The concept of concurrency has been around for a long time, and the main idea is to allow multiple tasks to be executed in the same time period in order to get faster results. The first language that supported concurrent programming was assembly language, but there was no theoretical basis for this type of programming, and a small programming error could make the program very unstable and testing of the program almost impossible. With the development of computer hardware and software technology, writing concurrent programs has become less complicated than before. As the underlying foundation of concurrent programming, this article will briefly analyze the design principles of processes and threads in an easy-to-understand manner.
Overview
Although the implementation of unix and its variants is slightly different from each other, there are many conceptual similarities between the standardized specifications of organizations such as `ISO and IEEE’. This article will focus on the Linux implementation as the main target. Before that, a few concepts need to be introduced.

Serial vs. concurrent programs
A serial program refers to a list of instructions that can only be executed by sequential instructions, while a concurrent program is a composite of multiple serial programs that can be executed concurrently. The order of all code in a serial program is fixed, while only some of the code in a concurrent program is ordered, and the order of execution of some of the code is not explicitly specified, a property known as indeterminacy, which causes concurrent programs to follow a different path of code execution each time, even when the same data is input.
Concurrent programs allow serial programs to run on one or more shareable CPUs, while also allowing each serial program to run on a CPU dedicated to it. The former approach, also known as multiprogramming, is supported by the operating system kernel and provides a way for multiple serial programs to multiplex multiple CPUs. In multiprocessing, multiple CPUs of a computer share a single memory (RAM) and several serial programs may be running on different CPUs at the same time. Multiprogramming and multiprocessing are the basis for the concurrent and parallel operation of serial programs.
Concurrent vs. parallel programs
In some references and books, the concepts of concurrency and parallelism are often confused. In fact there is a clear difference between the two. Parallelism refers to physical (computer parallel hardware such as multi-core CPUs) simultaneous execution, while concurrency refers to programming that enables multiple tasks to be logically intertwined for execution. Concurrent programs are a broader concept, representing all programs that can be implemented and distributed as such, which include parallel programs.
Process design
Processes are fundamental to Unix and its derivative operating systems, and are the smallest unit of resource allocation in which all code is executed. A program is an executable file stored on disk, in some directory, which is a static entity and has no meaning of execution. A process is derived from the execution of a program, i.e., a process is an instance of a program, a dynamic entity with its own life cycle.
Process Descriptors and Process Identifiers
To manage processes, the kernel provides a detailed description of each process’s attributes and behavior, including its priority, status, virtual address, access rights, etc. This information is recorded in each process descriptor (TASK_STRUCK). The process descriptor is a very complex data structure that also holds the unique identifier of the process in the operating system: the process ID (PID), which is a non-negative integer and is numbered sequentially, and the newly created PID is the result of incrementing the previous PID. When the PID reaches its maximum value (default 32768 on Linux), the kernel starts from scratch to find idle process IDs and uses the first one found. The process descriptor also contains the parent process ID (PPID) of the current process, from which the process can be queried for derived processes.
To view the current process PID and PPID using system calls.
Note that the PID is a number that uniquely identifies the process and does not convey any information about the process. However, the system kernel can efficiently convert the PID into a descriptor for the corresponding process. We can use the shell command kill to terminate a process or find the corresponding process by its PID and send it a message.
Derivation of processes
A process is able to create several new processes using fork (a system call function), the former being called the parent process and the latter becoming the child process. Each child process is a copy of the parent process, has a copy of the parent’s data segments, heap and stack, and shares code segments with the parent process. Each child process is independent, and changes made by the child process to the copy belonging to it are invisible to both the parent and the sibling process. To increase the efficiency of process creation, the Linux kernel uses techniques such as Copy on Write (COW) to “share” data. The system call exec can also be used to switch the executable in the child process to replace the code and data segments copied from the parent process.
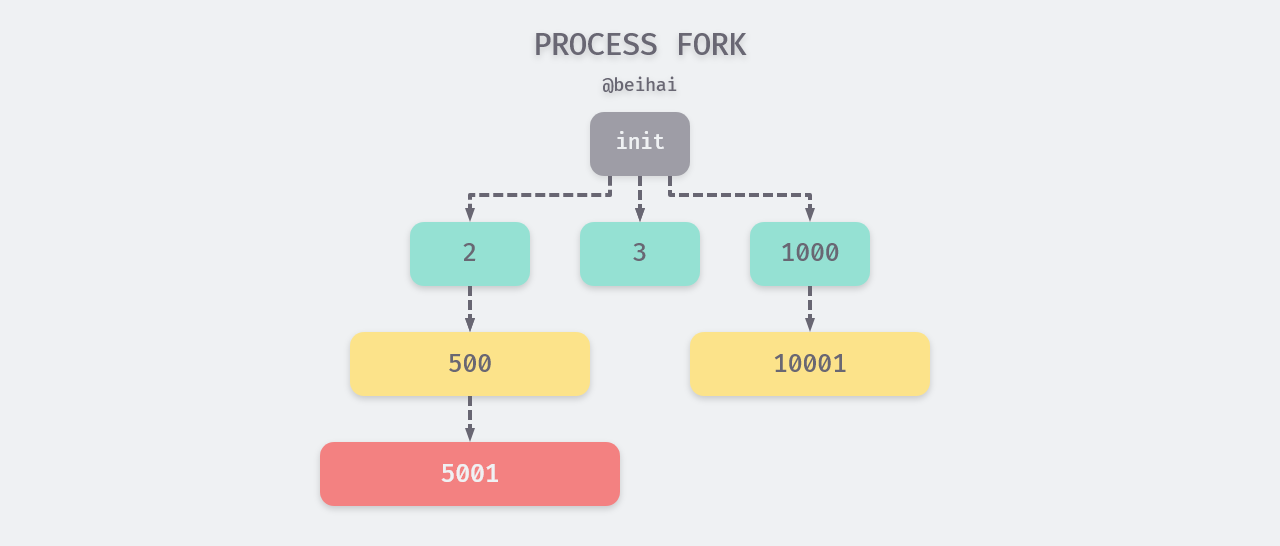
Every process on a Linux system has a parent process, and all processes form a tree structure. When the system starts, one init process (ID 1) is created, and all other processes are created by the init process through fork. init is parented by itself. If a process ends before its children, then its children will be “adopted” by the init process and become direct children of the init process.
States of processes
In Linux, processes are stateful at every moment, and their possible states are usually the following seven: executable, interruptible sleep, non-interruptible sleep, suspended or tracking, zombie, and exiting. The process state can be viewed with the shell command ps aux.
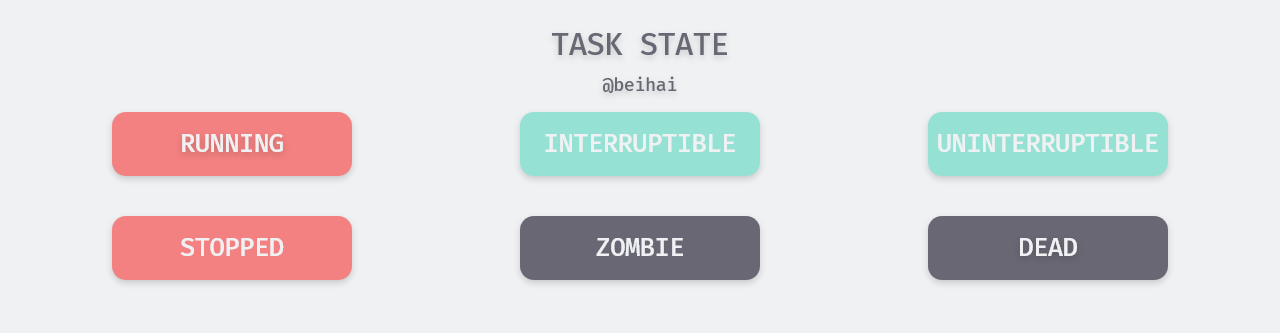
- Executable state (TASK_RUNNING), or R for short. A process in this state indicates that it is to run immediately or is running on a CPU. The task of the process scheduler is to select a process from each CPU’s executable queue to run on that CPU separately.
- Interruptible sleep state (TASK_INTERRUPTIBLE), or S for short. Processes in this state are hung because they are waiting for an event to occur (e.g., waiting for a socket connection, semaphore). These processes are put into the waiting queue for the corresponding event. When the event occurs, one or more processes in the corresponding wait queue will be woken up.
- The uninterruptible sleep state (TASK_UNINTERRUPTIBLE), or D for short. Similar to the S state, the process is in a sleep state, but at this moment the process is non-interruptible. Uninterruptible does not mean that the CPU does not respond to external hardware interrupts, but that the process does not respond to asynchronous signals, such as the inability to kill a process in state D with a kill. Processes in the D state are usually waiting for IO, such as disk IO, network IO.
- Suspended state or trace state (TASK_STOPPED or TASK_TRACED), or T for short. Send a
SIGSTOPsignal to a process, and it will enter theTASK_STOPPEDstate in response to that signal, unless the process itself is in state D and does not respond to the signal. Sending aSIGCONTsignal to a process in theTASK_STOPPEDstate allows it to recover from the T state to the R state. A process in theTASK_TRACEDstate will pause and wait for its tracer process to operate on it. For example, if you use the GDB debugging tool to set a breakpoint, the process will stop at that breakpoint. At this point, the process is in the tracing state. Sending theSIGSTOPsignal to a process in the traced state does not allow it to resume, but only after the debugging process (traced process) makes the corresponding system call or exits. - The zombie state (TASK_DEAD - EXIT_ZOMBIE), or Z for short. A process in this state will have most of the resources occupied by the process reclaimed during exit, except for a few pieces of information such as process descriptors and exit codes. This information is kept in consideration of the fact that the process’s parent process may need it. At this point the process is left with an empty TASK_STRUCK shell, hence the term zombie process.
- Exit state (TASK_DEAD - EXIT_DEAD), or X for short. A process in this state will have all its resources reclaimed by the operating system and be cleanly terminated.
A process may produce a series of state transitions during its life cycle, a schematic sketch of which is as follows.
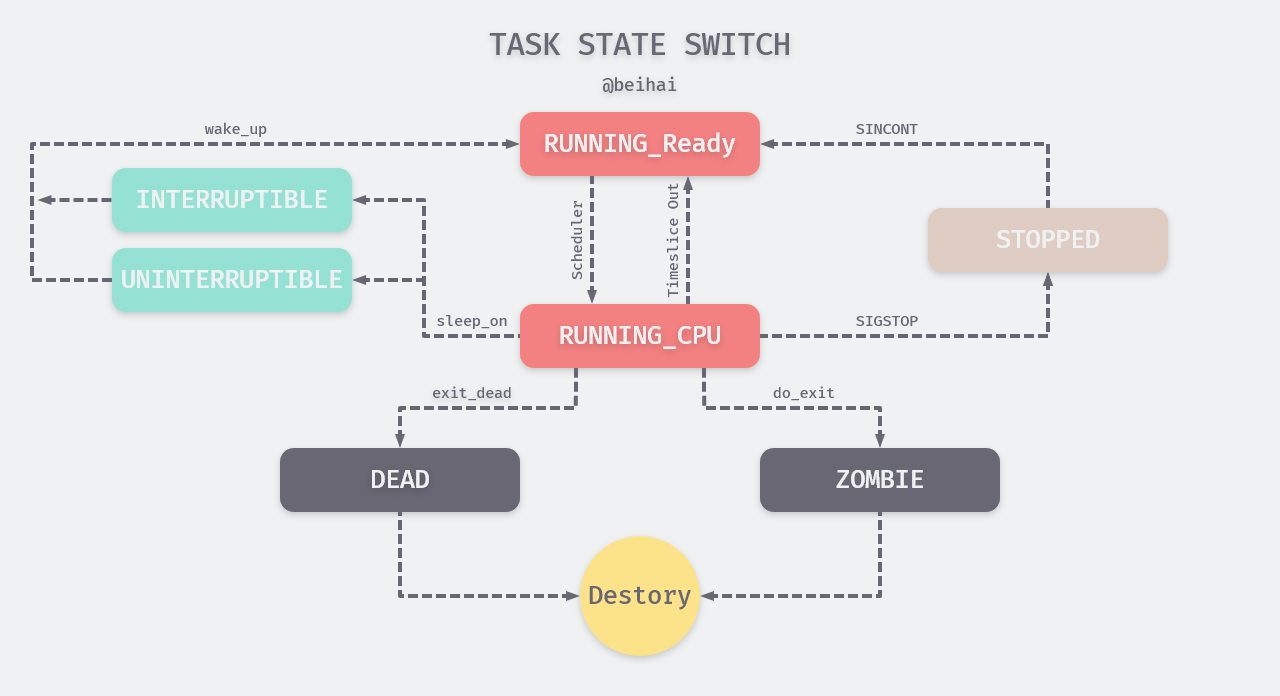
Note: The actual situation of process state transition is very complicated, for the sake of understanding, the above diagram only draws the outline process.
Address space and memory layout
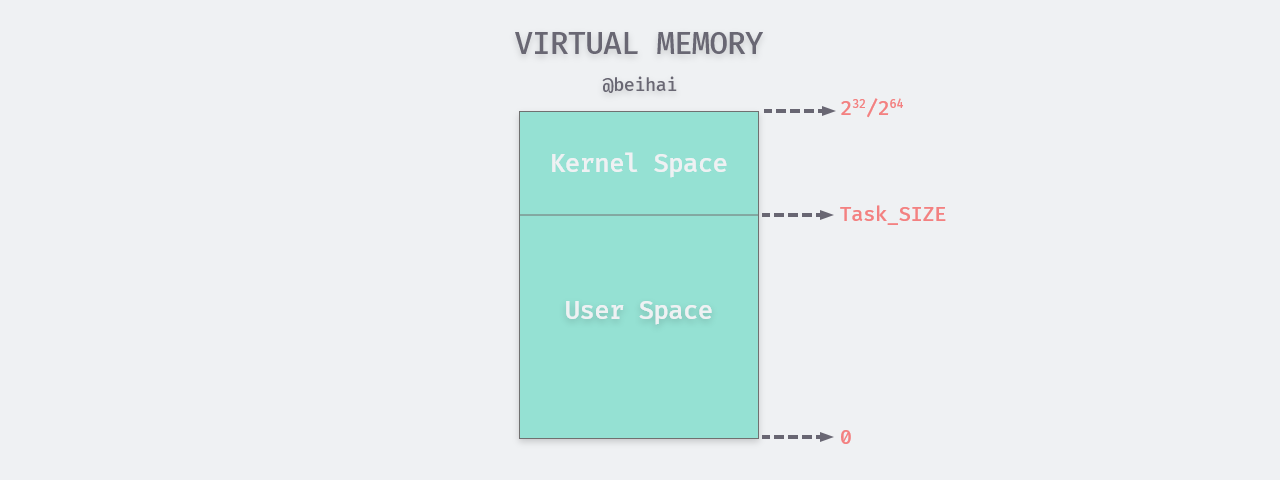
Each process in a multitasking operating system runs in its own memory sandbox. This sandbox is the virtual address space. The area of memory identified by the virtual address is the virtual memory space, which is often referred to as virtual memory. When we create a process, the operating system allocates memory space for the process, and each cell address within that memory area is identified and located by a pointer, i.e., memory addressing. A pointer is a positive integer represented by a number of binary bits whose length is determined by the CPU word length, 232 on a 32-bit computer and 264 on a 64-bit computer.
The kernel allocates virtual memory for the process instead of physical memory. The kernel divides the virtual memory into user space and kernel space, with the user space occupying the lower part of the address, from 0 to TASK_SIZE (TASK_SIZE is a constant, and its value depends on the specific hardware platform) and the rest of the kernel space. The division is shown in the figure.
The kernel space is dedicated to the kernel, while the virtual memory of user processes is allocated to the user space, which is usually independent of each other and not visible to each other. The virtual memory of a process is divided by the kernel into a number of pages, while the division of physical memory is the responsibility of the CPU, and a physical memory unit is called a page frame. The different pages of the process are mapped to the corresponding physical memory. This is shown in the following figure.
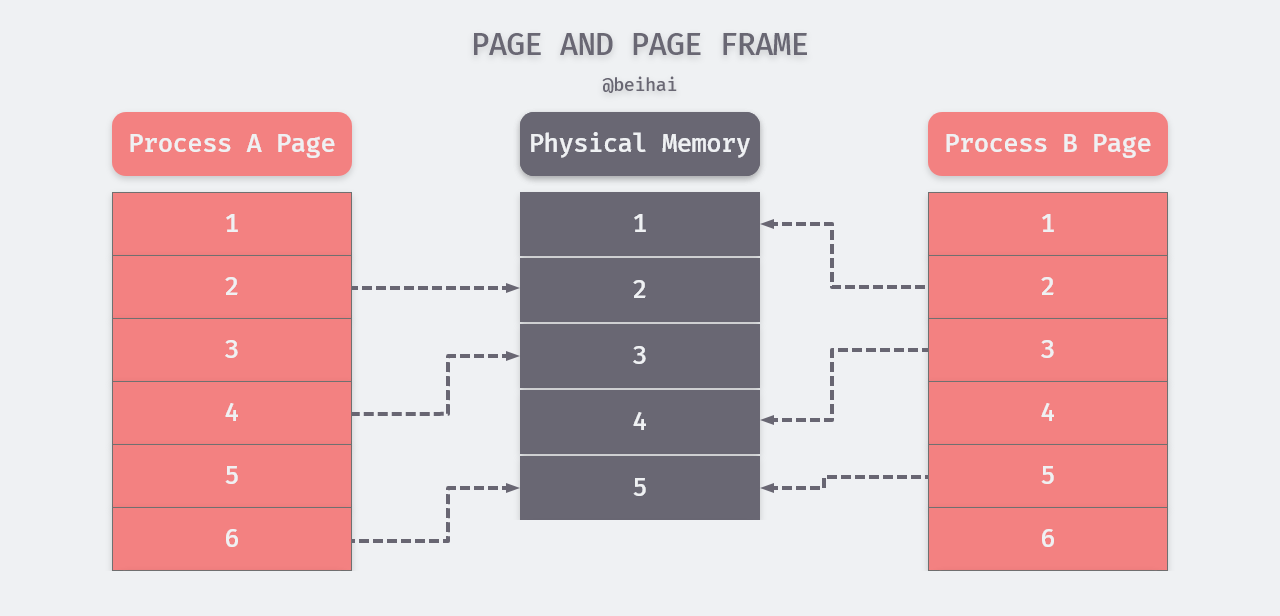
In the above figure, page frame 5 is shared by processes A and B, forming a shared memory area, which is how the shared memory approach is implemented in IPC. The page that is not mapped to physical memory in the diagram means that the page has no data or is not used, or perhaps the page is swapped out of the swap partition on disk.
System calls
User processes cannot directly manipulate the computer’s hardware while living in user space, but the system kernel can. Therefore, the kernel exposes some interfaces for user processes to call, which is the only way for them to use kernel functions and manipulate the hardware. The use of kernel interfaces by user processes is called a system call (verb), but often the term “system call” (noun) also refers to the set of interfaces provided by the kernel. When a system call occurs, the user process first issues an explicit request to the kernel space, which leads to the access of data and the execution of instructions in the kernel space.
To ensure the security and stability of the operating system, the kernel establishes two states based on the privilege levels provided by the CPU that allow processes to reside in them: kernel state and user state. The CPU spends most of its time in the user state, when the user process has no access to the kernel. When the user process issues a system call, the kernel switches the CPU from the user state to the kernel state and then executes the corresponding kernel function, which then switches the CPU back to the user state and returns the execution result.
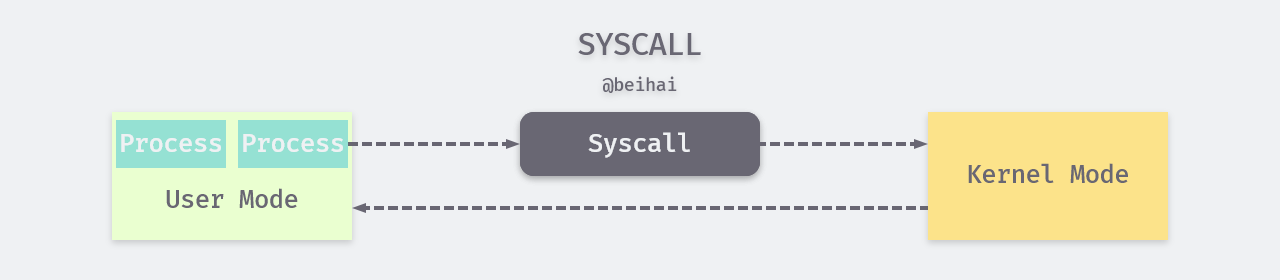
The original purpose of this design is to give different “permissions “ to different operations to ensure the security of the system.
Context Switching
A time-sharing operating system can use the power of the CPU to quickly switch between multiple processes, called context switching, to create the illusion that multiple processes are running simultaneously. But regardless of the speed of the switch, there is only one process running on a CPU core at the same time, and each process thinks it has the CPU all to itself.
Context switching comes at a cost. If process A, which is running on the CPU, is replaced, the kernel needs to save A’s running state and restore B’s last running state if it is not running for the first time. In addition, the kernel is responsible for scheduling the process, which process to run at the time of the switch, when to switch, and when to switch back to the replaced process.
Design of threads
Programming using multiple processes has some disadvantages, such as the process creation and switching overhead is relatively large, and a process cannot execute multiple tasks at the same time. Therefore, more flexible threads are introduced inside processes. A thread can be considered as a control flow within a process and is the smallest unit of program execution. The process of thread derivation is similar to process, created by other threads calling the system call function pthread_create. However, unlike the tree-like structure of a process, threads are related to each other in a hierarchical manner and do not have affiliation relationships.
All threads within a process share the same address space, file descriptors, stack, and process-related attributes. Therefore, when a new thread is created, it does not copy the data, code, etc. stored in the process it belongs to, so it is much lighter and has much less overhead. In addition, each thread also has its own thread stack, which stores some private data.
Threads also have a unique identification ID, called TID, which is normally only unique within the process it belongs to, but in Linux the TID is unique system-wide.
Control and state
Threads can have some control over other threads in the same process, there are four main cases as follows.
- create: the thread creates a new thread by calling the system call function
pthread_create, the calling thread needs to pass in the execution function with parameters to the new thread, and obtains the TID of the new thread upon successful creation. - terminate: the thread calls the system call function
pthread_cancelto send a request to terminate the execution of the target thread (which can also be itself), but the target thread is not terminated immediately; in general, the thread execution is terminated when it reaches a certain cancellation point. - join: the thread calls
pthread_jointo join the target function, the calling function will get the return value of the target function with process control and continue execution. - detach: the thread calls
pthread_detachto detach itself or other threads. The detached threads are automatically cleaned up and destroyed by the kernel when they terminate.
Threads also undergo a series of state transitions during their life cycle, the process of which is similar to that of the process and will not be described here too much.
Thread scheduling
The scheduling of threads is an important part of the system kernel. The scheduler divides the time into very small time slices for different threads, so that each thread has a chance to run on the CPU. Since threads are either CPU-consuming or I/O-consuming, some threads spend a certain amount of time using the CPU for computation, while others spend time waiting for I/O operations, such as waiting for keyboard input. The scheduler prioritizes threads, where static priority determines the maximum time a thread can run on the CPU at a time, and dynamic priority determines the order in which threads are executed. Typically the scheduler assigns higher priorities to I/O-consuming threads so that I/O operations that take more time can be executed sooner.
The static priority of a thread is a constant that is set to 0 by default if the application does not specify its value. dynamic priority is derived from static priority and can be adjusted by the scheduler in real time. All threads waiting for the CPU are placed in the CPU’s corresponding run queue in descending order of dynamic priority, so that the next running thread is always the one with the highest dynamic priority. The priority array is an array of linked lists, where a linked list contains only threads with the same priority, and newly added threads are placed at the end of the corresponding linked list. In fact, each CPU’s run queue contains two priority arrays, one for threads that are waiting to run and the other for threads that have run but have not yet finished.
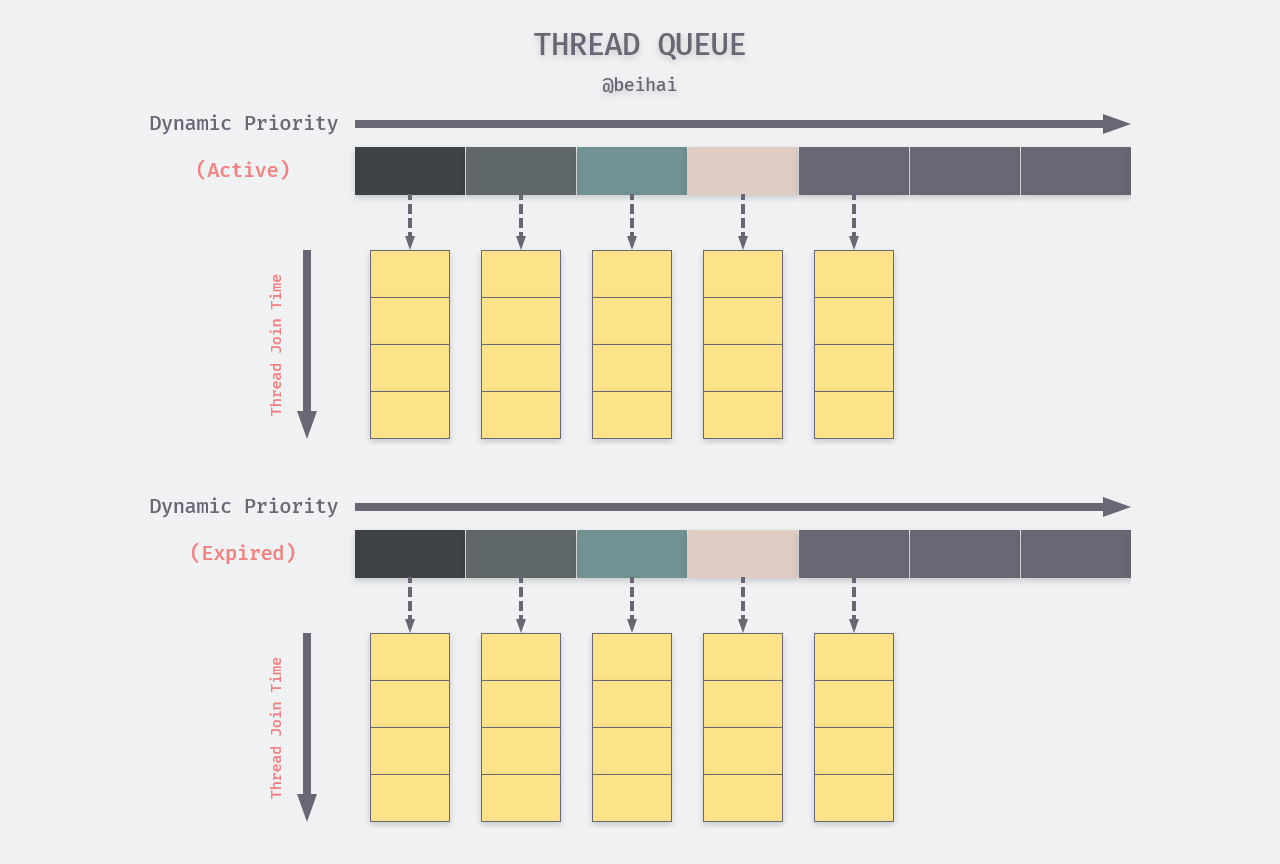
The names of the two arrays are not strictly defined, and are tentatively named active and expired in this article.
If a thread reaches the time slice, the scheduler takes the next thread to run from the active priority array and swaps the CPU and schedules the swapped threads into the expired priority array. When all threads in the active priority array have been run, the scheduler swaps the identities of the two priority arrays so that the threads queued into the expired priority array can run again.
In addition to the ready and running states described above, threads may also go to sleep due to waiting events. A thread in the sleep state is added to the corresponding wait queue, and when an event occurs, the kernel wakes up all threads in the corresponding wait queue and moves them to the run queue. The scheduler also adjusts the dynamic priority of the woken threads so that they can run earlier.
The scheduler also takes care of the load between multiple CPUs. Usually a thread will run on a fixed CPU, but it happens from time to time that some CPU cores are too busy and some are left idle. The scheduler will migrate threads on CPUs with higher loads, and this process may depend on the specific implementation.
Implementation models for threads
There are three main implementation models in thread evolution: the user-level thread model, the kernel-level thread model and the two-level thread model. The main difference between the three is the correspondence between threads and the kernel scheduling entity KSE.

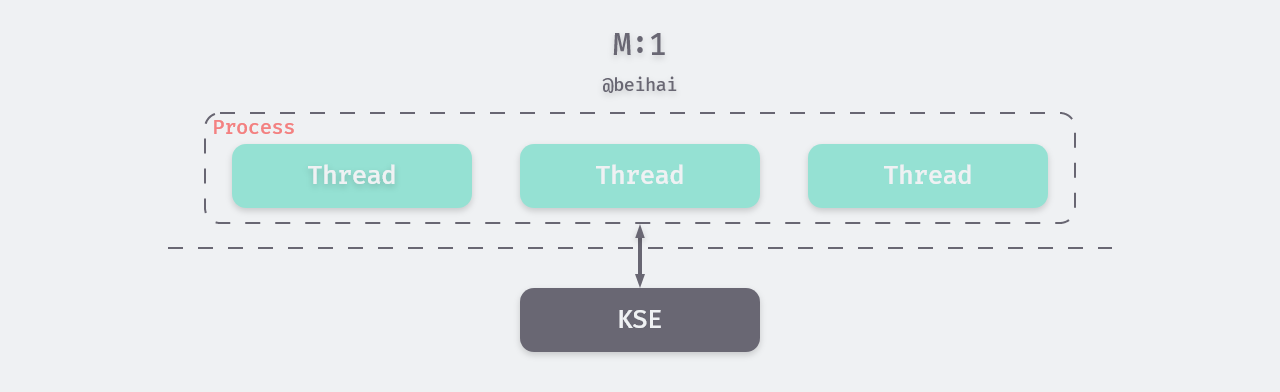
User-level thread model (M:1) : Applications use a thread library to design multi-threaded programs. A thread library is a package for user-level thread management that contains code for creating and destroying threads, passing information and data between threads, scheduling thread execution, and saving and restoring thread contexts. The thread library is stored in the user space of the process, and the existence of these threads is unaware to the kernel; the management of the threads in question is done autonomously by the program. Since the rules for thread switching within a process are much simpler than those for process scheduling and switching, and no user/core state switching is required, switching is faster and software portability is somewhat stronger.
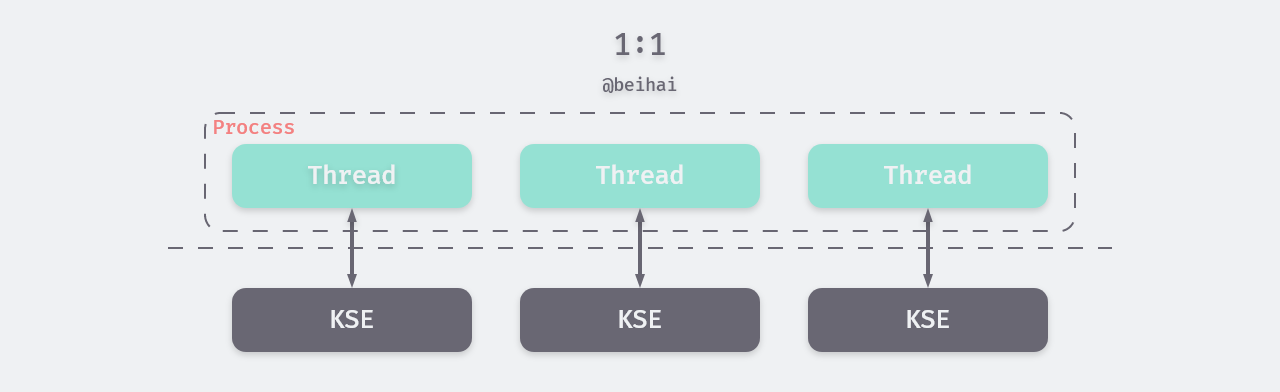
Kernel-level thread model (1:1): Threads under this model are managed by the kernel, and each thread corresponds to a KSE, so that the kernel can schedule each thread separately. The kernel can schedule multiple threads in a process to multiple processors at the same time, thus enabling truly concurrent thread operation. Even if a thread is blocked, the kernel can schedule another thread in the same process to continue execution.
Kernel threads are much more expensive to manage than user threads, and the process of creating, switching, and synchronizing threads consumes more resources. If a process contains a large number of threads, it also places a large burden on the kernel’s scheduler. In general, the operating system has a direct or indirect limit on the number of threads that can be created in a process. The kernel-level thread model is commonly used for thread implementations in operating systems.
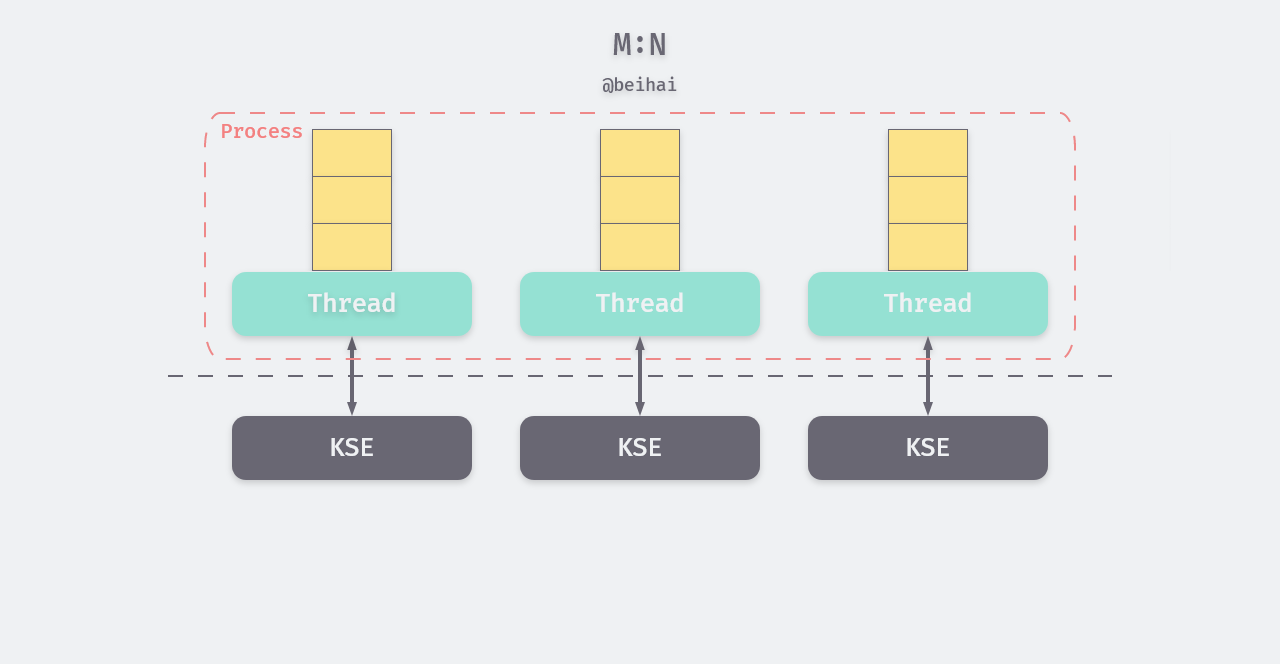
Two-level thread model (M:N): The two-level thread model is a many-to-many thread implementation that attempts to combine the advantages of M:1 and 1:1 and avoid their disadvantages. A process under this model can be associated with multiple KSEs and create multiple kernel threads, each of which manages the scheduling of the other threads within the process. This makes it possible to switch threads directly in user mode in most environments, reducing the consumption of kernel resources.
The two-level thread model is complex to implement and is not generally adopted by developers of operating system kernels, but it will be fully useful in some programming languages.
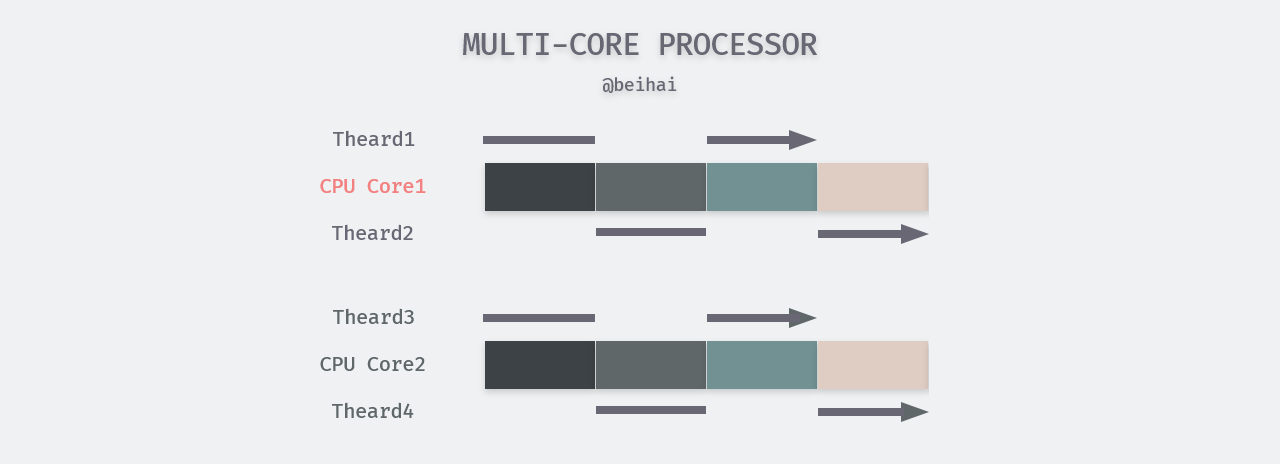
Multicore Concurrency
When running a multi-threaded program on a single-core processor, the power of fast CPU switching can create the illusion that multiple tasks are executing simultaneously. However, only one thread is executing at the same moment. On a multi-core processor, the maximum number of tasks that can be executed in parallel at the same moment is the number of processor cores. The former is called concurrency and the latter is called parallelism. Parallel running can be seen as a specific division of concurrent running, as in the figure below, threads 1-4 are running concurrently, while at the same moment, threads 1, 3 or 2 and 4 are executing in parallel.
Here’s an aside about the CPU’s hyper-threading technology. For a processor core, although it can process thousands of instructions per second, it can only process one instruction at a given time, but normally a single instruction does not use all the resources inside the CPU. Hyperthreading is a technology that can fully “mobilize” the temporarily idle processing resources inside the CPU. It can turn a physical processor into two logical processors at the software level, allowing the processor to process more instructions and data simultaneously and in parallel at a given moment, although the actual performance is not doubled. From a time point of view, a physical core with two logical processors to perform the number of tasks in parallel is also two.
Summary
This article introduces some basic concepts of processes and kernel scheduling of multiple threads. For a more detailed understanding of processes and threads you can read operating system related books. As the basic unit of system management, the concurrency model of many programming languages is also based on kernel threads. Understanding the basics of threads is also helpful for understanding the language.
Reference
http://wuchong.me/blog/2014/07/24/linux-process-manage/https://blog.csdn.net/wudebao5220150/article/details/12919453https://manybutfinite.com/post/anatomy-of-a-program-in-memory/https://linux.cn/article-7325-1.htmlhttps://blog.csdn.net/gatieme/article/details/51892437https://wingsxdu.com/posts/linux/concurrency-oriented-programming/process-and-thread/