
RisingWave is a recent open source Rust written cloud native streaming database product. Today a brief description of the state management mechanism in RisingWave based on the following diagram.
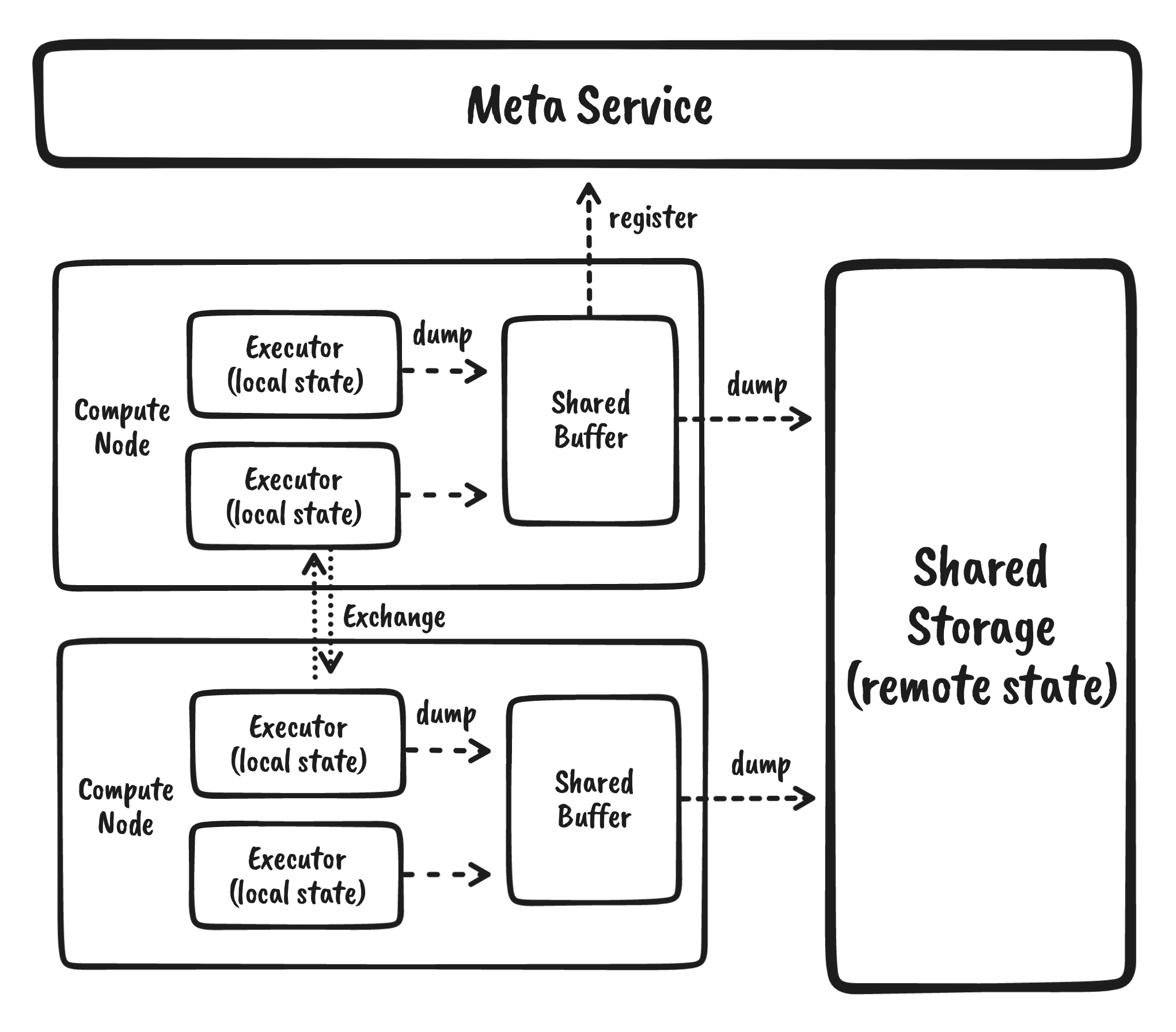
Hummock Overview
In RisingWave’s architecture, the storage of all internal state and materialized views is based on a set of stores called Hummock, which is not a storage system but a storage library. Hummock is not a storage system, but a storage library, and Hummock currently supports S3 protocol-compliant storage services as its backend.
From the interface, Hummock provides a Key-Value store-like interface:
- get(key, epoch): get a value
- iter(range, epoch): scan a range of key-value pairs
- batch_ingest(key-value batch): insert a batch of key-value pairs
As you can see, unlike the normal key-value store interface, Hummock does not provide the normal put interface, but only the batch input interface. Also, all operations are parameterized with epoch. This is related to RisingWave’s epoch-based state management mechanism.
Epoch-based checkpoint
RisingWave is a partial synchronized system based on a fixed epoch. every fixed time, the central meta node generates an epoch and issues an InjectBarrier request to all source nodes of the entire DAG. source nodes receive the After receiving the barrier, the source node injects it into a slice of the current data stream.
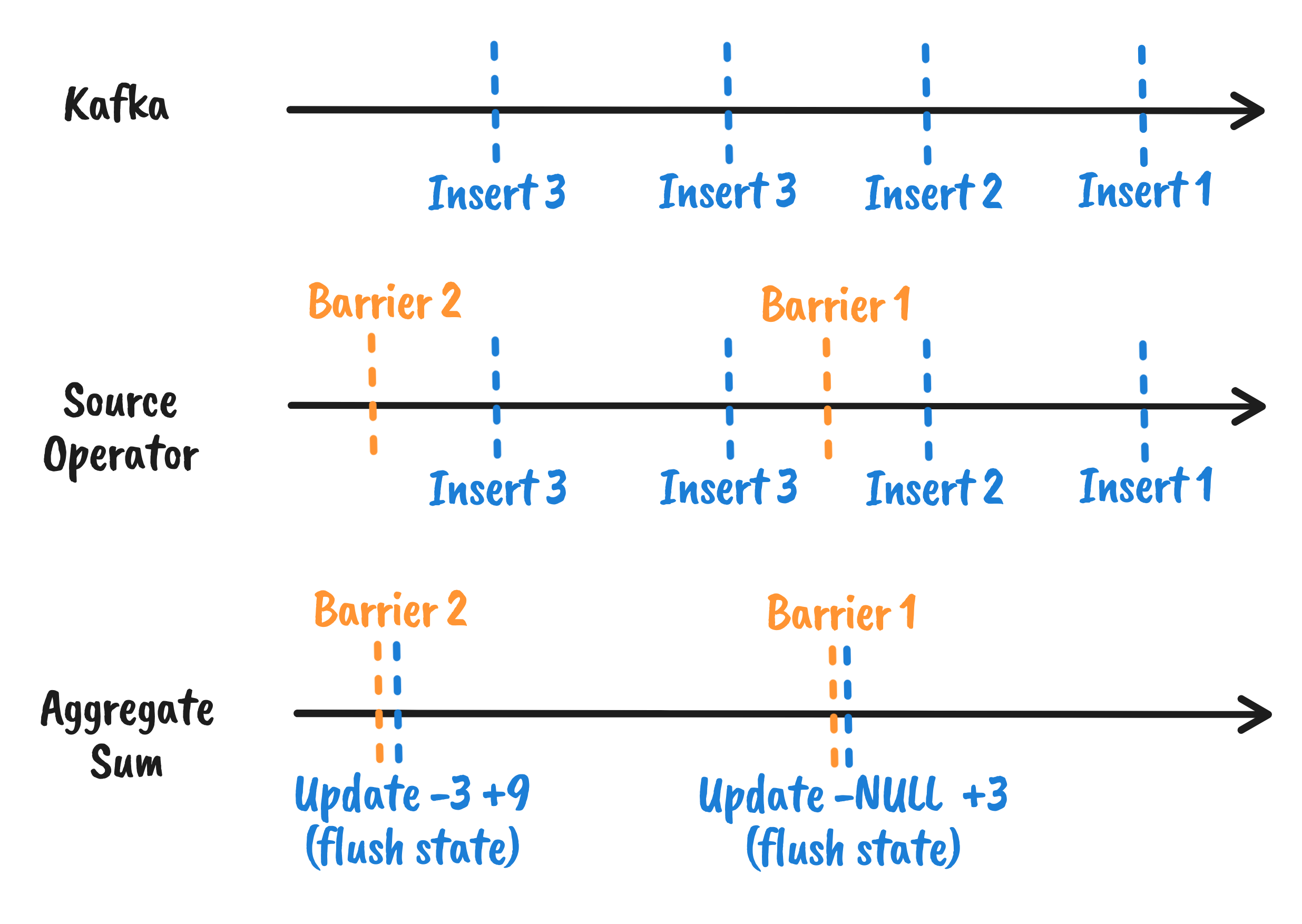
For any operator in the middle of the DAG, if a barrier is received, a number of things need to be done in sequence:
- if it is an operator with multiple input streams (Join, Union), then it needs to wait for barriers from other streams until it collects the same barrier from all input streams before processing.
- if there is a mutation that needs to be manipulated (for scale-out, create mview, drop mview), then apply the corresponding conf change.
- dump local state (async checkpoint)
3 is the focus of this article. In short, RisingWave is neither a local state backend nor a remote state backend, but a hybrid form. Only the state after the latest barrier is the local state maintained by the arithmetic itself, while the previous data is the remote state. the arithmetic chooses to dump state to the hummock store when and only when it receives a barrier. this is why the hummock store only provides the ingest This is why the hummock store only provides the ingest batch interface. —- operator will only dump the local state into hummock when it receives a barrier.
Async Checkpoint
As we mentioned earlier, when an operator receives a barrier, it will choose to dump data to Hummock, but we also mentioned that the barrier flows with the data stream, so if each operator needs to upload the wait state to shared storage (currently S3) synchronously, then the data processing will be blocking a whole round trip of the upload. If there are N stateful operators in the DAG, then the barrier will be delayed by N round trips during the whole transfer process, which will have a great impact on the processing power of the whole system. Therefore, we asynchronize the barrier process almost completely. The only thing a stateful operator needs to do after receiving a barrier is to synchronize the local state of the current epoch with std::mem::take, resetting it to an empty state so that the operator can move on to the next epoch’s data. This also introduces a number of problems.
- Where did the local state of this epoch get taken to?
- Since the local state is not uploaded to S3 synchronously, what should be done with the queries for the data during this time?
- What if the arithmetic crashes during the asynchronous upload, and how do we know if the checkpoint is successful?
To answer these questions, we introduced Shared Buffer.
Shared Buffer
Shared Buffer is a background task shared by all operators of a Compute Node. When a stateful operator receives a barrier, the local state is taken into the Shared Buffer.
Shared Buffer is mainly responsible for the following things.
- (Optional) The state of some operators may be small, such as SimpleAgg. Depending on the size of the local state, the state of the different operators is sliced and merged between the file granularity as appropriate.
- Upload the local state of the operator to shared storage.
- Register the state records that have been successfully uploaded to the meta service.
- Service queries from within the operator for local states that have not been successfully uploaded.
3 and 4 here are good answers to the questions raised in the previous subsection.
- From the user’s point of view, a checkpoint is considered complete only when all the local states of all the operators in an epoch are uploaded and successfully registered with the meta service, and both normal query and recovery are based on the latest complete checkpoint.
- From the internal operator’s point of view, when reading its own state, it must be required to read the complete and latest state, so in fact the internal operator needs the result of the remote state + shared buffer + local state merge. Here RisingWave also provides
MergeIteratorto do this generalization.
Local Cache
Since most of the state is in the remote state, RisingWave makes it easy to implement scale-out, but the cost is obvious. Compared to the local state design of Flink, RisingWave requires a lot more remote lookup.
Let’s take HashAgg as an example. When the HashAgg algorithm receives a Barrier, it dumps the statistics of the current barrier into the shared buffer, resetting the local state of the algorithm to empty. However, when processing the next epoch data, the recently processed group key may still be a hot spot, and we have to retrieve the corresponding key from the shared buffer or even the remote state. Therefore, our choice is not to clear the local state of the previous epoch by resetting it inside the operator, but to mark it as evictable, and then clean up the evictable data records when and only when there is not enough memory.
Based on this design, For the case of insufficient memory, or for operators with very small states (e.g., simple agg has only one record), all states are in memory and are operated by the current thread, maximizing performance, while dump is only used for recovery and query. For low memory cases, or for arithmetic with obvious hot and cold features (e.g. TopN), then it is possible to guarantee correct operation (remote lookup for cold data) and still fully exploit every bit of memory.
Compaction
The state is not uploaded to shared storage and not modified anymore, RisingWave will have a background compaction task.
Compaction has the following main purposes.
- Recycle garbage: Some of the arithmetic will generate DELETE records, which will also generate a tombstone record that needs to be deleted during compaction. Also, overwritten writes need to be merged and space reclaimed. 2.
- Organizing data: Some operators tend to merge the states of different operators in the same epoch when uploading to reduce write amplification. However, to optimize for subsequent queries, compaction tends to merge the states of different epochs of the same operator to reduce read amplification. In addition, RisingWave tends to align compute and storage distributions as much as possible, so compaction is also needed to organize the data after a scale-out occurs. We will expand on this later when we have a chance to introduce scale-out design, so we won’t go over it in this paper.
The Compactor that performs the compaction task can be flexibly deployed, either mounted on a compute node or started by a standalone process, and will also support serverless tasks to be started on the cloud in the future. As mentioned in Napa, if the user needs both freshness and query latency, then it is reasonable to pay more cost to perform more frequent compaction tasks, and vice versa to help the user to save money.
Conclusion
If we review the entire state store design, we see that it is a large cloud-based LSM tree. The local state and shared buffer of each operator corresponds to the memtable (allowing concurrent write, since all stateful operators guarantee distribution), while the shared storage stores SSTs, and the meta service is a centralized manifest that serves as the source of truth and triggers compaction tasks based on meta information.
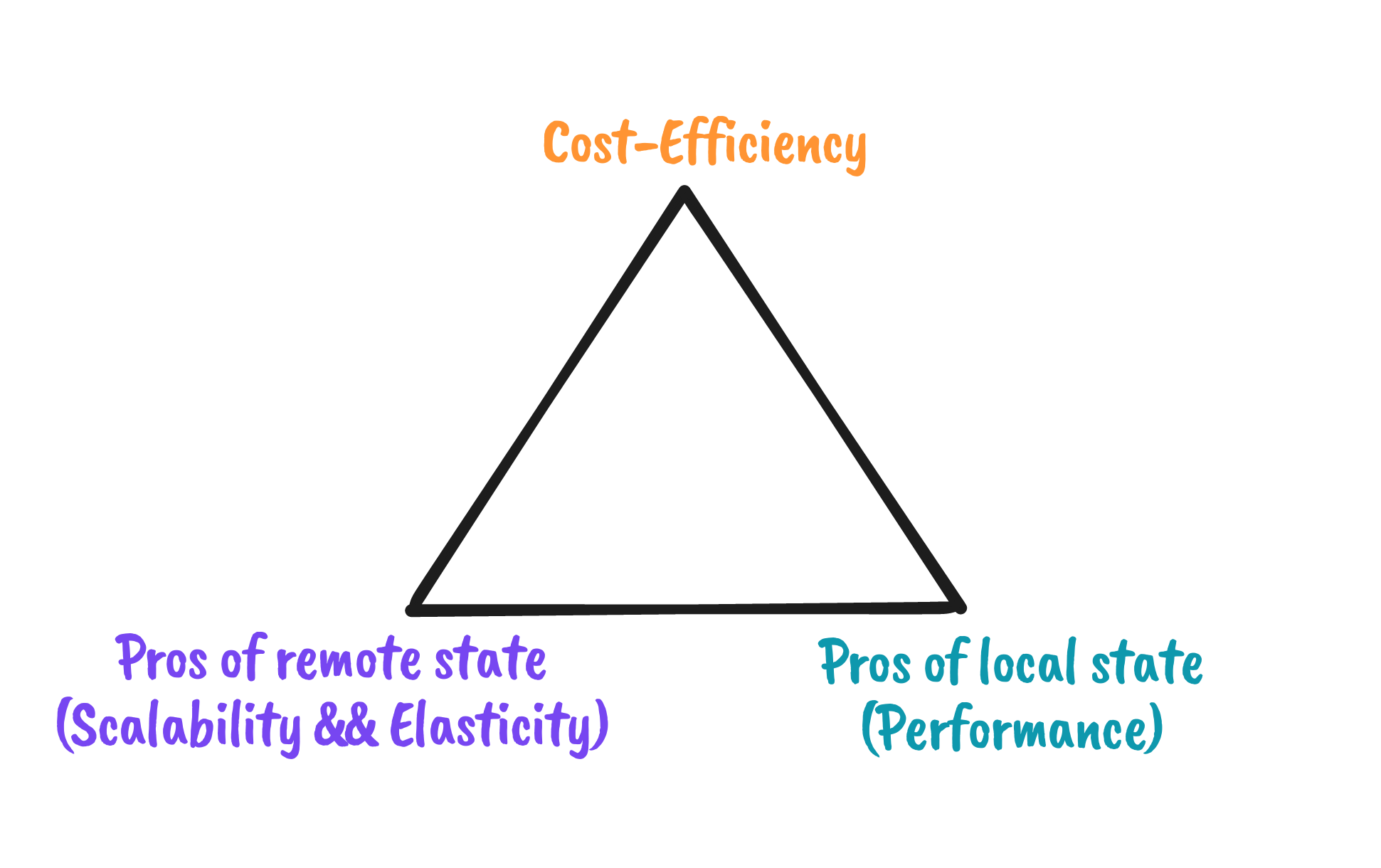
This paper briefly introduces the basic architecture and design trade off of the RisingWave State Store, with the core idea of leveraging the capabilities of shared storage on the cloud as much as possible, enjoying the benefits of remote state - scalability and more elastic scalability - while still hoping to The core idea is to leverage the power of shared storage on the cloud as much as possible to enjoy the benefits of remote state - scalability and more elastic scalability - while still achieving local state performance in smaller hot state scenarios. Of course, all of this is not without cost, and with a cloud-native architecture, we can leave this trade-off up to the user’s choice.
RisingWave is an active development project and the design is under active iteration, we are also currently introducing Shared State on top of the above design to reduce the stored state, which we will have a chance to expand on later. More design documentation can be found at RisingWave’s repo.