File System
The file system is the subsystem of the operating system responsible for managing persistent data. To put it simply, it is responsible for saving the user’s files to the disk hardware, because even if the computer loses power, the data in the disk is not lost, so the files can be saved persistently.
The basic data unit of a file system is the file, and its purpose is to organize and manage the files on disk, and the different ways of organizing them result in different file systems.
The most classic Linux saying is “everything is a file”. Not only common files and directories, but also block devices, pipes, sockets, etc., are unified and given to the file system for management.
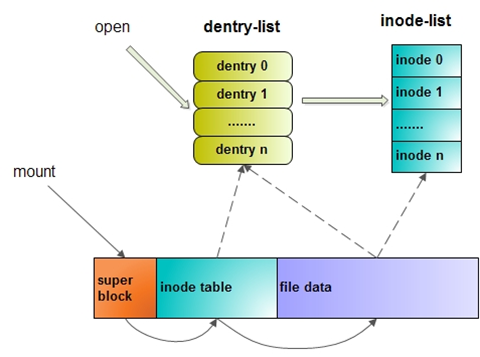
The Linux file system assigns two data structures to each file: index node and directory entry, which are mainly used to record meta information and directory hierarchy of files.
-
Index nodes, also known as inodes, are used to record meta-information about a file, such as inode number, file size, access rights, creation time, modification time, location of data on disk, and so on. Index nodes are unique identifiers of files, they correspond to each other one by one, and they are also stored in the hard disk, so index nodes also occupy disk space.
-
A directory entry, or dentry, is used to record the name of a file, a pointer to the index node, and a hierarchical association with other directory entries. Multiple directory entries are associated to form a directory structure, but it differs from an index node in that a directory entry is a data structure maintained by the kernel and is not stored on disk, but is cached in memory.
Since an index node uniquely identifies a file and a directory entry records the name of the file, the relationship between a directory entry and an index node is many-to-one, that is, a file can have multiple directories. For example, a hard link is implemented as multiple index nodes in a directory entry pointing to the same file.
Note that a directory is also a file, also uniquely identified by an index node. The difference with a normal file is that a normal file holds file data inside the disk, while a directory file holds subdirectories or files inside the disk.
Are directory entries and directories the same thing?
Although the names are similar, they are not the same thing. A directory is a file that is persistently stored on disk, while a directory entry is a data structure in the kernel that is cached in memory.
If a directory is read frequently from disk, it will be very inefficient, so the kernel will cache the read directory in memory with the data structure of the directory entry, and the next time the same directory is read again, it will be read from memory, which greatly improves the efficiency of the file system.
Note that the data structure “directory entry” is not just for directories, but also for files.
How is the file data stored on the disk?
The smallest unit of disk reading and writing is the sector, the size of the sector is only 512 bytes, so if the data is larger than 512 bytes, the disk needs to keep moving the head to find the data, we know that the general file can easily exceed 512 bytes then if multiple sectors are combined into one block, then the disk can be more efficient. Then the head reads multiple sectors at a time as a block (called a block on Linux, or a cluster on Windows). Therefore, the file system consists of multiple sectors into a logical block, and the smallest unit for each read/write is the logical block (data block), which is 4KB in size in Linux, i.e., 8 sectors are read/written at once, which will greatly improve the efficiency of disk read/write.
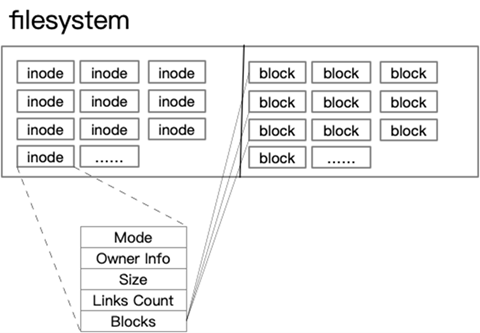
The data recorded by the file system, in addition to its own, there is data permission information, owner and other attributes, these information are stored in the inode, so who will record the inode information and the file system itself, such as the file system format, the number of inode and data? Then there is a super block to record this information.
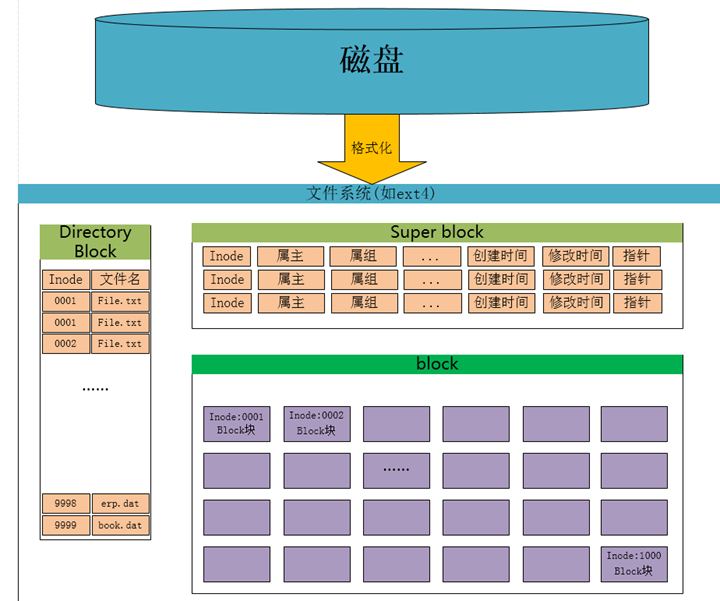
- superblock: records the overall information of the filesystem, including the total number of inodes/blocks, usage, remaining amount, and the format and related information of the filesystem.
- inode: Record the attribute information of the file, you can use the stat command to view the inode information.
- block: the actual file content, if a file is larger than one block, then it will occupy more than one block, but a block can only store one file. (Because the data is pointed by inode, if there are two files of data stored in the same block, it will be messed up)
node is used to point to the data block, then as long as the inode is found, and then the block number is found by the inode, then the actual data can be found.
The index node is the data stored on the hard disk. In order to speed up the file access, the index node is usually loaded into the memory. We can’t load all the superblock and index node area into memory, so the memory will definitely not hold up, so they are loaded into memory only when they need to be used, and they are loaded into memory at different times as follows.
- Superblock: enters memory when the file system is mounted.
- Index node area: into memory when the file is accessed.
Virtual File System
There are many different types of file systems, and the operating system wants to provide a uniform interface to the user, so it introduces an intermediate layer between the user layer and the file system layer, which is called the Virtual File System (VFS). VFS defines a set of data structures and standard interfaces supported by all file systems, so that programmers do not need to understand how the file system works, but only the uniform interfaces provided by VFS. The relationships between user space, system calls, virtual machine file systems, caches, file systems, and storage in the Linux file system are as follows.
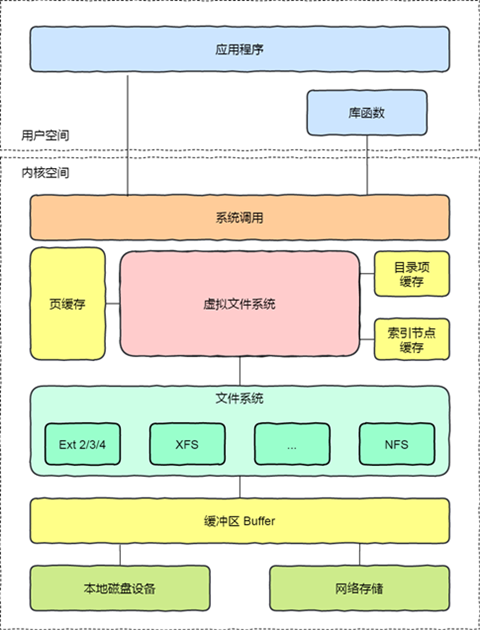
There are quite a few file systems supported by Linux, and depending on the storage location, file systems can be divided into three categories.
- Disk-based file systems, which store data directly in the disk, such as Ext 2/3/4, XFS, etc. are this type of file systems.
- In-memory file systems, which store data not on the hard disk but in memory. The /proc and /sys file systems we often use belong to this category.
- Network file systems, file systems used to access data from other computer hosts, such as NFS, SMB, etc.
The file system must first be mounted to a directory before it can be used properly, for example, Linux mounts the file system to the root directory at boot time.
Linux uses a hierarchical architecture that separates the user interface layer, the file system implementation and the storage device drivers, thus making it compatible with different file systems. The Virtual File System (VFS) is a software layer in the Linux kernel that provides a standard, abstract set of file operations in the kernel, allows different file system implementations to coexist, and provides a uniform file system interface to user space programs. The following diagram illustrates the overall structure of the Linux virtual file system.
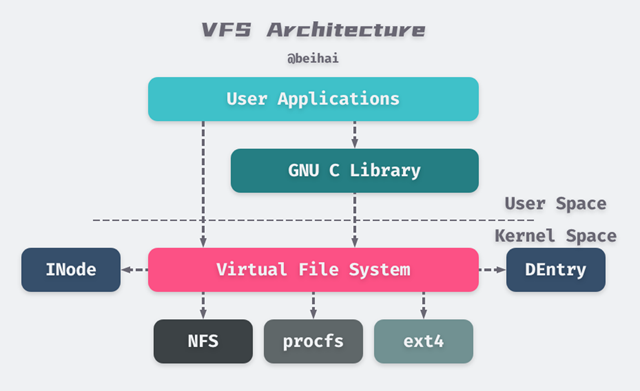
As you can see from the diagram above, the user-space application performs file operations either directly or indirectly by calling the System Call interface provided by the kernel (e.g., open(), write(), etc.) through library functions provided by the programming language.
The System Call interface then passes the application’s parameters to the virtual file system for processing.
Each file system implements a set of common interfaces for the VFS, and the specific file system operates on the data according to its own organization of the data on the disk. When an application operates on a file, VFS finds the corresponding mount point based on the file path, gets the specific file system information, and then calls the corresponding operation function for that file system.
VFS provides two caches for file system objects, INode Cache and DEntry Cache, which cache recently used file system objects and are used to speed up accesses to INode and DEntry. The Linux kernel also provides Buffer Cache buffers to cache requests between the file system and associated block devices, reducing the number of accesses to physical devices and speeding up accesses. The Buffer Cache manages buffers in the form of LRU lists.
The benefit of VFS is that it decouples the application’s file operations from the specific file system, making it easier to program.
- Application-level programs can perform file operations simply by using the read(), write(), and other interfaces provided externally by VFS, without caring about the details of the underlying file system implementation.
- The file system only needs to implement the VFS interface to be compatible with Linux, making it easy to port and maintain.
- Cross-file system file operations are implemented without concern for specific implementation details.
After understanding the overall structure of the Linux file system, the following is an analysis of the technical principles of Linux VFS. Since the implementation of the file system and device drivers is very complex, and I have not been exposed to this area, I will not cover the implementation of specific file systems in this article.
VFS structure
Linux views all file systems in terms of a set of generic objects, and the relationship between objects at each level is shown in the diagram below.
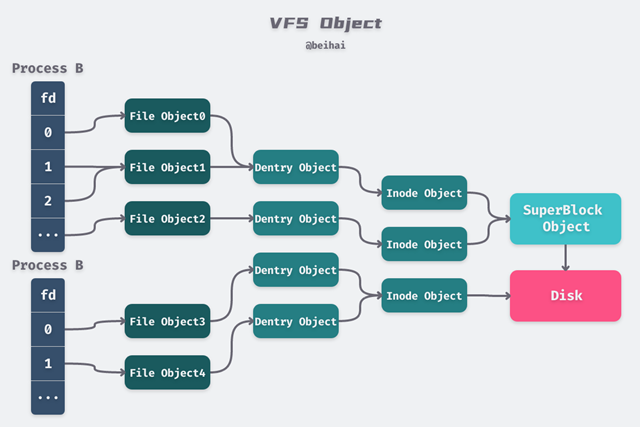
fd vs file
each process holds an array of fd[], which holds a pointer to a file structure; different fd’s of the same process can point to the same file object.
file is a data structure in the kernel that represents a file that is opened by a process and associated with the process. When the application calls the open() function, VFS creates the corresponding file object. It holds the status of the opened file, such as file permissions, paths, offsets, etc.
|
|
As you can see from the code above, the path to the file is actually a pointer to the DEntry structure, and VFS indexes to the location of the file via DEntry.
Except for the file offset f_pos, which is private to the process, all other data comes from INode and DEntry and is shared with all processes. The file objects of different processes can point to the same DEntry and Inode, thus enabling file sharing.
DEntry and INode
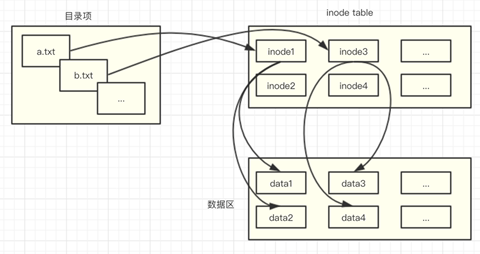
The Linux file system assigns two data structures to each file, a Directory Entry (DEntry) and an Index Node (INode).
DEntry is used to hold the mapping between file paths and INodes, thus supporting movement within the file system. DEntry is maintained by VFS, shared by all file systems, and is not associated with a specific process. dentry objects start at the root directory “/”, and each dentry object holds its own Each dentry object holds its own subdirectories and files, thus forming a file tree. For example, if you want to access the file “/home/beihai/a.txt” and operate on it, the system will resolve the file path, starting with the dentry object in the root directory “/”, and then find the “home/” directory, followed by “beihai/”, and finally the dentry structure of “a.txt”, in which the d_inode field corresponds to that file.
|
|
Each dentry object holds a corresponding inode object, representing a specific directory entry or file in Linux. inode contains all the metadata needed to manage objects in the file system, as well as the operations that can be performed on that file object.
|
|
The virtual file system maintains a DEntry Cache, which is used to store the most recently used DEntry and speed up query operations. When a file is opened by calling the open() function, the kernel will first search the DEntry Cache for the corresponding DEntry based on the file path, and then construct a file object and return it if it is found. If the file is not in the cache, then VFS will load it down one level according to the nearest directory found until it finds the corresponding file. During this time, VFS caches all the dentry generated by the load.
The data stored in an INode is stored on disk and organized by a specific file system. when an INode needs to be accessed, the file system loads the corresponding data from disk and constructs an INode. an INode may be associated with more than one DEntry, i.e. it is equivalent to creating multiple file paths for a particular file (usually by creating hard links to the files).
SuperBlock
SuperBlock represents a specific loaded file system, used to describe and maintain the state of the file system, defined by VFS, but populated with data based on the specific file system. Each SuperBlock represents a specific disk partition and contains information about the current disk partition, such as file system type, remaining space, etc. An important member of the SuperBlock is the chain s_list, which contains all modified INodes, using which it is easy to distinguish which files have been modified and to write the data back to disk with the kernel thread. Another important member of the SuperBlock is s_op, which defines all operations on its INode, such as marking, releasing index nodes, and a number of other operations.
|
|
A SuperBlock is a very complex structure that allows us to mount a physical file system on Linux or to add, delete, or check an INode. That’s why file systems usually store multiple copies of SuperBlock on the disk to prevent accidental data corruption that could make the whole partition unreadable.
inode content
The inode contains a lot of file meta-information, but not the file name, such as the number of bytes, the owner UserID, the group GroupID, the read/write execution permissions, the timestamp, and so on. While filenames are stored in directories, Linux systems do not use filenames internally, but use inode numbers to identify files. For the system the file name is just an alias for the inode number for easy identification.
stat
View inode information
|
|
Three main time attributes.
- ctime: change time is the time when the file or directory (attribute) was last changed, e.g. by executing commands such as chmod, chown, etc.
- atime: access time is the time when the file or directory was last accessed.
- mtime: modify time is the time when the file or directory (content) was last modified.
file
View file type
inode number
On the surface, the user opens the file by its name, but in fact, the system internally divides this process into three steps.
- The system finds the inode number corresponding to this file name.
- Getting the inode information by the inode number.
- According to the inode information, find the block where the file data is located and read out the data.
In fact, the system also has to see whether the user has access rights according to the inode information, and if so, it points to the corresponding data block, and if not, it returns permission denied.
ls -i
View the file i-node number directly, or you can view the i-node number by viewing the file inode information via stat.
inode size
The inode also consumes hard disk space, so when formatting, the operating system automatically divides the hard disk into two areas. One is the data area, which holds the file data; the other is the inode area, which holds the information contained in the inode. The size of each inode is typically 128 bytes or 256 bytes. Usually it is not necessary to focus on the size of individual inodes, but rather on the total number of inodes. the total number of inodes is determined at formatting time.
df -i
View the total number of inodes and used status of the hard disk partitions.
|
|
File reading and writing
When the file system opens a file, it does the following.
- The system finds the inode corresponding to this file name: it looks up the item corresponding to this file name in the directory table, from which it gets the inode number corresponding to this file
- Get the inode information of the disk through the inode number, the most important part of which is the disk address table.
- The disk address table in the inode information is used by the file system to connect the physical blocks of the file that are scattered into the logical structure of the file. There are 13 block numbers in the disk address table, and the file will read the corresponding blocks in the order in which the block numbers appear in the disk address table. Find the block where the file data is located and read out the data.
According to the above process, we can find that inode should have a special storage area for the system to find it quickly. In fact, when a disk is created, the operating system automatically divides the hard disk into two areas: the data area, where file data is stored, and the inode area (inode table), where inode information is stored.
The size of each inode is usually 128B or 256B. the total number of inode nodes is given at formatting time, usually one inode for every 1KB or 2KB. suppose that in a 1GB hard disk, each inode node is 128 bytes in size, and one inode is set for every 1KB, then the size of the inode table will will reach 128MB, which is 12.8% of the entire hard disk.
In other words, the total number of inodes per partition is fixed from the time it is formatted, so there is a possibility that the storage space is not full, but the inodes are exhausted because of too many small files. At this time, you can only clear the files or directories with high inode occupancy or modify the number of inodes. Of course, inode adjustment requires reformatting the disk and you need to make sure that the data has been effectively backed up before doing this operation.
A new question arises: which inode number should be assigned to the file when it is created? That is, how to ensure that the assigned inode number is not occupied?
Since it is a question of “whether it is occupied or not”, using a bitmap is the best solution, just like a bmap records the occupation of a block. The bitmap that identifies whether an inode number has been assigned is called an inodemap or imap, and to assign an inode number to a file you simply scan the imap to know which inode number is free.
(The so-called bitmap, which uses each bit to hold some kind of state, is suitable for large-scale data, but not a lot of data state.) Like a bmap block bitmap, inode numbers are pre-programmed. inode numbers are allocated, and inode numbers are released when files are deleted. The allocated and released inode numbers are like digging up a piece of a map and replacing it when it is used up.
The imap suffers from the same problem as the bmap and inode table that needs to be solved: if the file system is large, the imap itself will be large, and scanning every time a file is stored will result in a lack of efficiency. Again, the optimization is to divide the blocks occupied by the file system into block groups, each with its own imap range, to reduce retrieval time.
Use the df -i command to view information on the number of inodes.
Operation of files
System operations on files may affect inode.
- Copy: Creates a new file containing all data with a new inode number
- Move: When moving under the same disk, the directory changes and neither the node number nor the location of the actual data storage block changes. Moving across disks will of course delete the data on this disk and create a new entry on another disk.
- Hard links: The same inode number represents a file with multiple filenames, i.e. the same data can be accessed with different filenames, but they point to the same inode number and the number of links in the file metadata is increased. It is not possible to create hard links to directories.
- Soft links: A soft link is essentially a linked file, which stores a pointer to another file. Therefore, if a soft link is created to a file with a different inode number, the number of links to the soft link file will not increase. Soft links can be created to directories.
- Delete: When a file is deleted, the number of links in the inode is checked first. If the link number is greater than 1, only one hard link will be deleted without affecting the data. If the number of links is equal to 1, the inode will be freed and the corresponding block pointed to by the inode will be marked as free (the data will not be set to zero, so the hard disk data can be recovered if no new data is written after it is deleted by mistake). In the case of soft links, the linked file becomes a dangling link after the original file is deleted and cannot be accessed normally.
The use of inode can also delete some files with escape characters or control characters in the file name, most typically files that start with a minus sign -. If you can’t use the rm command directly, you can find out their inode numbers before deleting them.
|
|
Peculiarities
The separation of inode numbers from filenames has led to the following phenomena unique to some Unix/Linux systems.
- The file name contains special characters, which may not be deleted properly. In this case, deleting the inode directly can serve to delete the file:
find . /* -inum node number -delete - Moving a file or renaming a file, which only changes the file name and does not affect the inode number.
- After opening a file, the system identifies the file by its inode number and no longer considers the file name.
This situation makes software updates easy and can be done without closing the software and without rebooting. This is because the system recognizes running files by their inode numbers, not by their filenames. When updating, the new version of the file takes the same filename and generates a new inode that does not affect the running file. When the software is next run, the filename automatically points to the new version of the file, and the inode of the old version is recycled.
inode exhaustion failure
Since the total number of inodes on a hard disk partition is fixed after formatting, and each file must have an inode, it is possible to run out of inode nodes, but there is still a lot of space left on the hard disk, but no new files can be created. Also this is a way to attack, so some public file systems have to do disk limits to prevent affecting the normal operation of the system. As for fixing it, it’s easy, just find out which files that are taking up a lot of i-nodes and delete them.
Hard and soft links
Linux has a special kind of file called link. There are two types of links in Linux, hard links and soft links. In simple terms, a hard link is equivalent to a source file and a link file sharing an inode on disk and in memory, so the link file has a different dentry from the source file, so this feature means that a hard link cannot span the file system, and we cannot create a hard link for a directory. Soft links are different from hard links, firstly, soft links can span the file system, secondly, linked files and source files have different inode and dentry, therefore, the properties and contents of the two files are very different, the file contents of soft link files are the file names of the source files.
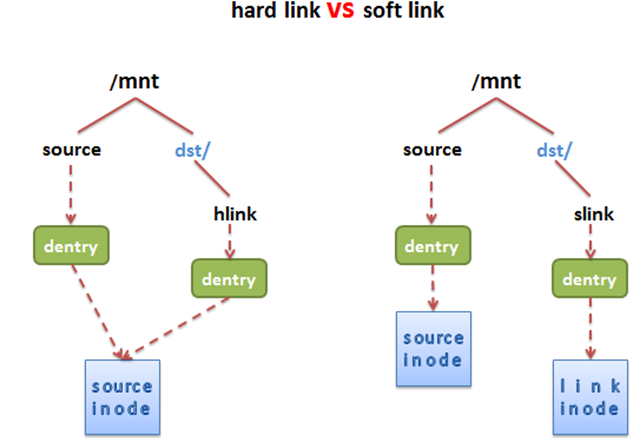
Hard links are “index nodes” in multiple directory entries pointing to a single file, i.e. to the same inode, but inodes cannot span file systems, each file system has its own inode data structure and list, so hard links cannot be used across file systems. Since multiple directory entries are pointing to one inode, the system will only delete the file completely if all hard links to the file and the source file are deleted.
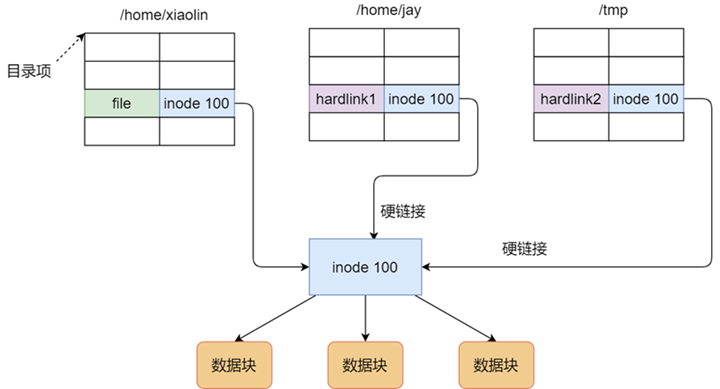
The soft link is equivalent to re-creating a file with a separate inode, but the content of this file is the path of another file, so when accessing the soft link, it is actually equivalent to accessing another file, so the soft link can cross the file system, even if the target file is deleted, the linked file is still there, but the file it points to is not found.
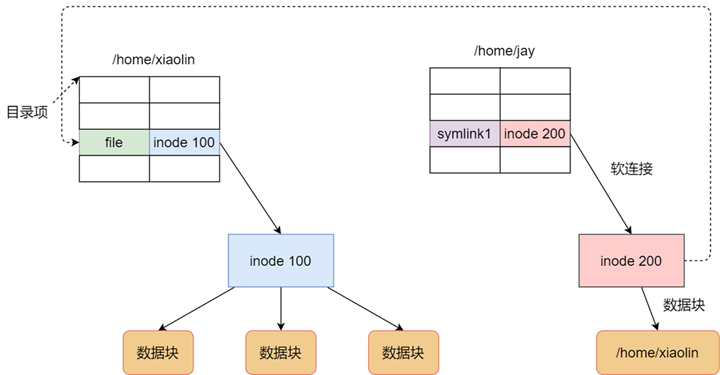
- The principles of soft and hard links are different
- A hard link creates a directory entry that contains the file name and the inode of the file, but the inode is the inode number of the original file, and does not create the data corresponding to it. So a hard link does not occupy the inode.
- A soft link also creates a directory entry, which also contains the file name and the inode of the file, but its inode does not point to the inode of the data pointed to by the original file name, but creates a new inode and creates the data, which points to the original file name, so the number of characters of the original file name is the number of bytes occupied by the soft link.
- There is a difference in the targets that can be created by soft and hard links
- Because each partition has a different set of inode tables, hard links cannot be created across partitions while soft links can, because soft links point to file names.
- A hard link cannot point to a directory
- If a directory has a hard link, it may introduce a dead loop, but you may wonder if a soft link will also be in a loop. The answer is of course not, because a soft link has its own data and can check its own file properties. But hard links can’t, because their inode numbers are the same, so they can’t be judged as hard links, so they will be in a dead loop.