Modern operating systems use virtual memory for memory management, and this article summarizes the principles of virtual memory and some application scenarios.
The main memory of a computer system is composed of M contiguous byte arrays, each of which has a unique Physical Address (PA). Under these physical conditions, the most natural way for the CPU to access memory is to use physical addressing, as shown in the figure below, where the CPU executes a load instruction to read the data at physical address 5.
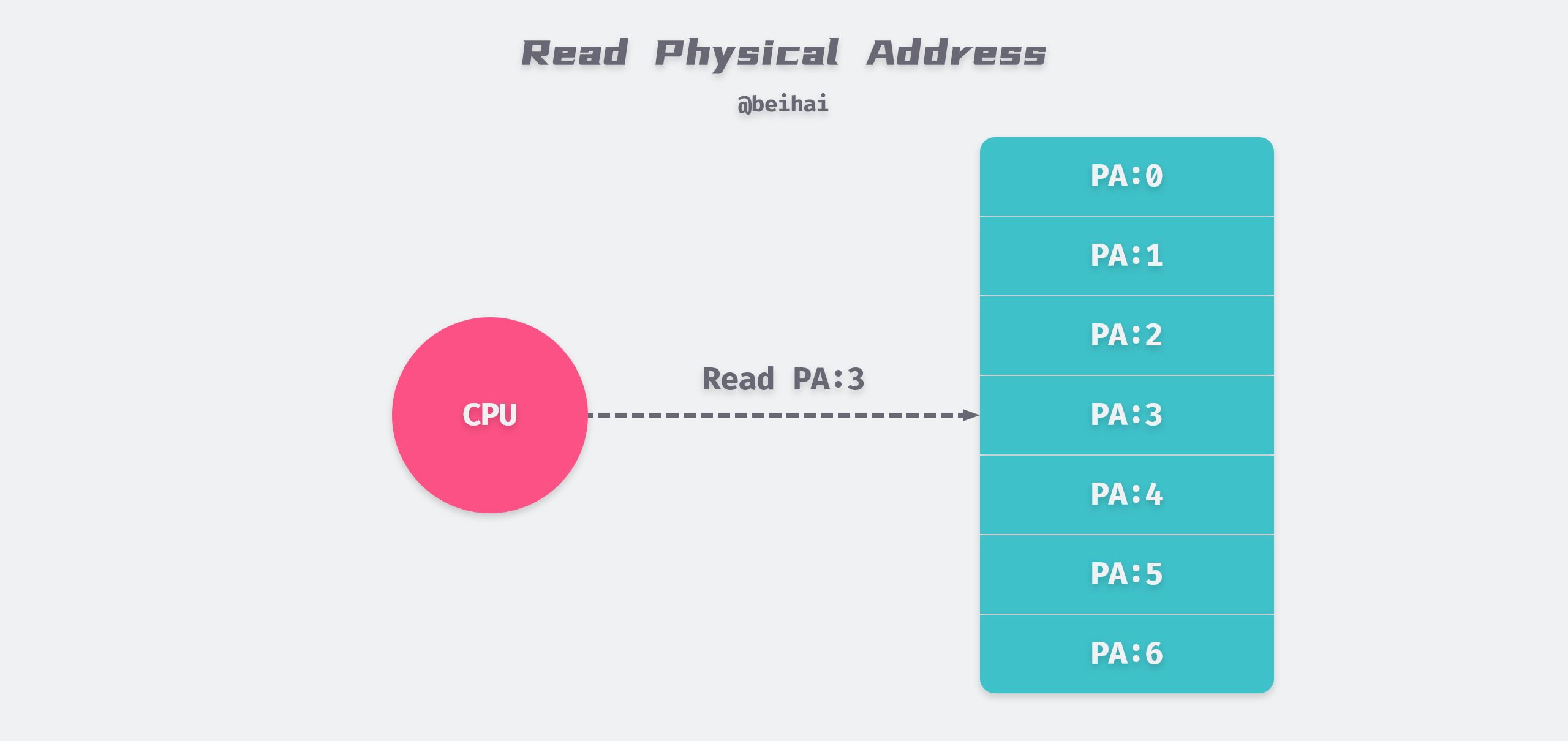
Because programs manipulate physical memory directly, if the second program writes a new value at physical address 2000, it will erase the contents of the first program stored in the same location. In this case, it is impossible to run two programs in memory at the same time.
In order to manage memory more efficiently and with fewer errors, modern operating systems provide an abstraction of main memory: virtual memory, which provides a large private address space for each process.
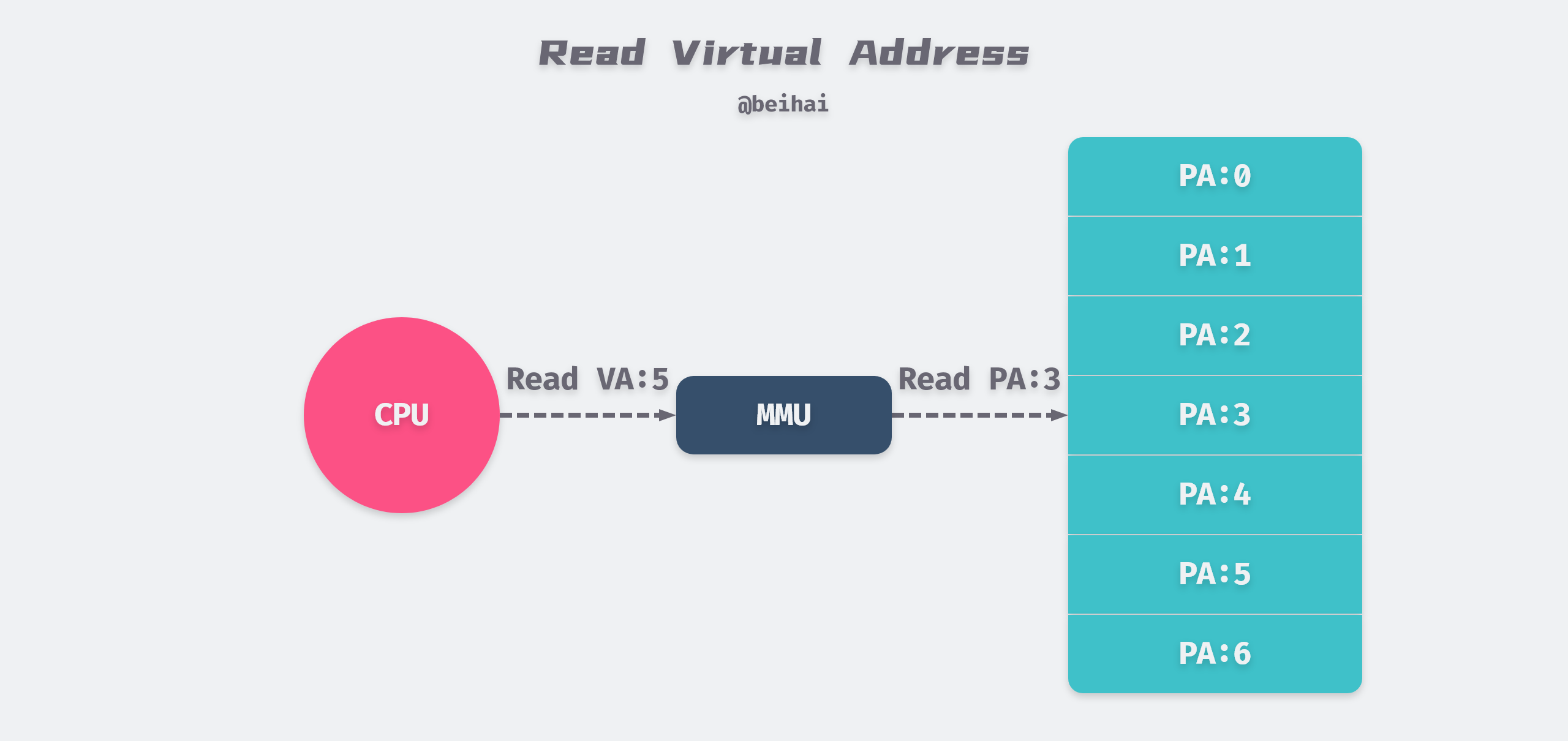
The CPU accesses the main memory by generating a virtual address. The Virtual Address (VA) held by the process is converted into a physical address by the Memory Mangament Unit (MMU) in the CPU chip, and then the memory is accessed by the physical address.
Virtual memory provides three important capabilities.
- Virtual memory uses memory efficiently by treating physical memory as a cache of address space stored on disk, holding only active regions in main memory, and transferring data between disk and main memory as needed.
- virtual memory provides a consistent address space for each process, simplifying how memory is managed.
- virtual memory protects each process’s address space from being corrupted by other processes.
Due to the long access time to the hard disk, synchronization between physical memory and disk is done using the Write Back mode, where the write operation is simply written to memory and then asynchronously flushed to disk.
Paging
The operating system uses paging to manage memory. Paging is the process of slicing all virtual memory space and physical memory space into fixed-size memory pages, and managing memory in pages. The default size of each page under Linux is 4KB.
Each physical page requires a struct page data structure to describe it, stored in physical memory. To reduce the memory footprint, the structure makes extensive use of the C language union Union to optimize its size. The following code snippet organizes the key fields in it.
|
|
The page structure manages the state of the current page, the number of references, whether it is free or not, etc. A page structure occupies about 64Bytes, which is about 1.5%.
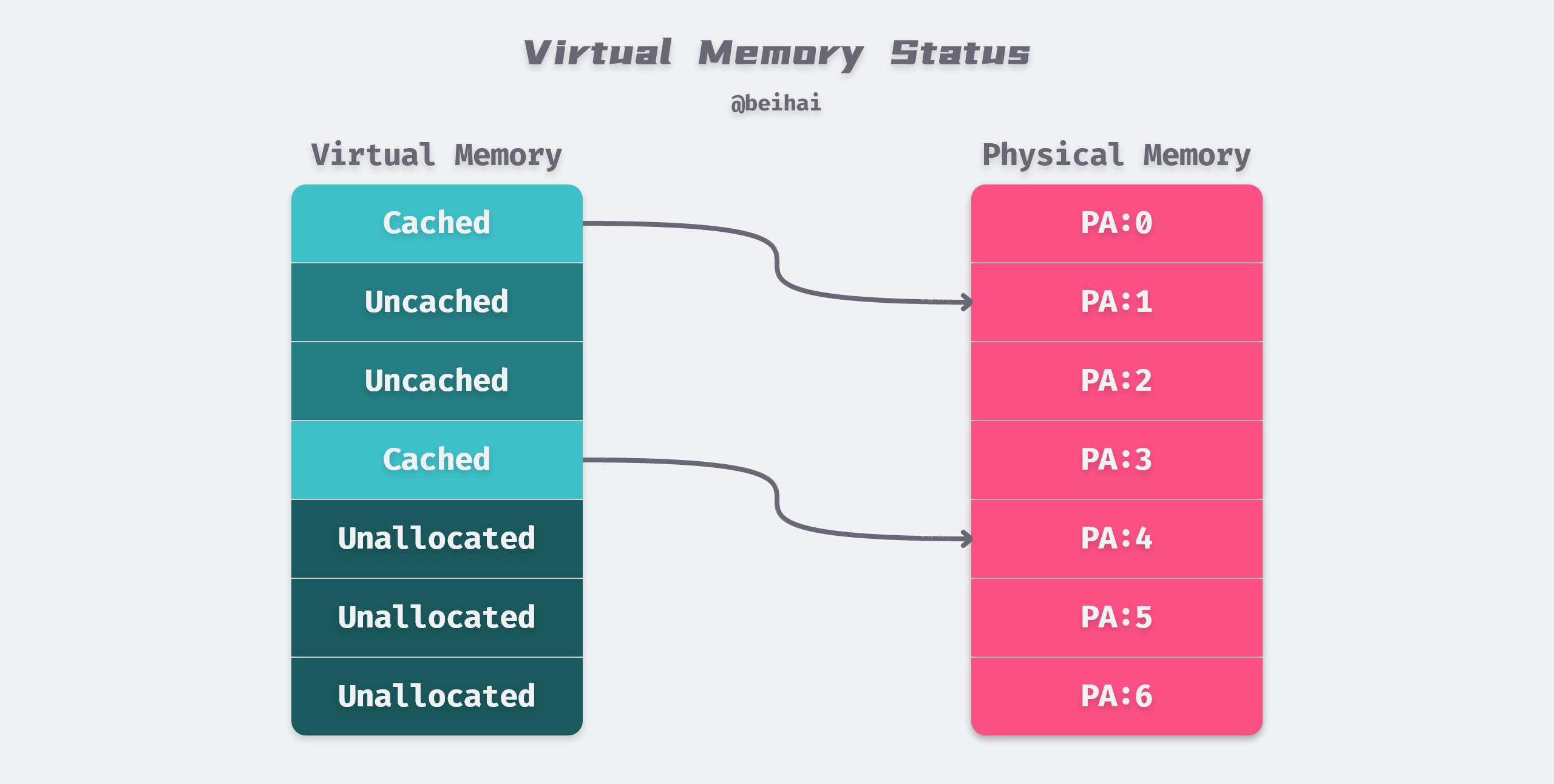
Virtual pages in virtual memory are stored on disk and may be in the following three states.
- Unallocated: memory pages that have not yet been requested for use by the process, i.e., free virtual memory that does not occupy any disk space.
- Uncached: memory pages that have only been loaded to disk and have not yet been loaded into physical memory.
- Cached: memory pages that have been loaded into physical memory.
Page tables
Like caching systems, virtual memory systems must have the ability to determine whether a virtual page is cached in physical memory. Each process has a Page Table data structure stored in physical memory, a node of which is called a Page Table Entry (PTE) and is responsible for maintaining the mapping of virtual pages to physical pages. The operating system maintains the contents of the Page Table, as well as migrates data between physical memory and disk.
Under the paging mechanism, the virtual address is divided into two parts, Page Number and Intra-page Offset. The page number serves as the index of the page table, which contains the base address of the physical memory where each page of the physical page is located, and the combination of this base address and the intra-page offset forms the physical memory address. For a memory address conversion, there are three steps as follows.
- slicing the virtual address into page numbers and offsets.
- looking up the corresponding physical page number in the page table, based on the virtual page number.
- add the physical page number to the previous offset to get the final physical memory address.
On-demand page scheduling
If the CPU references an address in virtual memory, but the address is not cached in physical memory, then a page out interrupt is triggered. Because physical memory has a finite amount of space, when there is not enough space in physical memory to use, the operating system selects the appropriate physical memory page to evict back to disk to make way for the new memory page.
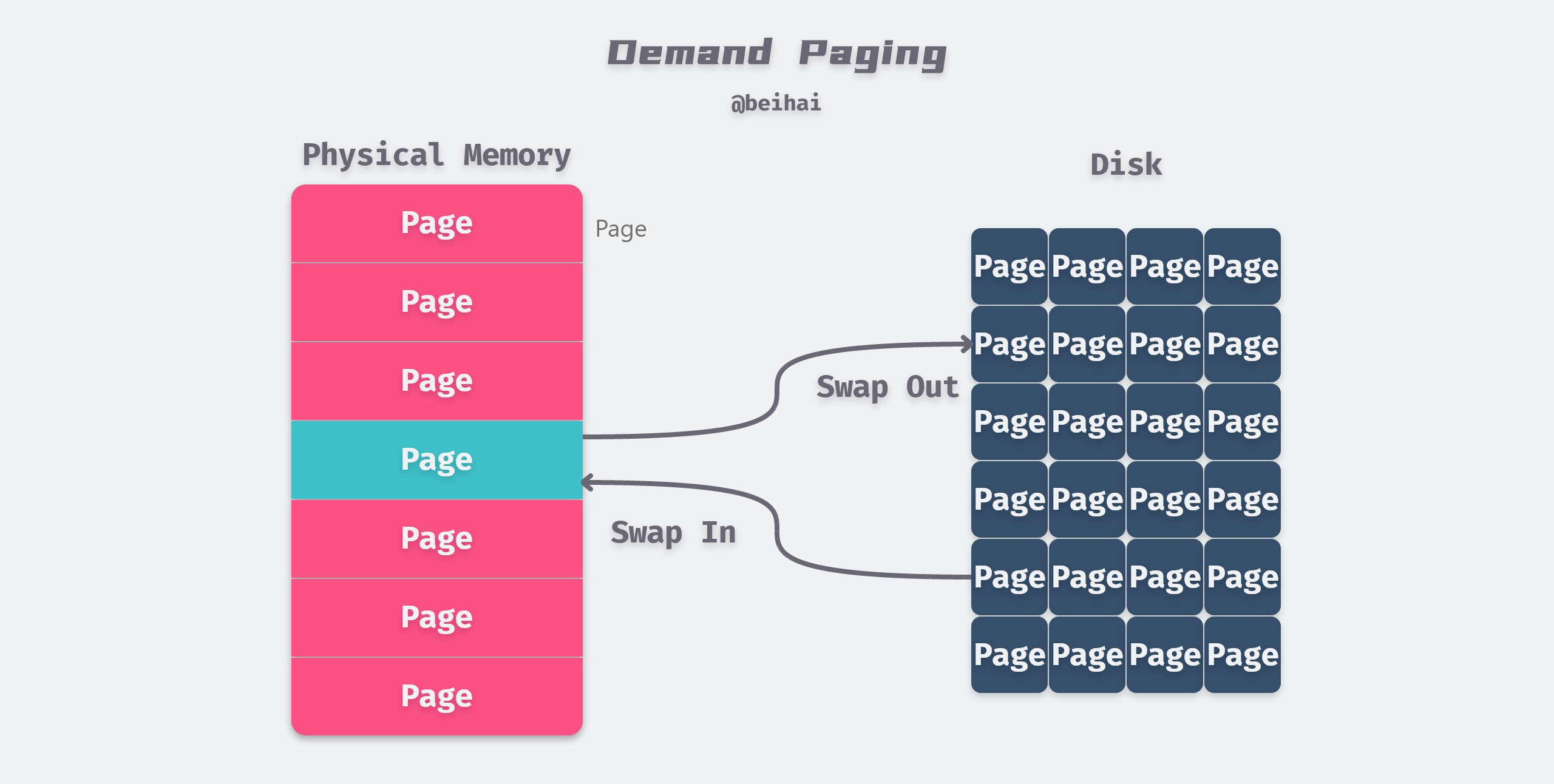
The strategy of swapping in pages only when a page miss occurs is known as the on-demand page scheduling algorithm, and the purpose of this algorithm is to make full use of memory resources as a cache on disk to improve the efficiency of the program’s operation.
Although the total number of pages referenced by a program throughout its runtime may exceed the total physical memory, program access to data tends to be localized and always tends to work on a smaller set of active pages at some point in the program’s runtime. This ensures that as long as the size of the working set does not exceed the size of the physical memory, then there will be no frequent swapping of pages in and out. Usually virtual memory works very efficiently.
Memory page permissions
Virtual memory provides separate address spaces making it easy to distinguish private memory for different processes. In addition to this, the page table can store the access relationships between processes and physical pages, such as read permissions, write permissions and execute permissions. Thus virtual memory can be used as a memory protection tool to determine whether the current process has permission to access the physical memory of the target, for example
- not allowing a user process to modify its read-only code segments.
- not allowing a user process to read or modify code and data structures in the kernel.
- not allowing the user process to read or write to the private memory of other processes.
The address translation mechanism provides better access control in a natural way. the CPU reads a PTE each time an address is generated, so it makes it simple to control access to the contents of the virtual page by adding additional permission bits to the PTE.
Multi-level page tables
As mentioned above, each process has its own page table structure, which has the advantage that each running process has its own separate memory space, isolating access to different processes. Each process needs its own page table, which results in a large amount of all the memory in the system being used to hold the page table. A process with 4GB of virtual memory will have over a million 4KB pages, and if we assume that one page table entry takes up 8Bytes, then one page table will take up 8MB, and a hundred such processes will take up 800MB.
To reduce the size of the page table and to allow unallocated virtual memory to be ignored, the Linux system divides the virtual address into multiple parts, forming a multi-level page table structure. x86-bit processors use a two-level page table structure for memory management. Under the X84-64 processor, Linux kernel 2.6.11 started using a four-level page table, while Linux kernel 4.14 started using a five-level page table structure.
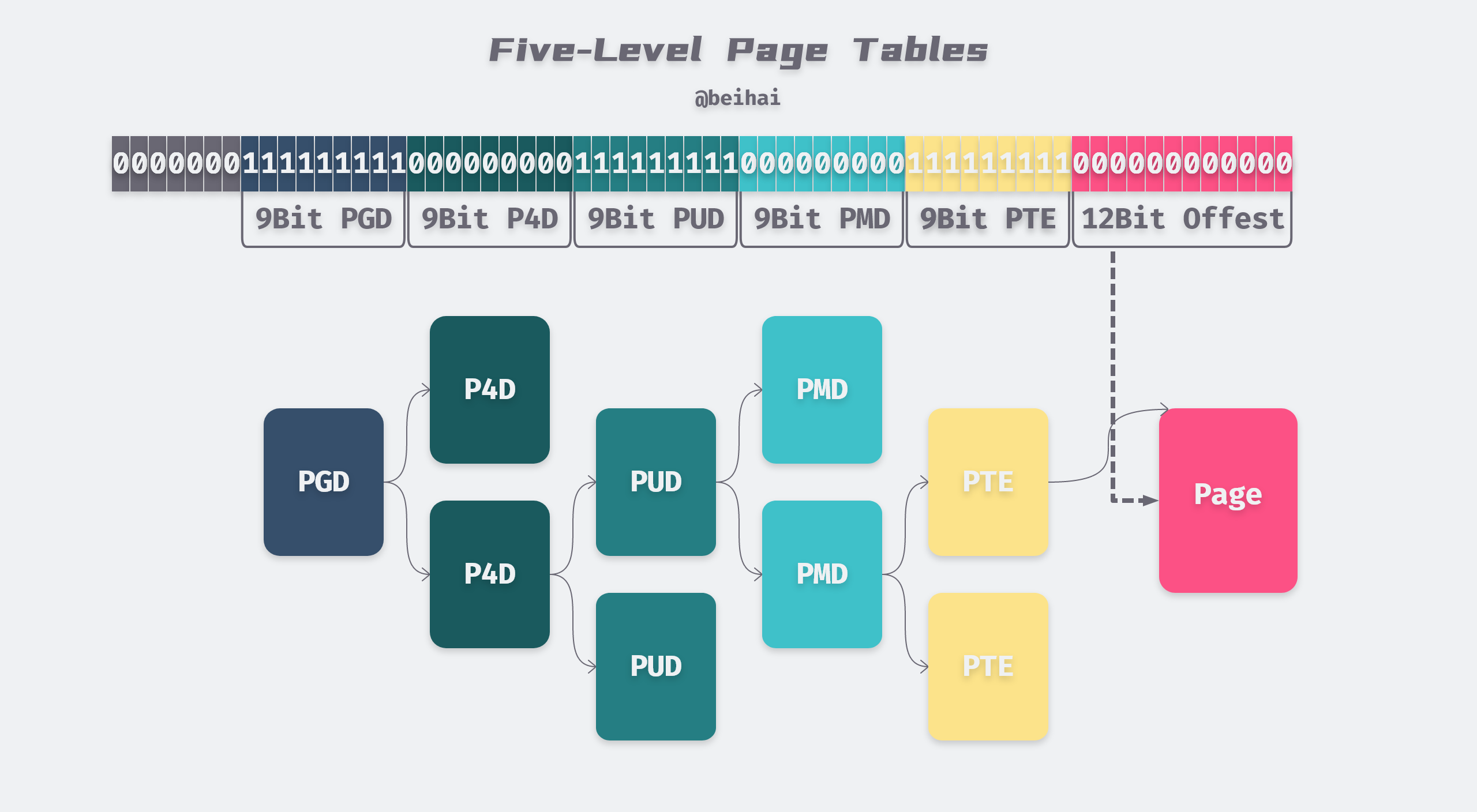
The figure above shows the structure of the five-level page table, using 57 bits to represent a virtual address, and the highest 7 bits are not used. The five levels of the page table are divided into PGD, P4D, PUD, PMD, and PTE, each of which occupies 9 bits.
Bits 57 - 49 are used to index the table entries of the Page Global Directory (PGD), which corresponds to a unique PGD for each process address space, and the PTE (Page Tabel Entry) allows us to index the physical address of the final physical page. The lowest 12 bits of the virtual address then identify the location of the actual data in the physical page in the form of an offset.
At any level of the page table, the pointer to the next level can be empty, indicating that the virtual address in that range is not used by the current process. Thus, with the above scheme, if a segment of virtual address is not mapped to an actual physical address, those subtrees corresponding to that segment of virtual address do not exist in the entire quadruple tree structure. This saves unnecessary storage space.
Huge Page
In order to implement Huge Page support, intermediate level page tables can define some special entries that point directly to the physical page where the actual data is eventually stored instead of lower level page tables. For example, PMD table entries can skip the PTE level and point directly to the 2MB Huge Page. in some database operations, we can use Huge Page to store more data at the same time, thus reducing the number of random I/Os.
The supported Huge Page sizes are different for different CPU architectures. We can see the Huge Page sizes supported by Linux in HugeTLB Pages. Take X86-64 as an example, if the PMD points directly to a physical page, the physical address size is 12bit offest plus 9bit PTE, a total of 21bit address can represent 2MB data.
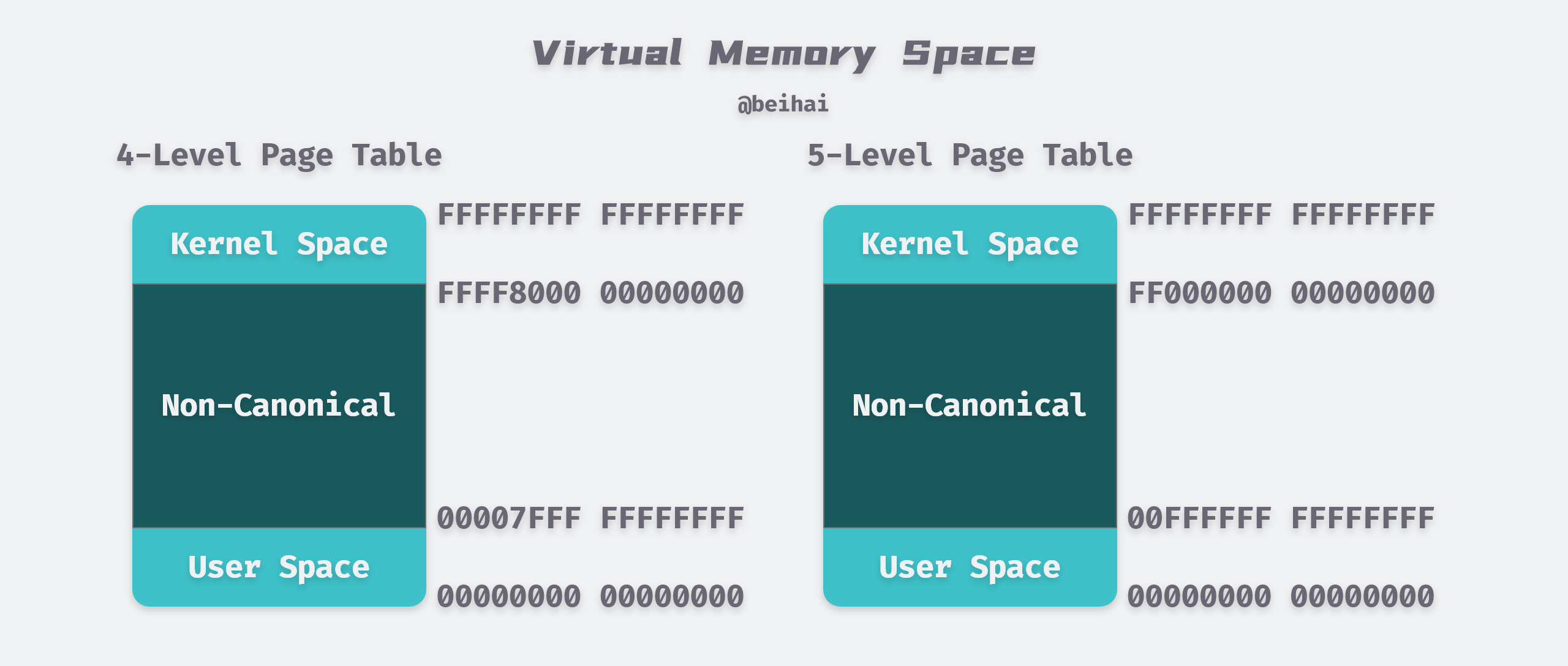
Virtual memory space
In the case of a four-level page table, each process has 256 TB of memory space, 128 TB in kernel space and 128 TB in user space, while a five-level page table provides 128 PB of addressing space. Since the virtual memory space of each process is completely independent, they all have full access to all memory from 0x00000000 00000000 to 0x00FFFFFF FFFFFFFF.
Applications
Based on the advantages of virtual memory’s middle layer processing, developers have provided us with some handy and useful features to better utilize with shared physical memory.
Shared memory
Normally, each process has its own private area of code, data, and stack that is not shared with other processes. The operating system creates a table of pages and maps the corresponding virtual pages to discrete physical pages. However, in some cases, there is a need to share code and data between processes, for example, every C program calls the C standard library function printf(). When using physical memory directly, the system cannot provide the shared memory feature because the physical memory address is unique, even if the operating system finds the same library loaded twice in the system, but each process specifies a different load address.
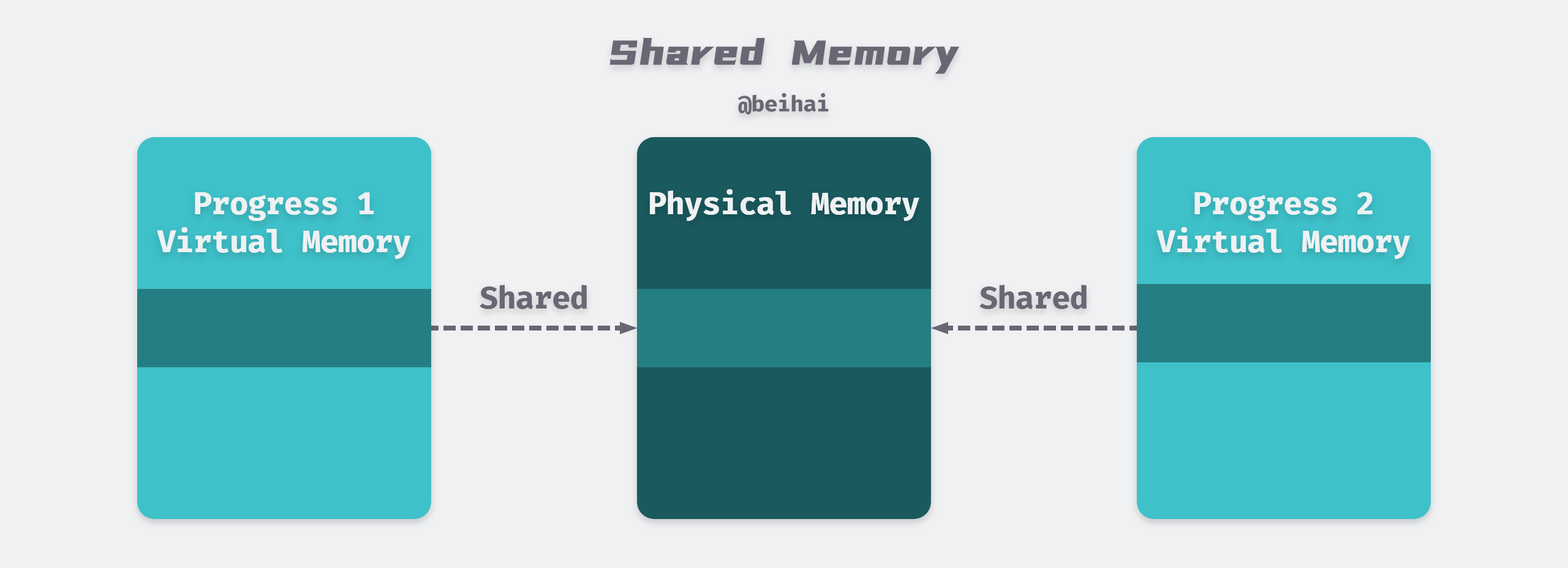
Memory and data sharing can be more easily achieved through virtual memory. Application processes create shared memory through the shmget() system call, and the operating system simply points the virtual memory address of each process to the system-allocated shared physical memory address. As shown in the figure above, the operating system arranges for multiple processes to share this memory by mapping the appropriate virtual pages in different processes to the same physical pages, thus reducing memory overhead and the cost of inter-process communication.
Memory-Mapped File
The Memory-Mapped File (mmap) technique maps a file into the virtual memory of the calling process and accesses the contents of the mapped file by manipulating the corresponding memory area. The mmap() system call function is typically used when frequent reads and writes to a file are required, replacing I/O reads and writes with memory reads and writes to achieve higher performance.
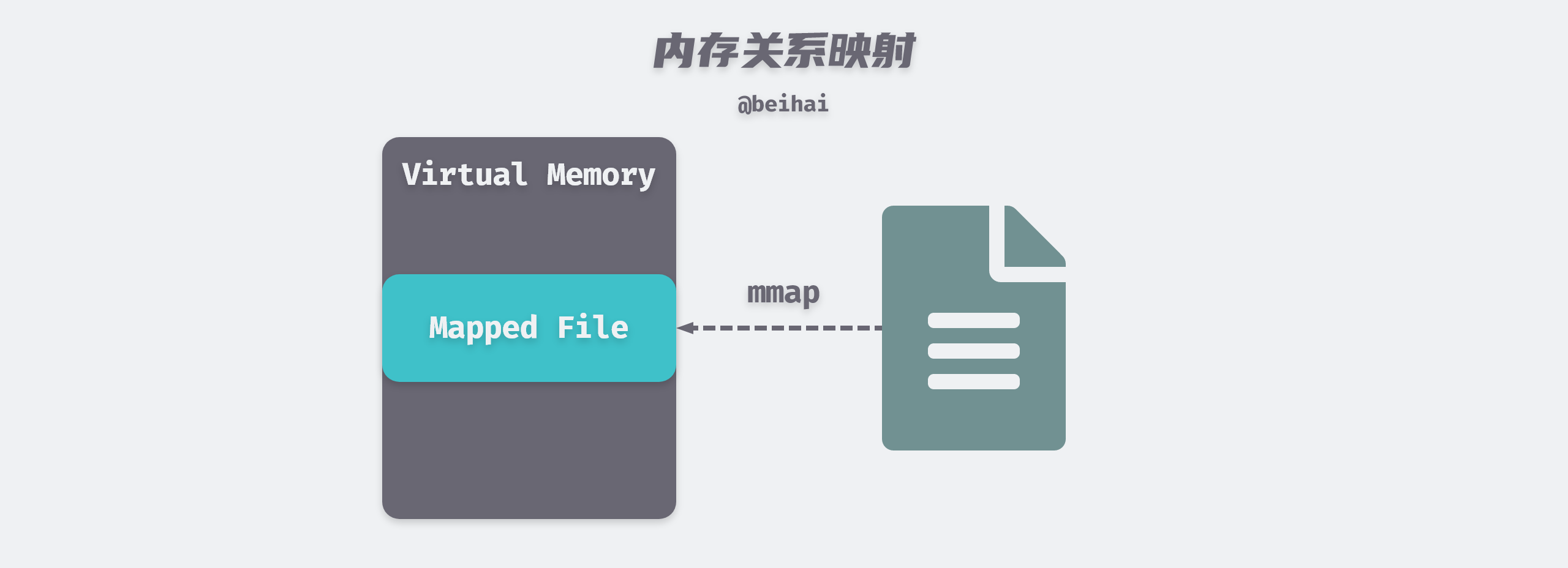
Traditional Unix or Linux systems have multiple buffers in the kernel. When we call the read() system call to read data from a file, the kernel usually copies the data to a buffer first, and then copies the data to the process memory space.
When using mmap, the kernel creates a memory map area in the virtual address space of the calling process, and the application process can access this memory directly for data, saving the overhead of copying data from kernel space to user process space. mmap does not actually copy the contents of the file to memory in real time, but rather copies the file data to memory only when a page-out interrupt is triggered during the reading of the data.
As mentioned above, program accesses tend to be localized, so we can map files much larger than physical memory and provide the associated fast read and write performance.
Copy-on-Write
Copy-On-Write (COW) technology does not actually copy the original object to another location in memory when copying an object, but sets a pointer to the source object’s location in the new object’s memory mapping table. The kernel maps the virtual memory to the physical memory and the two objects share the physical memory space. When a write operation is performed, the data is copied to the new memory address, the memory mapping table is modified to point to this new location, and the write operation is then performed at the new memory location.
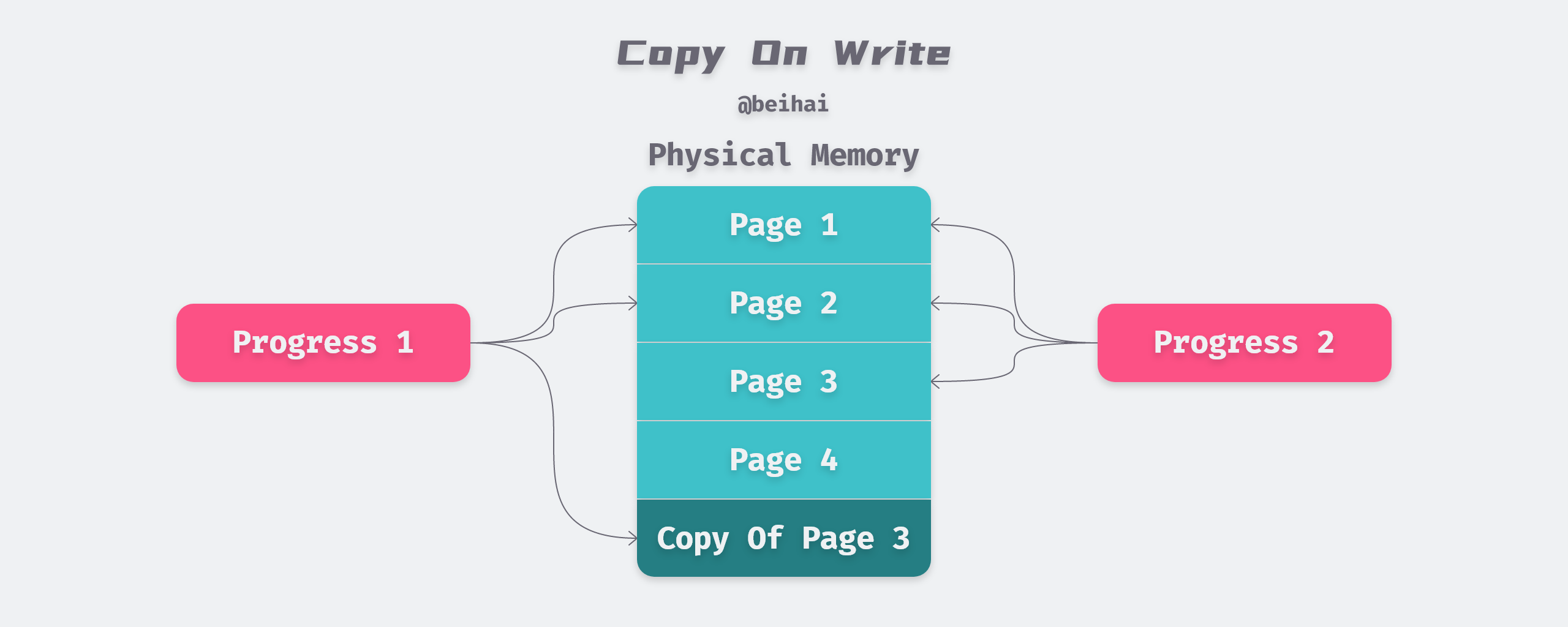
The main function of write-time replication is to postpone replication until the write operation actually occurs, which avoids a lot of pointless replication operations. The most common use case for write-time replication is the process creation mechanism, where the parent process creates several child processes through the system call fork(). To reduce the overhead of new process creation, modern operating systems use write-time replication, where the parent and child processes share the same memory space, thus enabling fast ‘copying’ of data.
When the fork() function is called, the parent and child processes share the physical memory space, but the parent and child processes are allocated different virtual memory spaces by the kernel, so they access different memory from the process point of view and are guaranteed to read their respective copies of data.
- When a read operation is performed on the virtual memory space, the corresponding value is returned directly.
- When the parent process makes changes to the shared memory, the shared memory is copied on a page-by-page basis and the parent process makes changes to the original physical space, while the child process uses the new physical space after the copy.
- When a child process makes changes to the shared memory, the child process will make changes on the copied new physical space without altering the original physical space to avoid affecting the memory space of the parent process.
Summary
The concept of virtual memory was introduced in the 1960s, long before CPU Cache was triggered by the increasing gap between CPU and main memory, but many of their concepts are very similar. Virtual memory treats physical memory as a cache of address space stored on disk, while CPU Cache is a cache of physical memory. The large performance gap between hardware is mitigated by a multi-level cache mechanism.
We don’t directly manipulate virtual memory in normal programming scenarios, but understanding virtual memory can help us better apply features like COW, mmap, etc. to write machine-friendly code.