Differences between threads, kernel threads and user threads
-
Threads: From the kernel’s point of view there is no such concept as threads. Linux implements all threads as processes, and the kernel has no special scheduling algorithm to handle threads. A thread is simply seen as a process that shares some resources with other processes. Like processes, each thread has its own
task_struct, so in the kernel, a thread appears to be a normal process. Threads are also called lightweight processes. A process can have multiple threads, which have their own independent stack and are scheduled by the operating system to switch. On Linux they can be created with thepthread_create()method or theclone()system call. -
kernel threads: standard processes that run independently in kernel space. The difference between kernel threads and normal threads is that kernel threads do not have a separate address space.
-
User thread: also known as a Coroutine, is a thread based on top of, but lighter than, a thread that exists and is managed by the user runtime and is not perceived by the operating system; its switching is controlled by the user program itself, but the user thread is also run by the kernel thread. coroutine in Lua and Python, Golang’s goroutine are all user threads.
The relationship between the three is shown below.
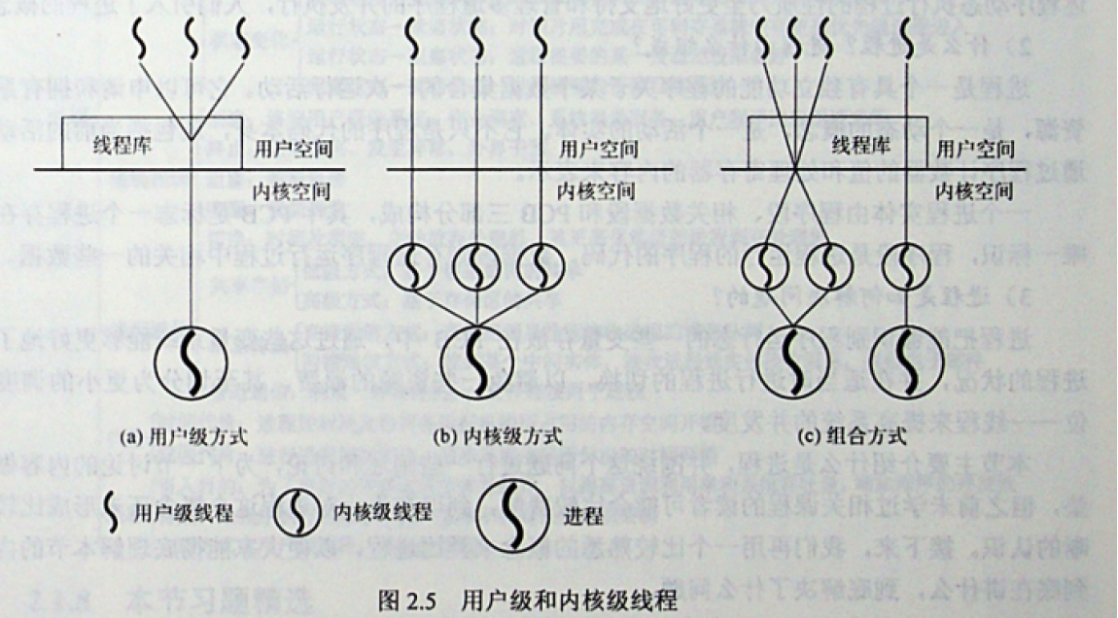
The relationship between goroutine and threads in Golang is shown below.
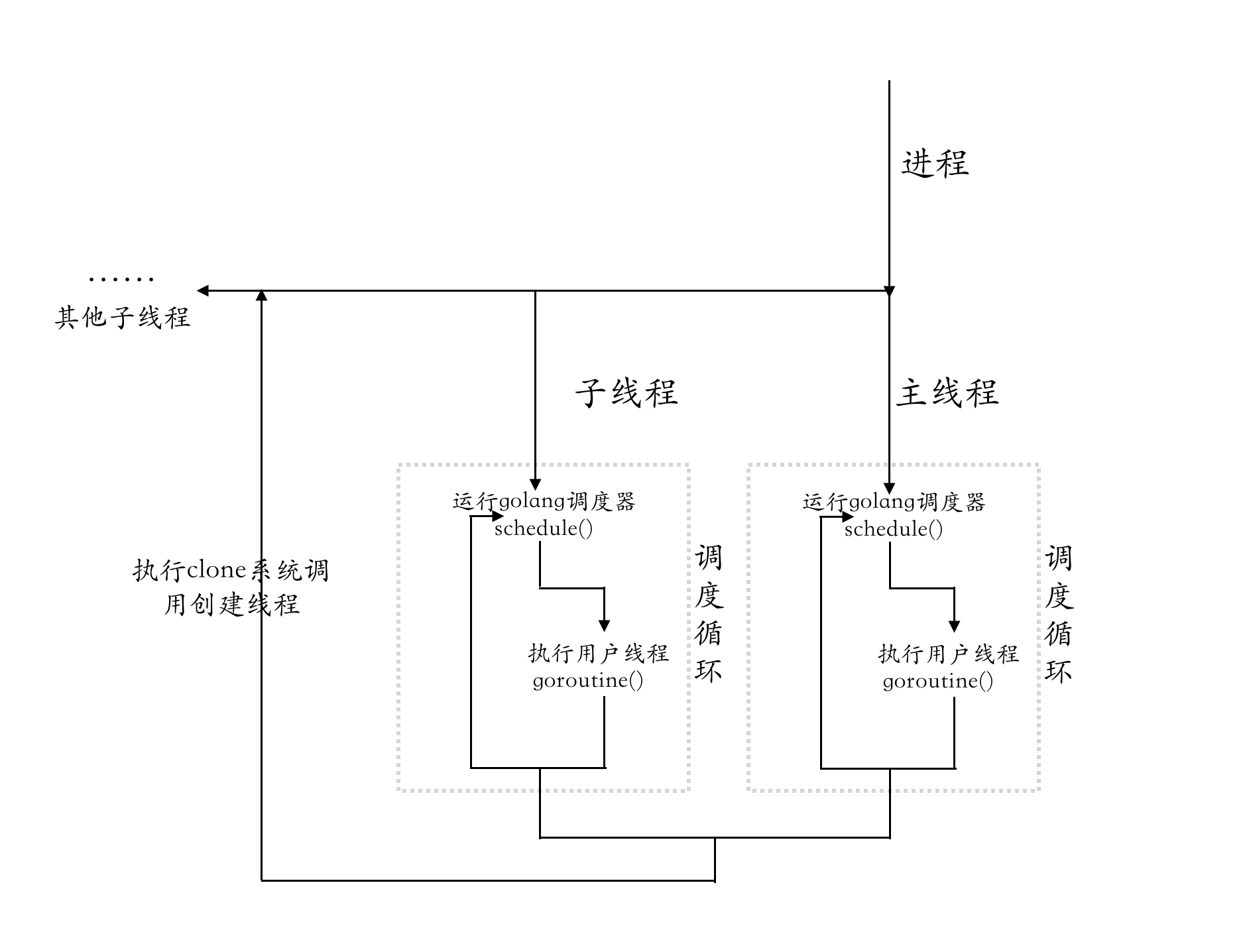
When a Golang program starts, it first creates a process, then a main thread, which executes some code for runtime initialization, including scheduler initialization, and then starts the scheduler, which keeps looking for a goroutine that needs to be run to bind to a kernel thread.
Reasons for Golang to use goroutine
Although there are already multi-threads and multi-processes in the operating system to solve the problem of high concurrency, but in today’s Internet mass and high concurrency scenario, the performance requirements are becoming more and more demanding, a large number of processes/threads will have the problem of high memory occupation and CPU consumption, and many services are transformed and refactored to reduce costs and increase efficiency.
A process can be associated with multiple threads, and the threads will share some resources of the process, such as memory address space, open files, process base information, etc. Each thread will also have its own stack and register information, etc. Threads are lighter than processes, while goroutines are lighter than threads, and multiple goroutines will be associated with one thread. Each goroutine will have its own stack space, so it will also be more lightweight. From process to thread to goroutine, it is actually a process of continuous sharing to reduce switching costs.
Golang uses goroutine mainly for the following reasons.
- The problem of too heavy kernel thread creation and switching: both creation and switching require access to the kernel state, and access to the kernel state has high overhead and high performance cost, while goroutine switching does not require access to the kernel state.
- Too heavy thread memory usage: the default stack size for creating a kernel thread is 8M, while creating a user thread, i.e. goroutine, requires only 2K memory, which is also automatically increased when the goroutine stack is not enough.
- goroutine scheduling is more flexible, all goroutine scheduling and switching happens in the user state, there is no overhead of creating threads, and even when a goroutine blocks, other goroutines on the thread will be scheduled to run on other threads.
Distribution of goroutines in the process memory space
A goroutine is essentially a function that can be suspended and resumed. When a goroutine is created, a section of space is allocated in the heap of the process, which is used to store the goroutine stack area, and then copied from the heap when the goroutine needs to be resumed to restore the runtime state of the function.
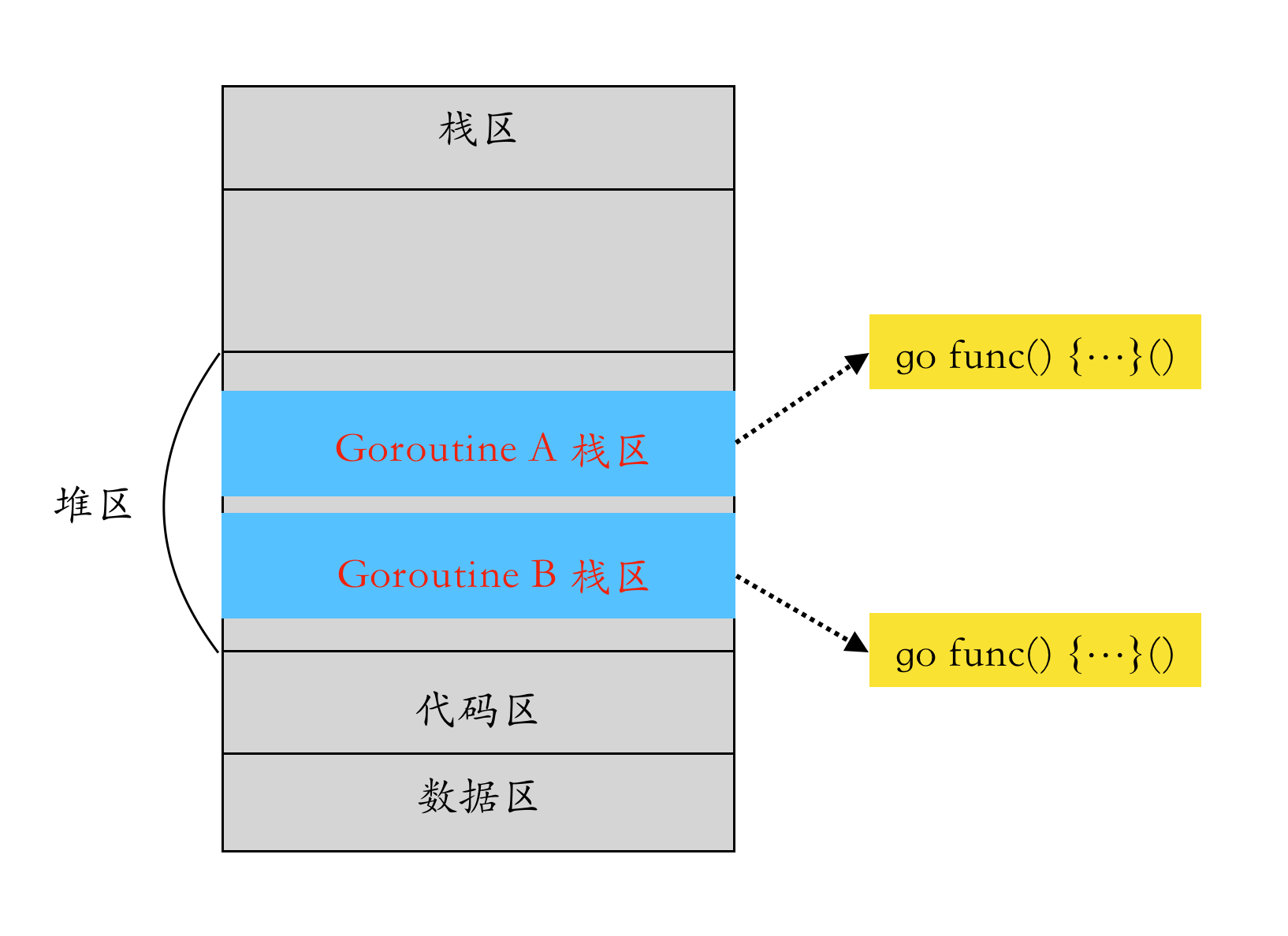
GPM Model Analysis
The commit history of Golang code shows that a lot of code is translated from C to Go. A lot of the code in the runtime before go 1.4 was implemented in C. For example, many of the scheduling-related functions implemented in the current version of proc.go were originally implemented in C, but later translated in Go code. If you need to know the details of Golang’s original design, you can look at the earliest C code commits.
|
|
This article focuses on the current GPM model in the scheduler, starting with an understanding of the roles and connections of the three components of the GPM model.
- G: Goroutine, the function we run in a Go program using the
gokeyword. - M: Machine, or worker thread, which stands for system thread, and M is an object in runtime that creates a system thread and binds to that M at the same time as each M is created.
- P: Processor, similar to the concept of a CPU core, which can execute Go code only when M is associated with a P.
G needs to be bound to M at runtime, and M needs to be bound to P. M is not equal in number to P. This is because M gets caught in system calls or blocks for other things while running G. New M is created in runtime when M is not enough, so the number of M may grow as the program executes, while P stays the same without user intervention, and the number of G is determined by is determined by the user code.
The connection between the three GPMs is shown below.
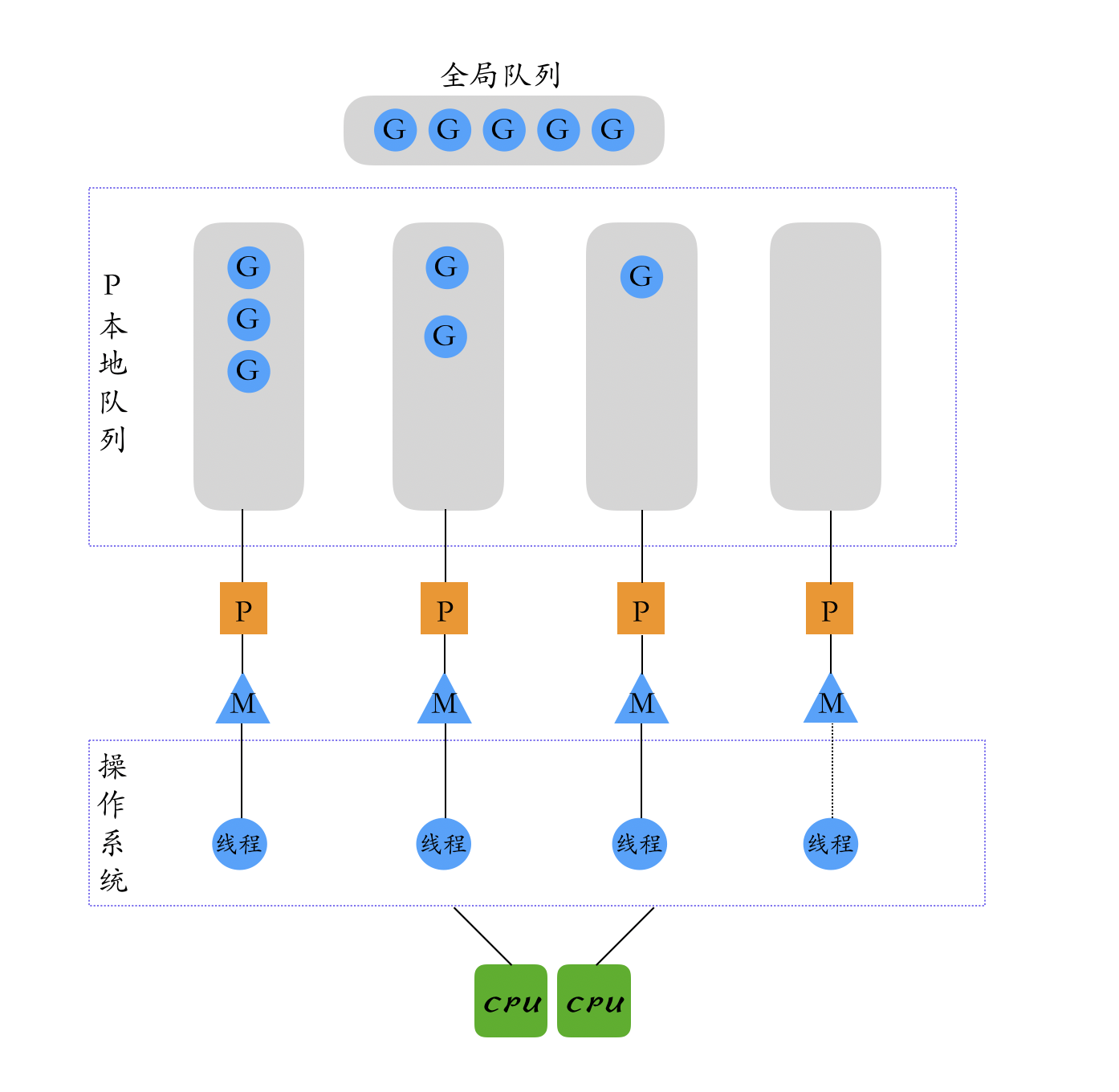
- Global queue: Holds the G’s waiting to run.
- P’s local queue: Similar to the global queue, it also holds the G waiting to run, and the number of Gs stored is limited. When a new G is created, the G is added to the local queue of P. If the queue is full, a part of the G in the local queue will be moved to the global queue.
- P list: All P’s are created at program startup and stored in an array of up to
GOMAXPROCS(configurable). - M: If a thread wants to run a task, it has to get P and then get G from P’s local queue. When P’s queue is empty, M will also try to get a batch of G from the global queue and put it into P’s local queue, or steal half from other P’s local queue and put it into its own P’s local queue, M runs G. After G is executed, M will get the next G from P and so on.
GPM Life Cycle
1. Life cycle of P
The structure of the P object is shown below.
|
|
(1)Why do we need P?
Before Golang 1.1, there was no P component in the scheduler. The performance of the scheduler was still poor at this time. Dmitry Vyukov of the community summarized the problems in the current scheduler and designed to introduce the P component to solve the current problems (Scalable Go Scheduler Design Doc), and introduced the P component in Go 1.1. The introduction of the P component not only solves several problems listed in the documentation, but also introduces some good mechanisms.
The documentation lists 4 main issues with the scheduler, mainly
-
The global mutex lock (
sched.Lock) problem: In testing, the community found that Golang programs consume 14% of their CPU usage at runtime on processing global locks. Without the P component, M could only fetch G from the global queue by adding a mutex lock, and there was a delay in the locking phase for other goroutine processing (creation, completion, rescheduling, etc.); with the introduction of the P component, there is a queue in the P object to hold the list of G. The local queue in P solves the problem of a single global lock in the old scheduler, and the G queue is split into two categories,schedcontinues to keep the global G queue, while there will be a local G queue in each P. At this time, M will run the G in P’s local queue first, and access without locking. -
G switching problem: frequent switching of runnable G by M will increase the latency and overhead, for example, the newly created G will be put into the global queue instead of being executed locally in M, which will cause unnecessary overhead and latency, and should be executed on the M that created the G first; after the P component is introduced, the newly created G will be put into the local queue of the G-associated P first.
-
M’s memory cache (
M.mcache) problem: In the version without P component, each M structure has amcachefield,mcacheis a memory allocation pool, small objects will be allocated directly frommcache, when M is running G, G needs to request small objects will be allocated directly from M’smcache, G G can be accessed without locking, because each M will only run one G at the same time, but there will only be some active M running G at each time in runtime, the other M blocking due to system calls etc. actually do not needmcache, this part ofmcacheis wasted, each M’smcachehas about 2M size of available memory, when there are thousands of M in the When there are thousands of M’s in the blocking state, a lot of memory is consumed. In addition, there is the problem of poor data locality, which means that M caches the small objects needed by G when it runs G. If G is dispatched to the same M again later, then it can speed up the access, but in the actual scenario, the probability that G is dispatched to the same M is not high, so the data locality is not good. With the introduction of the P component,mcacheis shifted from M to P, and P keepsmcache, which means there is no need to allocate amcachefor each M, avoiding excessive memory consumption. In this way, in a highly concurrent state, each G will only use memory when it is running, and each G will be bound to a P, so only the currently running G will occupy amcache, for which the number ofmcaches is the number of P, and no locks will be generated during concurrent accesses. -
Frequent thread blocking and wake-up problems: In the original scheduler, the number of system threads is limited by
runtime.GOMAXPROCS(). Only one system thread is opened by default. And since M performs operations such as system calls, when M blocks, it does not create a new M to perform other tasks, but waits for M to wake up, and M switches between blocking and waking frequently, which causes additional overhead. In the new scheduler, when M is in the system scheduling state, it will be disassociated from the bound P and will wake up the existing or create a new M to run other G bound to P.
(2) New logic for P
The number of P’s is initialized at runtime startup and is by default equal to the number of logical cores of the cpu. It can be set at program startup with the environment variable GOMAXPROCS or the runtime.GOMAXPROCS() method, and the number of P’s is fixed for the duration of the program.
In the IO-intensive scenario, the number of P can be adjusted appropriately, because M needs to be bound to P to run, and M will fall into the system call when executing G. At this time, P associated with M is in the waiting state, if the system call never returns, then the CPU resources are actually wasted during this time waiting for the system call, although there is a sysmon monitoring thread in runtime can seize G, here is to seize P associated with G, let P rebind a M to run G, but sysmon is periodic execution of seizure, after sysmon stable operation every 10ms to check whether to seize P, the operating system in 10ms can perform multiple thread switching, if P is in the state of the system call there is a need to run G, this part of G is not executed, in fact, CPU resources are wasted. In some projects, we can see the operation of modifying the number of P. The open source database project https://github.com/dgraph-io/dgraph adjusts GOMAXPROCS to 128 to increase the IO processing power.
(3) P destruction logic
If GOMAXPROC is not adjusted during the program run, unused P will be placed in the scheduler’s global queue schedt.pidle and will not be destroyed. If GOMAXPROC is turned down, p.destroy() will reclaim the excess P-associated resources and set the P state to _Pdead, while there may still be M objects associated with P, so P objects will not be reclaimed.
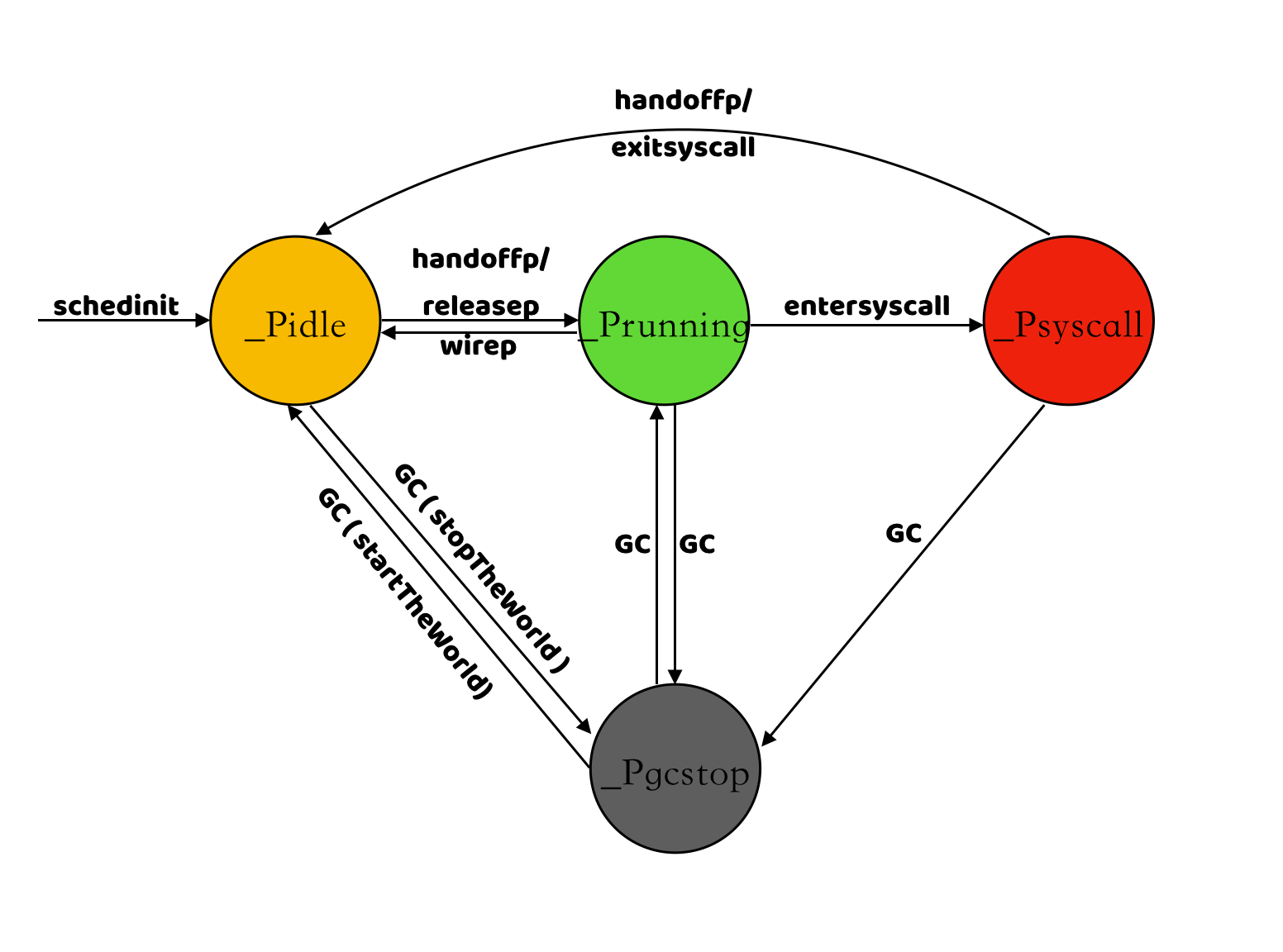
(4) The state of P
| state | Description |
|---|---|
_Pidle |
The state after P is initialized, when no user code or scheduler is running yet |
_Prunning |
The state of P when it is bound by M and running user code |
_Psyscall |
P will be set to this state by the associated M when a system call is required when G is executed |
_Pgcstop |
P will be set to this state by the associated M when a GC occurs during program operation |
_Pdead |
If the number of GOMAXPROCS is reduced while the program is running, the excess P will be set to the _Pdead state |
2. Life cycle of M
The structure of M object is as follows.
|
|
(1) New creation of M
M is an object in runtime that represents a thread. Each M object created creates a thread bound to M. New threads are created by executing the clone() system call. runtime defines the maximum number of M to be 10000. The maximum number of M is defined in runtime as 10000, which can be adjusted by debug.SetMaxThreads(n).
New M will be created in the following two scenarios.
- The Golang program creates the main thread when it starts, and the main thread is the first M i.e. M0.
- When a new G is created or a G goes from
_Gwaitingto_Grunningand there is a free P,startm()will be called, first getting an M from the global queue (sched.midle) and binding the free P to execute the G. If there is no free M, M will be created bynewm().
(2) Destruction of M
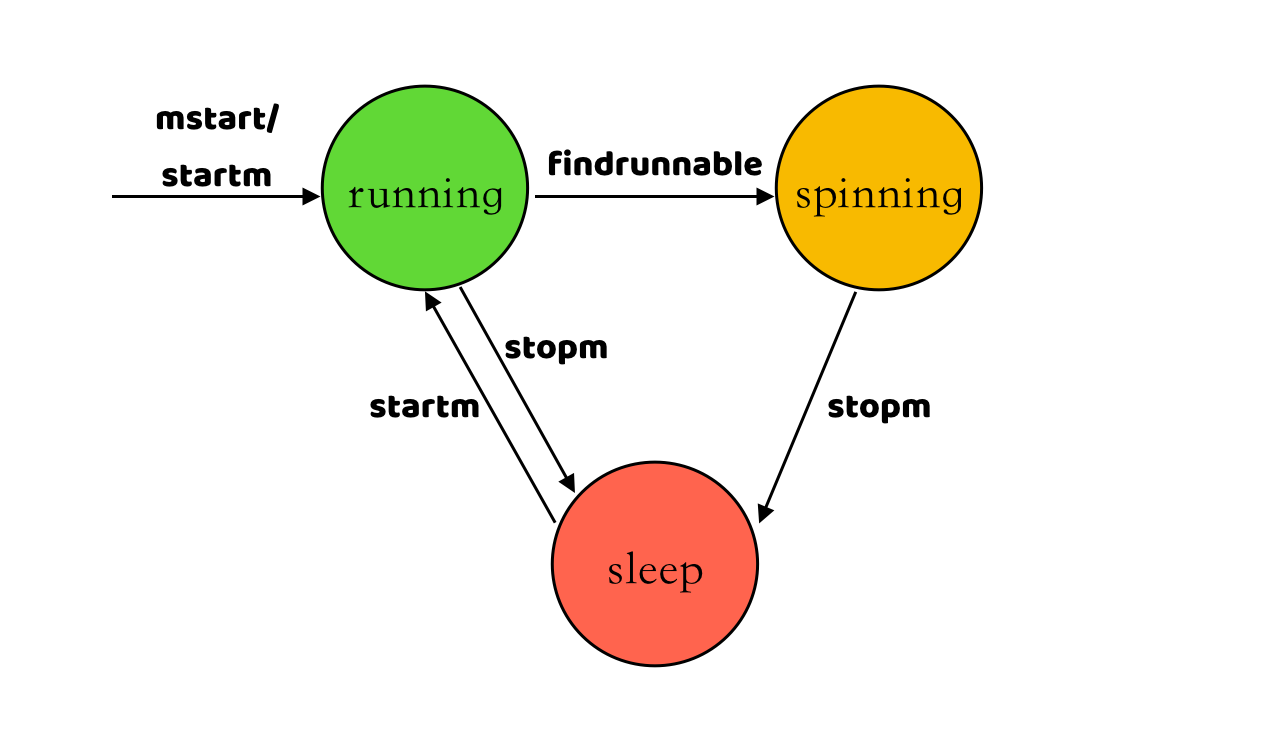
M will not be destroyed, but will go to sleep by executing the stopm() function when no runnable G can be found or no free P can be bound, and will go to sleep by executing the stopm() function in the following two cases.
-
When the P bound by M has no runnable G and cannot steal runnable G from other P, M will try to enter the spin state first (
spinning), only some M will enter the spin state, the number of M in the spin state is at most half of the number of P in the non-idle state (sched.nmspinning < (procs- sched.npidle)/ 2), M in the spin state will steal executable G from other P. If M does not steal G in the spin state or does not enter the spin state, it will go directly to the sleep state. -
When the G associated with M enters the system call, M will actively unbind with the associated P. When the G associated with M executes the
exitsyscall()function to exit the system call, M will find a free P to bind, if no free P is found then M will callstopm()to enter the sleep state.
The stopm() function puts the sleeping M into the global idle queue (sched.midle).
(3) Operation of M
M needs to be associated with P to run, and M has affinity with P. For example, when executing the entersyscall() function to enter the system call, M will actively unbind with the current P. M will record the current P in m.oldp, and when executing the exitsyscall() function to exit the system call, M will preferentially bind the P in m.oldp.
(4) What is the role of M0 and how does it differ from the M associated with other threads?
M0 is a global variable defined in src/runtime/proc.go, M0 does not need to allocate memory on the heap, all other M’s are objects created by new(m) and their memory is allocated from the heap, M0 is responsible for performing initialization operations and starting the first G, the Golang program will start M0 first, M0 and the main thread are bound. M0 is bound to the main thread, and when M0 starts the first G, the main goroutine, it functions just like any other M.
(5) Why should we limit the number of M’s?
Golang added a limit on the number of M’s in version 1.2 (runtime: limit number of operating system threads), the default maximum number of M’s is 10000, and in In version 1.17 the scheduler was initialized with a default value set in the schedinit() function (sched.maxmcount = 10000).
Why limit the number of M’s? In the article on refactoring the scheduler Potential Further Improvements, Dmitry Vyukov has already mentioned the need to limit the number of M’s. In scenarios where there is high concurrency or a large number of goroutines are repeatedly created, more threads are needed to execute the goroutine, and too many threads can exhaust system resources or trigger system limitations that can cause program exceptions. The kernel also consumes additional resources when scheduling a large number of threads, so limiting the number of M threads is mainly to prevent unreasonable use of the program.
The default size of each thread stack on Linux is 8M. If 10,000 threads are created, 78.125 G of memory is required by default, which is already a very large amount of memory usage for ordinary programs.
- /proc/sys/kernel/threads-max: indicates the maximum number of threads supported by the system.
- /proc/sys/kernel/pid_max: indicates the limit of the system global PID number value, every process or thread has an ID, the process or thread will fail to be created if the value of the ID exceeds this number.
- /proc/sys/vm/max_map_count: indicates a limit on the number of VMAs (virtual memory areas) a process can have.
(6) States of M
Through the analysis of the new and destruction process of M, M has three states: running, spin, and sleep, and the transitions between these three states are shown below.
3. Life cycle of G
The structure information of G is shown below.
|
|
(1) New creation of G
When a Golang program starts, the main thread creates the first goroutine to execute the main function, and a new goroutine is created if the user uses the go keyword in the main function, and the user can continue to create new goroutines in the goroutine using the go keyword. goroutines are created goroutines are created by calling the newproc() function in the golang runtime. The number of goroutines is limited by system resources (CPU, memory, file descriptors, etc.). If there is only simple logic in a goroutine, it is theoretically fine to have as many goroutines as you want, but if there are operations such as creating network connections or opening files in a goroutine, too many goroutines may result in reports such as too many files open or Resource temporarily unavailable and so on, causing the program to execute abnormally.
The newly created G is placed first in the runnext queue of the current G association P via the runqput() function. only one G is kept in P’s runnext queue, and if there is already a G in the runnext queue, it is replaced with the newly created G. Then the original G in runnext is placed in P’s local queue, runq, and if P’s local queue is full, half of the G in P’s local queue is moved to the global queue sched.runq. The main reason for moving the newly created G to P’s runnext first is to improve performance. runnext is a completely private queue for P. If G is placed in P’s local queue runq, the G in the runq queue may change due to other M’s stealing, and each time G is fetched from P’s local queue, atomic. LoadAcq and atomic.CasRel atomic operations every time G is fetched from the P local queue, which introduces additional overhead.
(2) Destruction of G
When G exits, the goexit() function is executed and the state of G changes from _Grunning to _Gdead. However, the G object is not freed directly, but is put into the local or global idle list gFree of the associated P for reuse via gfput(). Priority is given to the P local queue, and if there are more than 64 gFree in the P local queue, only 32 will be kept in the P local queue, and any more than that will be put into the global idle queue sched.gFree.
(3) Runs of G
G is bound to M to run, and M needs to be bound to P to run, so theoretically the number of running G at the same time is equal to the number of P. M does not keep the state of G. G keeps the state in its gobuf field, so G can be scheduled across M. After M finds a G to run, it switches from the g0 stack to the user G’s stack to run via the assembly function gogo().
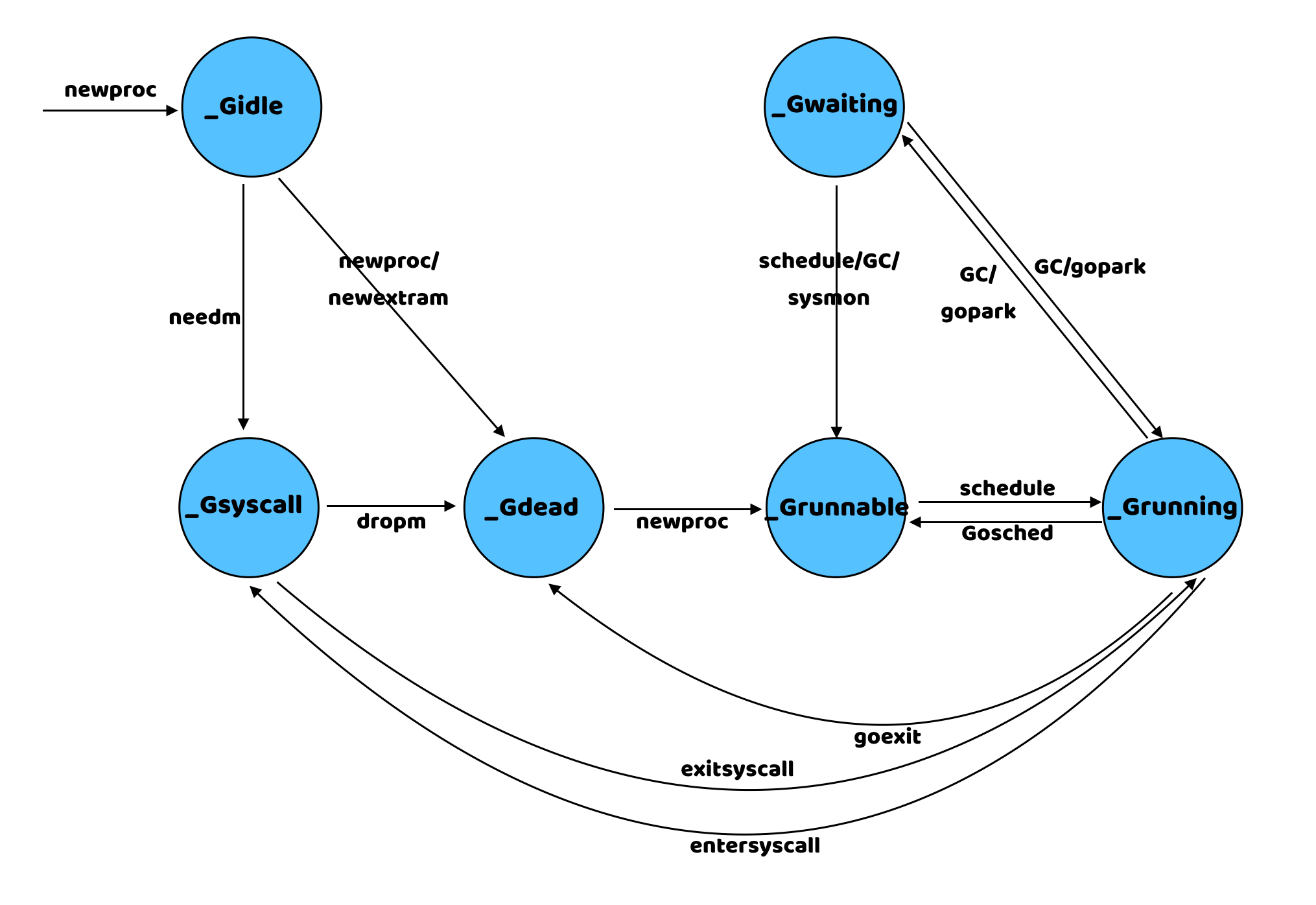
(4) What are the states of G?
The states of G are defined in the src/runtime/runtime2.go file. There are three main types of states, one is a few states when the goroutine is running normally, then the ones related to GC, and the remaining states are unused.
The role of each transition state and the relationship between the states are shown below.
| states | Description |
|---|---|
_Gidle |
has just been created and not yet initialized |
_Grunnable |
No execution code, no ownership of the stack, stored in the run queue |
_Grunning |
can execute code, has ownership of the stack, has bound M and P |
_Gsyscall |
System call being executed |
_Gwaiting |
Blocked due to runtime, not executing user code and not on the run queue |
_Gdead |
Run completed in exit state |
_Gcopystack |
The stack is being copied |
_Gpreempted |
Blocked due to preemption, waiting for wake-up |
_Gscan |
GC is scanning the stack space |
4. The role of g0
There are two types of g0 in runtime, one is m0-associated g0 and the other is other m-associated g0. m0-associated g0 is defined as a global variable and its memory space is allocated on the system’s stack with a size of 64K - 104 bytes, and other m-associated g0 is a stack allocated on the heap with a default size of 8K.
src/runtime/proc.go#1879
Every time an M is started, the first goroutine created is g0. Each M will have its own g0. g0 is mainly used to record the stack information used by the worker thread, and is only used to be responsible for scheduling, which needs to be used when executing the scheduling code. When executing the user goroutine code, the stack of the user goroutine is used, and the stack switch occurs when scheduling.
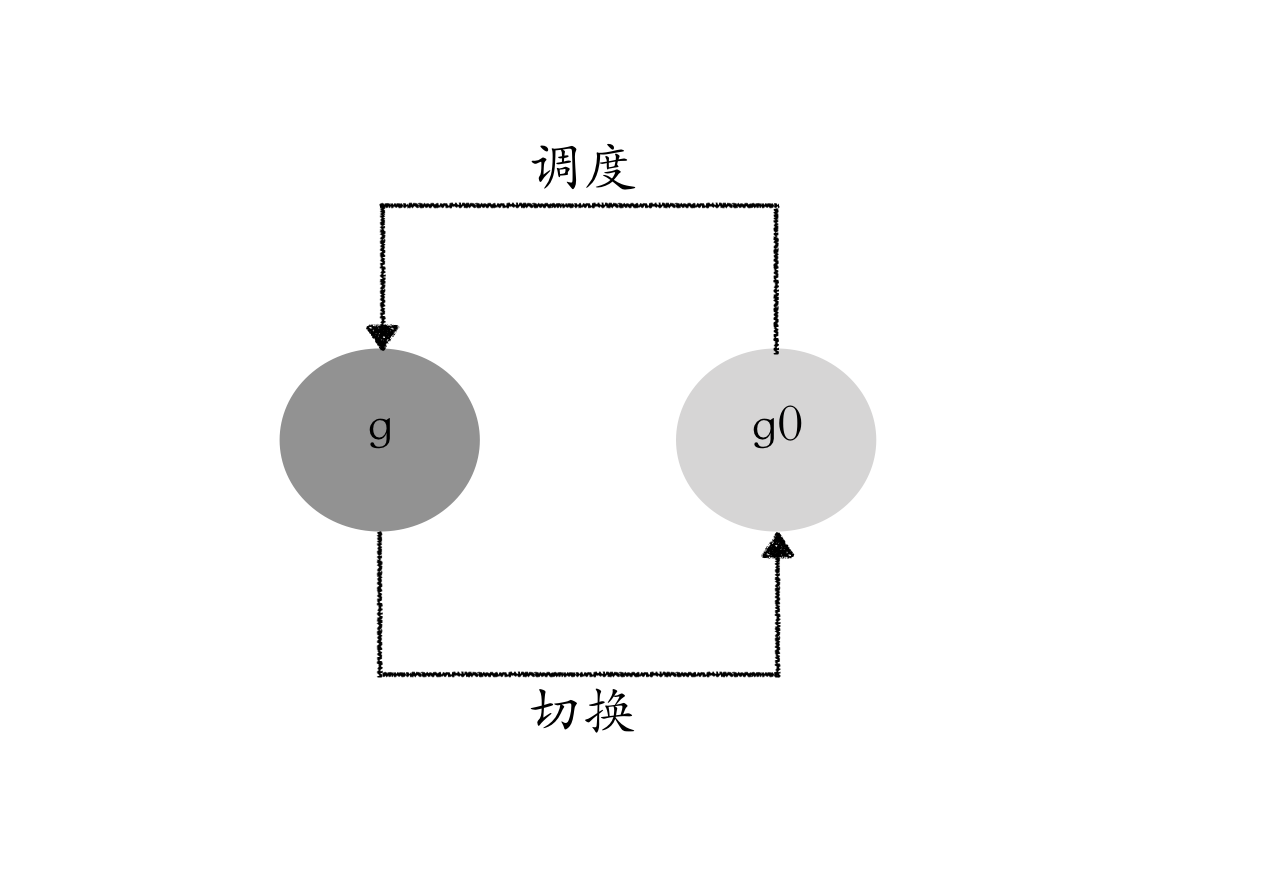
Many functions in the runtime code are called through the systemstack() function when they are executed. The role of the systemstack() function is to switch to the g0 stack, then execute the corresponding function and finally switch back to the original stack and return. In principle, as long as a function has nosplit this system annotation will need to be executed on the g0 stack, because the addition of nosplit compiler in the compilation will not be inserted in front of the function to check the stack overflow code, these functions in the execution of the stack overflow may cause, and g0 stack is relatively large, in the compilation if each function in the runtime to do stack overflow check will affect efficiency That’s why we cut to the g0 stack.
Summary
This article mainly analyzes the Golang GPM model. In the process of reading the runtime code, we found that there are many details in the code that need a lot of time to analyze, and only some simple explanations of the general framework are given in the article, and some details are brought in by the way. In the later articles, many details will be analyzed again.