BPF is a very flexible and efficient virtual machine-like component in the Linux kernel, capable of safely executing bytecode at many kernel hook points. This article briefly organizes the technical principles and application scenarios of eBPF.
eBPF Origins
BPF is called Berkeley Packet Filter, as the name suggests, BPF was originally used for packet filtering and was used in the tcpdump command, for example running a filter rule like tcpdump tcp and dst port 443 would copy packets with protocol tcp and destination port 443 to the user state.
The BPF program runs in the kernel to facilitate filtering out unnecessary traffic and retrieving only those packets that we need to monitor, thus reducing the overhead of copying unnecessary packets into user space and subsequently filtering them.
BPF is implemented based on a virtual machine in the kernel, by translating BPF rules into bytecode to run in the kernel.
The eBPF (extended BPF) evolved from the BPF and has a richer set of instructions than the previous BPF, which expanded from 2 32-bit registers to 11 64-bit registers and was known as the cBPF (classic BPF). After v3.15 of the linux kernel, the kernel started to support eBPF, so a special program is responsible for translating cBPF instructions into eBPF instructions for execution.
eBPF greatly extends its functionality beyond packet filtering, allowing us to run arbitrary eBPF code in the kernel, for example, by attaching programs to kprobe events that trigger the eBPF program to run when the corresponding kernel function is started. To borrow from Brendan Gregg’s description of eBPF technology.
eBPF does to Linux what JavaScript does to HTML.
Just as we can use JavaScript to develop event-triggered programs on web pages that run corresponding functions when events such as mouse clicks on buttons occur, these mini-programs run in a secure virtual machine in the browser. With eBPF, we can write mini-programs that run when events such as disk I/O, system calls, etc. occur, and these run in a secure virtual machine on the kernel. More precisely, eBPF is more like a v8 virtual machine running JavaScript, where we can compile high-level programming languages into bytecode and run them in the sandboxed environment of eBPF.
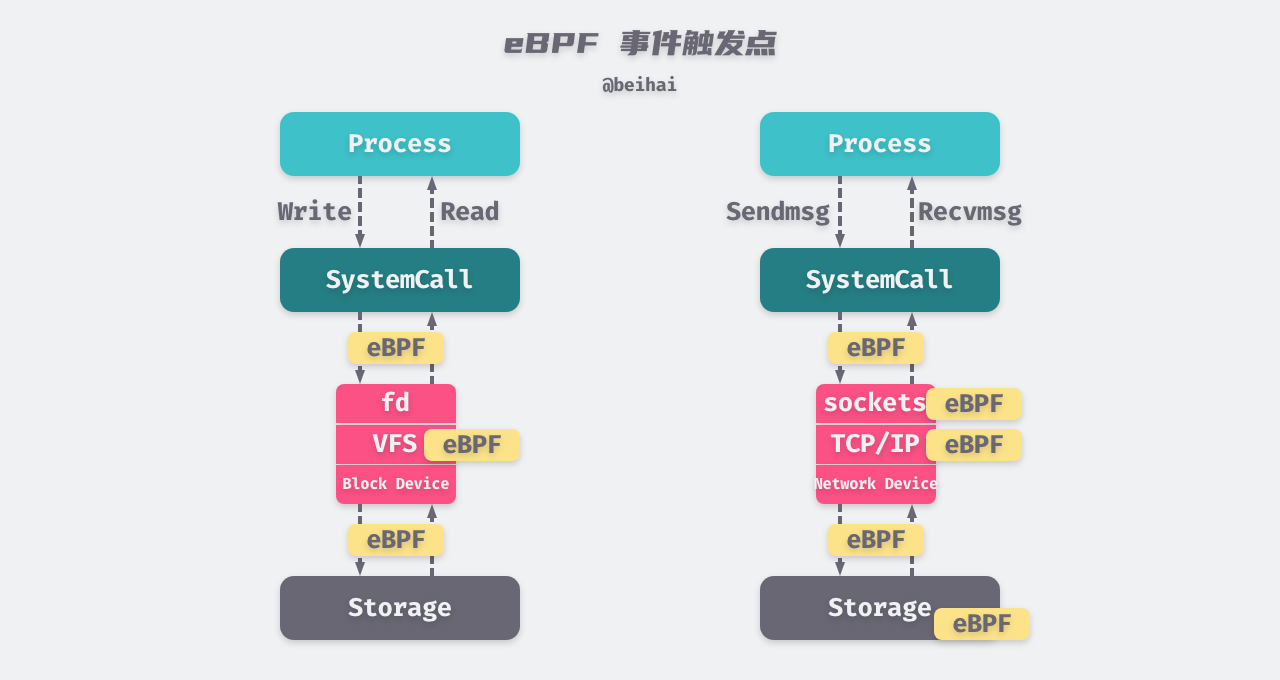
An event-triggered task is a task in a real-time operating system that starts running only under the condition that a specific event associated with it occurs.
Today eBPF is not only specific to networking, but can also be used in scenarios such as kernel tracking, security, etc. The versatility of eBPF has attracted a larger community to innovate and develop related eco-software.
Why use?
Since eBPF programs can be triggered by a series of events, eBPF-based applications can help us discover what is happening in the system. eBPF has an application scenario of program monitoring - identifying abnormal behavior of an application, for example when writing files to important system directories. eBPF code can run in response to a file event to check if the program’s behavior is legitimate.
Although there are some off-the-shelf tools that can perform similar tasks, such as the ps command that reports the current system process status. However, the monitoring accuracy of such monitoring programs lies in the program sampling frequency; programs that execute at shorter sampling intervals than the monitoring program will not be detected, and increasing the sampling frequency will again affect the system performance. And the eBPF program is event-triggered, not sampling-based, and it runs in the kernel at a very high speed, so eBPF-based detection tools are more accurate than traditional sampling-based methods.
In addition, there is no need to recompile the kernel to use eBPF programs. We can write programs in a subset of C, compile them into eBPF bytecode using a compiler backend, and then the kernel maps the eBPF instructions to the processor’s native instructions (opcode) using a JIT on-the-fly compiler located in the kernel for optimal execution performance in the kernel.
The drawback of eBPF-based security tools is that we can only detect new processes or file access events when they start, but we cannot prevent them from starting. These monitoring results can tell us when processes are running in an abnormal manner and can be used to trigger protective actions, such as shutting down processes or closing containers, via eBPF. However, if this unexpected behavior is malicious, damage may have been done.
The cilium document BPF and XDP Reference Guide summarizes some of the advantages of eBPF.
- Kernel programmability without kernel/user space switching. eBPF Map can be used when state needs to be shared between eBPF programs or between kernel/user space.
- The ability for eBPF programs to disable unneeded features at compile time, e.g., if the container does not require IPv4, then eBPF programs can be written to handle only the IPv6 case.
- eBPF provides a stable ABI to the user space and does not rely on any third-party kernel modules: eBPF is a core component of the Linux kernel, and Linux is already widely deployed, so it is guaranteed that existing eBPF programs will continue to run on new kernel versions. This guarantee is at the same level as the system calls and the eBPF programs are portable across platforms.
- in network scenarios, eBPF programs can be updated atomically without restarting the kernel, system services, or containers and without causing network outages, in addition to the fact that updating an eBPF Map does not result in a loss of program state
- BPF programs work with the kernel, reusing existing kernel infrastructure (e.g., drivers, netdevices, tunnels, protocol stacks, and sockets) and tools (e.g., iproute2), as well as the security guarantees provided by the kernel. Unlike the Linux Module, eBPF programs are verified by an in-kernel verifier to ensure that they do not cause the kernel to crash, that the program will always terminate, etc. Unlike the Linux Module, eBPF programs are verified by an in-kernel verifier. For example, XDP programs reuse existing kernel drivers and can directly manipulate data frames stored in the DMA buffers without exposing these data frames or even the entire driver to user space as in some models (e.g. DPDK). Moreover, XDP programs reuse the kernel stack instead of bypassing it. eBPF programs can be thought of as generic `glue code’ between kernel facilities, taking advantage of cleverly designed programs in the middle layer to solve specific problems.
eBPF Programming
The eBPF is designed as a general purpose RISC instruction set that maps directly to x86_64, arm64, so all eBPF registers can be mapped to CPU hardware registers one by one, and the generic operations are 64-bit so that arithmetic operations can be performed on pointers.
Although the instruction set contains forward and backward jumps, the eBPF checker in the kernel forbids loops in the program to ensure that the program will eventually stop. Since eBPF programs run in the kernel, the checker’s job is to ensure that these programs are safe to run and do not affect the stability of the system. This means that loops are possible from an instruction set point of view, but the checker imposes restrictions on them.
Some concepts and conventions in eBPF programming are described below.
Registers and calling conventions
The BPF consists of the following three parts.
- 11 64-bit registers that contain 32-bit subregisters.
- a Program Counter (PC);
- a 512-byte size eBPF stack space.
The registers are named from r0 to r10, and the eBPF calling convention is as follows.
r0holds the return value of the called helper function, and is also used to hold the exit value of the eBPF program.r1-r5holds the parameters passed when the eBPF calls the kernel helper function.r6-r9are stored by the called party and can be read by the caller after the function returns.r10is the only read-only register that holds the address of the stack frame pointer of the eBPF stack space.- The stack space is used to temporarily hold the values of
r1-r5. Due to the limited number of registers, if the values in these registers are to be reused between multiple auxiliary function calls, then the eBPF program needs to be responsible for temporarily dumping these values onto the eBPF stack or saving them to the registers held by the callee.
Note: The default mode of operation is 64-bit. 32-bit subregisters can only be accessed through a special ALU (Arithmetic Logic Unit), and writes to 32-bit subregisters are padded with zeros to 64 bits.
When a BPF program starts execution, the r1 register holds the program’s context, i.e. the program’s input parameters. eBPF can only work in a single context, which is defined by the program type, e.g. a network program can take the kernel representation of a network packet, skb, as an input parameter.
Before kernel version 5.2 eBPF programs were strictly limited to a maximum of 4096 instructions, which meant that every program was designed to end quickly, but as eBPF programs became more complex, this was relaxed to 1 million instructions starting with version 5.2. In addition, there is the concept of tail calls in eBPF, which allows one eBPF program to call another eBPF program. Tail calls are also limited, currently up to 32 levels of calls. This feature is now commonly used to decouple the program logic into several different phases.
Program Types and Helper Functions
Each eBPF program belongs to a specific Program Types, which can be found in the linux/bpf.h#L168 at v5.9 file to see what program types are supported in the current version, and more are being added all the time. They can be broadly classified into several categories such as network, trace, security, etc. The input parameters of eBPF programs also vary according to the program type.
Helper Functions are used to help handle the interaction between user space and kernel space, such as getting PIDs, GIDs, time, and manipulating kernel objects from the kernel. The helper functions supported by different kernel versions are also different. We can view the helper functions supported by the current version from linux/bpf.h#L3399 at v5.9.
For example, eBPF programs of type BPF_PROG_TYPE_SOCKET_FILTER can only use the following helper functions.
Due to space limitations, only a few simple examples are given in this article. For a detailed classification of auxiliary functions and relationships, please refer to the BCC documentation bcc/docs/kernel-versions .
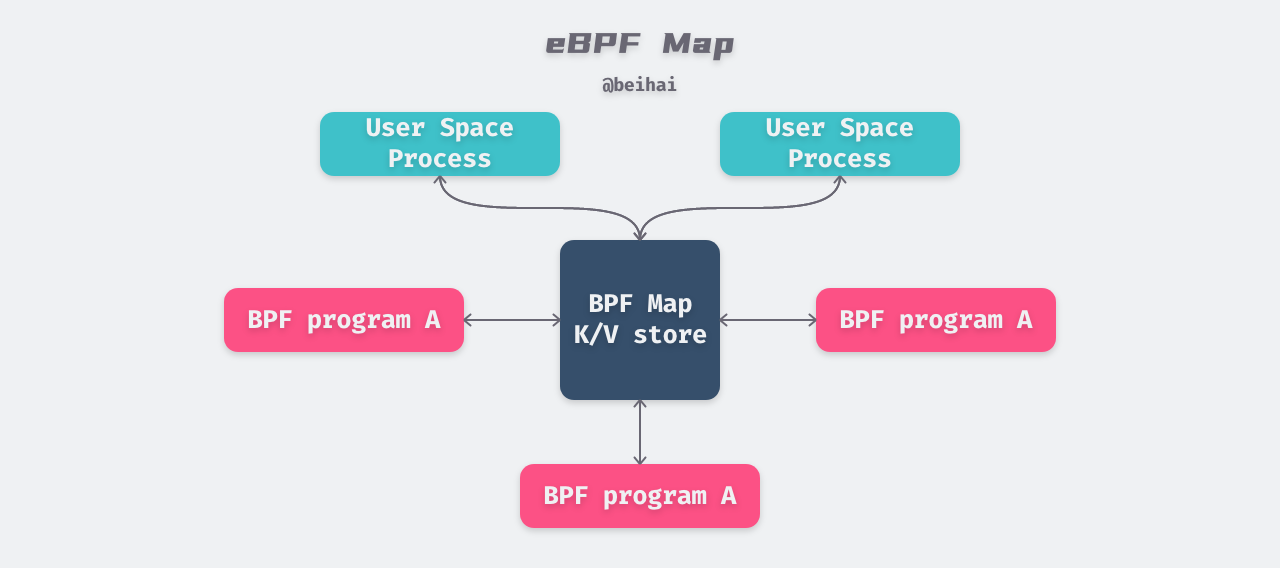
eBPF Maps
eBPF Maps are efficient key-value repositories that reside in kernel space**. data in a Map can be accessed by any eBPF program, and state information can be placed in a Map if you want to save state between multiple eBPF program calls. maps can also be accessed from user space via file descriptors and can be shared between any eBPF program and user space Map can also be accessed from user space via file descriptors and can be shared between any eBPF program and user space applications. Thus, the Map can be used for data interaction between eBPF programs and eBPF programs, and between eBPF programs and user-state programs.
The eBPF programs sharing a Map do not need to be the same program type, e.g. a monitoring program can share a Map with a network program. Currently a single eBPF program can directly access up to 64 different Maps.
Mapping Types
Map provides a layer of base data structure mapping for upper-level programs. There are more than two dozen data types, all implemented by the core kernel, so we cannot add or modify data structures.
There are two types of Map: generic Map and non-generic Map. The following are some of the generic Map types.
The Generic Map provides mappings for data structures such as hash tables, arrays, LRU, etc., in addition to the corresponding single CPU mapping types: we can assign CPUs to the type maps, and each CPU will see its own independent version of the map, which is more conducive to high-performance lookup and metrics aggregation.
eBPF programs can read and write Map through helper functions, and user-state programs can read and write Map through the bpf() system call, and all functions and commands that operate on the generic Map are listed below.
|
|
Data manipulation is not complicated, and its role can be seen from the function name. The user state bpf() system call then encapsulates some advanced operations to facilitate bulk data processing.
The above lists several non-generic Maps that are only used in specific scenarios, for example BPF_MAP_TYPE_PROG_ARRAY is used to hold references to other eBPF programs and can be used with tail calls to jump between programs, BPF_MAP_TYPE_ARRAY_OF_MAPS and BPF_MAP_TYPE_ HASH_OF_MAPS are used to hold pointers to other Maps so that the entire Map can be replaced atomically at runtime, and BPF_MAP_TYPE_CGROUP_ARRAY is used to hold references to cgroups.
eBPF Virtual File System
The basic feature of an eBPF mapping is the file descriptor fd, which means that the data saved when the file descriptor is closed is also lost. In order to keep this data even after the program that created it terminates, the eBPF virtual file system was introduced starting with Linux kernel version 4.4 and by default mounts the data in the /sys/fs/bpf/ directory, identifying these persistent objects by their path.
We can only manipulate these objects with the system call bpf(), the BPF_OBJ_PIN command is used to save Map objects to the file system, and BPF_OBJ_GET is used to get objects that are already fixed to the file system.
Concurrent Access
Since eBPF mapping can occur with many programs accessing the same Map concurrently, this can create contention conditions. To prevent data contention, eBPF introduces the concept of spin locks to lock the accessed map elements.
The spinlock feature was introduced in Linux 5.1 and is only available for arrays, hashes, and cgroup mappings.
In the eBPF program, we can use the two helper functions BPF_FUNC_spin_lock() and BPF_FUNC_spin_unlock() to lock and unlock the data so that other programs can access the element safely after releasing the lock. In user space, we can use the BPF_F_LOCK flag when updating or reading elements to avoid data races.
eBPF Application Scenarios
After understanding the basic concepts of eBPF programming, let’s take a look at a few application scenarios for eBPF.
Tracing
The purpose of tracing is to provide runtime useful information for future problem analysis. The main advantage of using eBPF for tracing is that you can access almost any information about the Linux kernel and application, and eBPF imposes minimal overhead on system performance and latency, and does not require business process modifications to collect data. eBPF provides both probe and trace point tracing methods
Probes
The probes provided by eBPF are of two types.
- Kernel probes: provide dynamic access to internal components in the kernel.
- User space probes: provide dynamic access to programs running in user space.
There are two types of kernel probes: kprobes allow inserting eBPF programs before any kernel instructions are executed, and kretprobes insert eBPF programs when kernel instructions have return values. User space probes allow dynamic flags to be set in programs running in user space; they are equivalent to kernel probes and are divided into uprobes and ureprobes.
In the following BCC example code, we have written a kprobes probe program that demonstrates the functionality of eBPF by tracing the execve() system call. Monitoring the execve() system call is useful for detecting unexpected executables.
The do_sys_execve() function in the code is used to get the name of the command the kernel is running and print it to the console; we then bind the do_sys_execve() function to the execve() system call using the bpf.attach_kprobe() method provided by BCC. Running this program will show you that whenever the kernel executes the execve() system call, the corresponding command name will be printed on the console.
|
|
Note that kernel probes do not have a stable application binary interface (ABI), so the same program code may not work in different kernel versions.
Tracepoints
Tracepoints are static markers for kernel code, developed and written by the kernel staff, and are guaranteed to exist on newer versions for traces from older versions.
Each tracepoint on Linux corresponds to a /sys/kernel/debug/tracing/events entry. For example, to see the network-related tracepoints.
|
|
In the following example, we bind the eBPF program to the net:netif_rx tracepoint and print out the name of the calling program on the console.
|
|
Networking
eBPF programs have two main uses in networking: packet capture and filtering. User-space programs can add filters to any socket to extract information about packets, or to release, ban, redirect, etc. for specific types of packets.
Packet Filtering
Packet filtering is one of the most common scenarios for eBPF and is used in three main situations.
- Real-time traffic drop, e.g., allowing only UDP traffic to pass and dropping other packets.
- real-time observation of packets filtered by specific conditions.
- subsequent analysis of network traffic captured in a real-time system.
tcpdump is a typical eBPF packet filtering application, and now we can write some custom networking programs in bcc/examples/networking you can see some examples of usage
Flow Control Classifier
A few examples of traffic control uses are as follows.
- prioritizing certain types of packets.
- Dropping specific types of packets.
- Bandwidth allocation.
XDP
XDP (eXpress Data Path) provides a high-performance, programmable network data path for the Linux kernel. It gives Linux networks a huge performance boost because network packets are processed before they even enter the network stack.
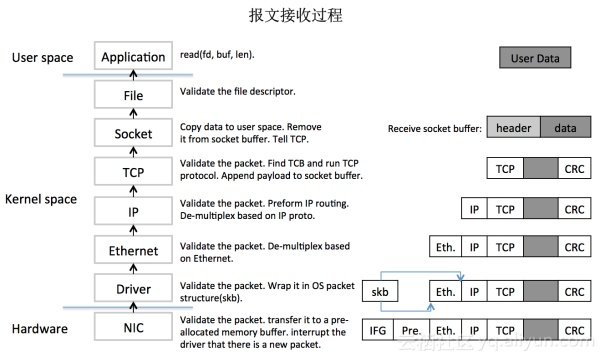
The above image shows a complete packet reception process, and the entire processing chain is long, requiring memory copies, context switches, hardware and software interrupts between the kernel and user states. Processing a large number of packets will take up a lot of CPU resources, making it difficult to meet the demands of a highly concurrent network.
XDP solves this problem. It is equivalent to adding a new layer to the Linux network stack. The processing is done at the earliest moment when the message arrives at the CPU, even avoiding the allocation of sk_buff and reducing the load on the memory copy. With the support of specific NIC hardware and drivers, it is even possible to offload XDP programs to the NIC, further reducing CPU usage.
XDP relies on eBPF technology and provides a complete, programmable packet processing scheme that allows us to forward, redirect and pass down packets using XDP. Examples can be found in bcc/examples/networking/xdp.
Security
Seccomp (Secure Computing) was introduced to the Linux kernel in version 2.6.12 to limit the system calls available to processes to four: read, write, _exit, and sigreturn. Initially, Seccomp mode was implemented using a whitelist approach, in which the kernel terminates the process using SIGKILL or SIGSYS if any other system call is attempted, except for open file descriptors and the four allowed system calls.
Although Seccomp secures the host, it is too restrictive to be of much practical use. To address the need for more fine-grained restrictions in practical applications, Seccomp-BPF was introduced.
Seccomp-BPF is a combination of Seccomp and cBPF rules (note that it is not eBPF), which allows users to filter system calls using a configurable policy implemented using BPF rules, which can filter on any system call and its parameters.
An example of its use can be found in seccomp.