Just now, a team of Meta (formerly Facebook) engineers blogged about a new Linux kernel feature called Transparent Memory Offloading (TMO), which can save 20% to 32% of memory per Linux server. to 32% of memory per Linux server. The feature is said to be available in Facebook/Meta servers in 2021, and the team has successfully upgraded the operating system components of TMO to the Linux kernel.

Transparent Memory Offload (TMO) is Meta’s solution for heterogeneous data center environments, introducing a new Linux kernel mechanism that measures in real time the work lost due to resource shortages between CPU, memory and I/O. Guided by this information, TMO automatically adjusts the amount of memory to be offloaded to heterogeneous devices (such as compressed memory or SSDs) without any a priori knowledge of the application.
That is, TMO adjusts for the sensitivity of slower memory accesses based on the performance characteristics of the device and the application. In addition to application containers, TMO also fully identifies offload timing from sidecar containers that provide infrastructure-level functionality.
Uninstallation timing
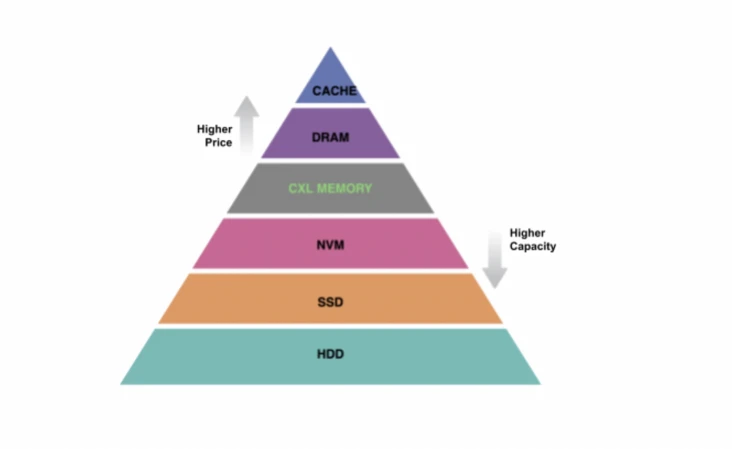
In recent years, a large number of cheaper non-DRAM memory technologies such as NVMe SSDs have been successfully deployed in data centers or are under development. In addition, emerging non-DRAM memory bus technologies [such as Compute Express Link (CXL)] offer memory-like access semantics and approach DDR performance. The data diagram showing the memory storage hierarchy illustrates how the various technologies stack on top of each other. The combination of these trends provides new opportunities for memory tiering that were not possible in the past.
Using memory tiering, less frequently accessed data is migrated to slower memory. The migration process can be driven by the application itself, a user space library, the kernel, or a virtual machine monitor.Meta’s TMO feature work focuses on kernel-driven migration or swapping, which can be applied transparently to many applications without modifying the application.
Despite its conceptual simplicity, kernel-driven swapping of latency-sensitive data center applications can be challenging at hyperscale. meta built TMO, a transparent memory offload solution for containerized environments.
Solution: Transparent Memory Offload
Components of TMO.
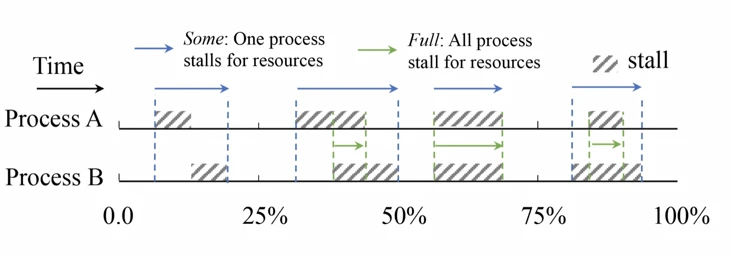
- Stress Suspension Information (PSI), a Linux kernel component for real-time measurement of work loss due to resource shortages between CPU, memory, and I/O. For the first time, Meta enables direct measurement of an application’s sensitivity to memory access slowdowns without having to resort to fragile low-level metrics such as page lift rates.
- Senpai is a user-space agent that applies light active memory pressure to efficiently offload memory across different workloads and heterogeneous hardware, with minimal impact on application performance.
- TMO performs memory offloading for swapping at sub-threshold memory stress levels with a turnover rate proportional to the file cache. This is in contrast to the historical behavior of swapping as an emergency overflow under severe memory stress.
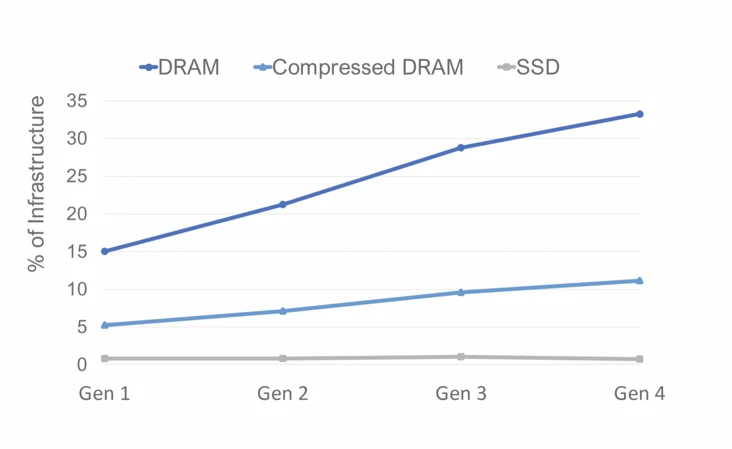
The cost of DRAM is a small fraction of the cost of the server, which prompted Meta to work on TMO. The data graph shows the relative costs of DRAM, compressed memory, and SSD storage. meta estimated the cost of compressed DRAM based on a compression rate of 3x representing the average of its production workloads.
DRAM costs are expected to grow to 33% of Meta’s infrastructure spending, while DRAM power consumption follows a similar trend to 38% of server infrastructure power consumption.
On top of compressed DRAM, Meta is also equipping all production servers with powerful NVMe SSDs, which account for less than 3% of server costs at the system level (about three times as much as the current generation of server compressed memory). The data graph shows that across generations, the cost of iso capacity to DRAM, SSD is still less than 1% of the server cost - about 10 times less per byte than compressed memory.
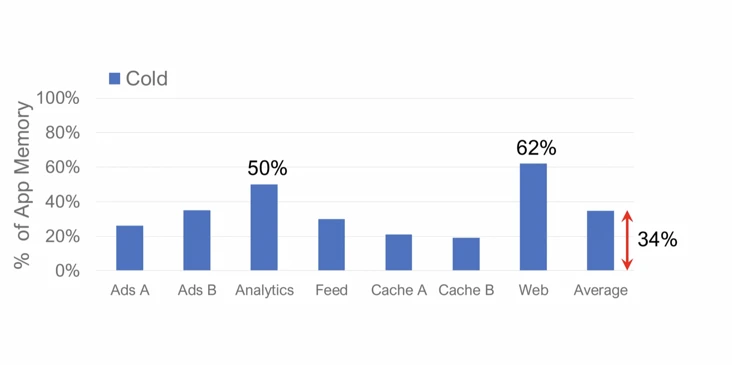
Although cheaper than DRAM, compressed memory and NVMe SSDs have poor performance characteristics. The good thing is that typical memory access patterns provide plenty of opportunity for offloading to slower media. The data graph shows “cold” application memory, the percentage of pages that have not been accessed in the last 5 minutes. This memory can be offloaded to compressed memory or SSDs without impacting application performance.
Overall, cold storage averages about 35% of Meta Server’s total memory. However, it varies widely across applications, ranging from 19% to 62%. This highlights the importance of offload methods that are robust to various application behaviors.
In addition to the frequency of access, the offload solution needs to consider what type of memory is being offloaded. Memory accessed by applications consists of two main categories: anonymous and file backup. Anonymous memory is allocated directly by the application in the form of heap or stack pages. File-backed memory is allocated by the kernel’s page cache to store frequently used file system data on behalf of the application.
TMO Design Overview
TMO contains multiple components across user space and kernel. “Senpai” sits at the heart of the offload operation as a user space agent that uses the kernel’s recycling algorithm to identify the least used memory pages and move them out of the offload backend in a control loop around the observed memory pressure. During this process, the PSI (Pressure Stall Information) kernel component quantifies and reports memory pressure, and the recycling algorithm is directed to specific applications via the kernel’s cgroup2 memory controller.
Senpai
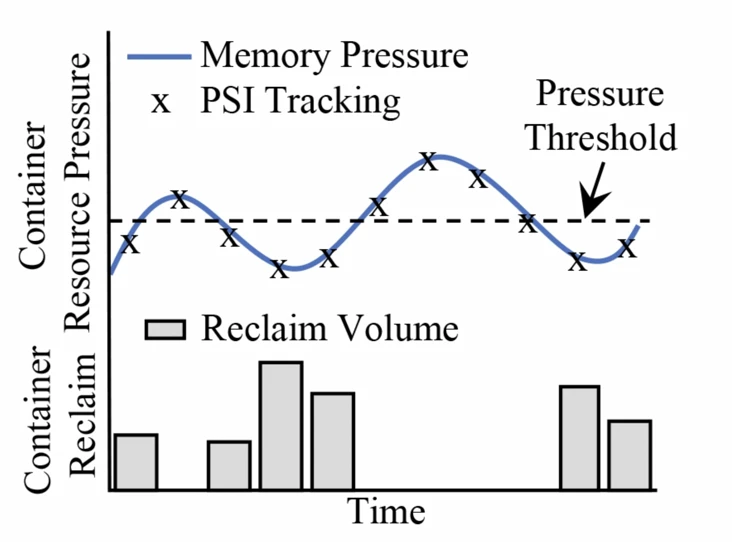
Senpai sits on top of the PSI metric, which uses pressure as feedback to determine how hard to drive kernel memory recycling. If the container measurement falls below a given pressure threshold, Senpai will increase the recovery rate; if the pressure drops below, Senpai will ease it. The pressure threshold is calibrated so that the paging overhead does not functionally impact workload performance.
swap algorithm
TMO offloads memory at low stress levels that do not affect the workload, but although Linux exits the file system cache under stress, it seems to be “reluctant” to move anonymous memory out to the swap device. Even when there is a known cold heap and the file cache exceeds the TMO stress threshold, the configured swap space can remain frustratingly empty.
Therefore, TMO introduces a new swap algorithm that takes advantage of these drives without reverting to the traditional setup of still using spinning storage media, which can be achieved by tracking the rate of file system cache reconfiguration in the system and scaling the swap. That is, for each file page that repeatedly needs to be read from the file system, the kernel attempts to swap out an anonymous page, which frees up space for a page flip. If a swap insert occurs, Recall is pushed back into the file cache again.
Currently, Meta manually selects the offload backend between compressed memory and SSD-backed swaps based on the memory compressibility of the application and its sensitivity to memory access slowdowns. While tools can be developed to automate this process, a more basic solution requires the kernel to manage the offload backend hierarchy (e.g., automatically using zswap for hotter pages, SSD for cooler or less compressible pages, and future folding of NVM and CXL devices into the memory hierarchy). The kernel recycling algorithm should dynamically balance between these memory pools, and Meta is actively working on this architecture.
With upcoming bus technologies such as CXL providing memory-like access semantics, memory offload can help offload not only cold storage but also hot storage, and Meta is also actively looking at this architecture to leverage CXL devices as a memory offload backend.