Descheduler component introduction
When an instance is created, the scheduler can select the best node for scheduling based on the cluster state at that time, but the resource usage within the cluster is dynamically changing, and the cluster will become unbalanced over time, requiring the Descheduler to migrate the pods already running on the node to other nodes to achieve a more balanced distribution of resources within the cluster. There are several reasons why we want to migrate the instances running on a node to other nodes.
- Changes in pod utilization on the node that result in under- or over-utilization of some nodes.
- changes in node labels resulting in pod affinity and anti-affinity policies not being met.
- new nodes coming online and faulty nodes going offline.
The descheduler selects the instances that need to be migrated based on the relevant policies and then deletes the instances, and the new instances are rescheduled to the appropriate nodes via kube-scheduler. descheduler’s policies for migrating instances need to be used in conjunction with kube-scheduler’s policies, and the two are complementary.
The main purpose of using descheduler is to improve the stability of the cluster and to increase the resource utilization of the cluster.
Descheduler Policies Introduction
To address the above issues, descheduler provides a series of policies that allow users to rebalance the cluster state according to some rules and configurations to achieve a desired effect. The core principle is to find the pods that can be migrated and evict them according to the policy configuration, it does not schedule the evicted pods itself, but relies on the default scheduler to do so. There are currently ten supported policies.
| policy | Description |
|---|---|
| RemoveDuplicates | Migrate Pods of the same type on a node to ensure that only one Pod is associated with a ReplicaSet, Replication Controller, StatefulSet, or Job running on the same node. |
| LowNodeUtilization | Migrate Pods on nodes with higher requests ratios. |
| HighNodeUtilization | Migrate Pods on nodes with low requests ratios. |
| RemovePodsViolatingInterPodAntiAffinity | Migration of Pods that do not satisfy anti-affinity. |
| RemovePodsViolatingNodeAffinity | Migration of Pods that do not satisfy the node node affinity policy. |
| RemovePodsViolatingNodeTaints | Migration of Pods that do not meet the node taint policy. |
| RemovePodsViolatingTopologySpreadConstraint | Migration of Pods that do not satisfy the topological distribution constraints. |
| RemovePodsHavingTooManyRestarts | Migrate Pods that have been restarted too many times. |
| PodLifeTime | Migrate Pods that have been running for a long time. |
| RemoveFailedPods | Migrate Pods that have failed to run. |
Example migration policy for a high-utilization node.

Other policy examples.
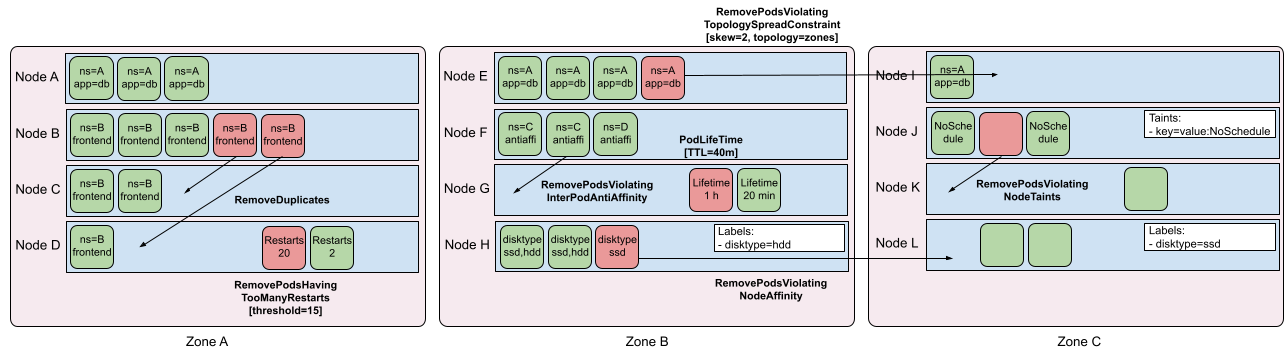
This is an introduction to the Community Descheduler component.
Descheduler feature extensions
After understanding the descheduler’s policies, you will find that the community descheduler’s functionality is far from meeting the needs of the company’s internal production environment, first of all, several policies starting with Remove are actually not needed in most scenarios. LowNodeUtilization and HighNodeUtilization policies can be extended according to the actual scenario, but these two policies are based on the allocation rate request ratio of nodes to make decisions, and Pod migration based on the allocation rate only has a general effect and cannot meet the requirements of production environments. In most production environments, we need to use the real node utilization rate to perform Pod migration.
LowNodeUtilization Policy Extensions
In addition to changing the community request allocation rate metric to be based on the real cpu usage of the nodes, some additional features have been added after analyzing the data of the production environment. The strategy has evolved several times in the process of actual use, from the initial use of the community’s periodic inspection mechanism to trigger, but the strategy has a certain lag, the real scenario if the node utilization is too high to deal with as soon as possible, in order to improve the timeliness of the node high utilization scenario, the strategy is extended to directly connect to the internal monitoring system, through the alarm callback to trigger the migration of Pods on the node. Finally, for some scenarios where Pod migration cannot be performed during peak periods, a node utilization prediction algorithm is also designed to predict the high utilization nodes to perform Pod migration operations in advance before peak periods.
1. Triggered by alarm callback
The policy is straightforward, and the migration of Pods on nodes is triggered directly after high utilization nodes are found through monitoring, and the policy adjustment is more flexible through alarm configuration, which takes effect directly after configuration without upgrading descheduler components. If there are more high-utilization nodes, the alarm policy can be configured under the standard threshold in an aggressive way. In a production environment, the policy, whether aggressive or conservative, may not achieve the best results, and eventually the policy needs to be adjusted to a robust state.
2. Node utilization prediction
In the production environment, there is a time window for business change, and the operation of Pod migration of some high quality services needs to be consistent with the time window for business change. To avoid affecting the stability of the business due to Pod migration, for this scenario where Pod migration cannot be carried out during the peak period, it is necessary to predict the high-utilization nodes and process them before the peak period comes, and the implementation of the current prediction algorithm mainly refers to the recommended algorithm of the community VPA component, which is a prediction algorithm based on time series. The core of the algorithm is to obtain the utilization data of all instances on the node for the last 8 days, then calculate the daily P95 data by day, and finally weight the daily P95 data with different weighting factors to obtain the final prediction results.
Prediction data need to do a lot of analysis and validation to discover the factors that have an impact on the accuracy. In the process of actual validation, we found that there are two main points that affect the prediction results.
- (1) The existence of timed tasks for business instances.
- (2) Some business instances have OpenTracing turned on.
- (3) Uneven traffic across different instances of the service.
- (4) Hardware impact: different CPU models of the hosts where different instances are located, CPU main frequency, multi-level cache capacity, instruction set, number of bits, etc., can affect the performance of the CPU and thus the performance of the instances.
- (5) Software impact: kernel parameter configuration, etc.
Second, the change of the number of instances on the node, if after predicting the node utilization result, there are new and destroyed operations of instances on the node will also affect the accuracy of the prediction. The current node utilization prediction function is also under continuous optimization, so the details will not be explained in detail here.
HighNodeUtilization Policy Extension
In the actual scenario, there are many instances running for a long time on some nodes with high request allocation rate but low actual utilization rate, and the business will not be changed for a long time, so the instances will not be rescheduled automatically by destroying and rebuilding.
The extension of the HighNodeUtilization policy is simpler than the LowNodeUtilization policy, mainly by replacing the request rate with the actual utilization rate, and then there are some constraints and effect analysis mechanisms that both policies need to use.
Constraint policies in Descheduler Pod migration scenarios
Due to the complexity of the scenarios in production environments, Pod migration is also a damaging operation for the business, and it is important to take the necessary precautions during the migration process and configure some constraint policies to guarantee the stability of the business.
Although k8s can be configured with PDB (PodDisruptionBudget) to avoid simultaneous eviction of copies of objects, we believe that PDB is not fine-grained enough and cannot be better used in cross-cluster scenarios, and a global constraint limit module will be used here to make the Pod of the service have as little impact on the service and balance the load as possible during the redispatch process The problematic nodes will ensure that the service is not interrupted or the service SLA is not degraded.
Currently, there are various policies to constrain the Pod migration process. In terms of macro policies, the constraints are mainly for global policies, and there are restrictions on the rate of Pod migration and the total number of Pods migrated in a cycle in different clusters and resource pools, as well as restrictions on the Pod migration time window and whether to migrate across clusters, and black and white lists are configured for each cluster and resource pool. In the micro policy, mainly for the node and service constraints policy, node and service Pod migration rate and the total number of migrated Pods in a cycle are also limited, and the selection of Pods under the service during migration will also do some restrictions for Pod status and service level.
Effect analysis of Descheduler Pod migration
After the secondary scheduler has been perfected, it needs an effect evaluation mechanism. If the secondary scheduler service has migrated many Pods after running for a period of time, but the number of highly utilized nodes has not been reduced due to other factors, how should we analyze it?
After analyzing the online data, we finally used three indicators to evaluate the effect of secondary scheduling. The first one is the discovery rate of high-utilization nodes, which refers to the ratio of the number of high-utilization nodes discovered by secondary scheduling to the number of high-utilization nodes collected by the company’s standard, which in theory should be close to the result of both. In practice, the algorithm used in the alarm policy was found to be inconsistent with the algorithm used in the company’s statistical standard during the implementation. The detection rate is low due to the low sensitivity of the configured alarms and the limitation of the Pod migration window.
The second one is the Pod eviction rate of high-utilization nodes. The eviction rate refers to the ability to select and evict the appropriate Pods on the node after the discovery of a high-utilization node. Some high-utilization nodes cannot evict Pods on the nodes because of service-related constraints, unreasonable instance selection algorithms, or global policy constraints.
The third one is the efficiency of Pod eviction from high-utilization nodes. If the utilization of the Pod node above the evicted high-utilization node is not reduced to a certain threshold, it is also not as expected. There are three main reasons for the low eviction efficiency, the first one is that various constraints lead to the eviction of Pods that are not optimal, and the node utilization does not decrease significantly. The second is that after a Pod is evicted, a new Pod will be scheduled on the node soon. The third is that the utilization rate of some Pods on the node becomes higher.
Finally, the analysis of the number of high-utilization nodes in the whole cluster, for the data of high-utilization nodes in the whole cluster, will also be split by resource pool and cluster dimension to establish the above three index data. Theoretically, if the three indicators of high utilization node discovery rate, eviction rate and efficiency are in line with the expectation, the proportion of high utilization nodes in the whole cluster will be controlled within a certain range.
The above is a process of secondary scheduling effect analysis.
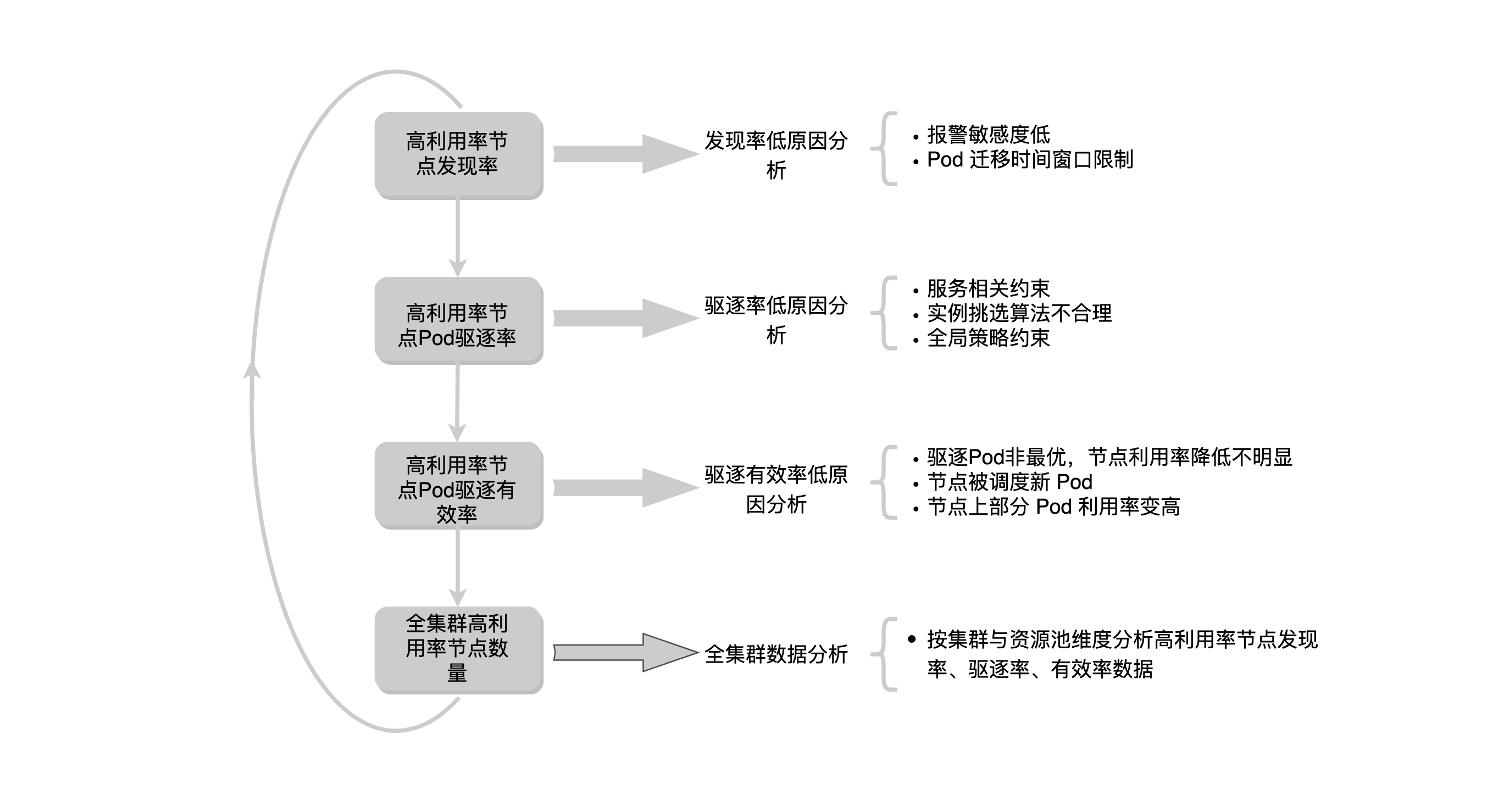
The current analysis is mainly conducted by some data from the secondary scheduling component itself. The cluster-wide high-utilization nodes are also related to business traffic, cluster capacity, scheduler policies, and other factors. The overall resource utilization of the cluster increases when some services have operational activities, and the scheduler schedules instances up for nodes with low scores when the cluster resources are tight, all of which have an impact on the number of high-utilization nodes.
Summary
This article introduces the basic functionality of the current community descheduler component as well as some of the flaws and extension strategies of the descheduler in production environments. There are also some safeguards for business stability when using descheduler to migrate Pods. The basic function of descheduler is to migrate Pods based on some policies, and there are many scenarios in the production environment where Pods on nodes need to be migrated. For example, kernel upgrade operations that require node restart, or machine relocation operations in different server rooms. There are also scenarios where k8s components are upgraded (runtime switching, etc.) that can be supported by adding policies to descheduler. In the future, we will continue to add other policies to the descheduler in the context of production environments. For example, Pod migration based on node interference rate scenario, Pod migration based on anti-affinity policy for service signature.