The eBPF is a register-based virtual machine originally designed to filter network packets, and is known as the Extended Berkeley Packet Filter (eBPF) since the original paper was written at the Lawrence Berkeley National Laboratory. This paper will explain why eBPF is so popular in easy-to-understand language.
Introduction to eBPF
In layman’s terms, eBPF is a custom program that runs in the kernel of the operating system when triggered by an event. You can think of eBPF programs as event-driven functions (e.g. AWS lamda, 👉OpenFunction). eBPF programs have access to a subset of kernel functions as well as memory. When an eBPF program is loaded into the kernel, there is a validator to ensure that it is safe to run, and if it cannot be validated, it will be rejected. This means that even garbage eBPF code will not crash the kernel.
In the container world, eBPF is becoming more and more popular, with the most popular products being Cilium and Pixie. Among them, Cilium is a CNI plug-in based on eBPF and also provides Service Mesh without Sidecar.
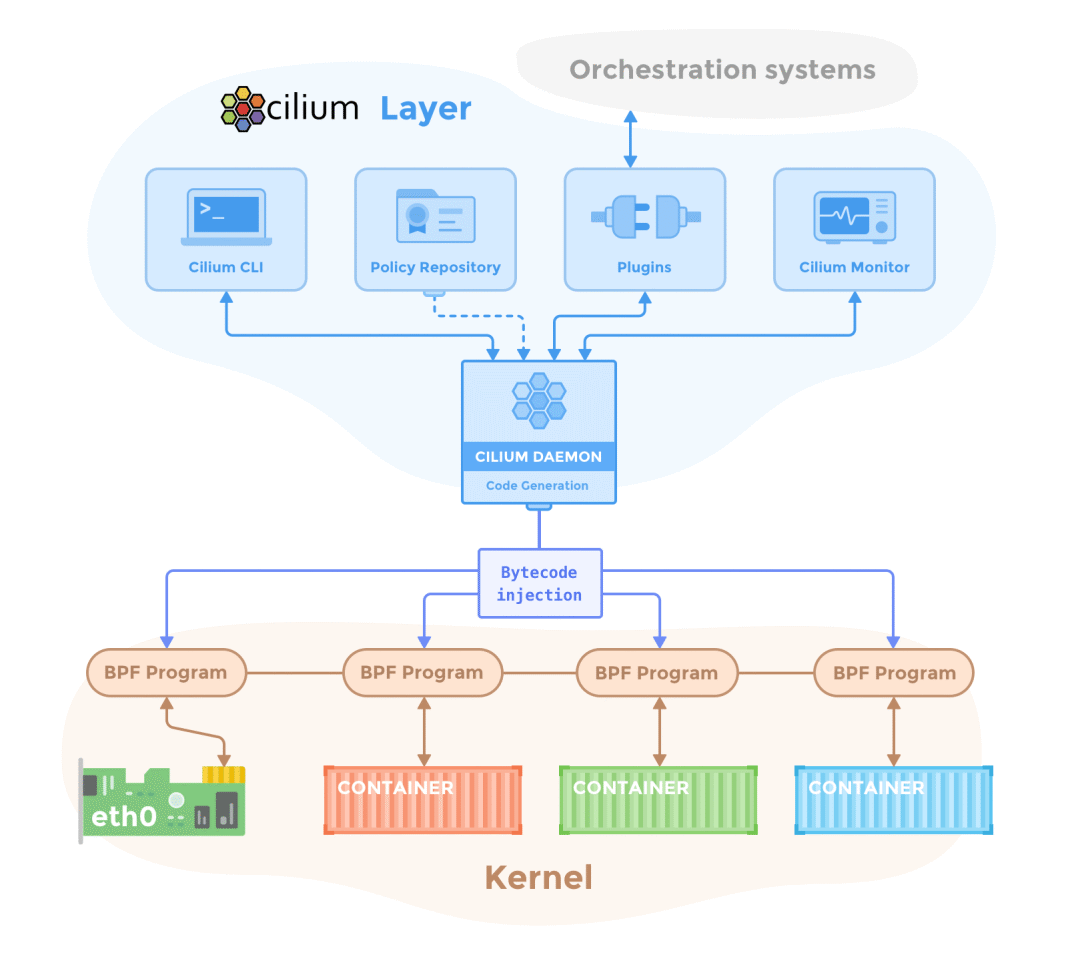
Pixie, on the other hand, is focused on using eBPF to achieve observability.
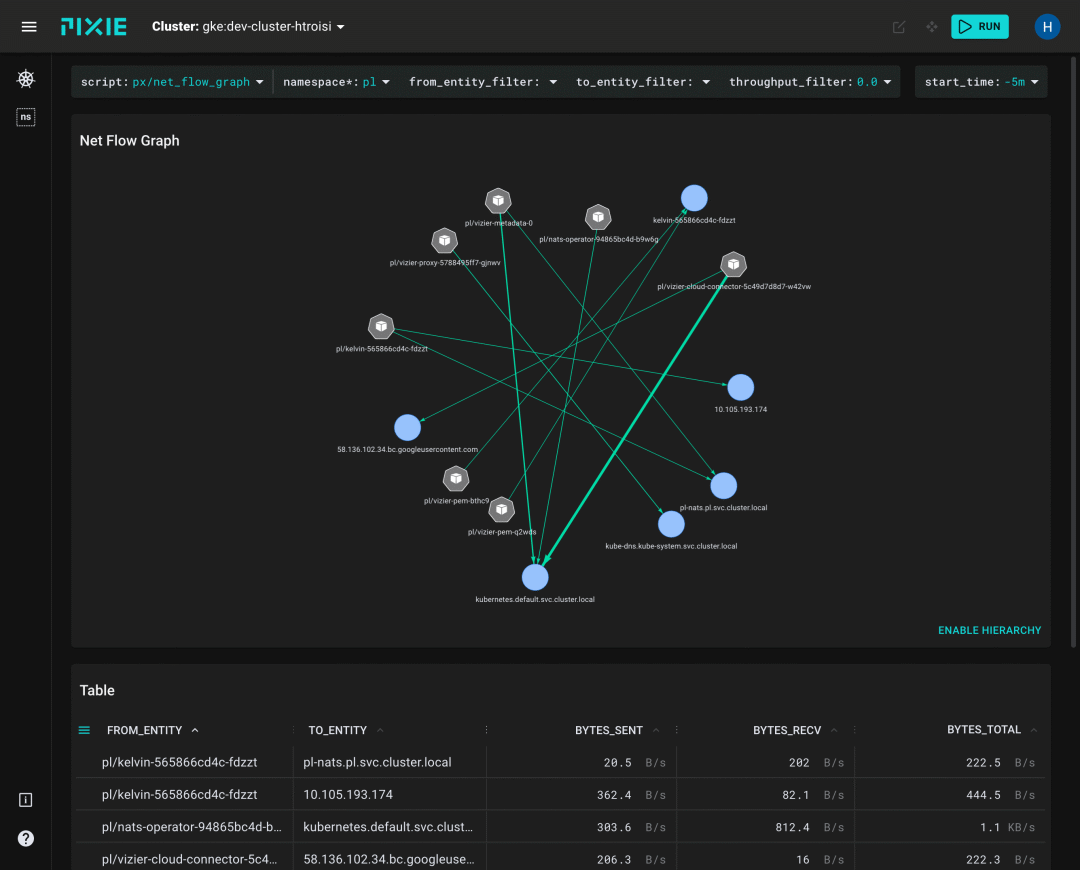
More eBPF usage scenarios.
- Debugging and tracing: tracing arbitrary system calls, kernel functions, and arbitrary processes in user space. Representative tool: bpftrace.
- Networking: Monitor, filter, and control traffic. A user-space program can attach a filter to any socket to monitor the traffic passing through it and perform various actions on it, such as allowing passage, denying passage, redirecting, etc.
- Security Monitoring and Isolation: eBPF programs can monitor and report on system calls that occur in the kernel, and can also prevent applications from executing certain system calls in the kernel (such as deleting files).
Although Linux has long supported these features mentioned above, eBPF can help us perform these tasks more efficiently, consuming less CPU and memory resources.
Why is eBPF so efficient?
eBPF programs “run” faster than traditional programs because their code is executed directly in kernel space.
Imagine a scenario where a program wants to count the number of bytes it sends out from a Linux system.
First, when network activity occurs, the kernel generates raw data, which contains a lot of information, most of which is not related to the “bytes” information. So, whatever raw data is generated, if you want to count the number of bytes sent out, you have to filter it over and over and do the math on it. This process is repeated hundreds of times a minute (or more).
Traditional monitoring programs run in user space, and all the raw data generated by the kernel must be copied from kernel space to user space, and this data copying and filtering is extremely taxing on the CPU. This is why ptrace is “slow” and bpftrace is “fast”.
Instead of copying data from kernel space to user space, eBPF allows you to run monitors directly in kernel space to aggregate observable data and send it to user space. eBPF can also filter data and create Histograms directly in kernel space, which is much faster than exchanging large amounts of data between user space and kernel space.
eBPF Mapping (eBPF Map)
eBPF has another hack that allows bidirectional data exchange between user space and kernel space using eBPF Map. In Linux, maps are a generic type of storage used to share data between user space and kernel space, and they are key-value stores that reside in the kernel.
For application scenarios like observability, eBPF programs perform calculations directly in kernel space and write the results to an eBPF map that can be read/written by user-space applications.
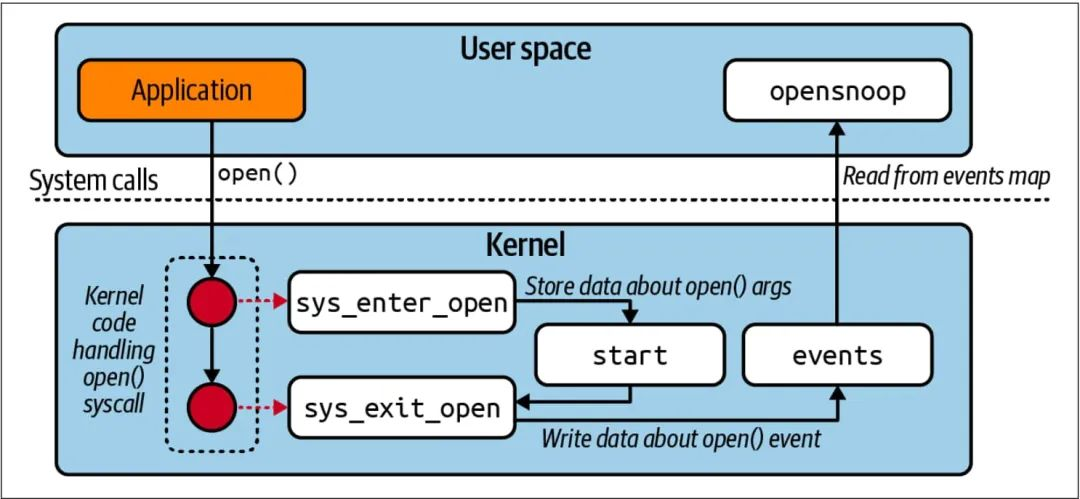
Now you should understand why eBPF is so efficient, right? The main reason is that eBPF provides a way to run custom programs directly in kernel space and avoid copying extraneous data between kernel space and user space.