I’ve been in contact with cloud native for a few years now, but I don’t know enough about kubernetes fundamentals, so I often need to open godoc or kubernetes source code to see the definition of an interface or method when writing code. This fast-food way of consuming code can solve common problems, but sometimes a simple problem will be troubled for a long time. The reason for this is that there is no systematic learning of kubernetes, and in particular no deeper understanding of the design and principles of the kubernetes API, which is a topic that we usually can’t get around to extend the functionality of kubernetes. At the same time, this is also a difficult topic to explain clearly, because kubernetes has become mature and complex after multiple iterations, which can also be seen from the multiple repositories under the kubernetes organization on the Github platform. I believe that many people, like me, do not know how to start when they see repositories such as kubernetes, client-go, api, apimachinery, and so on. In fact, it’s easier to start with the API, especially after we have some understanding of the functionality of the kubernetes core components.
In the next few notes, I’m going to take a deep dive into the design of the kubernetes API and the principles behind it.
API-Server
We know that the core components of kubernetes control level include API-Server, Controller Manager, and Scheduler, where API-Server internally interacts with the distributed storage system etcd to achieve persistence of kubernetes resources (e.g. pods, namespace, configMap, services, etc.).
It also provides an external RESTFul interface to access the kubernetes API, which is responsible for authentication (authN), authorization (authZ), and validation of API requests, among other things.
The “external” mentioned just now is a relative concept, because in addition to command-line tools like kubectl, other components of kubernetes also access the kubernetes API through various client libraries, see the client-libraries list for the official client libraries, the most typical of which is the Go language client library client-go.
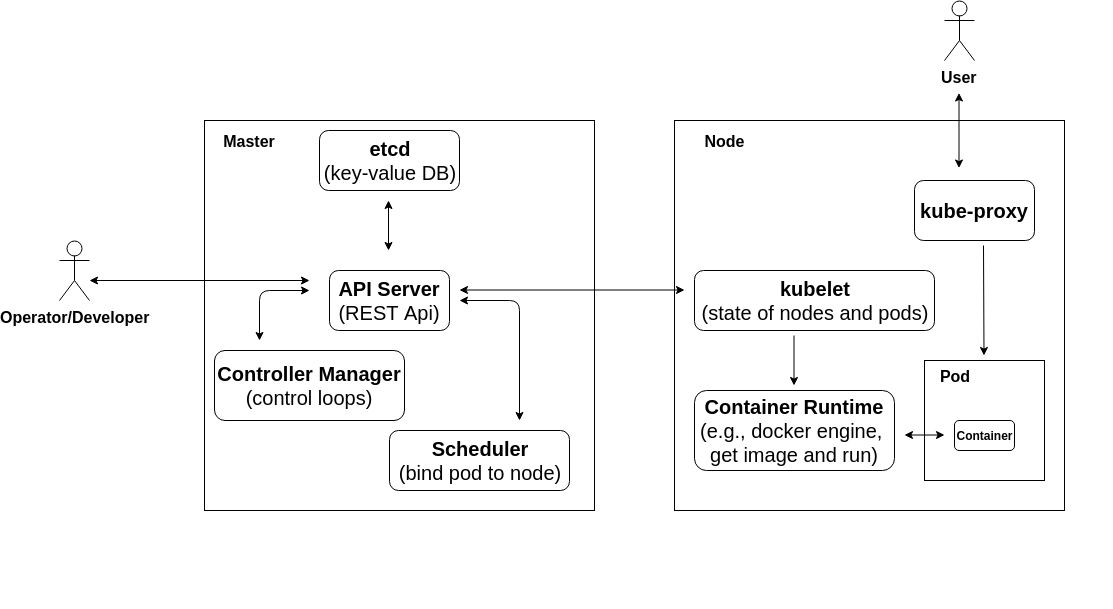
The API-Server is the only component that interacts with etcd at the kubernetes control level, and all other kubernetes components have to update the state of the cluster through the API-Server, so the API-Server is stateless; of course, multiple instances of the API-Server can be created for disaster recovery. Server implements a declarative API to manage kubernetes resources by working with the controller model.
Now that we know that the API-Server’s primary responsibility is to provide a RESTFul API for kubernetes resources, how do clients request kubernetes resources and how does the API-Server organize those kubernetes resources?
GVK vs GVR
The Kubernetes API is provided in a RESTful form via the HTTP protocol. API resources are serialized mainly in JSON format, but the Protocol Buffer format is also supported for internal communication. To facilitate extension and evolution, the kubernetes API supports grouping and multi-versioning, which is reflected in the different API access paths. With grouping and multi-versioning support, compatibility between versions can be ensured even if specific fields of API resources are removed or the presentation of API resources is refactored in a new version.
API-groups
Dividing the entire kubernetes API resource into groups provides a number of benefits.
- Groups can be turned on or off individually.
- Groups can have independent versions that iterate forward separately without affecting other groups
- The same resource can exist in several different groups at the same time, so that both stable and experimental versions of a particular resource can be supported
Information about the grouping of kubernetes API resources can be found in the serialized resource definitions, e.g.
In the apiVersion field, apps is the grouping of Deployment resources, in fact, Deployment does not only appear in the apps grouping, but also in the extensions grouping, different groupings can experiment with different features; in addition, core resources in kubernetes such as pod, namespace, configmap, node, service, etc. exist in the core subgroup, but for historical reasons, core does not appear in the apiVersion field, for example, the following serialized object defining a pod resource.
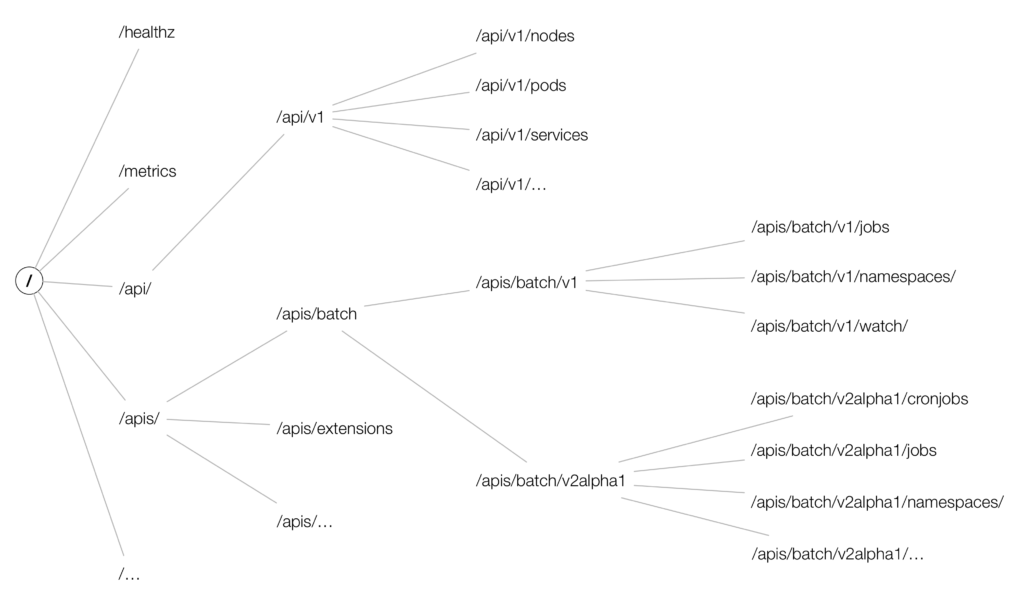
API groupings are also reflected in the RESTful API paths for accessing resources, generally /api/$VERSION for the core group and /apis/$GROUP_NAME/$VERSION for the other named groups, in addition to system-level resources such as cluster metrics /metrics, which basically form the tree structure of the kubernetes API.
API-version
To support independent evolution, the kubernetes API also supports different versions, with different versions representing different levels of maturity. Note that it is the API and not the resources that support multiple versions. This is because multi-version support is for the API level, not for a specific resource or field of a resource. In general, we distinguish between different resource objects based on API groups, resource types, namespace, and name. For different versions of the same resource object, the API-Server takes care of lossless switching between versions, which is completely transparent to the client. In fact, different versions of the same type of resource may have the same data in the persistence layer. For example, if the same resource type supports both v1 and v1beta1 API versions, the resource object is created with the v1beta1 version and can be updated or deleted with v1 or v1beta1 later.
API multi-version support is generally implemented by placing resource groupings in different versions, e.g., batch has both v2alph1 and v1 versions. In general, new resource groupings appear first in v1alpha1 version, are advanced to v1beta1 as stability improves, and finally graduate from v1 version.
As new user scenarios emerge, the kubernetes API needs to constantly change, perhaps by adding a new field, removing an old field, or even changing the presentation of a resource. To ensure compatibility, kubernetes has developed a series of policies. In general, for APIs that are already GA, Kubernetes strictly maintains their compatibility so that end-users can consume them with confidence, while beta versions of APIs are maintained as much as possible to ensure that they do not break interactions between versions, while for alpha versions of APIs it is difficult to guarantee compatibility and less recommended for use in production environments.
GVK vs. GVR Mapping
In the kubernetes API universe, we often use GVK or GVR to distinguish specific kubernetes resources. Where GVK is short for Group Version Kind, and GVR is short for Group Version Resource.
With the above introduction to kubernetes API grouping and multi-versioning, we already understand Group and Version, but what do Kind and Resource mean respectively?
Kind is the type of the API “top-level” resource object, and each resource object needs Kind to distinguish itself from the resource type it represents, e.g., for the example of a pod.
where the kind field represents the type of the resource object. Generally speaking, there are three different types of Kind in the kubernetes API:
- the type of a single resource object, most typically the Pod mentioned in the example earlier
- list types of resource objects, such as PodList and NodeList, etc.
- special types and types of non-persistent operations, many of which are subresources, such as
/bindingfor binding resources,/statusfor updating the status of resources, and/scalefor reading and writing the number of resource instances
Note that a resource type of the same Kind can not only appear in different versions of the same group, such as apps/v1beta1 and apps/v1, but it can also appear in different groups, for example Deployment starts with alpha characteristics in the extensions group, and GA is later pushed to the apps group, so in order to strictly distinguish between different Kinds, the API’s Group, Version and Kind need to be combined to form GVK.
Resource is a presentation of resources sent or read in JSON format using the HTTP protocol. It can be presented as a single resource object, e.g. .../namespaces/default, or as a list of resources, such as .../jobs. /To properly request a resource object, the API-Server must know the apiVersion and the requested resource so that the API-Server can properly decode the requested information, which is in the requested resource path. In general, the combination of Group, Version, and Resource of an API object into a GVR and a specific resource request path can distinguish the specific resource requested, e.g. /apis/batch/v1/jobs is a request for all jobs information.
GVR is often used to combine RESTful API request paths. For example, the RESTful API request path for the Deployment below apps/v1 looks like this.
|
|
The GVK of a resource can be obtained from the resource’s type information by fetching the serialized object in JSON or YAML format, and conversely, the GVK information can be used to obtain the GVR of the resource object to be read and build a RESTful API request for the corresponding resource. This mapping of GVK to GVR is called RESTMapper, and Kubernetes defines the RESTMapper interface with a default implementation of DefaultRESTMapper.
For a detailed specification of the kubernetes API, please refer to the API Conventions.
How to Store
After the previous section, we already know the organization of the kubernetes API and the design principles behind it. Next, let’s take a look at how the resource objects of the Kubernetes API end up providing reliable storage. As mentioned before, the API-Server is stateless and needs to interact with the distributed storage system etcd to implement persistent operations on resource objects. Conceptually, the data model supported by etcd is a key-value store. In etcd2, individual keys exist in a hierarchical structure, while in etcd3 this becomes a flat model, but the hierarchy is maintained for compatibility.
How are etcd’s used in Kubernetes? In fact, etcd is deployed as a standalone part, and even multiple etcd’s can form a cluster, and the API-Server is responsible for interacting with etcd’s to persist resource objects. Since 1.5.x, Kubernetes has been using etcd3 across the board.
The way etcd is used can be configured in the API-Server’s relevant startup parameters.
|
|
Kubernetes resource objects are stored in etcd in JSON or Protocol Buffers format, which can be determined by configuring the kube-apiserver startup parameter --storage-media-type to determine the format in which you want the serialized data to be stored in etcd, which by default is application/vnd.kubernetes.protobuf; alternatively, you can configure the default version number for persistent storage of resource objects for each API group by configuring the --storage-versions startup parameter.
Here’s a simple example of creating a pod and then using the etcdctl tool to view the data stored in etcd.
|
|
The process of creating a resource object using various client tools and then storing it in etcd is roughly as shown below.
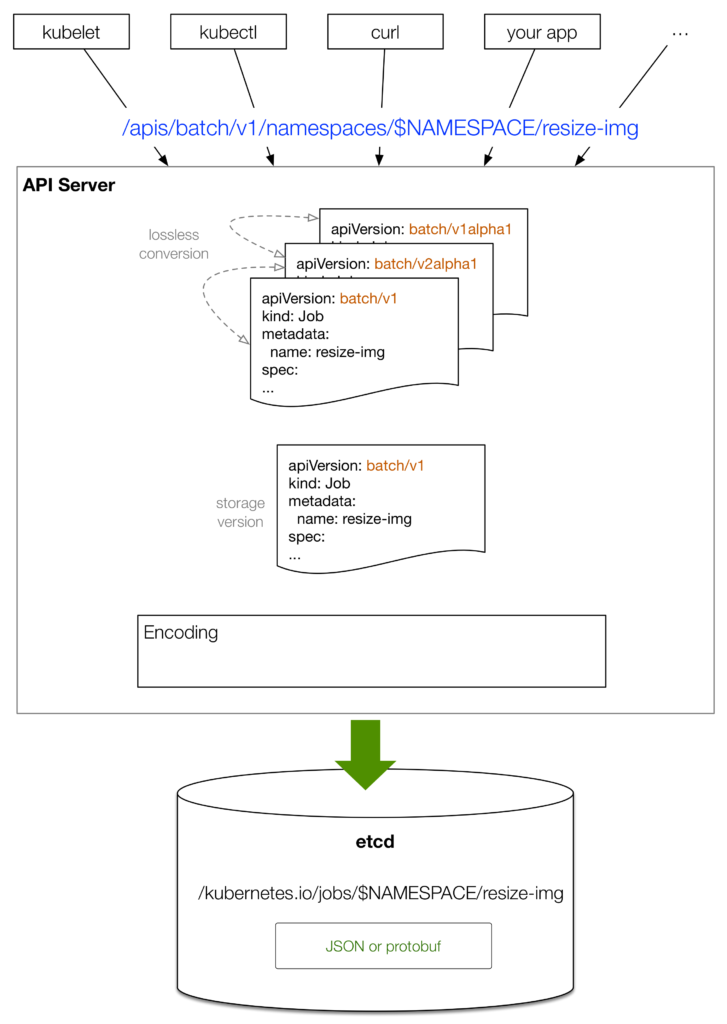
- The client-side tool (e.g. kubectl) provides a serialized representation of the resource object with the desired state, which is provided in YAML format in this example.
- kubectl converts the YAML to JSON format and sends it to the API-Server.
- the API-Server performs a lossless conversion for different versions of the same type of object. Fields that do not exist in older versions are stored in annotations.
- The API-Server converts the received object to the canonical storage version, which is specified by the API-Server startup parameter and is generally the latest stable version.
- Finally, the resource object is parsed by JSON or protobuf and stored in etcd with a specific key.
How does the lossless transformation mentioned above work? The following is an example using the Kubernetes Resource Object object Horizontal Pod Autoscaling (HPA).
|
|
The output of the above command shows that even if the version of HorizontalPodAutoscale changes from v2beta1 to v2beta2, API-Server is able to convert losslessly before the different versions, regardless of which version is actually stored in etcd. In fact, the API-Server stores all known Kubernetes resource types in a registry called Scheme. In this registry, the type, grouping, and version of each Kubernetes resource and how to convert them, how to create new objects, and how to encode and decode objects into a serialized form in JSON or protobuf format are defined.
So far, we’ve learned what the Kubernetes API-Server is, the basic terminology involved, and how to implement versioning of API resources and persistent storage of API resources. In the next notes, we’ll further explore the more detailed operational mechanisms of the Kubernetes API from a code implementation perspective.