in which the variable might appear.
That is, the declaration syntax of a variable clarifies the type of that variable in the expression. It seems a bit difficult to understand, so look at a few examples to understand.
|
|
*ptr is an expression of type int, so ptr must be a pointer to int.
|
|
arr[i] is an expression of type int, so arr must be an array and the elements of the array are int.
|
|
*arr[i] is an expression of type int, so arr[i] must be a pointer, so arr must be an array with elements that are pointers to int.
|
|
(*ptr)[100] is an expression of type int, so ptr must be a pointer to an array of type int.
|
|
*comp() is an expression of type int, so comp() must return an int pointer, so comp is a function that returns a pointer to an int.
|
|
(*comp)() is an expression of type int, so *comp must be a function, so comp is a function pointer
If you don’t understand the above explanation, it doesn’t matter, you can think about it when you write code. For complex declarations, it is generally recommended to use the typedef approach. For example.
The a1 defined in this way is not much more difficult to understand; it is first an array whose elements are pointers to int. K&R C has a program that converts complex declarations into textual descriptions: K&R - Recursive descent parser.
Memory management
C, being a system-level language, does not have runtime, and memory requested through functions like malloc needs to be freed manually by the programmer. This is something that high-level languages try to avoid nowadays, because programmers are very unreliable compared to computers. Fortunately, C has also evolved, and in the GNU99 extension (also supported by clang), a cleanup attribute to simplify memory freeing.
Let’s look at how memory releases were handled before cleanup was used (full code).
|
|
The request function is a relatively common practice in C, where the function getso to a unified place when it errors out, and cleans up memory there at the same time. Personally, I find this approach rather ugly, and it is easier to miss the release of a variable. Here’s a look at how it looks after using cleanup.
As you can see, str executes free_char for resource usage before the main function exits. For ease of use, the following macro can be defined with #define.
One thing needs to be clear: cleanup can only be used in local variables, not in function parameters or return values. Therefore, a complete C project also needs to use other means to ensure memory safety, the main tools are ASAN, valgrind, both of which are currently not The reader can choose according to the situation. Here is an example of the use of valgrind.
|
|
In the case of a memory leak, something along the following lines will be reported.
|
|
You can see the leaks very clearly, and then just follow the diagram to fix the corresponding logic. Report after repair.
In addition to using tools to avoid memory problems, a more elegant way is to design the API to ensure as few allocations as possible and to distinguish boundaries, which will be discussed later in the API design and not repeated here. The following links have more discussion on cleanup.
- Portable equivalent to gcc’s attribute(cleanup)
- A good and idiomatic way to use GCC and clang attribute((cleanup)) and pointer declarations
Strings
There is no string type in C. It is only defined that when the last element of a character array is NULL, this array can be used as a string, and strings in this way are called Null-terminated byte strings. Since the string length is not recorded, many operations take O(n) time, a more famous recent example being GTA developers, which improves performance by 50% by removing sscanf.
Moreover, there is no variable string like StringBuilder in C, so you need to manually request memory when performing some operations like replace/split, which is not only hard to use, but more importantly, prone to memory leaks and security problems. Here I have two recommended ways to simplify string handling in C.
-
Try to use fixed-size local variables
When doing some string operations, sometimes you don’t need to dynamically request memory, just use a fixed size of stack memory, which also saves you the trouble of free. For example.
-
Try to use mature string libraries from the community instead of
string.hsuch as Redis author’s Simple Dynamic Strings, for more see: Good C string library - Stack Overflow
-
Similarly, there is an implementation of hashtable in C.
Raw String
In the real world, there are inevitably more complex string scenarios, and other programming languages provide raw strings to simplify the process. In the current C standard, this usage is not supported, but the GNU99 extension provides this functionality:
|
|
In addition to this use of the GNU99 extension, the xxd command can also be used to embed the contents of a file into C code in the following manner.
Note that hello_txt does not end with NULL, which is not very convenient in some cases, and can be appended with the following command.
Designated Initializers
Designated Initializers. It is no exaggeration to say that this is the most exciting feature of ISO C99, making C more like a modern language and more useful at the same time.
When using this type of assignment, fields that are not assigned to a value are automatically initialized to zero, which is a very important point for pointers, which point to NULL instead of an arbitrary address.
static_assert
This is a feature added to C11 to check the truth of an assertion at compile time.
Generic selection
Generic selection. This feature of C11 supports generic programming to a certain extent.
|
|
Multi-threading
C11 has added the following two header files for multi-threading support.
- threads.h, similar to the pthread library
- stdatomic.h, providing atomic variables and a C++-like memory order
Coding style
Error handling
In traditional C, it is common practice for functions to return an integer error code, and the error message is obtained by reading a global variable. For example libc, the processing logic is roughly as follows.
The real return value is passed through the last pointer parameter. This practice has a long history but has two drawbacks, as follows.
- Handling verbosity. Each function call requires error handling and cannot be chained
- Forcing a single memory allocation. Because the return value needs to be assigned to a pointer argument, a memory allocation is inevitable
A recommended approach, modeled after the Result type in Rust, is to simply return a struct containing both the real data and the error message.
Other functions use the contents.valid judgment when using the results, this way the above two problems are solved, the use of the effect is as follows.
Since the value type struct is returned directly, this indirectly reduces the stress of manually managing memory. And since there are no pointers to pointers, the program will theoretically run faster.
API Packaging
In the above introduction to C package management, it was mentioned that when C programs use a library, they only need to care about the header file, which defines the public interface to use the library, i.e. the implementation and the interface are separate.
However, in the general sense, the header file only encapsulates the function, only the declaration of the function, not the implementation, but in fact, it can also encapsulate the struct. For example.
Here emacs_value is the encapsulation of the structure emacs_value_tag, the real definition of the structure in the source code file, the class library only needs to provide the constructor of the structure can be, the user does not need to sense the structure size and implementation.
For more information about the C API design, see this document (PDF), which is a discussion of.
Summary
As a language with a long history, C is not obsolete, but on the contrary, it has evolved gradually as the times progress. For programmers who have been using high-level languages for a long time, when they first switch to C, they may feel that it is too rudimentary and inefficient for development, but this is really just a superficial phenomenon that will fade away through familiarity with the whole ecosystem. And with less black magic, programmers will have a greater sense of control over the entire code base.
In the beginning you always want results.
In the end all you want is CONTROL.